【推薦演演算法】從架構到原理學習推薦(上)
前言
推薦是演演算法領域一個比較有趣且自由度很高的玩法,其解決問題的本質是「給什麼樣的user推薦什麼樣的item」,因此建模也是往這個思路去走,當然這裡的user和item概念可以互換或昇華。工業上不同企業所用的推薦系統架構也不盡相同,本文介紹的是一套工業上比較基礎的三層式架構:召回+排序+過濾。本文會通俗介紹所有概念,會涉及一些數學知識和演演算法原理,下一章再講解程式碼實戰,歡迎各位一起交流並指出不足之處,感謝!
目錄
1 推薦的定義
狹義上的推薦: 給使用者(User)推薦專案(Item),挖掘使用者可能喜歡的專案展示給使用者。
廣義上的推薦: 將推薦的主體和客體進行昇華,主體和客體可以任意選擇,如給專案推薦使用者,給使用者推薦使用者等。值得注意的是,使用者和專案也可以根據場景裡不同的實體進行變換,如給使用者集(如包含多個使用者的群組)推薦專案等,給使用者推薦專案集(如包含多個地點的行程)等
2 推薦的架構
如前面所提,我們用三層式架構:召回+排序+過濾,流程圖如下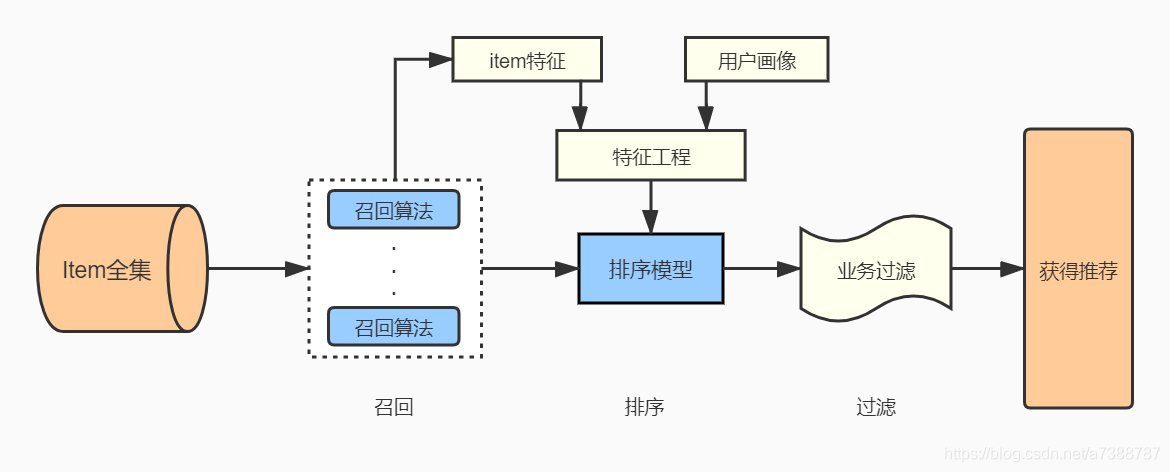
現在我們假設要從9999個商品裡面推薦10個給小明,以此場景來幫助理解上述整個每部分的作用:
1)item全集: 被推薦物件的全體,即9999個商品;
2)召回演演算法: 我們知道9999個商品相對是很大的數位,召回演演算法相當於第一層「漏斗「,能初步篩選出一些較為符合小明的商品,設從9999裡面挑出200個;
3)排序模型(排序演演算法): 商品規模從召回演演算法出來就降低到200了,但依然相對較多,那麼排序演演算法相當於第二層」漏斗「,幫我們計算小明購買這200個商品的概率,在本文這個架構裡面,所做的特徵工程和時序打標籤方法構造出來的模型就是解決「什麼樣的人購買什麼樣的商品的概率是多少」並從高到低排序;
4)業務過濾: 理論上排序演演算法給我們的結果裡面從高到低選10個推薦給小明就OK了,但可能這10個最高的商品未必符合實際的業務場景,如這10個商品小明已經購買過5個了,短期內不會再購買,那麼我們在短期內不應該推薦重複的商品給他,業務過濾就是為了滿足這些業務要求而設定的第三層」漏斗「;
5)推薦結果: 經過上述過程,就能獲得最後的推薦結果了,我們可以進行評價指標的計算,衡量推薦效果,提供演演算法優化的依據。
以上是推薦系統架構的大致概括,能初步理解這個過程後,接下來詳細介紹各層」漏斗「,包括演演算法原理,資料的形式變化及流向等。
3 分步理解
依次解釋召回演演算法,排序演演算法,業務過濾這三部分內容
3.1 召回演演算法
實際上常說的推薦演演算法通常指的就是召回演演算法(這裡的召回和有監督學習裡面的召回是完全不同的概念),仍然回到剛才小明推薦的場景,召回演演算法解決的是從9999個商品找出200個小明可能喜歡的商品,但是不同的召回演演算法得出來的200個商品也是不同的,通常這個階段可以只用一種演演算法,也可以用多種演演算法實現多路召回,即多種召回演演算法的結果組合起來構成這200個商品。本文介紹幾種經典的演演算法來實現召回
3.1.1 基於使用者的協同過濾(UserCF)
相信協同過濾這個詞(collaborative filtering)有些朋友也聽到爛了,通俗來說它的定義就是:小明喜歡一批商品,那麼我會看看有哪些人跟小明一樣喜歡這些商品的,認為這些人和小明是具有相同的喜好,再把這些人喜歡過的商品(小明還沒喜歡過或接觸過的)推薦給小明。程式就是這樣的程式,具體的」喜歡「怎麼衡量呢?
我們需要這樣的資料:
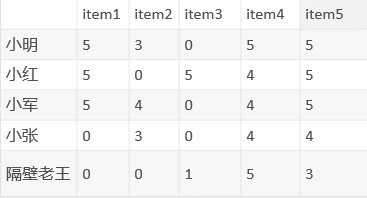
這是一個評分矩陣,通常由埋點資料或其他原始資料經過處理而得到,這裡以0-5評分製為例,0代表這個人還沒點選過這個商品,1-5可以按照從點選到購買成功這個行為路徑去劃分,5分就是購買成功(當然你也可以用0-10分制),常用的還有0/1制,即只要購買了就是1,其餘均為0。這個矩陣就能反映一個人的喜好了,如小明的喜好就是[5,3,0,5,5],小軍[5,4,0,4,5],顯然這是兩個向量,兩人的相似度就可以用向量間的夾角來衡量,這樣的相似度稱為餘弦相似度,公式為:
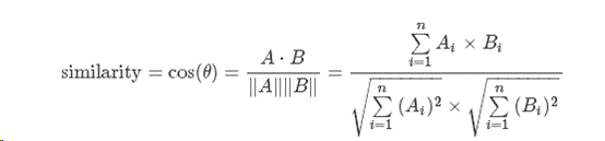
還可以用其他方式來計算相似度,如:皮爾遜相關係數,閔氏距離,傑卡德相似係數,曼哈頓距離,漢明距離等,總之,相似度越大,兩人的愛好越接近。
通過上面的評分矩陣和相似度計算公式,是不是可以計算任意兩人間的相似度了?再畫成一個表格:
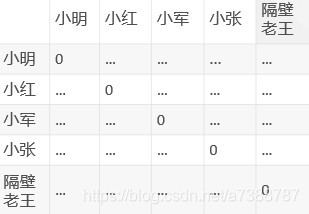
這個就是相似度矩陣,我就偷懶不一一計算了,省略號就是具體的相似度,每個人與自身的相似度肯定是最大的,我們要置為0。然後按照相似度矩陣可以找到與小明最接近的n個人,假設小紅和小軍與小明的愛好最接近,商品也足夠多的時候,那麼就可以從小紅、小軍中選擇4分(自己定)以上且小明對應為0分的商品作為小明的推薦列表了,這個就是UserCF所做的事,回到我們之前的場景中,在9999個商品中就可以給小明召回200個商品,當然一些特殊情況比如小明已經購買過9900個商品了,只有99個0分的,那麼可以自行設計解決方案,可以補齊到200個商品,也可以只召回99個等等。
3.1.2 基於物品的協同過濾(ItemCF)
能理解上面的UserCF,ItemCF就很好理解了,在剛才的評分矩陣中我們是將每一行看作是一個向量的,現在,同樣的評分矩陣,我們將每一列看作一個向量:
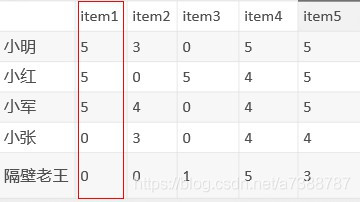
如item1就是[5,5,5,0,0],每個item的向量就衡量出它在人群中的地位了,又到了喜聞樂見的計算相似度環節,計算任意兩個item之間的相似度矩陣:
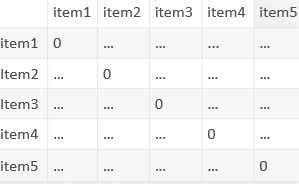
這個相似度矩陣的物理意義就是用各個item在人群裡的表現來衡量任意item的接近程度,在原來的評分矩陣中,小明的向量是[5,3,0,5,5],即小明對item1, item3, item5都是很喜歡的,對這三個item,是不是可以在上述item相似度矩陣中找到與之最接近的n個item呢?答案是肯定的,如果item足夠多,那麼n可以等於200,就作為小明的推薦列表了,這就是ItemCF所做的事。
以上就是兩種協同過濾的原理,協同過濾可以說是最經典的推薦演演算法,你們可能已經發現:UserCF傾向於社會化,為你找到與你接近的群體,ItemCF則傾向於個性化,幫你找到你自己會喜歡的那一類物品。如果你是產品經理,看到這裡可以跳過後續的幾個演演算法,快速瀏覽後面的排序演演算法、業務過濾,瞭解整個系統運作即可;如果你是資料探勘工程師,不妨集中精神繼續看完接下來的幾個召回演演算法。
3.1.3 傳統矩陣分解(MF)& SVD & SVD++
矩陣分解(Matrix factorization)的思想和協同過濾完全不同,我們看一下評分矩陣:
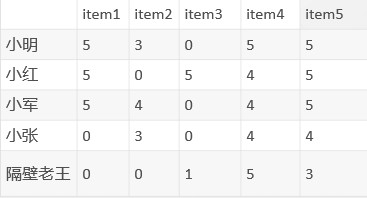
前面提過矩陣中為0的表示這個人還沒接觸過這個商品,但實際小明喜不喜歡這個商品,我們是不知道的,換句話說,小明對於item3將會有一個具體的分數,只是我們目前不知道而已,那我們能不能預測出這個分數呢?是肯定的,為了方便理解,先把矩陣中為0的格子換成問號:
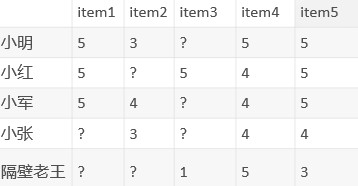
矩陣分解可以計算出上面所有問號的近似值,是很純粹的數學問題。我們知道兩個矩陣相乘能得到一個新的矩陣,反之,一個矩陣也可以分解成兩個矩陣相乘:
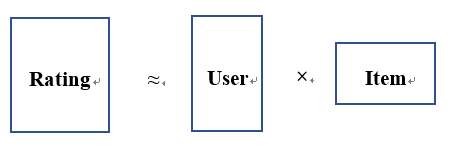
一個評分矩陣分解成兩個矩陣後,分別表示使用者隱因子矩陣P、專案隱因子矩陣Q,什麼意思呢,解釋起來會比較複雜,我的理解如下:
你對《泰坦尼克號》的喜愛程度是5分,矩陣分解後,使用者隱因子矩陣P表示的是其他使用者有幾分像你,專案隱因子矩陣Q表示其他電影有幾分像《泰坦尼克號》,從而加權組合計算得出所有人喜歡每個電影的程度。
因此矩陣分解的過程就是擬合出這兩個子矩陣的過程:

演演算法思路:
- 初始化左矩陣P 及 右矩陣Q, 賦予隨機值
- 構造目標函數C = 評分矩陣 - 左矩陣 x 右矩陣
- 利用梯度下降法求解, 設定步長及結束條件:
達到最大迭代次數 或 C足夠小 或 C變化足夠小- 利用步長更新左右矩陣
- 迭代結束後: 評分矩陣 ≈ 左矩陣P x 右矩陣Q
- 原評分為0的位置得到非0值, 作為預測分數
- 將預測分數從高到低取n個作為召回
可以不用理解,知道結論即可:評分矩陣A可以分解成兩個子矩陣,兩個子矩陣再相乘一次得到近似矩陣A′≈A,其中A′ 把A的0值計算出來了,且兩個矩陣的非0值是非常接近的,有理由認為0值計算出來的就是預測值,評分矩陣就解出來了,即可從高到低把預測分數高的200個物品推薦給小明。
矩陣分解的變種還有SVD奇異值矩陣分解和SVD++,SVD是對傳統矩陣分解的一個變種,把一個評分矩陣分解成三個子矩陣,中間矩陣反映的是分解後能還原為原矩陣的程度,計算公式和思想不同,但形式上都是希望把0值計算出來。SVD++在 SVD 模型的基礎上融入使用者對物品的隱式行為,認為 評分=顯式興趣 + 隱式興趣 + 偏見,在計算0值時會加入該使用者對於所有物品的評分與全體使用者平均水平的差異,例如它發現你大部分平分都比平均值低0.5分,那麼在計算你對新物品的喜歡程度時,額外減去0.5分,這相當於加入了」大膽的猜測「作為偏置值,因此SVD++計算耗時十分漫長,有時會因為過於」大膽「而使效果更差,因此實際使用不多。
3.1.4 貝葉斯個性化排序(BPR)
BPRMF也是一種矩陣分解,但它是基於BPR這種思想來實現的矩陣分解,因此和傳統矩陣分解區分開來。假設小明喜歡的物品集合是I,其餘物品集合是J,顯然評分表現上是Ui>Uj的,為了求出具體的評分,傳統矩陣分解訓練的過程是為了擬合一組引數矩陣P和Q,來預測出小明對J集合的評分,BPR的訓練過程則是為了擬合一組引數矩陣W和H,來最大化小明對I和J兩者評分的差距,即求概率P(Ui>Uj)時,W和H的值,求出後兩矩陣相乘後得到的矩陣是使用者對任意商品的排序分,從高到低選擇推薦即可。下面給出無數學公式的演演算法思路,參考於劉建平老師的部落格,有興趣的同學可以去詳細學習原理:傳送門
損失函數L:
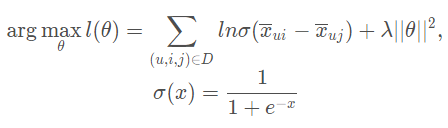
演演算法思路:
輸入:訓練集D三元組,梯度步長α, 正則化引數λ,分解矩陣維度k
輸出:模型引數,矩陣W,H
1.隨機初始化矩陣W,H ;
2.迭代更新模型引數 (損失函數是越來越大的);
3.如果W,H收斂,則演演算法結束,輸出W,H,否則回到步驟2.
4.當拿到W,H後,就可以計算出每一個使用者u對應的任意一個商品的排序分;最終選擇排序分最高的若干商品輸出
3.1.5 基於詞向量的召回(word2vec)
NLP領域也能用來做推薦召回,其思想很直觀明瞭,我們知道一篇文章裡面的關鍵詞往往和文章主題有關,換言之,同一個主題的文章,關鍵詞往往接近甚至一樣,再換言之,同一主題的文章的關鍵詞,往往捆綁出現,理解這個思想後,我們來看看怎麼將詞向量用於推薦。
我們昇華一下,同一主題的文章看成是同一類使用者,文章裡面出現的關鍵詞看成是使用者喜歡過的物品名稱,也就是說同一類使用者喜歡的物品,往往捆綁出現,比如小明和小軍是同類人,小明按時間先後購買的物品集合是 [球衣,足球,足球鞋,長襪,護板] ,小軍按時間先後購買的物品集合是 [哨子,足球,足球鞋,護板],顯然這類使用者喜歡的物品有一個捆綁出現的關係,那麼來了一個新使用者小王,他的行為資料表現出對 足球鞋 的喜歡,根據小明和小軍的表現來看,如果只推薦1個商品,可以推 「足球」或「長襪」 ,足球往往在足球鞋之前被購買,長襪往往在其之後被購買,因此向前或向後推薦均可;如果我們要推薦2個商品,那麼可以推球衣,足球,哨子,長襪,護板中的任意2個,依然是向前或向後均可,這裡推薦1個或2個就是一個視窗概念,視窗越大,推薦範圍越大,捆綁關係越不明顯,反之越小,捆綁關係越強。這個特例明白的話,就推廣一下概念,成千上萬的使用者,每個使用者各自喜歡的商品集合按時間先後排序,訓練一個模型,那麼這個模型就描述了這個人群裡面的捆綁關係,此時來了一個新人,一旦他表現出對某個商品的喜歡,模型就可以根據該商品去尋找捆綁的其他商品推薦給他。這是通俗的解釋,技術一點的語言概括就是:把使用者一列行為看成文字,商品就是單詞,利用nlp技術計算每個詞(商品)的向量,這樣可以衡量商品之間的相似度。利用使用者歷史購買記錄,推薦相似的商品。這就是word2vec詞向量模型所做的事。
比較經典的幾個召回演演算法介紹完了,它們是並列的,多選一的關係,回到一開始的場景,從9999個商品召回200個給小明的任務就完成了,當然如果你希望召回的結果作為最終推薦結果,那麼可以不需要後面的排序演演算法,把200設定為10個即可。
3.2 排序演演算法
推薦的評價指標中有一些指標是會衡量推薦的順序的,如MAP,MRR,這些指標在單純的召回演演算法中無法體現,因為召回演演算法僅告訴我們使用者可能購買的物品,但無法得知購買的概率,並且上面提到的召回演演算法都和只用到了使用者的行為資訊資料,沒用上關於商品和使用者的相關屬性,依然存在很大的提升空間,這就需要第二層「漏斗」——排序演演算法。
排序演演算法實際是一個有監督學習裡面的分類任務,既然如此,我們就用分類中效果比較不錯的新秀——LightGBM來解決問題(Xgb也是可以的),簡便,輕盈,快速,還能輸出概率值,這裡不贅述它的原理,有興趣的同學自行了解,我們直接上用法。
每個被推薦的使用者從召回演演算法出來後都有200個適合他的物品,接下來講一下建模思路,設原始資料是1-4月份的行為資料:
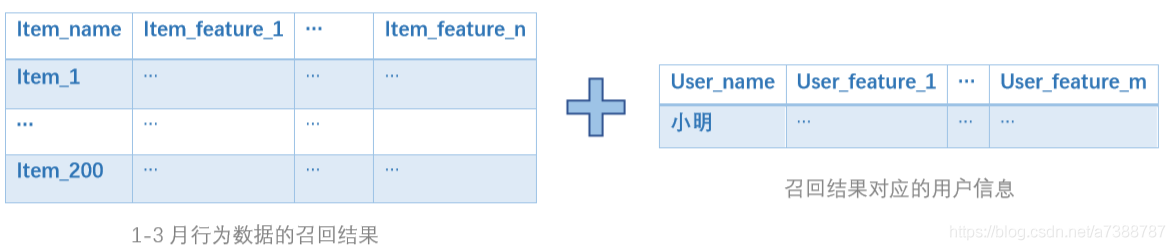
1-3月份的資料經過召回演演算法處理得到召回結果,與使用者資訊表關聯並做特徵工程,用4月分的資料為其打標籤,會得到如下訓練集:
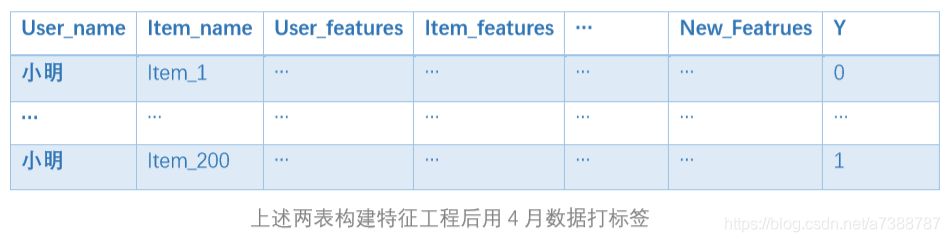
然後訓練模型,把User_name及Item_name兩列蓋住,不難發現模型學習的本質是「具有某某屬性的使用者會購買某某特徵的物品」,這個模型就能很好地解釋了當前資料集裡面人群的購買習慣;調參,輸出概率值,即為使用者購買某商品的概率了,從高到低選取10個推薦結果即可。
3.3 業務過濾
到此為止我們已經推播了10個小明最有可能購買的商品了,但是考慮到推薦的週期性(不可能只執行一次對吧),因此可以結合我們的業務需求去設計一些業務規則,如:使用者購買過同樣商品後需要多久後才繼續推薦這個商品(即使模型算出來的概率很高);或者同樣商品在連續幾個推薦週期內重複推薦,使用者仍沒有購買,我們就不能強人所難了,諸如此類的規則。業務過濾實現方法很多,可以SQL定期構建重複商品表,排序後的推薦結果與此表關聯過濾再進行推薦,等等。
另外還有一些冷啟動和新使用者等問題的處理方案,不同場景處理方法不同,可以做一些處理並加入到演演算法裡面,也可以單獨走另一套流程,如建立熱榜規則,對新使用者只推熱榜商品,或對活躍使用者推播新商品,好處是對於活躍使用者或熱門商品來說,將新商品/新使用者與之聯絡能快速產生互動資料,方便後續的推薦使用。
4 評價指標
最後我們希望衡量整體推薦效果如何,推薦上有幾個常用指標:
PRE精確率: 推薦的基金中, 被使用者」喜歡」的部分佔推薦數的比例, 取值範圍[0,1]
REC召回率: 推薦的基金中, 被使用者」喜歡」的部分佔使用者所有」喜歡」的比例, 取值範圍[0,1]
F1: 與機器學習一樣, 綜合考慮了PRE和REC的值
HR命中率: 被推薦的使用者中有」喜歡」的人數佔總使用者數
MRR平均排名: 推薦列表中, 使用者」喜歡」的第一個基金的排名的倒數, 越大越好
MAP平均精度: 推薦列表中, 每個使用者」喜歡」的基金的排名倒數之和的平均值
計算公式直接借用其他大佬總結的圖:

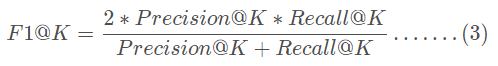
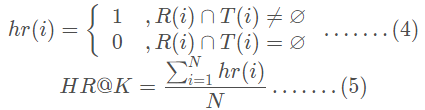


第一類指標關心使用者想要的,我有沒有推薦到,強調語文裡的「準確性」,分別為Precision@K、Recall@K、F1@K、HR@K ; 第二類指標更關心找到的這些專案,是否放在使用者更顯眼的位置裡,即強調「順序性」,分別為MRR@K、MAP@K。實際上常用的是PRE、REC、MRR和MAP,其中對於後兩個考慮順序的指標來說,通常數值會比較低,且波動較大,而REC在使用者瀏覽記錄很多但推薦數目較少時,得分會非常低,因此如果對於推薦效果要求並非十分嚴格的系統,PRE能更好反映推薦品質。
純手打,肝了一段時間終於寫完,本系列的下一篇將用程式碼實戰去實現這套系統,如果覺得對自己有幫助,請點贊收藏加關注O