Apache Kylin安裝指南+入門案例(附圖)
Apache Kylin安裝檔案
- Kylin安裝
- Kylin使用案例
1. Kylin安裝
-
使用FTP工具上傳apache-kylin-2.5.1-bin-hbase1x.tar.gz壓縮包到node01的
opt/software目錄下 -
解壓上一步上傳的壓縮包
opt/module下tar -zxvf apache-kylin-2.5.1-bin-hbase1x.tar.gz -C /opt/module -
進入
opt/module目錄,更改apache-kylin-2.5.1-bin-hbase1x目錄名字mv pache-kylin-2.5.1-bin-hbase1x kylin-2.5.1 -
此時
opt/module目錄結構如下
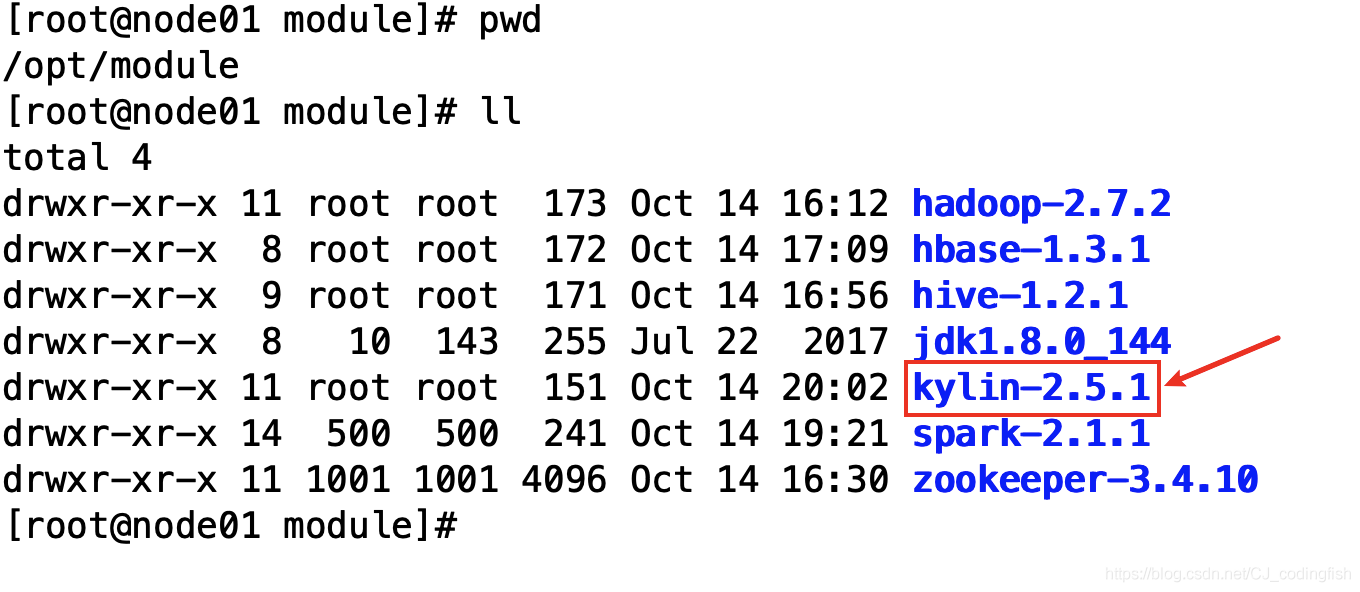
-
進入到
kylin-2.5.1目錄,檢視kylin的目錄結構
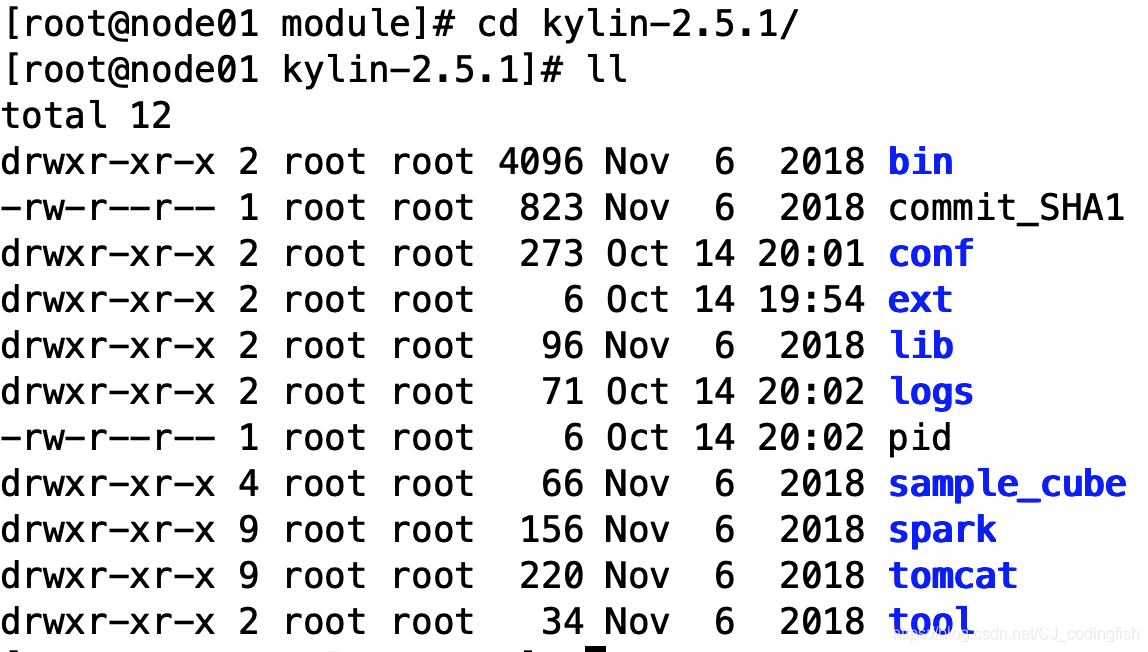
-
進入
conf目錄,將kylin.properties.template改成kylin.properties,命令:mv kylin.properties.template kylin.properties -
編輯
kylin.properties檔案,新增以下內容# 下面的node01是你的主機名,我將kylin裝在了第一個節點上,需要根據你的主機名更改 kylin.server.cluster-servers=node01:7070 kylin.server.mode=all -
在
/etc/profile下新增java hadoop hive hbase kylin spark的環境變數,下面參考我的設定# JAVA_HOME export JAVA_HOME=/opt/module/jdk1.8.0_144 export PATH=:$JAVA_HOME/bin:$PATH # HADOOP_HOME export HADOOP_HOME=/opt/module/hadoop-2.7.2 export PATH=$PATH:$HADOOP_HOME/bin # SPARK_HOME export SPARK_HOME=/opt/module/spark-2.1.1 export PATH=$PATH:$SPARK_HOME/bin # HIVE_HOME export HIVE_HOME=/opt/module/hive-1.2.1 export PATH=$PATH:$HIVE_HOME/bin # HBASE_HOME export HBASE_HOME=/opt/module/hbase-1.3.1 export PATH=$PATH:$HBASE_HOME/bin # KYLIN_HOME export KYLIN_HOME=/opt/module/kylin-2.5.1 export PATH=$PATH:$KYLIN_HOME/bin -
使用分發命令分發
/etc/profile檔案,命令是xsync /etc/profile# 附xsync指令碼 # 注意的兩個地方看下圖 一個是更改 for迴圈中的條件,一個是更改用到主機名的地方 # 使用檔案分發指令碼步驟如下 1. cd /usr/local/bin 2. vim xsync 3. 輸入下面的shell指令碼內容 4. chmod 777 xsync 5. 在任意一個位置建立一個檔案,然後測試xsync指令碼 #!/bin/bash #1 獲取輸入引數個數,如果沒有引數,直接退出 pcount=$# if((pcount==0)); then echo no args; exit; fi #2 獲取檔名稱 p1=$1 fname=`basename $p1` echo fname=$fname #3 獲取上級目錄到絕對路徑 pdir=`cd -P $(dirname $p1); pwd` echo pdir=$pdir #4 獲取當前使用者名稱稱 user=`whoami` #5 迴圈 for((host=1; host<4; host++)); do echo ------------ node0$host ---------------- # rsync是遠端同步工具 -r遞迴 -v顯示覆制過程 -l拷貝軟連線 rsync -rvl $pdir/$fname $user@node0$host:$pdir done
-
由於上面在
/etc/profile檔案中新增了內容,需要鍵入source /etc/profile讓剛剛做的修改立即生效 -
正式分發
/etc/profile檔案,鍵入命令xsync /etc/profile -
到第二個和第三個節點上檢視
/etc/profile檔案中的內容是否和第一個節點中的檔案內容一致 -
在第二個節點和第三個節點上鍵入命令
source /etc/profile -
進入kylin的安裝目錄
cd /opt/module/kylin-2.5.1/
-
鍵入以下命令以分別檢查環境
# 檢查環境 bin/check-env.sh # 檢查hive依賴 bin/find-hive-dependency.sh # 檢查hbase依賴 bin/find-hbase-dependency.sh -
啟動/停止Kylin
# 啟動Kylin bin/kylin.sh start # 停止Kylin bin/kylin.sh stop -
Warnings這裡目前收集了一次錯誤,之前都解決了,如果有需要請在貼文下方留言您的error錯誤:
ERROR: Check hive's usability failed, please check the status of your cluster解決 在kylin的安裝目錄下進入
bin目錄然後找到check-hive-usability.sh,之後鍵入命令vim check-hive-usability.sh編輯該檔案,修改timeLeft的值為100(預設值為60),見下圖

-
進入web介面
如果成功啟動,在terminal中鍵入jps命令會出現RunJar的程序,terminal末尾的顯示的資訊如下圖

# 進入瀏覽器,在位址列中輸入 node01:7070/kylin/login # 賬號和密碼資訊 賬號:ADMIN 密碼:KYLIN -
Web介面如下
2.Kylin使用案例
-
資料準備
-
百度網路硬碟連結下載: https://pan.baidu.com/s/18vuT3wbANskP7J3nhlf4GQ 密碼: 10jw
-
下載
emp.txt和dept.txt
-
-
進入到Hive的操作介面
-
建立資料庫表
# 建立部門表 create external table if not exists default.dept( deptno int, dname string, loc int ) row format delimited fields terminated by '\t'; # 建立員工表 create external table if not exists default.emp( empno int, ename string, job string, mgr int, hiredate string, sal double, comm double, deptno int) row format delimited fields terminated by '\t'; -
檢視建立的表
show tables; -
向表中匯入資料
# 將從網路硬碟中下載好的資料檔案匯入到節點的`/opt/module/datas`目錄下(datas目錄是自己手動建立的) # 這裡Hive中就使用預設的資料庫default資料庫 # 向部門表dept中匯入資料 load data local inpath '/opt/module/datas/dept.txt' into table default.dept; # 向員工表emp中匯入資料 load data local inpath '/opt/module/datas/emp.txt' into table default.emp; -
檢視兩張表中的資料
select * from emp;select * from dept;
-
-
在Kylin的Web介面建立專案
-
登入系統
- 使用者名稱:
ADMIN密碼:KYLIN
- 使用者名稱:
-
建立工程
- 點選左上角的 + 號,輸入Project Name和Project Description;最後點選頁面卡右下方的
Sumbit來提交
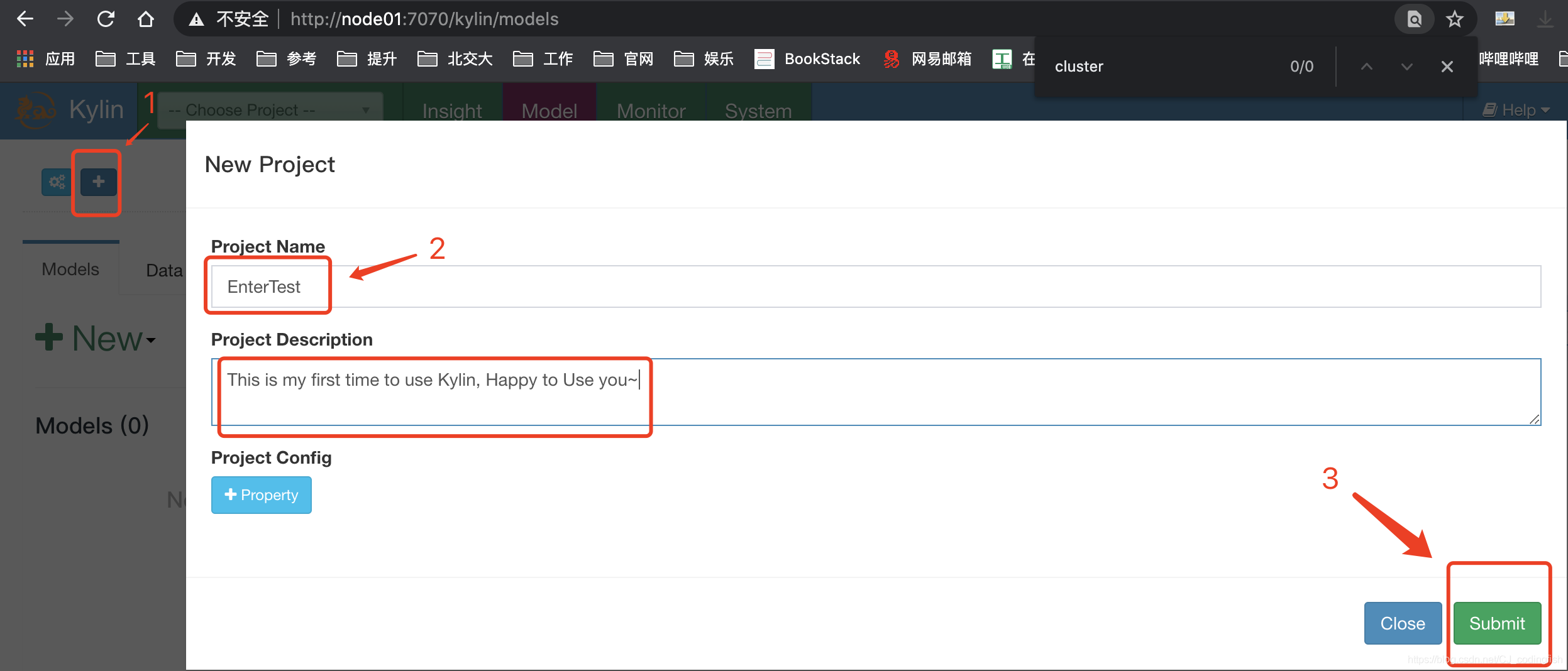
- 點選左上角的 + 號,輸入Project Name和Project Description;最後點選頁面卡右下方的
-
選擇資料來源
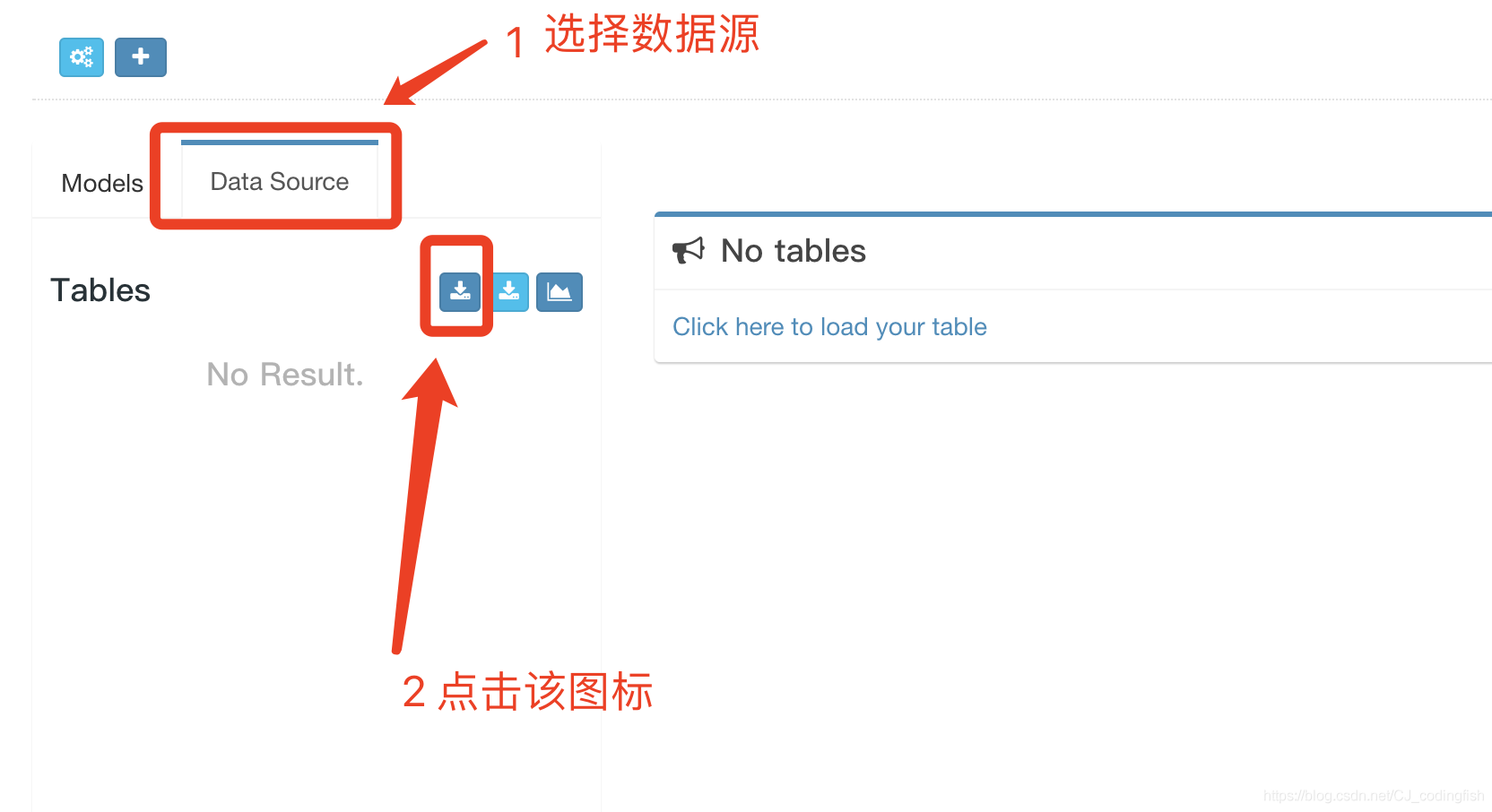
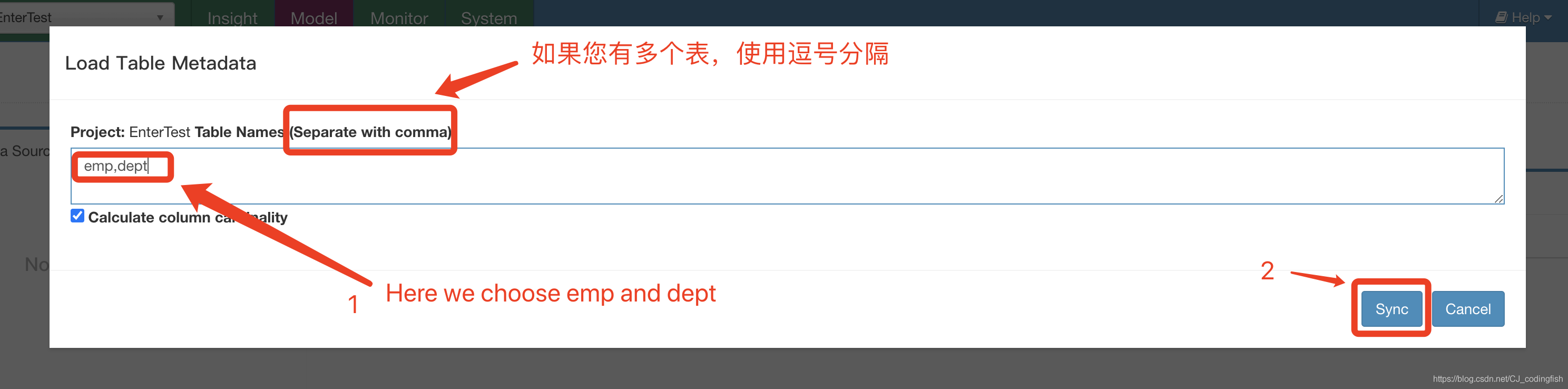
-
檢視資料來源
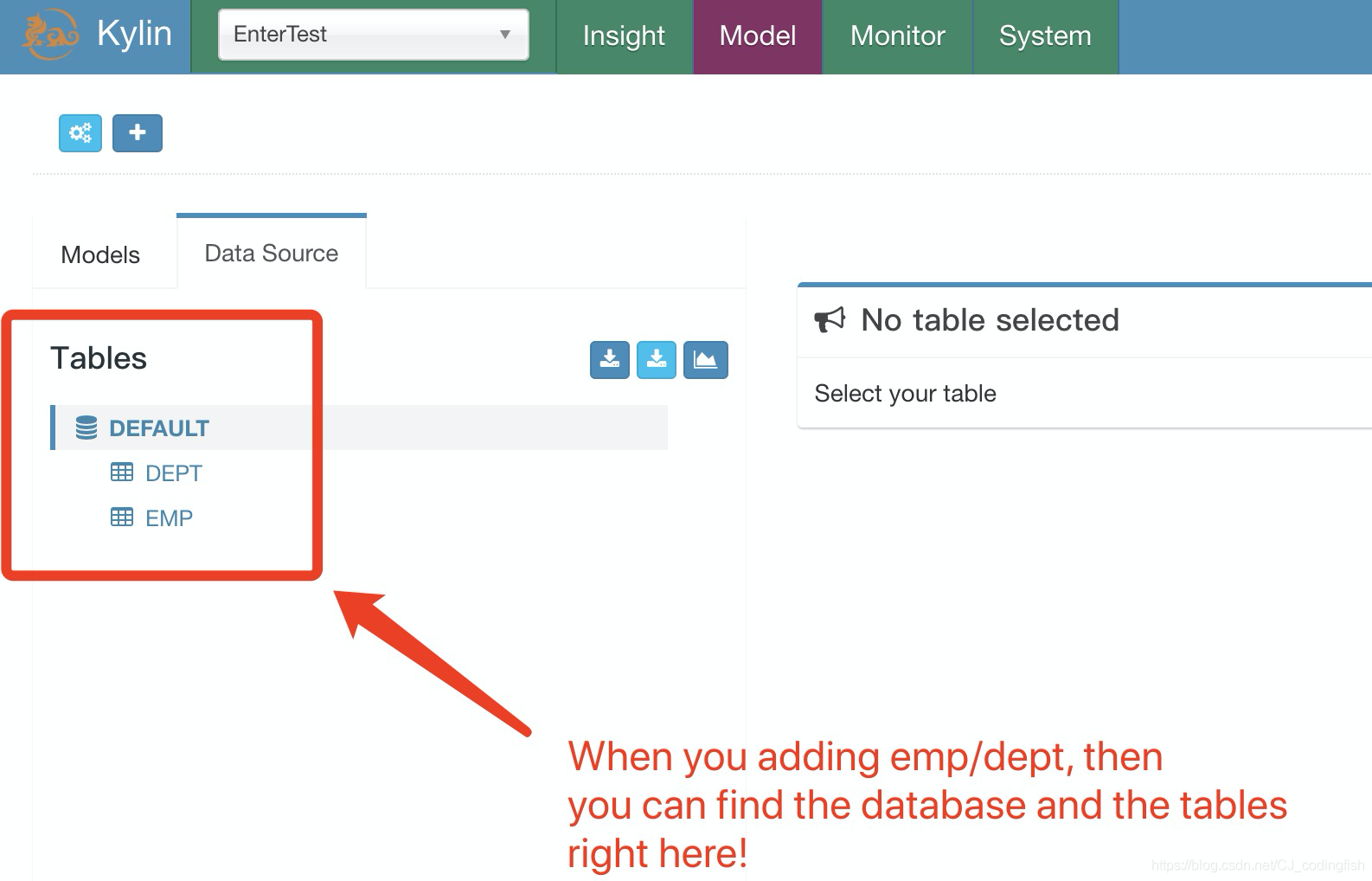
-
建立Model
-
回到Models頁面
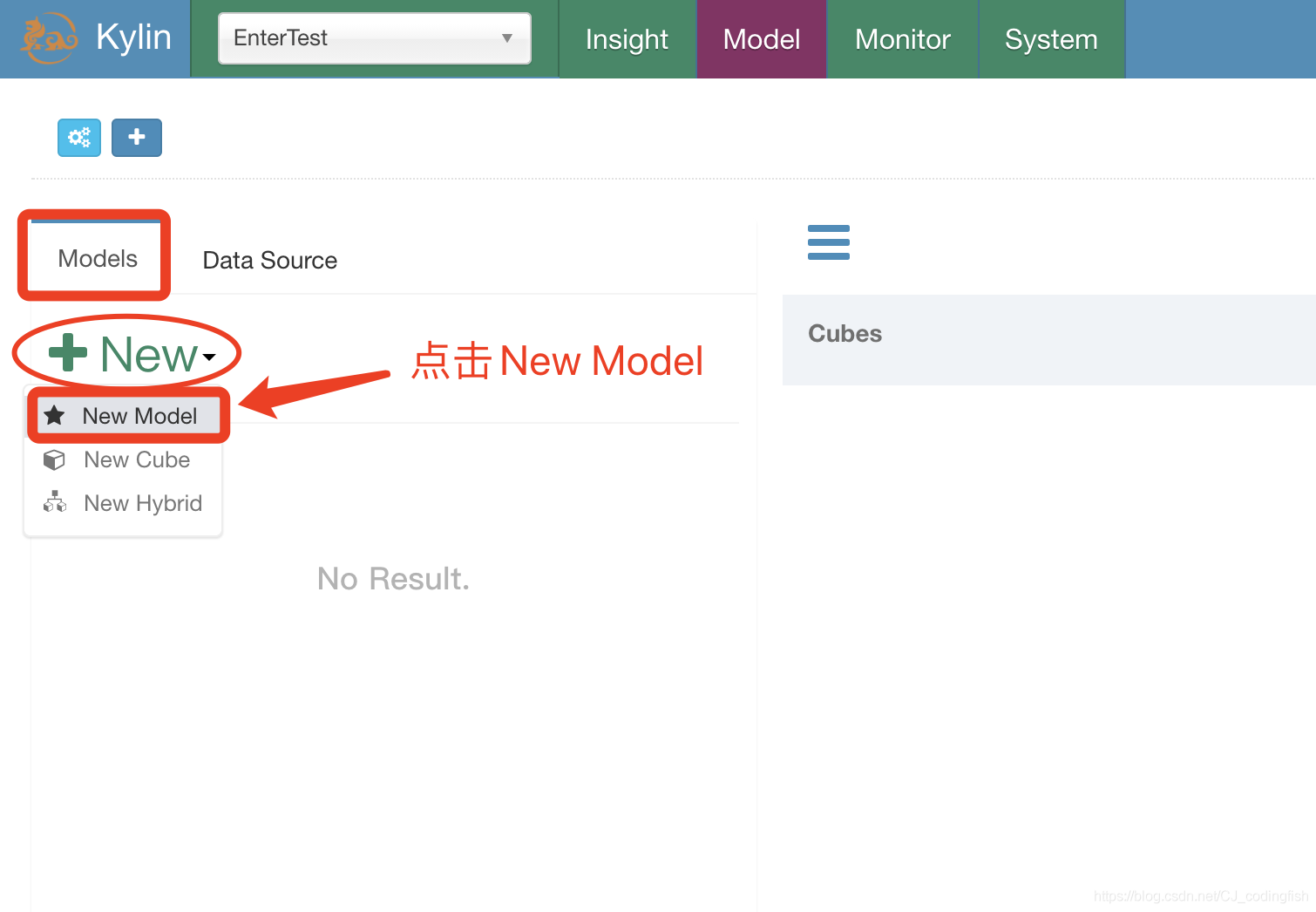
-
填充Model名稱和描述資訊,然後繼續Next
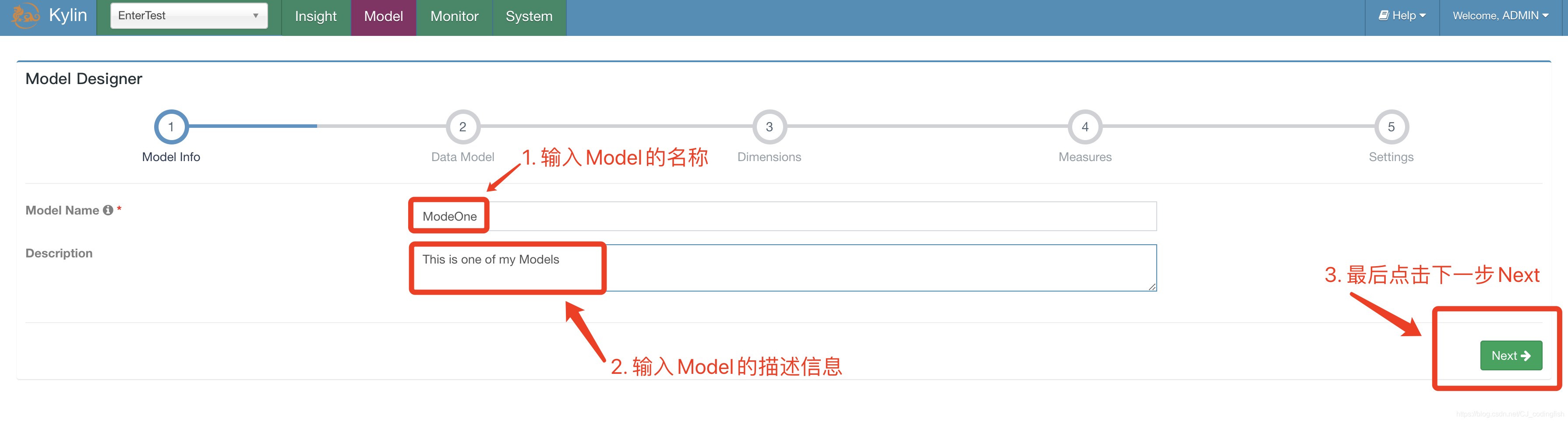
-
選擇事實表
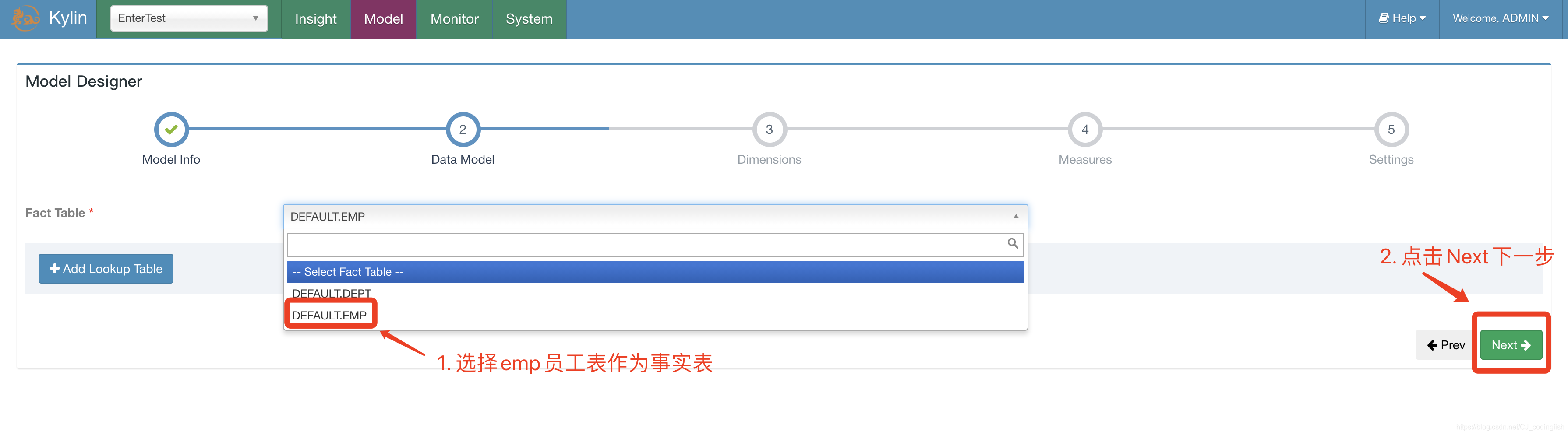
-
選擇新增的維度表及JOIN的欄位
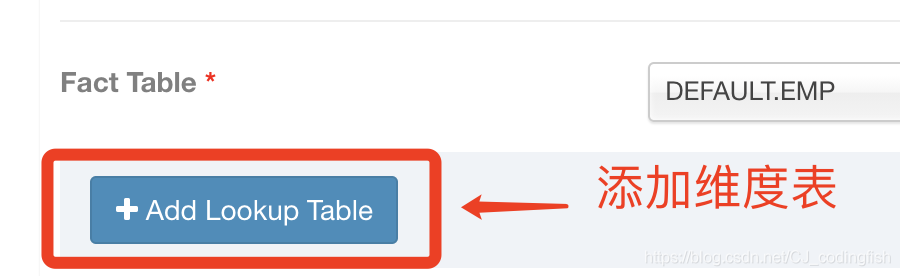
-
選擇新增的維度表和JOIN的欄位
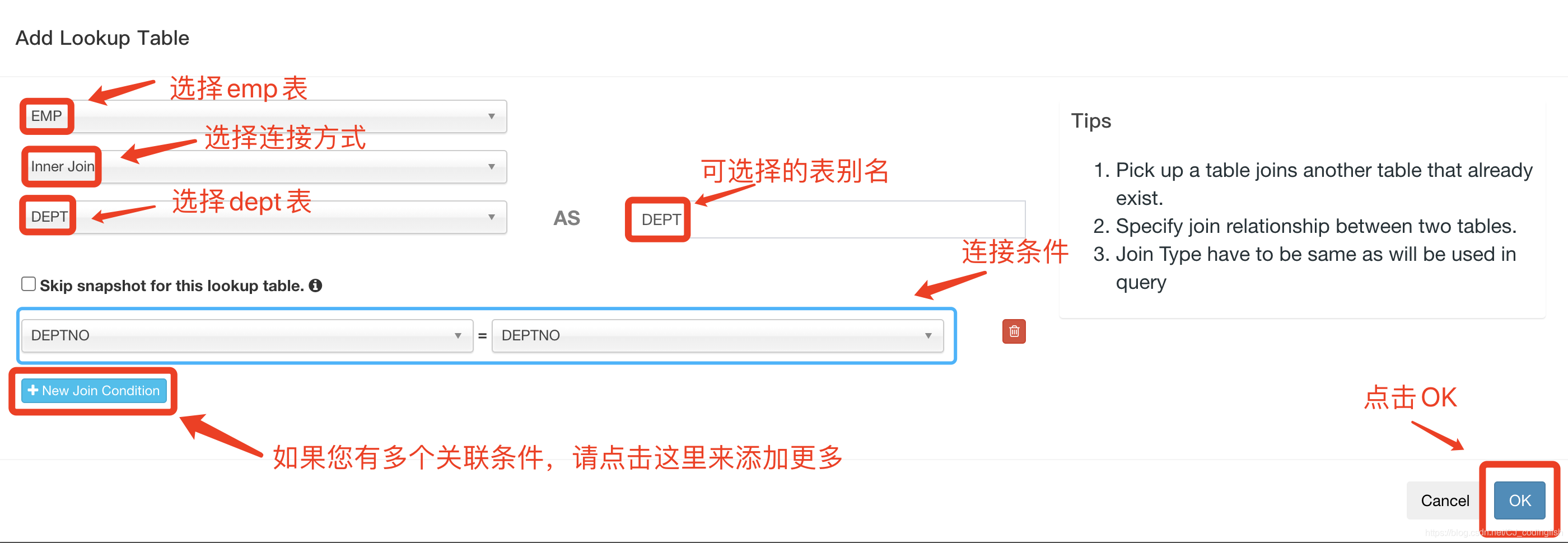
-
選擇維度資訊
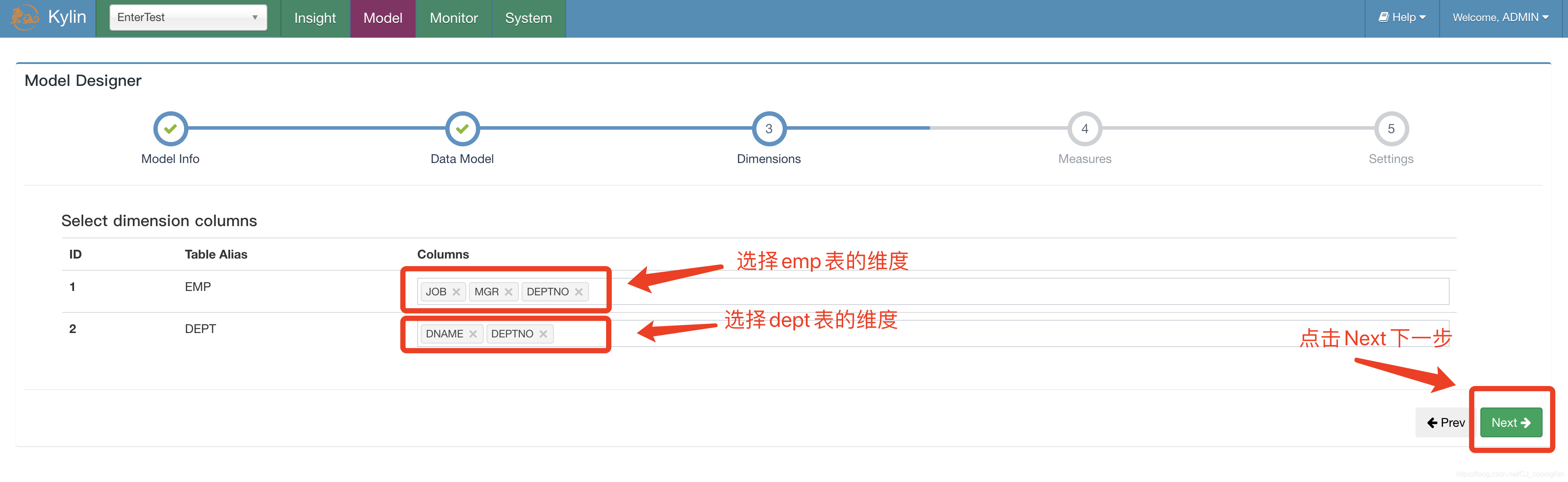
-
選擇度量資訊
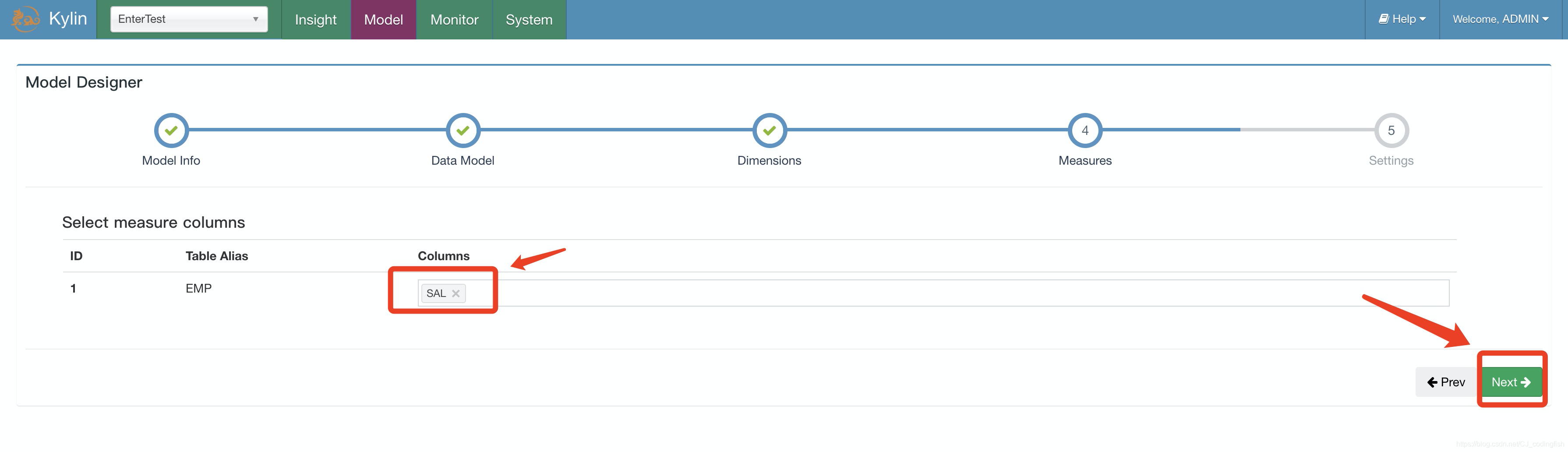
-
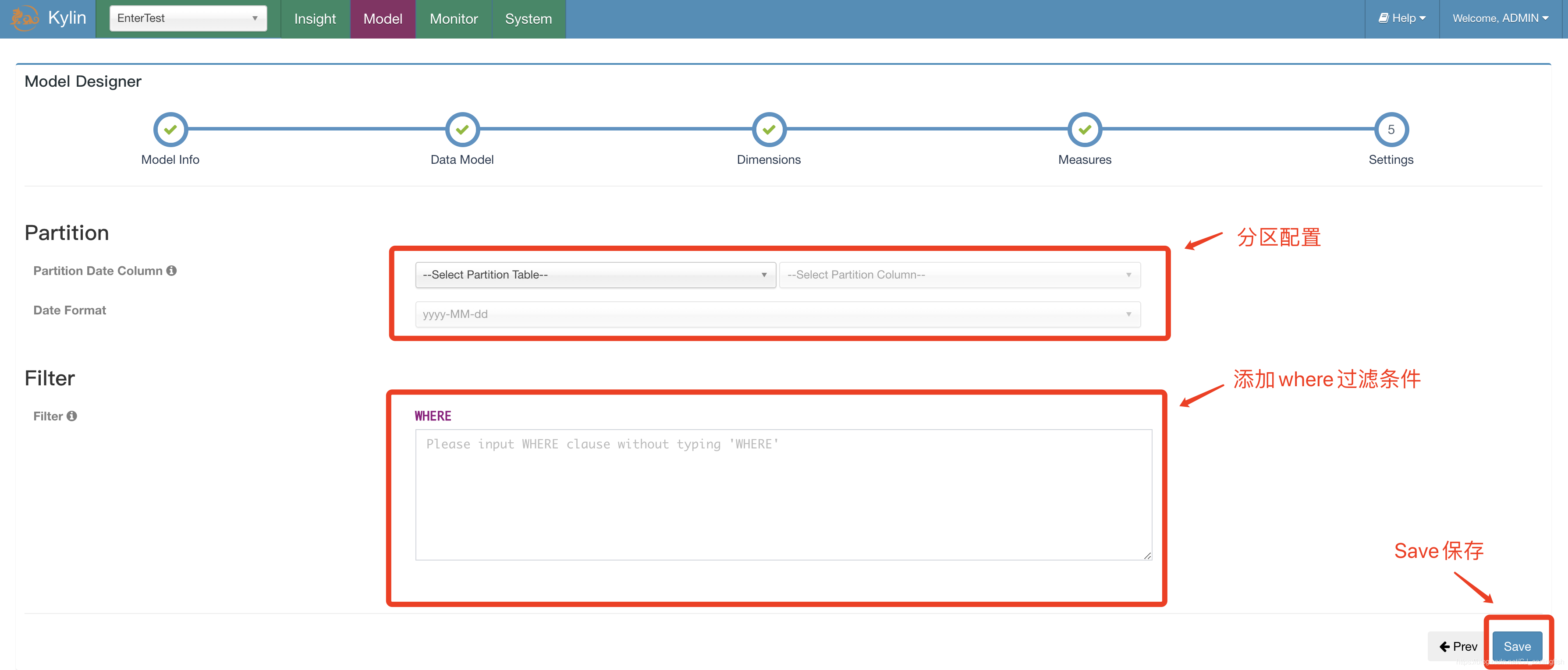
新增分割區資訊及where過濾條件,點選Save
-
ModelOne建立完成
-
-
建立Cube
-
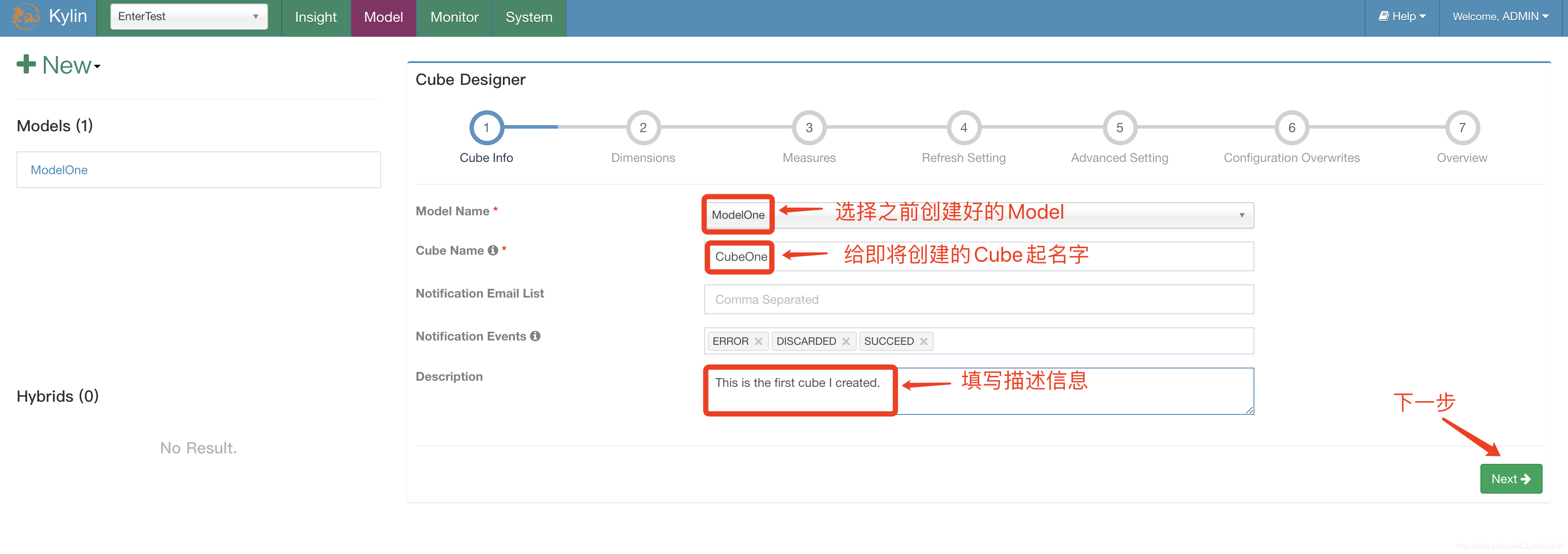
選擇Model -> New Cube,選擇我們剛剛建立的ModelOne並填寫Cube Name
-
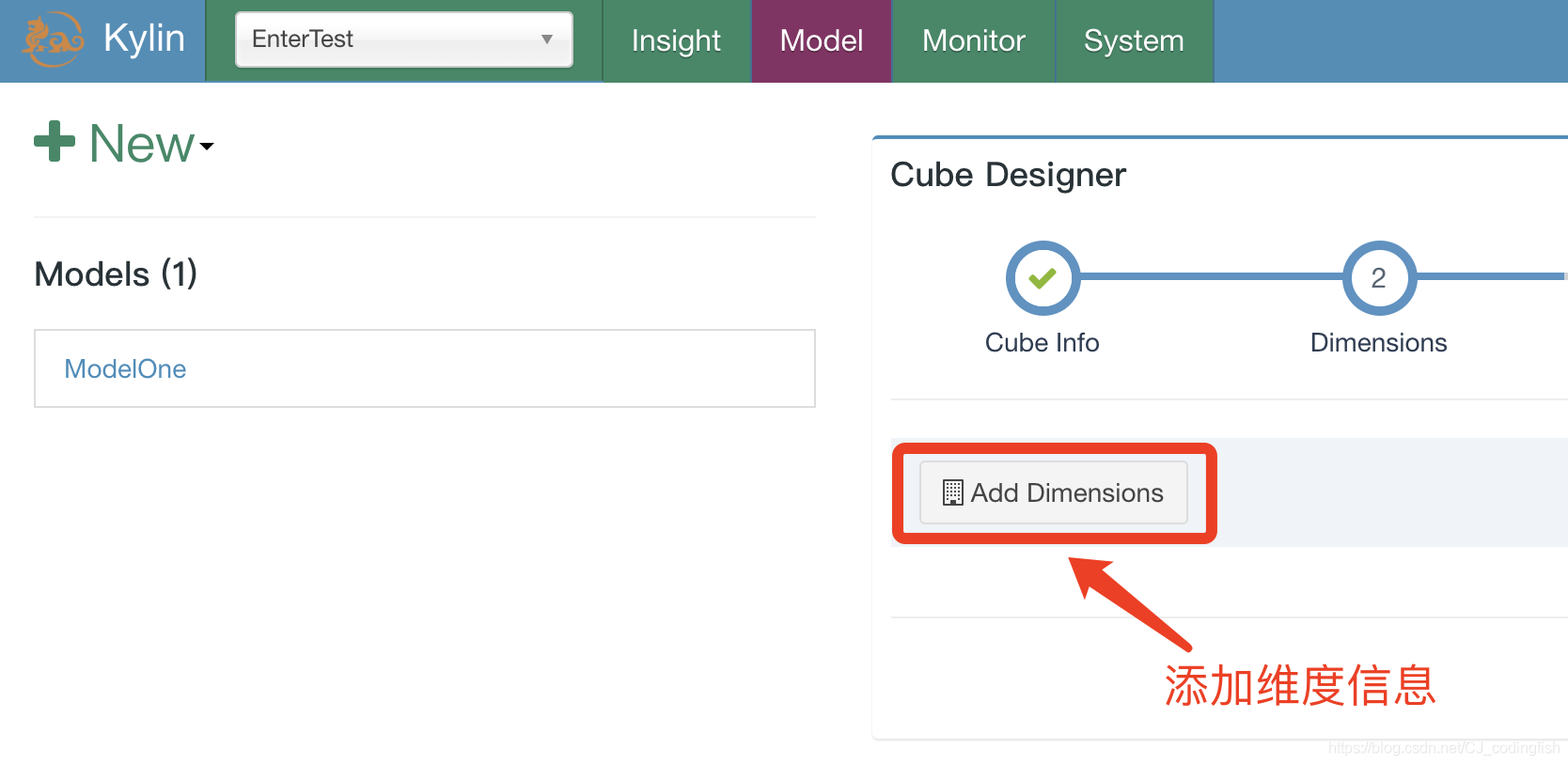
新增維度
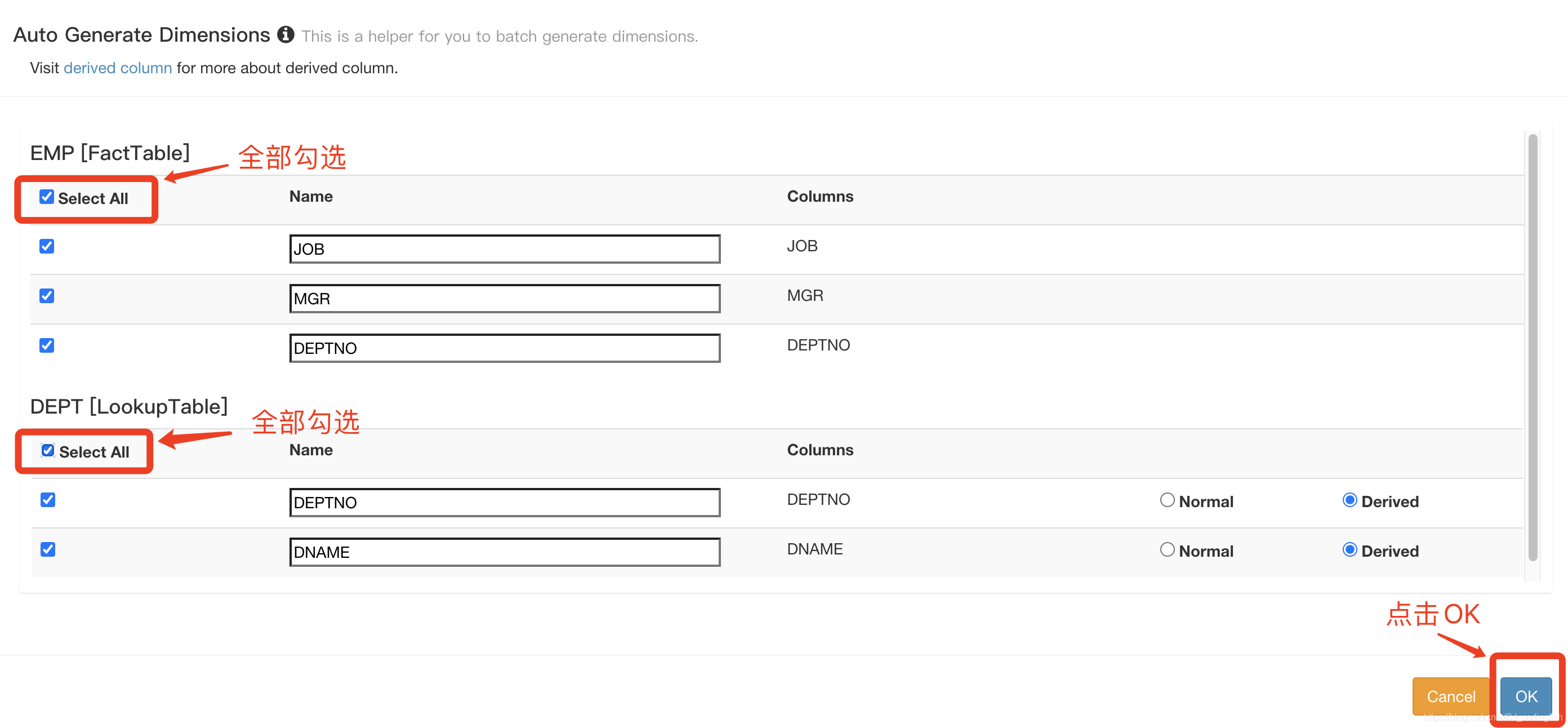
-
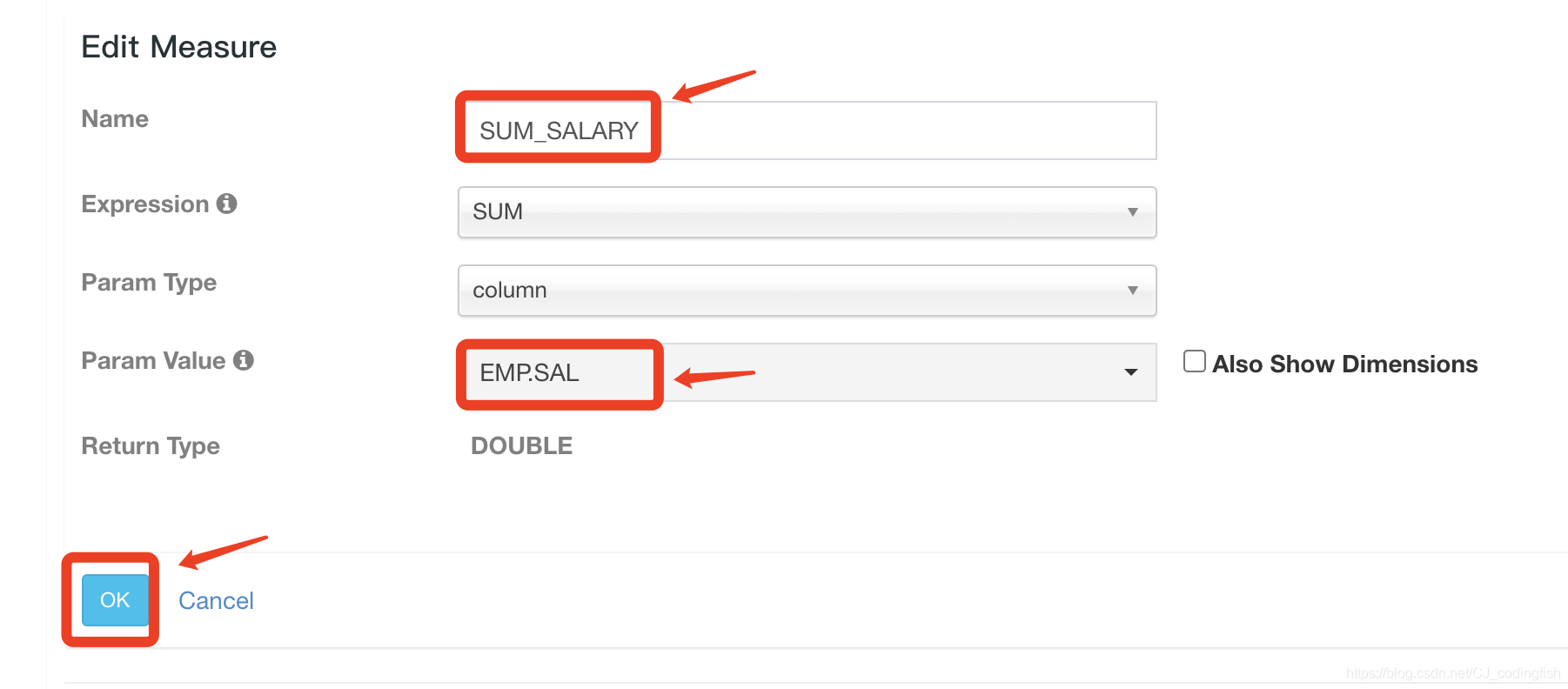
新增預計算內容
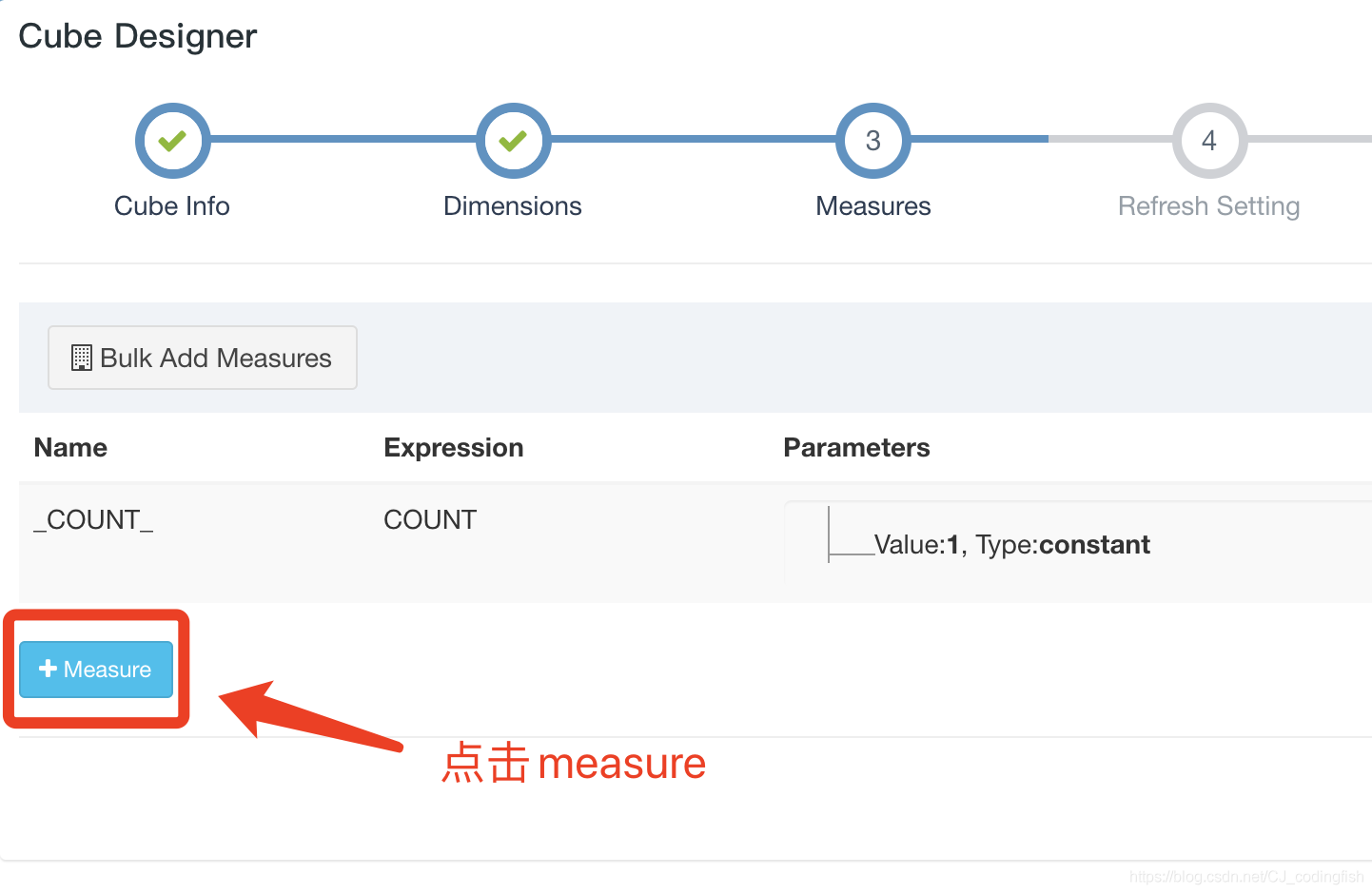
-
-
- 建立好的Cube資訊展
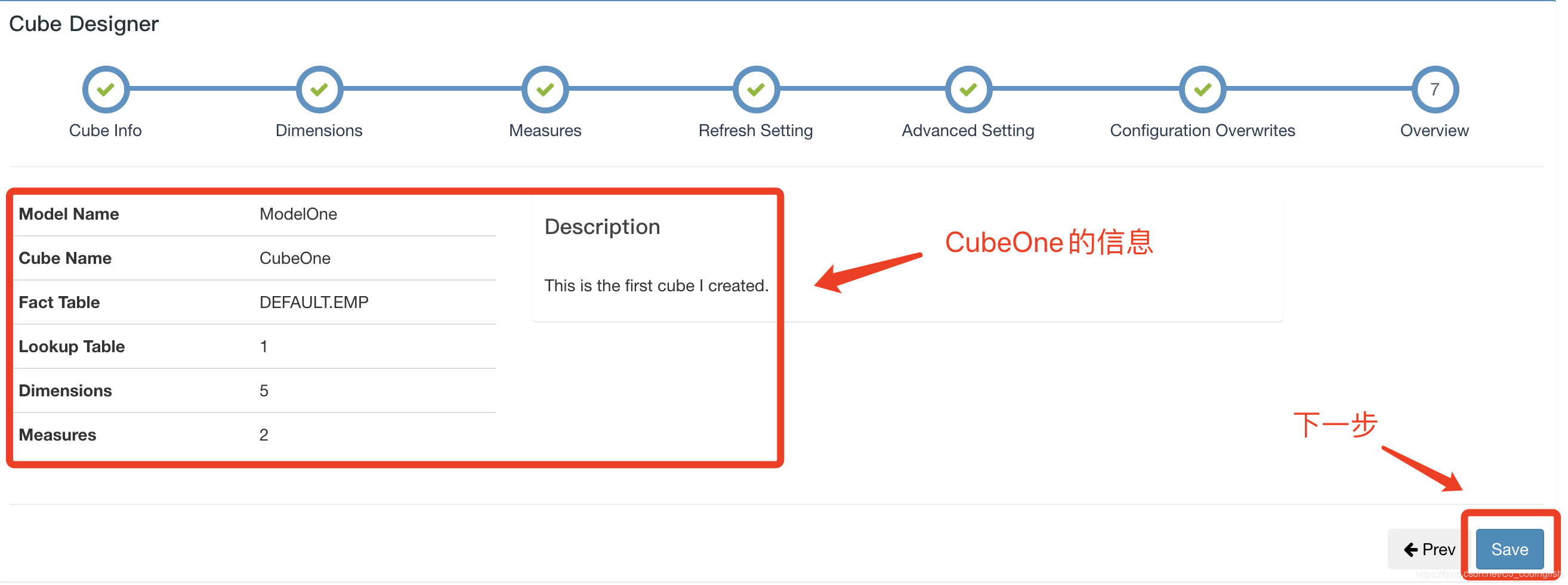
- 到此為止,我們的CubeOne設定完成
-
觸發Cube預計算
-
點選
Action->Build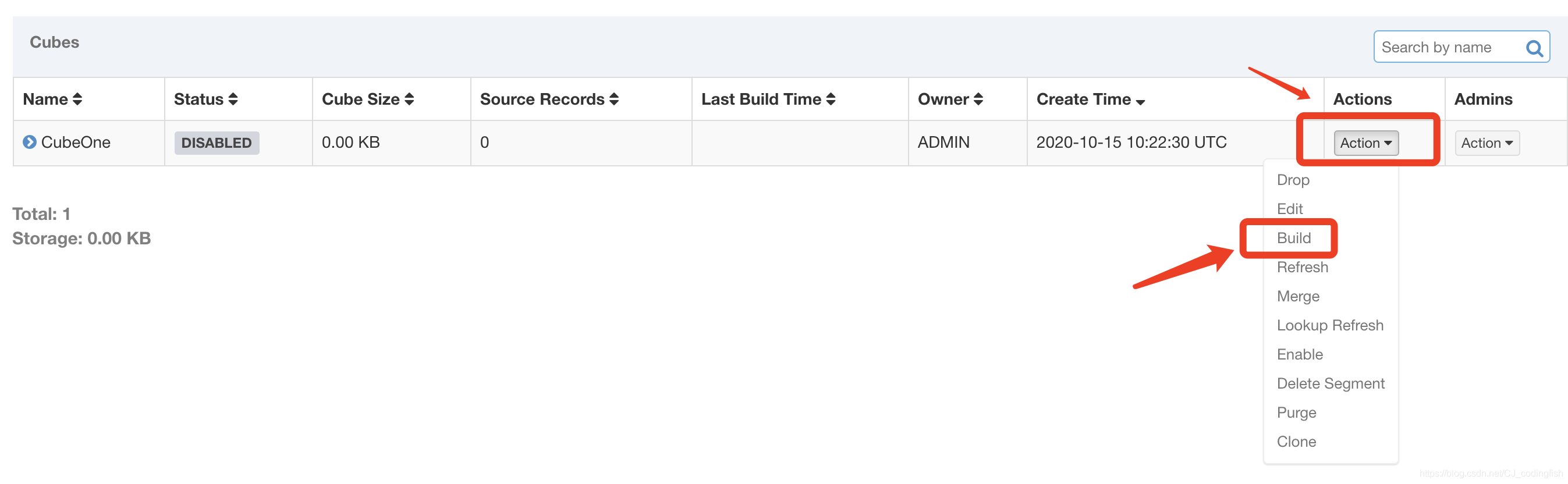
-
檢視構建進度
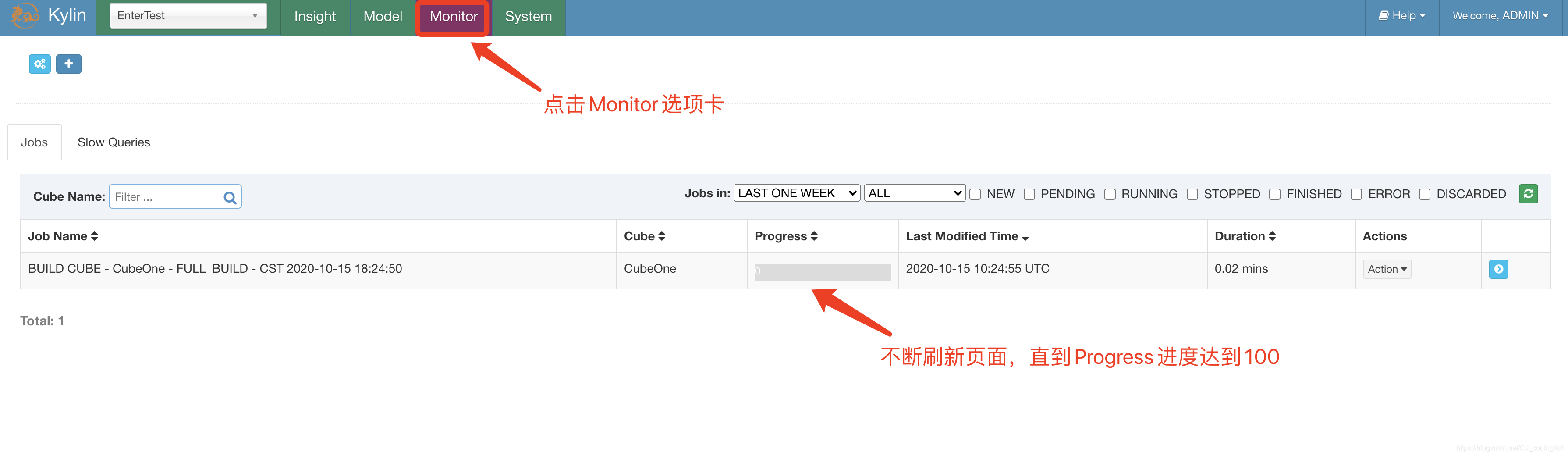
-
Cube構建完成
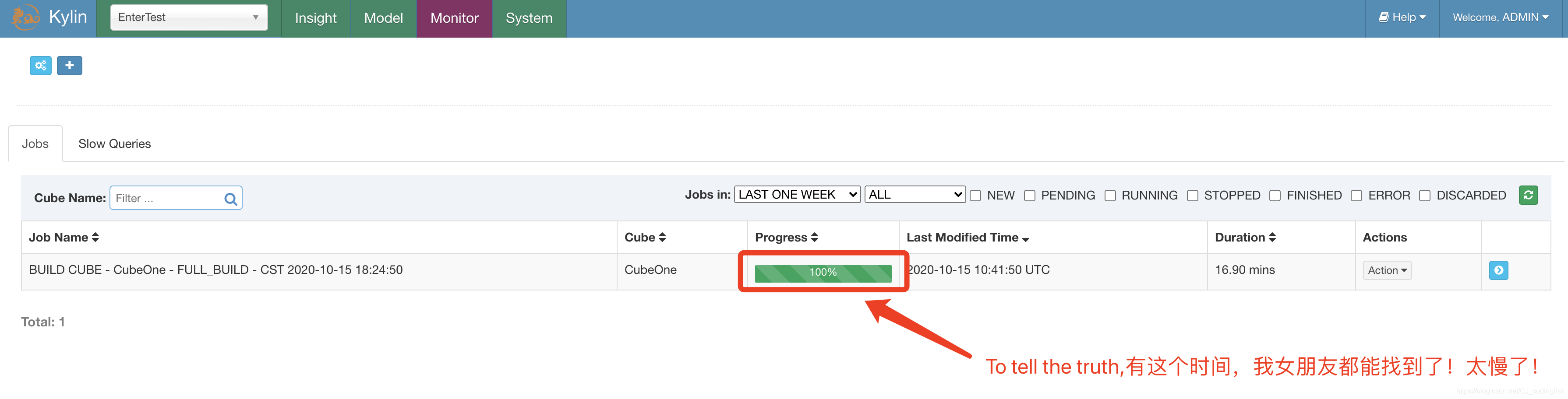
-
-
對比Kylin和Hive
-
Hive查詢
# 需求:根據部門名稱統計員工薪水總數 # 進入到Hive的Shell埠 bin/hive # 鍵入下面的語句 select dname,sum(sal) from emp e join dept d on e.deptno = d.deptno group by dname;查詢時間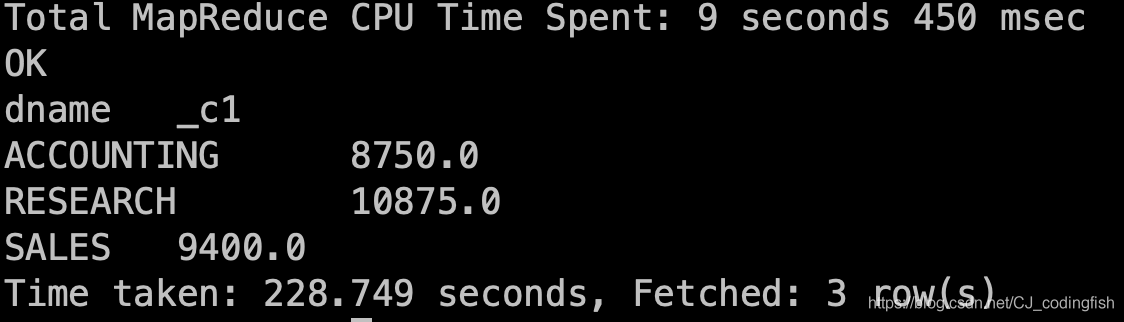
-
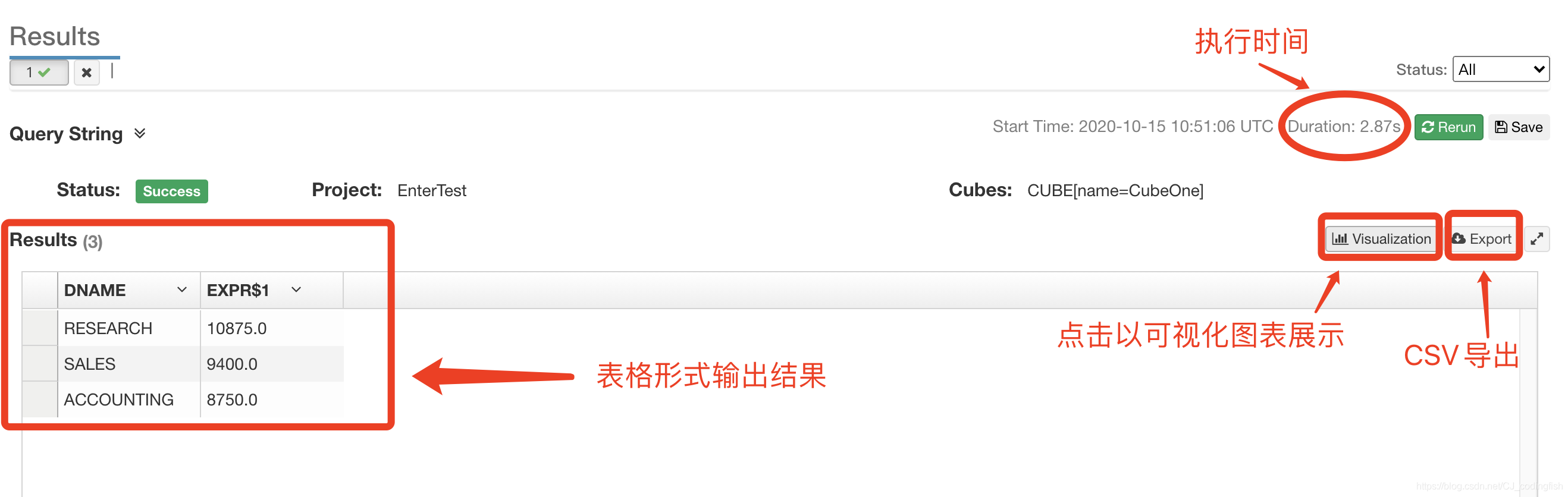
Kylin查詢
進入Insight頁面,輸入SQL語句,點選Sumbit來提交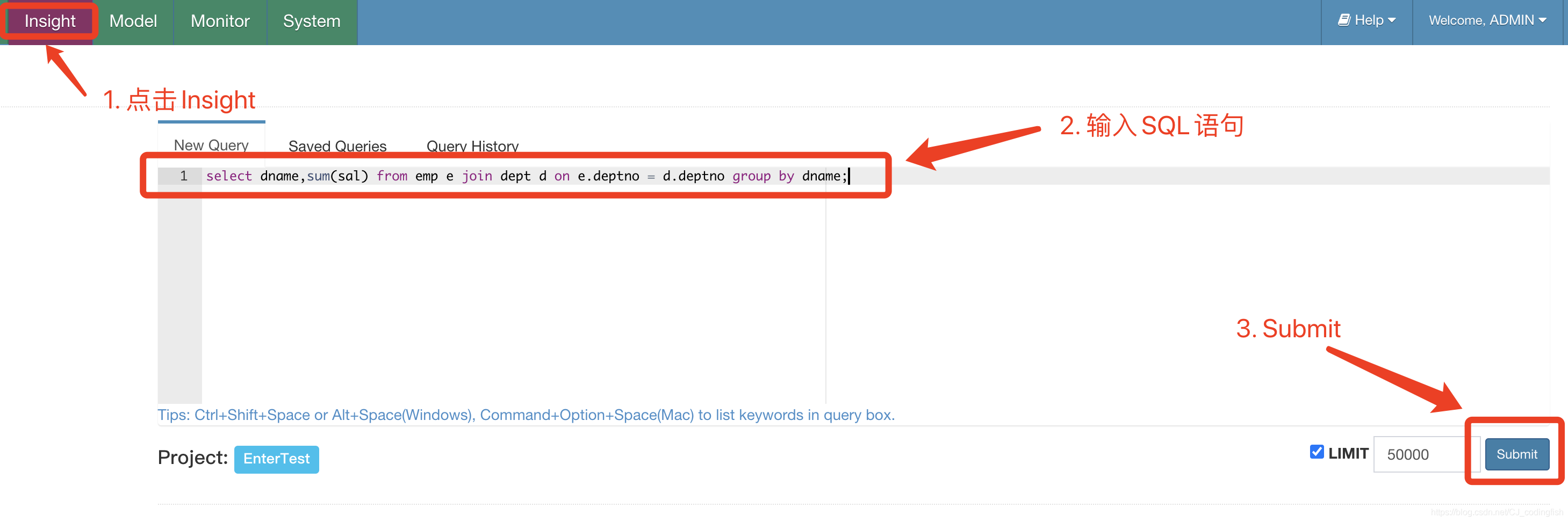
-