分析redis原理及實現
1 什麼是redis
redis是nosql(也是個巨大的map) 單執行緒,但是可處理1秒10w的並行(資料都在記憶體中)
使用java對redis進行操作類似jdbc介面標準對mysql,有各類實現他的實現類,我們常用的是druid
其中對redis,我們通常用Jedis(也為我們提供了連線池JedisPool)
在redis中,key就是byte[](string)
redis的資料結構(value):
String,list,set,orderset,hash
2 redis的使用
先安裝好redis,然後執行,在pom檔案中引入依賴,在要使用redis快取的類的mapper.xml檔案設定redis的全限定名。引入redis的redis.properties檔案(如果要更改設定就可以使用)
應用場景:
String :
1儲存json型別物件,2計數器,3優酷視訊點贊等
list(雙向連結串列)
1可以使用redis的list模擬佇列,堆,棧
2朋友圈點贊(一條朋友圈內容語句,若干點讚語句)
規定:朋友圈內容的格式:
1,內容: user:x:post:x content來儲存;
2,點贊: post:x:good list來儲存;(把相應頭像取出來顯示)
hash(hashmap)
1儲存物件
2分組
3 string與hash的資料差別
在網路傳輸時候,必須要進行進行序列化,才可以進行網路傳輸,那麼在使用string型別的型別的時候需要進行相關序列化,hash也是要進行相關的系列化,所以會存在很多序列化,在儲存的時候hash是可以儲存的更加豐富,但是在反序列化的時候,string的反序列化相對較低,而hash的序列化和返序列化是相對hash類更加複雜,所以看業務場景,如果是資料經常修改的那種,為了效能可以使用string,如果是資料不是經常改的那種就可以使用hash,由於hash,儲存資料時比較豐富,可以儲存多種資料型別
4 redis的持久化方式:
能,將記憶體中的資料非同步寫入硬碟中,兩種方式:RDB(預設)和AOF
RDB持久化原理:通過bgsave命令觸發,然後父程序執行fork操作建立子程序,子程序建立RDB檔案,根據父程序記憶體生成臨時快照檔案,完成後對原有檔案進行原子替換(定時一次性將所有資料進行快照生成一份副本儲存在硬碟中)
優點:是一個緊湊壓縮的二進位制檔案,Redis載入RDB恢復資料遠遠快於AOF的方式。
缺點:由於每次生成RDB開銷較大,非實時持久化,
AOF持久化原理:開啟後,Redis每執行一個修改資料的命令,都會把這個命令新增到AOF檔案中。
優點:實時持久化。
缺點:所以AOF檔案體積逐漸變大,需要定期執行重寫操作來降低檔案體積,載入慢
5 redis單執行緒為什麼這麼快
redis是單執行緒的,但是為什麼還是這麼快呢,
原因1: 單執行緒,避免執行緒之間的競爭
原因2 :是記憶體中的,使用記憶體的,可以減少磁碟的io
原因3:多路複用模型,用了緩衝區的概念,selector模型來進行的
6 redis主掛了怎麼操作
redis提供了哨兵模式,當主掛了,可以選舉其他的進行代替,哨兵模式的實現原理,就是三個定時任務監控,
6.1 每隔10s,每個S節點(哨兵節點)會向主節點和從節點傳送info命令獲取最新的拓撲結構
6.2 每隔2s,每個S節點會向某頻道上傳送該S節點對於主節點的判斷以及當前Sl節點的資訊,
同時每個Sentinel節點也會訂閱該頻道,來了解其他S節點以及它們對主節點的判斷(做客觀下線依據)
6.3 每隔1s,每個S節點會向主節點、從節點、其餘S節點傳送一條ping命令做一次心跳檢測(心跳檢測機制),來確認這些節點當前是否可達
當三次心跳檢測之後,就會進行投票,當超過半數以上的時候就會將該節點當做主
7 redis叢集
redis叢集在3.0以後提供了ruby指令碼進行搭建,引入了糙的概念,
Redis叢集內節點通過ping/pong訊息實現節點通訊,訊息不但可以傳播節點槽資訊,還可以傳播其他狀態如:主從狀態、節點故障等。因此故障發現也是通過訊息傳播機制實現的,主要環節包括:主觀下線(pfail)和客觀下線(fail)
主客觀下線:
主觀下線:叢集中每個節點都會定期向其他節點傳送ping訊息,接收節點回復pong訊息作為響應。如果通訊一直失敗,則傳送節點會把接收節點標記為主觀下線(pfail)狀態。
客觀下線:超過半數,對該主節點做客觀下線
主節點選舉出某一主節點作為領導者,來進行故障轉移。
故障轉移(選舉從節點作為新主節點)
8 記憶體淘汰策略
Redis的記憶體淘汰策略是指在Redis的用於快取的記憶體不足時,怎麼處理需要新寫入且需要申請額外空間的資料。
noeviction:當記憶體不足以容納新寫入資料時,新寫入操作會報錯。
allkeys-lru:當記憶體不足以容納新寫入資料時,在鍵空間中,移除最近最少使用的key。
allkeys-random:當記憶體不足以容納新寫入資料時,在鍵空間中,隨機移除某個key。
volatile-lru:當記憶體不足以容納新寫入資料時,在設定了過期時間的鍵空間中,移除最近最少使用的key。
volatile-random:當記憶體不足以容納新寫入資料時,在設定了過期時間的鍵空間中,隨機移除某個key。
volatile-ttl:當記憶體不足以容納新寫入資料時,在設定了過期時間的鍵空間中,有更早過期時間的key優先移除。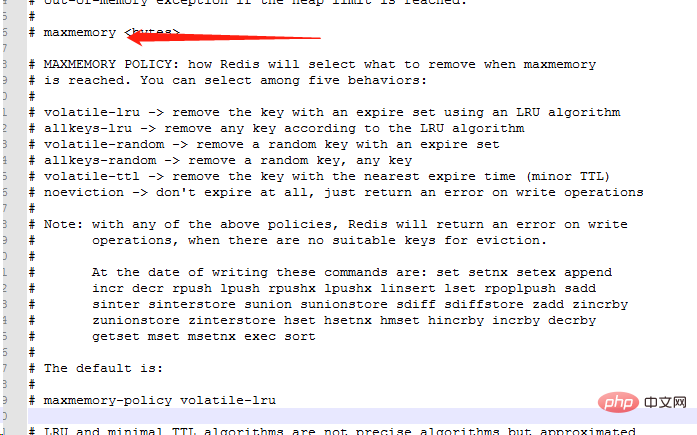
9 快取擊穿的解決方案:
原因:就是別人請求資料的時候,很多資料在快取中無法查詢到,直接進入資料查詢,
解決方法,對相關資料進行查詢的資料只查詢快取,如果是一些特殊的可以進行資料庫查詢,
也可以採用布隆過濾器進行查詢
10快取雪崩的解決方案:
快取雪崩的原因:一次性加入快取的資料過多,導致記憶體過高,從而影響記憶體的使用導致服務宕機
解決方法:
1 redis叢集,通過叢集方式將資料放置
2 後端服務降級和限流:當一個介面請求次數過多,那麼就會新增過多資料,可以對服務進行限流,限制存取的數量,這樣就可以減少問題的出現
以上就是分析redis原理及實現的詳細內容,更多請關注TW511.COM其它相關文章!