Python 原始碼分析(九)
Python 的原始碼探索
- 簡言
- _compression 內部類壓縮演演算法
- 優化紀錄檔
1、簡言
Hello
又見面了,朋友們,人們總是會在滿足期待以後就失去它。這次看看壓縮演演算法的邏輯構造,談不上深入,希望對大家也有幫助。
2、_compression 內部類壓縮演演算法
演演算法
_compression 這個 .py 檔案有個首行註釋:gzip,lzma 和 bz2 模組使用的內部類,該檔案有兩個類, BaseStream(基本流)和 DecompressReader(解壓縮器)。
① BaseStream 類:
class BaseStream(io.BufferedIOBase):
"""Mode-checking helper functions."""
def _check_not_closed(self):
if self.closed:
raise ValueError("I/O operation on closed file")
def _check_can_read(self):
if not self.readable():
raise io.UnsupportedOperation("File not open for reading")
def _check_can_write(self):
if not self.writable():
raise io.UnsupportedOperation("File not open for writing")
def _check_can_seek(self):
if not self.readable():
raise io.UnsupportedOperation("Seeking is only supported "
"on files open for reading")
if not self.seekable():
raise io.UnsupportedOperation("The underlying file object "
"does not support seeking")
–
類檔註釋:模型檢查助手功能。
該類繼承 io 的 BufferedIOBase。
四個方法:檢查未關閉的,檢查可以開啟的,檢查可以讀寫的,檢查可以識別的。
= 檢查未關閉的:函數引數是預設的 self,程式碼塊內是一個 if 判斷,當出現 self.closed 這個條件,使用 raise 關鍵字丟擲異常資訊。異常型別為 ValueError,型別錯誤。丟擲資訊為:關閉檔案的I / O操作。如果在 python 直譯器直接執行該語句,如下: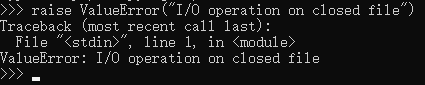
= 檢查可以開啟的:程式碼塊內是一個 if not 判斷,如果沒有觸發 self.readable() 函數,則使用 raise 語句丟擲,丟擲資訊為【檔案未開啟以供讀取】,測試如下:
= 後面兩個以此類推,丟擲資訊為【檔案無法開啟以進行寫入】、【僅在開啟以供讀取的檔案上支援搜尋】、【基礎檔案物件不支援查詢】,由此可見,BaseStream 類為(解)壓縮物件提供了容錯,並處理了可能會出現的異常。
② DecompressReader 類: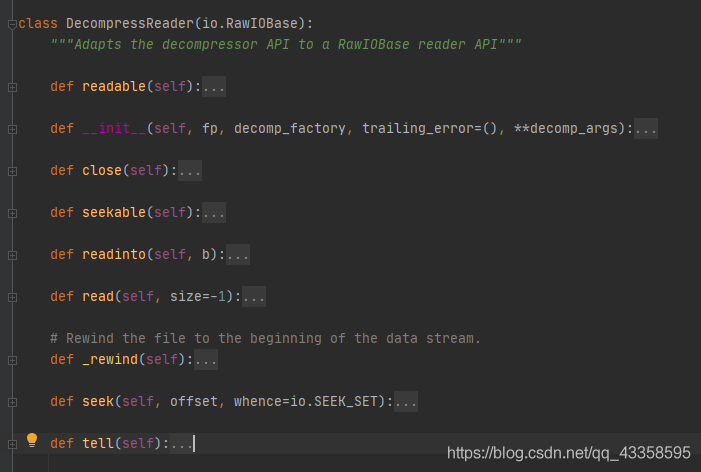
類檔註釋:使解壓縮器 API 適應 RawIOBase 閱讀器 API。
該類繼承自 io 的 RawIOBase。
九個方法:可讀的,屬性,close 方法,可識別的,讀取,read 方法,回溯,seek 方法,返回。
= 可讀的:該方法有且僅有一個返回,return True。
def readable(self):
return True
–
= 屬性:定義類的屬性,可傳入引數有 fp,decomp_factory,trailing_error=(),**decomp_args,定義了八個屬性,如下:
def __init__(self, fp, decomp_factory, trailing_error=(), **decomp_args):
self._fp = fp
self._eof = False
self._pos = 0 # 減壓縮流中的當前偏移
# 知道解壓縮後的流的大小,設定為 SEEK_END
self._size = -1
# 儲存解壓縮器工廠和引數。
# 如果檔案包含多個壓縮流,則每個
# 流將需要一個單獨的解壓縮器物件,新的解壓縮器
# 實現向後的 seek() 時也需要物件。
self._decomp_factory = decomp_factory
self._decomp_args = decomp_args
self._decompressor = self._decomp_factory(**self._decomp_args)
# 從解壓縮器捕獲的異常類表示無效
# 尾隨資料要忽略
self._trailing_error = trailing_error
–
= close 方法:使用 self._decompressor = None 對 _decompressor 物件重新賦值為 None,然後返回 super().close() 方法。
def close(self):
self._decompressor = None
return super().close()
–
= 可識別的:返回 self._fp.seekable() 方法。
def seekable(self):
return self._fp.seekable()
–
= 讀取:使用 with…as… 讀取物件,這裡用到的技巧是我之前也沒見過的,就是【with memoryview(b) as view, view.cast(「B」) as byte_view:】裡面,先是讀取 memoryview(b) 然後傳給 view,然後使用逗號隔開,繼續執行 with 方法,讀取 view.cast(「B」) 然後傳給 byte_view,with 程式碼塊內【data = self.read(len(byte_view))】中,使用 len 方法計算出 byte_view 的檔案長度,然後呼叫 read 方法處理,最後賦值給 data。接著【byte_view[:len(data)] = data】將 byte_view 中直到 len(data) 個元素修改為,也就是重新賦值為 data,最後返回 len(data)。
def readinto(self, b):
with memoryview(b) as view, view.cast("B") as byte_view:
data = self.read(len(byte_view))
byte_view[:len(data)] = data
return len(data)
–
= read 方法:設定預設引數 size=-1,如果該引數小於 0,返回 self.readall(),如果沒有 size 或是 self._eof,返回由 b"" 格式化後的字元,如果遇到 EOF,則為預設值,將 data 的值賦值為 None,根據輸入資料,我們對解壓縮器的呼叫可能不會返回任何資料,在這種情況下,讀取另一個塊後再試一次,所以執行 while 語句。
def read(self, size=-1):
if size < 0:
return self.readall()
if not size or self._eof:
return b""
data = None # Default if EOF is encountered
# Depending on the input data, our call to the decompressor may not
# return any data. In this case, try again after reading another block.
while True:
if self._decompressor.eof:
rawblock = (self._decompressor.unused_data or
self._fp.read(BUFFER_SIZE))
if not rawblock:
break
# Continue to next stream.
self._decompressor = self._decomp_factory(
**self._decomp_args)
try:
data = self._decompressor.decompress(rawblock, size)
except self._trailing_error:
# Trailing data isn't a valid compressed stream; ignore it.
break
else:
if self._decompressor.needs_input:
rawblock = self._fp.read(BUFFER_SIZE)
if not rawblock:
raise EOFError("Compressed file ended before the "
"end-of-stream marker was reached")
else:
rawblock = b""
data = self._decompressor.decompress(rawblock, size)
if data:
break
if not data:
self._eof = True
self._size = self._pos
return b""
self._pos += len(data)
return data
–
使用 while True 形成自迴圈,迴圈開始,先判斷如果 self._decompressor.eof 成立,則【rawblock = (self._decompressor.unused_data or self._fp.read(BUFFER_SIZE))】,這行程式碼是給 rawblock 賦值很容易看出來,但用的小括號和 or 我也沒見過,經過測試,如下: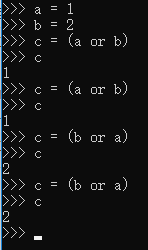
由此可見,只會賦值 or 之前的值,所以該行程式碼經過 python 直譯器執行後,rawblock 的值應該是 _decompressor 的 unused_data,該語句執行後,有一個巢狀在同級的 if not 判斷,作為結束 while 迴圈的條件,條件為 if not rawblock,如果沒有執行,就繼續執行下一個流,因為結構相對複雜,所以把這個 while 迴圈單獨拿出來看,如下:
while True:
if self._decompressor.eof:
rawblock = (self._decompressor.unused_data or
self._fp.read(BUFFER_SIZE))
if not rawblock:
break
# 繼續下一個流。
self._decompressor = self._decomp_factory(
**self._decomp_args)
try:
data = self._decompressor.decompress(rawblock, size)
except self._trailing_error:
# 尾隨資料不是有效的壓縮流,忽略它。
break
else:
if self._decompressor.needs_input:
rawblock = self._fp.read(BUFFER_SIZE)
if not rawblock:
raise EOFError("Compressed file ended before the "
"end-of-stream marker was reached") # 壓縮檔案在到達流結束標記之前結束
else:
rawblock = b""
data = self._decompressor.decompress(rawblock, size)
if data:
break
–
可以看到,有很多 if 判斷,甚至巢狀 if,還有 try-except 結構,為了避免混亂,就一個一個分開理解,首先是 while 迴圈的觸發條件,True,當使用該關鍵字作為迴圈執行條件時,可視作條件成立,直接進入迴圈,直到結束條件觸發,這個結束條件在該回圈體系中,一共有三個,該回圈體系第一層巢狀是 if-else-if,if 成立條件是 self._decompressor.eof,否則執行 else 語句塊的程式碼,如果有 data,則立刻結束該 while 迴圈。
= 回溯:將檔案倒帶到資料流的開頭,除了 _fp 呼叫了 seek(),並傳入引數 0,使其回溯,其他三個 _eof、_pos 和 _decompressor 都是用定義屬性時的值賦值,達到回溯目的。
# Rewind the file to the beginning of the data stream.
def _rewind(self):
self._fp.seek(0)
self._eof = False
self._pos = 0
self._decompressor = self._decomp_factory(**self._decomp_args)
–
= seek 方法:重新計算偏移量作為絕對檔案位置,回溯中 _fp 呼叫過的 seek 方法,引數有 offset 和 whence=io.SEEK_SET。
def seek(self, offset, whence=io.SEEK_SET):
# Recalculate offset as an absolute file position.
if whence == io.SEEK_SET:
pass
elif whence == io.SEEK_CUR:
offset = self._pos + offset
elif whence == io.SEEK_END:
# Seeking relative to EOF - we need to know the file's size.
if self._size < 0:
while self.read(io.DEFAULT_BUFFER_SIZE):
pass
offset = self._size + offset
else:
raise ValueError("Invalid value for whence: {}".format(whence))
# Make it so that offset is the number of bytes to skip forward.
if offset < self._pos:
self._rewind()
else:
offset -= self._pos
# Read and discard data until we reach the desired position.
while offset > 0:
data = self.read(min(io.DEFAULT_BUFFER_SIZE, offset))
if not data:
break
offset -= len(data)
return self._pos
–
= 返回:返回當前檔案位置,方法裡面直接使用 return 返回 self._pos,就是當前檔案位置。
def tell(self):
"""Return the current file position."""
return self._pos
–
到這裡,基本就是 _compression 檔案的全部內容了,可以知道解壓縮和壓縮的演演算法並不簡單,通過層層的迭代和巢狀,把操作的物件一步一步的按邏輯執行,最終得到想要的輸出。
3、優化紀錄檔
紀錄檔
2020-10-21,第一次釋出。
感謝 CSDN,感謝 C 友們的支援