Numpy中 np.random.rand() 和 np.random.randn() 的用法和區別
2020-10-22 15:00:46
參考:
- numpy.random.rand(d0, d1, …, dn)的隨機樣本位於[0, 1)中:本函數可以返回一個或一組服從**「0~1」均勻分佈**的隨機樣本值。
- numpy.random.randn(d0, d1, …, dn)是從標準正態分佈中返回一個或多個樣本值。
1. np.random.rand()
-
語法:
np.random.rand(d0,d1,d2……dn)
注:使用方法與np.random.randn()函數相同 -
作用:
通過本函數可以返回一個或一組服從「0~1」均勻分佈的隨機樣本值。隨機樣本取值範圍是[0,1),不包括1。 -
應用:在深度學習的Dropout正則化方法中,可以用於生成dropout隨機向量(dl),
例如(keep_prob表示保留神經元的比例):
dl = np.random.rand(al.shape[0],al.shape[1]) < keep_prob
-
舉例:
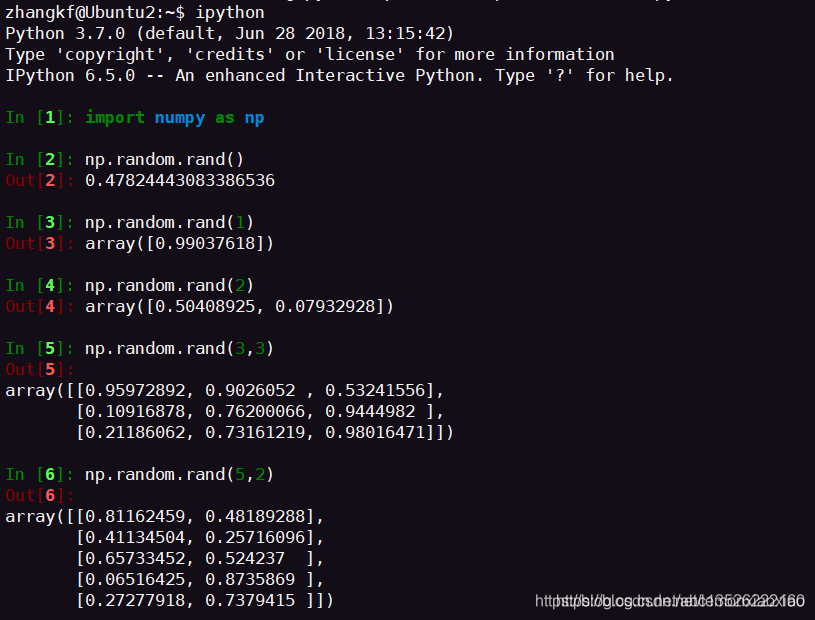
-
注:
均勻分佈:
也叫矩形分佈,它是對稱概率分佈,在相同長度間隔的分佈概率是等可能的。
均勻分佈由兩個引數a和b定義,它們是數軸上的最小值和最大值,通常縮寫為U(a,b)。
均勻分佈的概率密度函數為:
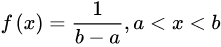
2. np.random.randn()
- 語法:
np.random.randn(d0,d1,d2……dn)
1)當函數括號內沒有引數時,則返回一個浮點數;
2)當函數括號內有一個引數時,則返回秩為1的陣列,不能表示向量和矩陣;
3)當函數括號內有兩個及以上引數時,則返回對應維度的陣列,能表示向量或矩陣;
4)np.random.standard_normal()函數與np.random.randn()類似,但是np.random.standard_normal()的輸入引數為元組(tuple)。
# 舉例:
np.random.standard_normal((5))
# [-0.53268495 0.30171848 1.85232368 -0.58746393 0.19683992]
np.random.standard_normal((5,2))
'''
[[-2.44520524 2.29767001]
[-1.19770033 -1.09569325]
[-0.75414833 0.49509984]
[-1.42537268 0.41788237]
[ 1.85465491 -1.44383249]]
'''
np.random.standard_normal((5,2,3))
'''
[[[ 0.54013502 -0.25347615 1.73395647]
[ 1.03386947 -0.54856199 2.10004584]]
[[-0.57632903 -0.05856844 1.72805595]
[ 1.3507174 0.61459539 0.63380028]]
[[-2.24857933 -1.29276097 0.42585061]
[ 0.75974263 -0.83670586 -1.56930898]]
[[-0.32212 1.2884624 1.53744081]
[ 1.5444555 -1.82408734 -0.55952688]]
[[-1.21191144 -1.40454518 -0.3369976 ]
[-0.89314143 0.28291988 1.58394166]]]
'''
np.random.standard_normal((5,2,3,1))
'''
[[[[ 0.19019221]
[ 0.64618425]
[ 0.99815722]]
[[-0.0570328 ]
[ 0.83271045]
[-0.30469335]]]
[[[-1.14788388]
[ 0.09563431]
[ 2.05611213]]
[[-0.14251287]
[ 1.00922816]
[-0.55403104]]]
[[[ 1.75657437]
[ 1.46381575]
[ 1.10527197]]
[[ 0.22667296]
[ 0.18305552]
[ 0.5778761 ]]]
[[[ 0.26501242]
[-0.4863313 ]
[ 1.01096974]]
[[-2.46562874]
[ 0.19516242]
[-1.92500848]]]
[[[ 0.97904566]
[ 0.80444414]
[ 0.99981326]]
[[-0.74329878]
[-0.9265738 ]
[ 0.0288684 ]]]]
'''
5)np.random.randn()的輸入通常為整數,但是如果為浮點數,則會自動直接截斷轉換為整數。
-
作用:通過本函數可以返回一個或一組服從標準正態分佈的隨機樣本值。
-
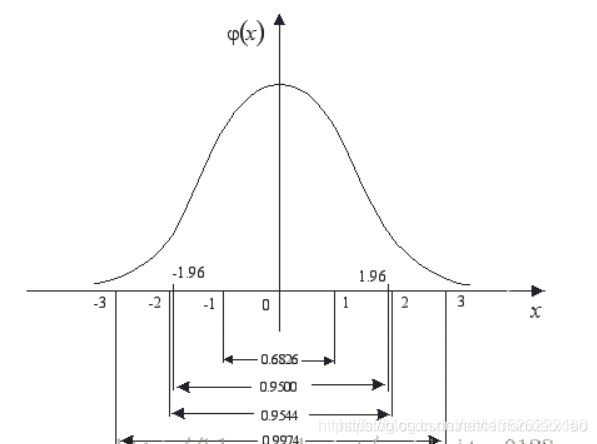
特點: 標準正態分佈是以0為均數、以1為標準差的正態分佈,記為N(0,1)。對應的正態分佈曲線如下所示,即:
-
注:
標準正態分佈曲線下面積分佈規律是:
在-1.96~+1.96範圍內曲線下的面積等於0.9500(即取值在這個範圍的概率為95%),在-2.58~+2.58範圍內曲線下面積為0.9900(即取值在這個範圍的概率為99%).
因此,由 np.random.randn()函數所產生的隨機樣本基本上取值主要在-1.96~+1.96之間,當然也不排除存在較大值的情形,只是概率較小而已。