沃德天,Python竟然還能做實時翻譯
文章目錄
有了它,實現實時翻譯還遠嗎?

歡迎關注我,一塊來履行我之前的承諾,連更一個月之內,把幾篇寫完。
| 序號 | 預計完成時間 | 開發dome名字以及功能&釋出文章內容 | 是否已寫完 | 文章連結 |
|---|---|---|---|---|
| 1 | 9月3 | 文字翻譯,單文字翻譯,批次翻譯demo。 | 已完成 | CSDN:點我直達 微信公眾號:點我直達 |
| 2 | 9月11 | OCR-demo,完成批次上傳識別;在一個demo中可選擇不同型別的OCR識別《包含手寫體/印刷體/身份證/表格/整題/名片),然後呼叫平臺能力,具體實現步驟等。 | 已完成 | CSDN:點我直達 微信公眾號: |
| 3 | 10月27 | 語音識別demo,demo中上傳—段視訊,並擷取視訊中短語音識別-demo的一段音訊進行短語音識別 | CSDN:點我直達 微信公眾號: | |
| 4 | 9月17 | 智慧語音評測-demo | CSDN: 微信公眾號: | |
| 5 | 9月24 | 作文批改-demo | CSDN: 微信公眾號: | |
| 6 | 9月30 | 語音合成-demo | CSDN: 微信公眾號: | |
| 7 | 10月15 | 單題拍搜-demo | CSDN: 微信公眾號: | |
| 8 | 10月20 | 圖片翻譯-demo | CSDN: 微信公眾號: | |
一、還有3秒到達戰場
最近,某水果手機廠在萬眾期待中開了一場沒有釋出萬眾期待的手機產品的釋出會,釋出了除手機外的其他一些產品,也包括最新的水果14系統。幾天後,更新了系統的吃瓜群眾經過把玩突然發現新系統裡一個超有意思的功能——翻譯,比如這種:

奇怪的翻譯知識增加了!
相比常見的翻譯工具,同聲翻譯工具更具有實用價值,想想不精通其他語言就能和歪果朋友無障礙交流的場景,真是一件美事,不如自己動手實現個工具備用!一個同聲翻譯工具,邏輯大概可以是先識別,而後翻譯,翻譯能否成功,識別的準確率是個關鍵因素。為了降低難度,我決定分兩次完成工具開發。首先來實現試試語音識別的部分。
輕車熟路,本次的demo繼續呼叫有道智雲API,實現實時語音識別。
二、效果展示
先看看介面和結果哈:
可以選擇多種語音,這裡只寫了四種常見的:
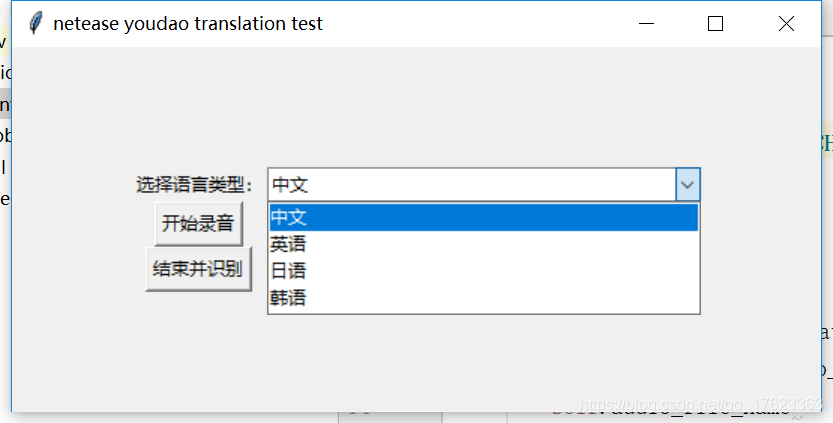
我分別測試的中文、韓文、英文。看著還不錯哦~

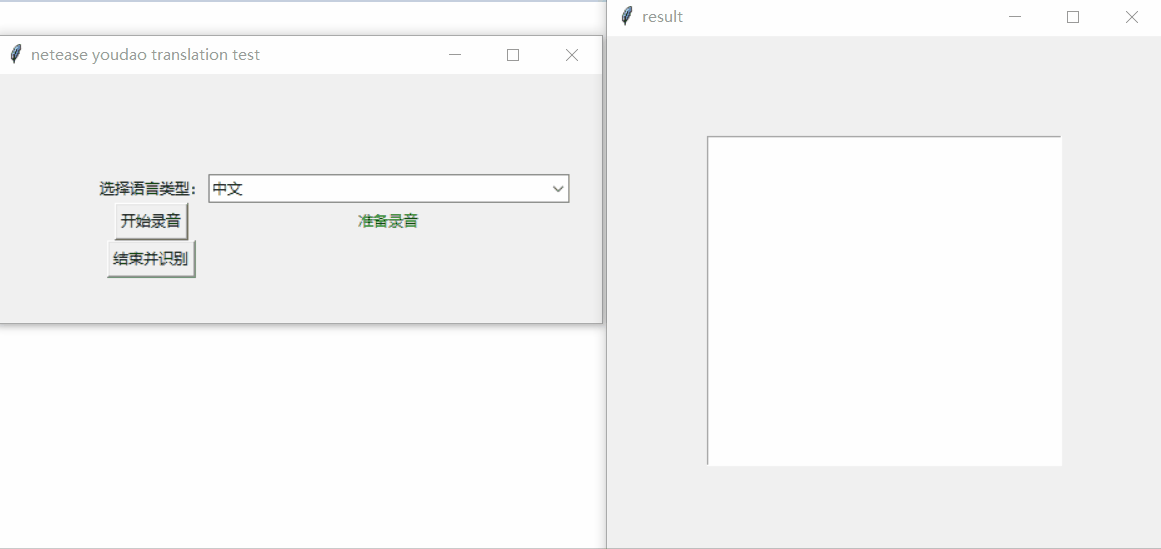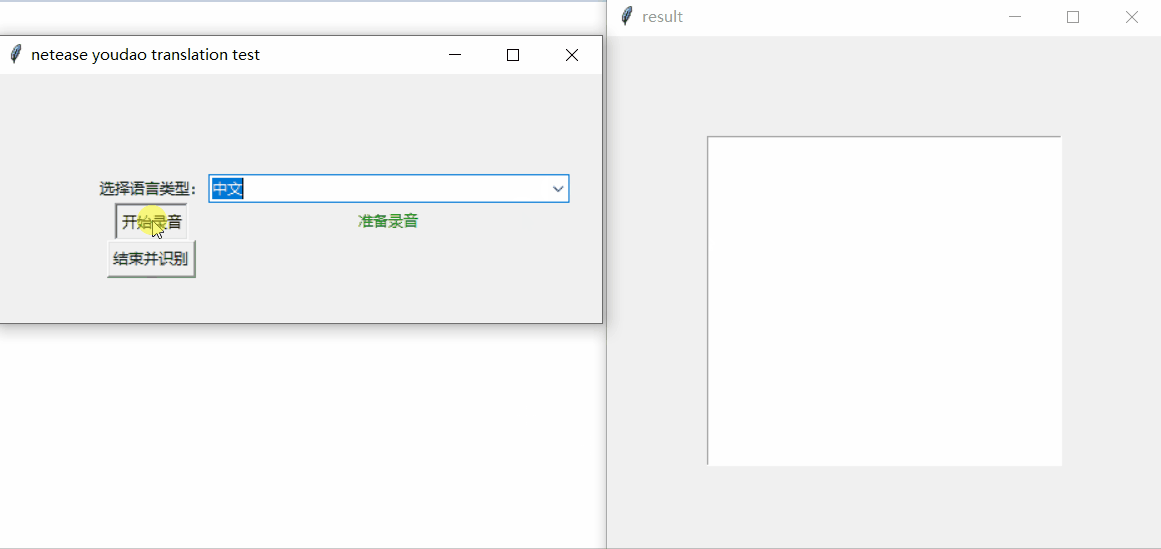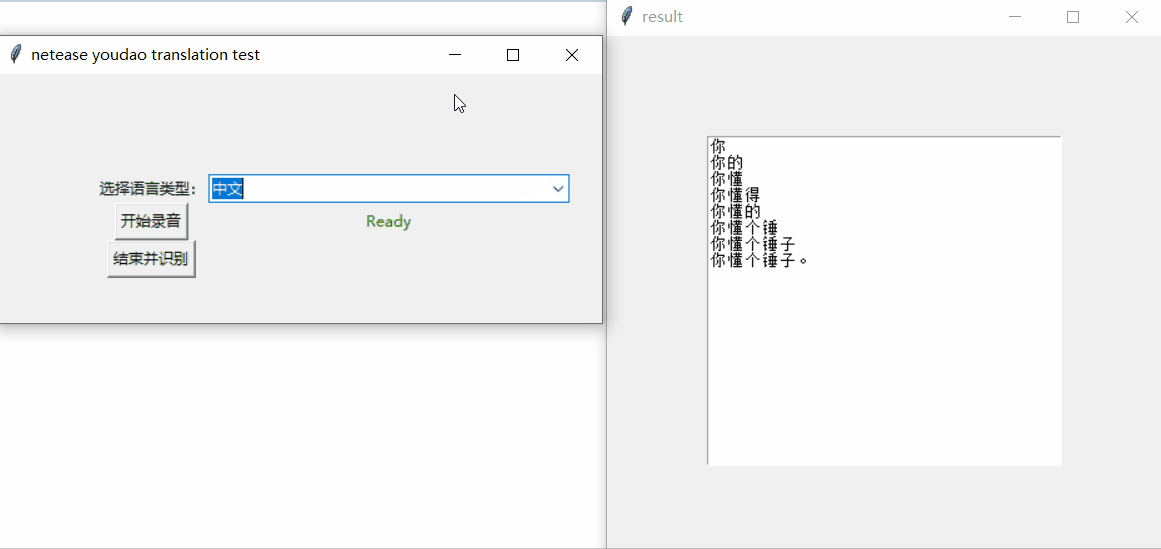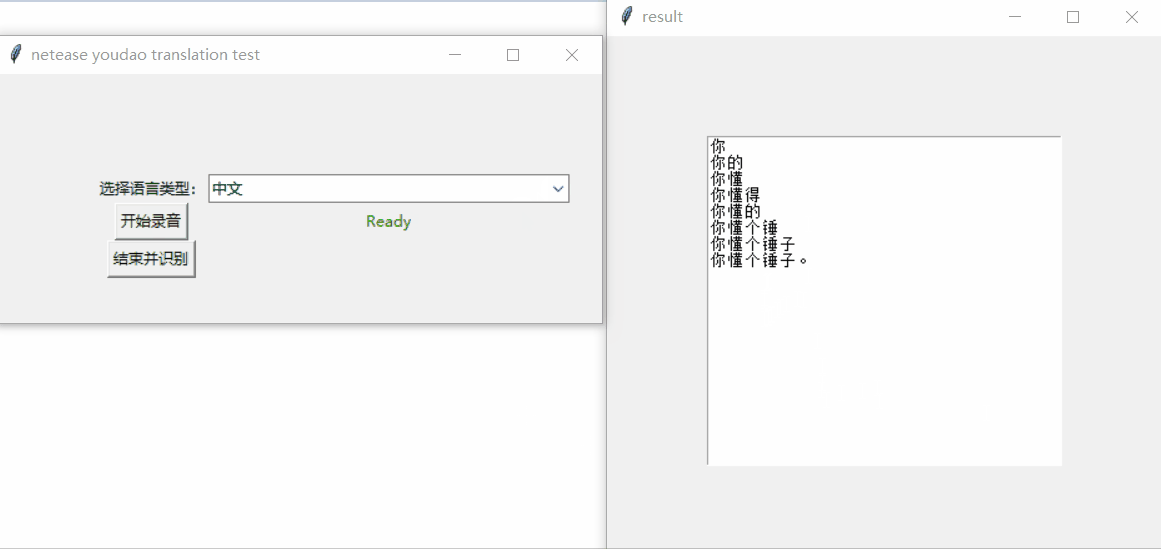
這裡翻譯結果,是根據音訊一個字、一個字這樣實時識別的,由於識別速度比較快,所以看起來木有時間差。
四、呼叫API介面的準備工作
首先,是需要在有道智雲的個人頁面上建立範例、建立應用、繫結應用和範例,獲取呼叫介面用到的應用的id和金鑰。具體個人註冊的過程和應用建立過程詳見文章分享一次批次檔案翻譯的開發過程
五、開發過程詳細介紹
(一)準備工作
下面介紹具體的程式碼開發過程。
首先是根據實時語音識別檔案來分析介面的輸入輸出。介面設計的目的是對連續音訊流的實時識別,轉換成文字資訊並返對應文字流,因此通訊採用websocket,呼叫過程分為認證、實時通訊兩階段。
在認證階段,需傳送以下引數:
| 引數 | 型別 | 必填 | 說明 | 範例 |
|---|---|---|---|---|
| appKey | String | 是 | 已申請的應用ID | ID |
| salt | String | 是 | UUID | UUID |
| curtime | String | 是 | 時間戳(秒) | TimeStamp |
| sign | String | 是 | 加密數位簽章。 | sha256 |
| signType | String | 是 | 數位簽章型別 | v4 |
| langType | String | 是 | 語言選擇,參考支援語言列表 | zh-CHS |
| format | String | 是 | 音訊格式,支援wav | wav |
| channel | String | 是 | 聲道,支援1(單聲道) | 1 |
| version | String | 是 | api版本 | v1 |
| rate | String | 是 | 取樣率 | 16000 |
簽名
sign生成方法如下:
signType=v4;
sign=sha256(應用ID+salt+curtime+應用金鑰)。
認證之後,就進入了實時通訊階段,傳送音訊流,獲取識別結果,最後傳送結束標誌結束通訊,這裡需要注意的是,傳送的音訊最好是16bit位深的單聲道、16k取樣率的清晰的wav音訊檔,這裡我開發時最開始因為音訊錄製裝置有問題,導致音訊效果極差,介面一直返回錯誤碼304(手動捂臉)。
(二)開發
這個demo使用python3開發,包括maindow.py,audioandprocess.py,recobynetease.py三個檔案。介面部分,使用python自帶的tkinter庫,來進行語言選擇、錄音開始、錄音停止並識別的操作。audioandprocess.py實現了錄音、音訊處理的邏輯,最後通過recobynetease.py中的方法來呼叫實時語音識別API。
1、介面部分
主要元素:
root=tk.Tk()
root.title("netease youdao translation test")
frm = tk.Frame(root)
frm.grid(padx='80', pady='80')
label=tk.Label(frm,text='選擇語言型別:')
label.grid(row=0,column=0)
combox=ttk.Combobox(frm,textvariable=tk.StringVar(),width=38)
combox["value"]=lang_type_dict
combox.current(0)
combox.bind("<<ComboboxSelected>>",get_lang_type)
combox.grid(row=0,column=1)
btn_start_rec = tk.Button(frm, text='開始錄音', command=start_rec)
btn_start_rec.grid(row=2, column=0)
lb_Status = tk.Label(frm, text='Ready', anchor='w', fg='green')
lb_Status.grid(row=2,column=1)
btn_sure=tk.Button(frm,text="結束並識別",command=get_result)
btn_sure.grid(row=3,column=0)
root.mainloop()
選擇語言型別之後,開始錄音,錄音結束後,通過get_result()方法呼叫介面進行識別。
def get_result():
lb_Status['text']='Ready'
sr_result=au_model.stop_and_recognise()
2、音訊錄製部分的開發
音訊錄製部分引入pyaudio庫(需通過pip安裝)來呼叫音訊裝置並錄製介面要求的wav檔案,並呼叫wave庫儲存音訊檔。
Audio_model類的構造:
def __init__(self, audio_path, language_type,is_recording):
self.audio_path = audio_path, # 錄音儲存路徑
self.audio_file_name='' # 錄音檔名
self.language_type = language_type, # 錄音語言型別
self.language_dict=["zh-CHS","en","ja","ko"] # 支援的語言,用於從UI出的型別轉為介面所需型別
self.language=''
self.is_recording=is_recording # 錄音狀態
self.audio_chunk_size=1600 # 以下為一些介面所要求的錄音引數,取樣率、編碼、通道等
self.audio_channels=1
self.audio_format=pyaudio.paInt16
self.audio_rate=16000
(2)record()方法的開發
record()方法中實現了錄音的邏輯,呼叫pyaudio庫,讀取音訊流,寫入檔案。
def record(self,file_name):
p=pyaudio.PyAudio()
stream=p.open(
format=self.audio_format,
channels=self.audio_channels,
rate=self.audio_rate,
input=True,
frames_per_buffer=self.audio_chunk_size
)
wf = wave.open(file_name, 'wb')
wf.setnchannels(self.audio_channels)
wf.setsampwidth(p.get_sample_size(self.audio_format))
wf.setframerate(self.audio_rate)
# 讀取資料寫入檔案
while self.is_recording:
data = stream.read(self.audio_chunk_size)
wf.writeframes(data)
wf.close()
stream.stop_stream()
stream.close()
p.terminate()
(3)stop_and_recognise()方法的開發
stop_and_recognise()方法將Audio_model的錄音狀態標記為false,並啟動呼叫有道智雲API的方法。
def stop_and_recognise(self):
self.is_recording=False
recognise(self.audio_file_name,self.language_dict[self.language_type])
3、實時語音識別部分的開發
有道智雲實時語音識別介面使用socket通訊,為簡化展示邏輯,因此在此處發開了展示識別結果的介面,使用tkinter顯示:
#輸出結果的視窗
root = tk.Tk()
root.title("result")
frm = tk.Frame(root)
frm.grid(padx='80', pady='80')
text_result = tk.Text(frm, width='40', height='20')
text_result.grid(row=0, column=1)
recognise()方法根據介面檔案,將所需引數拼接到uri,傳給start()方法請求介面:
def recognise(filepath,language_type):
print('l:'+language_type)
global file_path
file_path=filepath
nonce = str(uuid.uuid1())
curtime = str(int(time.time()))
signStr = app_key + nonce + curtime + app_secret
print(signStr)
sign = encrypt(signStr)
uri = "wss://openapi.youdao.com/stream_asropenapi?appKey=" + app_key + "&salt=" + nonce + "&curtime=" + curtime + \
"&sign=" + sign + "&version=v1&channel=1&format=wav&signType=v4&rate=16000&langType=" + language_type
print(uri)
start(uri, 1600)
start()方法是實時識別部分的核心方法,通過websocket呼叫識別介面。
def start(uri):
websocket.enableTrace(True)
ws = websocket.WebSocketApp(uri,
on_message=on_message,
on_error=on_error,
on_close=on_close)
ws.on_open = on_opend
ws.run_forever()
在請求介面時,首先讀取先前錄製的音訊檔,並行送:
def on_open(ws):
count = 0
file_object = open(file_path, 'rb') #開啟錄製的音訊
while True:
chunk_data = file_object.read(1600)
ws.send(chunk_data, websocket.ABNF.OPCODE_BINARY) #傳送
time.sleep(0.05)
count = count + 1
if not chunk_data:
break
print(count)
ws.send('{\"end\": \"true\"}', websocket.ABNF.OPCODE_BINARY)
而後在通訊過程中處理介面返回的訊息,收集介面返回的識別結果:
def on_message(ws, message):
result=json.loads(message)
resultmessage= result['result'] #解析呼叫介面的返回結果
if resultmessage:
resultmessage1 = result['result'][0]
resultmessage2 = resultmessage1["st"]['sentence']
print(resultmessage2)
#text_result.insert(tk.END, resultmessage2+'\n')
result_arr.append(resultmessage2)
最後在通訊結束後展示識別結果:
def on_close(ws):
print_resule(result_arr)
print("### closed ###")
def print_resule(arr):
text_result.delete('1.0',tk.END)
for n in arr:
text_result.insert("insert", n + '\n')
五、總結
有道智雲提供的介面一如既往的好用,這次開發主要的精力全都浪費在了由於我自己錄製的音訊品質差而識別失敗的問題上,音訊品質ok後,識別結果準確無誤,下一步就是拿去翻譯了,有了有道智雲API,實現實時翻譯也可以如此簡單!
關注我微信公眾號第一時間推播給你哦:
回覆選單,更有好禮,驚喜在等著你。

歡迎掃碼加入我建立的社群群哦,可以與我更進一步的交流,群裡還有很多大佬等著你,一起玩耍,一起進步!!!



