2020全新java基礎面試題彙總

java中==和equals和hashCode的區別
(更多面試題推薦:)
1、==
java中的資料型別,可分為兩類:
基本資料型別,也稱原始資料型別 byte,short,char,int,long,float,double,boolean 他們之間的比較,應用雙等號(==),比較的是他們的值。
參照型別(類、介面、陣列) 當他們用(==)進行比較的時候,比較的是他們在記憶體中的存放地址,所以,除非是同一個new出來的物件,他們的比較後的結果為true,否則比較後結果為false。物件是放在堆中的,棧中存放的是物件的參照(地址)。先看下虛擬機器器記憶體圖和程式碼:
public class testDay {
public static void main(String[] args) {
String s1 = new String("11");
String s2 = new String("11");
System.out.println(s1 == s2);
System.out.println(s1.equals(s2));
}
}結果是:
false
true
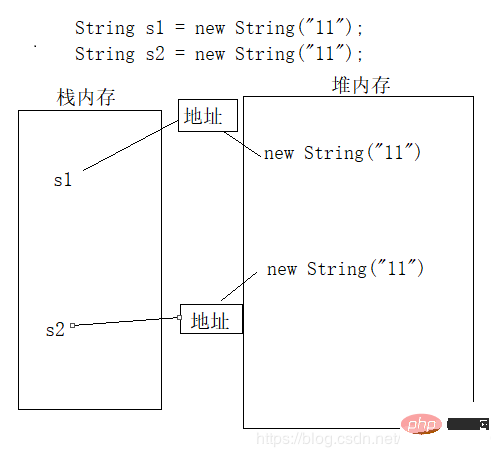
s1和s2都分別儲存的是相應物件的地址。所以如果用 s1== s2時,比較的是兩個物件的地址值(即比較參照是否相同),為false。而呼叫equals方向的時候比較的是相應地址裡面的值,所以值為true。這裡就需要詳細描述下equals()了。
2、equals()方法詳解
equals()方法是用來判斷其他的物件是否和該物件相等。其再Object裡面就有定義,所以任何一個物件都有equals()方法。區別在於是否重寫了該方法。
先看下原始碼:
public boolean equals(Object obj) { return (this == obj);
}很明顯Object定義的是對兩個物件的地址值進行的比較(即比較參照是否相同)。但是為什麼String裡面呼叫equals()卻是比較的不是地址而是堆記憶體地址裡面的值呢。這裡就是個重點了,像String 、Math、Integer、Double等這些封裝類在使用equals()方法時,已經覆蓋了object類的equals()方法。看下String裡面重寫的equals():
public boolean equals(Object anObject) { if (this == anObject) { return true;
} if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length; if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0; while (n-- != 0) { if (v1[i] != v2[i]) return false;
i++;
} return true;
}
} return false;
}重寫了之後就是這是進行的內容比較,而已經不再是之前地址的比較。依次類推Math、Integer、Double等這些類都是重寫了equals()方法的,從而進行的是內容的比較。當然,基本型別是進行值的比較。
需要注意的是當equals()方法被override時,hashCode()也要被override。按照一般hashCode()方法的實現來說,相等的物件,它們的hashcode一定相等。為什麼會這樣,這裡又要簡單提一下hashcode了。
3、hashcode()淺談
明明是java中==和equals和hashCode的區別問題,怎麼一下子又扯到hashcode()上面去了。你肯定很鬱悶,好了,我打個簡單的例子你就知道為什麼==或者equals的時候會涉及到hashCode。
舉例說明下:如果你想查詢一個集合中是否包含某個物件,那麼程式應該怎麼寫呢?不要用indexOf方法的話,就是從集合中去遍歷然後比較是否想到。萬一集合中有10000個元素呢,累屎了是吧。所以為了提高效率,雜湊演演算法也就產生了。核心思想就是將集合分成若干個儲存區域(可以看成一個個桶),每個物件可以計算出一個雜湊碼,可以根據雜湊碼分組,每組分別對應某個儲存區域,這樣一個物件根據它的雜湊碼就可以分到不同的儲存區域(不同的區域)。
所以再比較元素的時候,實際上是先比較hashcode,如果相等了之後才去比較equal方法。
看下hashcode圖解:
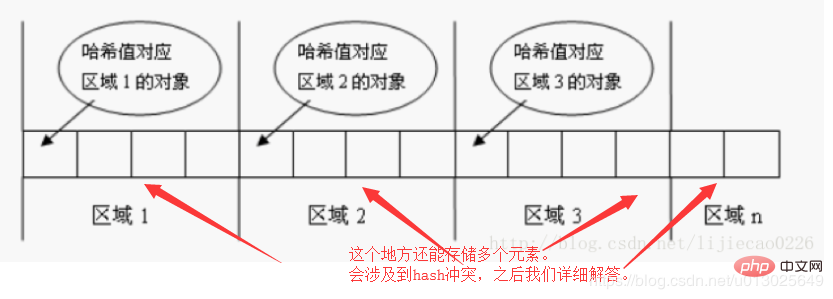
一個物件一般有key和value,可以根據key來計算它的hashCode值,再根據其hashCode值儲存在不同的儲存區域中,如上圖。不同區域能儲存多個值是因為會涉及到hash衝突的問題。簡單如果兩個不同物件的hashCode相同,這種現象稱為hash衝突。簡單來說就是hashCode相同但是equals不同的值。對於比較10000個元素就不需要遍歷整個集合了,只需要計算要查詢物件的key的hashCode,然後找到該hashCode對應的儲存區域查詢就over了。
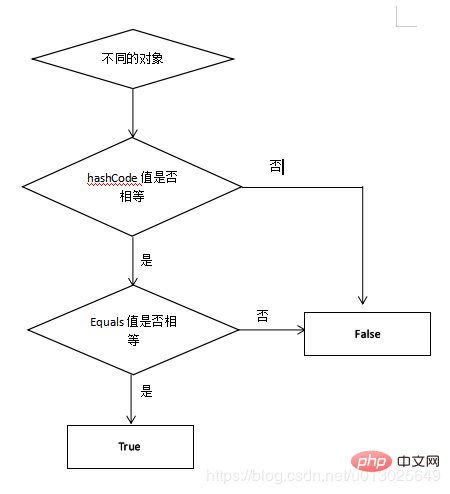
大概可以知道,先通過hashcode來比較,如果hashcode相等,那麼就用equals方法來比較兩個物件是否相等。再重寫了equals最好把hashCode也重寫。其實這是一條規範,如果不這樣做程式也可以執行,只不過會隱藏bug。一般一個類的物件如果會儲存在HashTable,HashSet,HashMap等雜湊儲存結構中,那麼重寫equals後最好也重寫hashCode。
總結:
- hashCode是為了提高在雜湊結構儲存中查詢的效率,線上性表中沒有作用。
- equals重寫的時候hashCode也跟著重寫
- 兩物件equals如果相等那麼hashCode也一定相等,反之不一定。
2. int、char、long 各佔多少位元組數
byte 是 位元組
bit 是 位
1 byte = 8 bit
char在java中是2個位元組,java採用unicode,2個位元組來表示一個字元
short 2個位元組
int 4個位元組
long 8個位元組
float 4個位元組
double 8個位元組
3. int和Integer的區別
- Integer是int的包裝類,int則是java的一種基本資料型別
- Integer變數必須範例化後才能使用,而int變數不需要
- Integer實際是物件的參照,當new一個Integer時,實際上是生成一個指標指向此物件;而int則是直接儲存資料值
- Integer的預設值是null,int的預設值是0
延伸: 關於Integer和int的比較
- 由於Integer變數實際上是對一個Integer物件的參照,所以兩個通過new生成的Integer變數永遠是不相等的(因為new生成的是兩個物件,其記憶體地址不同)。
Integer i = new Integer(100); Integer j = new Integer(100); System.out.print(i == j); //false
- Integer變數和int變數比較時,只要兩個變數的值是向等的,則結果為true(因為包裝類Integer和基本資料型別int比較時,java會自動拆包裝為int,然後進行比較,實際上就變為兩個int變數的比較)
Integer i = new Integer(100); int j = 100; System.out.print(i == j); //true
- 非new生成的Integer變數和new Integer()生成的變數比較時,結果為false。(因為非new生成的Integer變數指向的是java常數池中的物件,而new Integer()生成的變數指向堆中新建的物件,兩者在記憶體中的地址不同)
Integer i = new Integer(100); Integer j = 100; System.out.print(i == j); //false
- 對於兩個非new生成的Integer物件,進行比較時,如果兩個變數的值在區間-128到127之間,則比較結果為true,如果兩個變數的值不在此區間,則比較結果為false
Integer i = 100; Integer j = 100; System.out.print(i == j); //true
Integer i = 128; Integer j = 128; System.out.print(i == j); //false
對於第4條的原因: java在編譯Integer i = 100 ;時,會翻譯成為Integer i = Integer.valueOf(100);,而java API中對Integer型別的valueOf的定義如下:
public static Integer valueOf(int i){
assert IntegerCache.high >= 127; if (i >= IntegerCache.low && i <= IntegerCache.high){ return IntegerCache.cache[i + (-IntegerCache.low)];
} return new Integer(i);
}java對於-128到127之間的數,會進行快取,Integer i = 127時,會將127進行快取,下次再寫Integer j = 127時,就會直接從快取中取,就不會new了
4. java多型的理解
1.多型概述
多型是繼封裝、繼承之後,物件導向的第三大特性。
多型現實意義理解:
現實事物經常會體現出多種形態,如學生,學生是人的一種,則一個具體的同學張三既是學生也是人,即出現兩種形態。
Java作為物件導向的語言,同樣可以描述一個事物的多種形態。如Student類繼承了Person類,一個Student的物件便既是Student,又是Person。
多型體現為父類別參照變數可以指向子類物件。
前提條件:必須有子父類別關係。
注意:在使用多型後的父類別參照變數呼叫方法時,會呼叫子類重寫後的方法。
- 多型的定義與使用格式
定義格式:父類別型別 變數名=new 子類型別();
2.多型中成員的特點
- 多型成員變數:編譯執行看左邊
Fu f=new Zi();
System.out.println(f.num);//f是Fu中的值,只能取到父中的值
- 多型成員方法:編譯看左邊,執行看右邊
Fu f1=new Zi();
System.out.println(f1.show());//f1的門面型別是Fu,但實際型別是Zi,所以呼叫的是重寫後的方法。
3.instanceof關鍵字
作用:用來判斷某個物件是否屬於某種資料型別。
* 注意: 返回型別為布林型別
使用案例:
Fu f1=new Zi();
Fu f2=new Son();if(f1 instanceof Zi){
System.out.println("f1是Zi的型別");
}else{
System.out.println("f1是Son的型別");
}4.多型的轉型
多型的轉型分為向上轉型和向下轉型兩種
向上轉型:多型本身就是向上轉型過的過程
使用格式:父類別型別 變數名=new 子類型別();
適用場景:當不需要面對子類型別時,通過提高擴充套件性,或者使用父類別的功能就能完成相應的操作。
向下轉型:一個已經向上轉型的子類物件可以使用強制型別轉換的格式,將父類別參照型別轉為子類參照各型別
使用格式:子類型別 變數名=(子類型別)父類別型別的變數;
適用場景:當要使用子類特有功能時。
5.多型案例:
例1:
package day0524;
public class demo04 {
public static void main(String[] args) {
People p=new Stu();
p.eat();
//呼叫特有的方法
Stu s=(Stu)p;
s.study();
//((Stu) p).study();
}
}
class People{
public void eat(){
System.out.println("吃飯");
}
}
class Stu extends People{
@Override
public void eat(){
System.out.println("吃水煮肉片");
}
public void study(){
System.out.println("好好學習");
}
}
class Teachers extends People{
@Override
public void eat(){
System.out.println("吃櫻桃");
}
public void teach(){
System.out.println("認真授課");
}
}答案:吃水煮肉片 好好學習
例2:
請問題目執行結果是什麼?
package day0524;
public class demo1 {
public static void main(String[] args) {
A a=new A();
a.show();
B b=new B();
b.show();
}
}
class A{
public void show(){
show2();
}
public void show2(){
System.out.println("A");
}
}
class B extends A{
public void show2(){
System.out.println("B");
}
}
class C extends B{
public void show(){
super.show();
}
public void show2(){
System.out.println("C");
}
}答案:A B
5. String、StringBuffer和StringBuilder區別
1、長度是否可變
- String 是被 final 修飾的,他的長度是不可變的,就算呼叫 String 的concat 方法,那也是把字串拼接起來並重新建立一個物件,把拼接後的 String 的值賦給新建立的物件
- StringBuffer 和 StringBuilder 類的物件能夠被多次的修改,並且不產生新的未使用物件,StringBuffer 與 StringBuilder 中的方法和功能完全是等價的。呼叫StringBuffer 的 append 方法,來改變 StringBuffer 的長度,並且,相比較於 StringBuffer,String 一旦發生長度變化,是非常耗費記憶體的!
2、執行效率
- 三者在執行速度方面的比較:StringBuilder > StringBuffer > String
3、應用場景
- 如果要操作少量的資料用 = String
- 單執行緒操作字串緩衝區 下操作大量資料 = StringBuilder
- 多執行緒操作字串緩衝區 下操作大量資料 = StringBuffer
StringBuffer和StringBuilder區別
1、是否執行緒安全
- StringBuilder 類在 Java 5 中被提出,它和 StringBuffer 之間的最大不同在於 StringBuilder 的方法不是執行緒安全的(不能同步存取),StringBuffer是執行緒安全的。只是StringBuffer 中的方法大都採用了 synchronized 關鍵字進行修飾,因此是執行緒安全的,而 StringBuilder 沒有這個修飾,可以被認為是執行緒不安全的。
2、應用場景
- 由於 StringBuilder 相較於 StringBuffer 有速度優勢,所以多數情況下建議使用 StringBuilder 類。
- 然而在應用程式要求執行緒安全的情況下,則必須使用 StringBuffer 類。 append方法與直接使用+串聯相比,減少常數池的浪費。
6. 什麼是內部類?內部類的作用
內部類的定義
將一個類定義在另一個類裡面或者一個方法裡面,這樣的類稱為內部類。
內部類的作用:
成員內部類 成員內部類可以無條件存取外部類的所有成員屬性和成員方法(包括private成員和靜態成員)。 當成員內部類擁有和外部類同名的成員變數或者方法時,會發生隱藏現象,即預設情況下存取的是成員內部類的成員。
區域性內部類 區域性內部類是定義在一個方法或者一個作用域裡面的類,它和成員內部類的區別在於區域性內部類的存取僅限於方法內或者該作用域內。
匿名內部類 匿名內部類就是沒有名字的內部類
靜態內部類 指被宣告為static的內部類,他可以不依賴內部類而範例,而通常的內部類需要範例化外部類,從而範例化。靜態內部類不可以有與外部類有相同的類名。不能存取外部類的普通成員變數,但是可以存取靜態成員變數和靜態方法(包括私有型別) 一個 靜態內部類去掉static 就是成員內部類,他可以自由的參照外部類的屬性和方法,無論是靜態還是非靜態。但是不可以有靜態屬性和方法
(學習視訊推薦:)
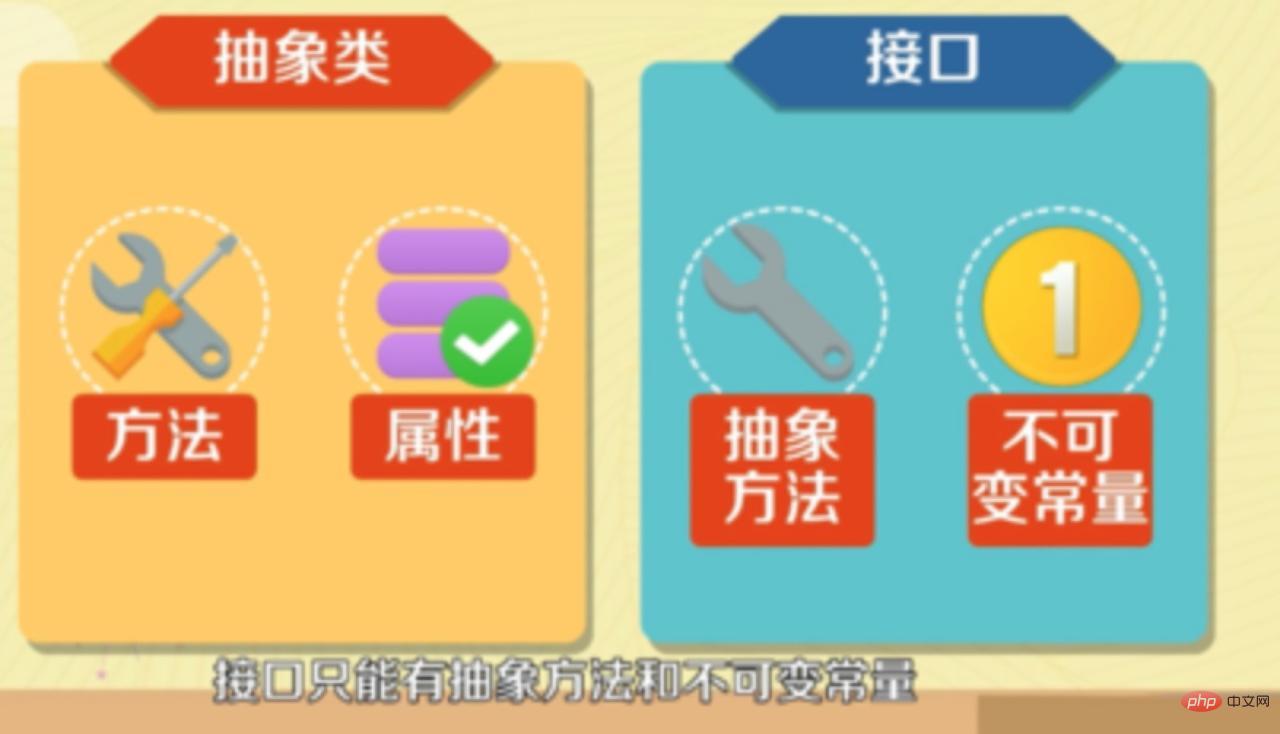
7. 抽象類和介面的區別
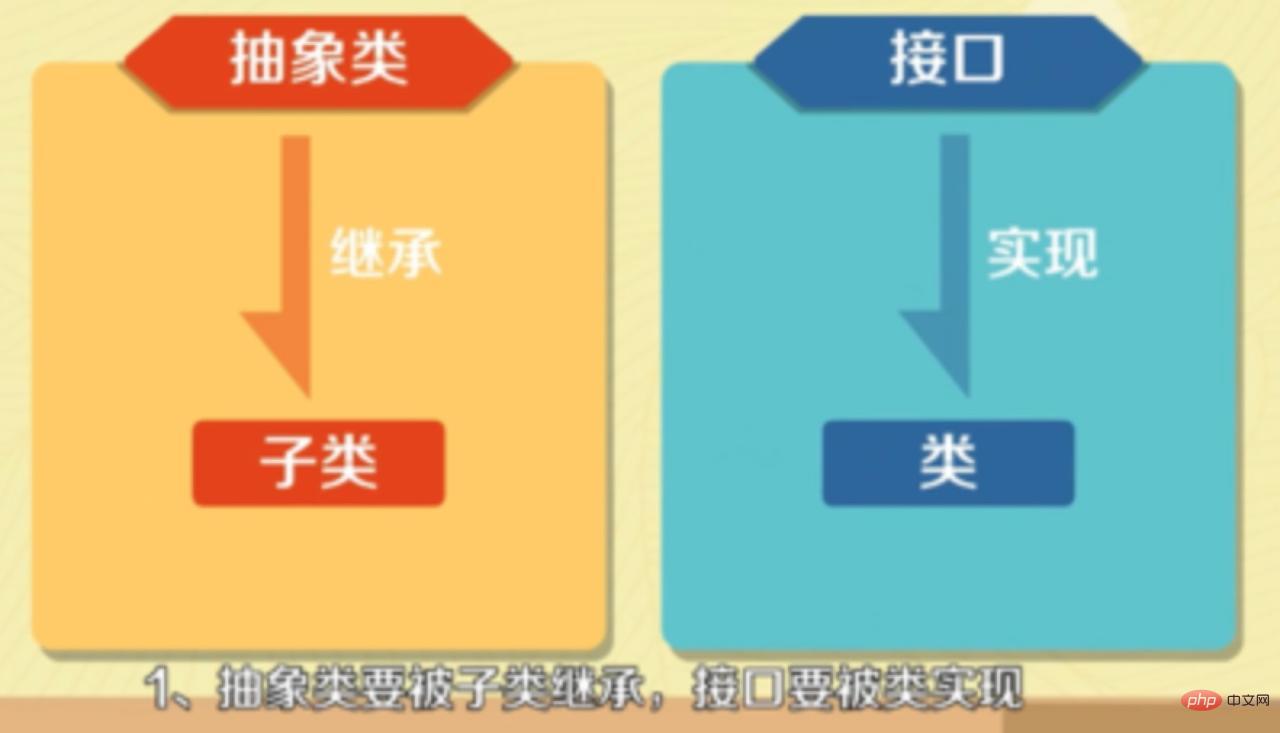
- 抽象類要被子類繼承,介面要被類實現。
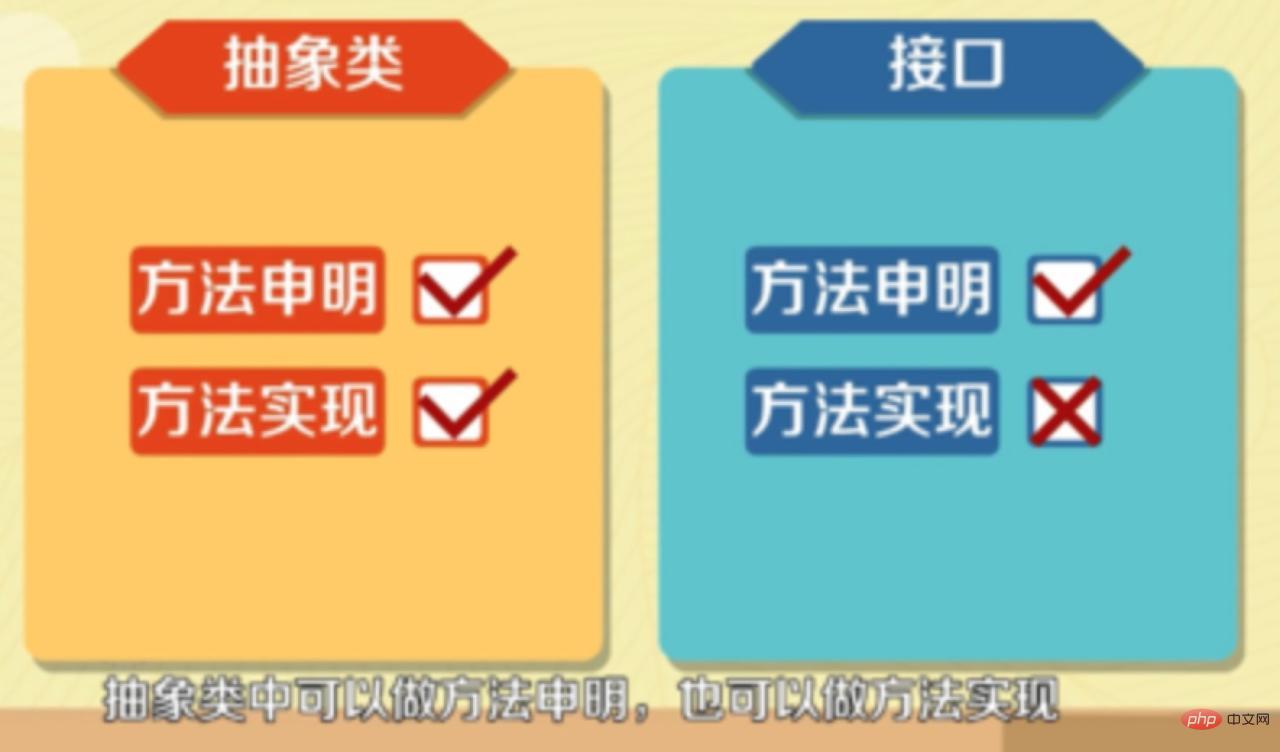
- 介面只能做方法宣告,抽象類中可以作方法宣告,也可以做方法實現。
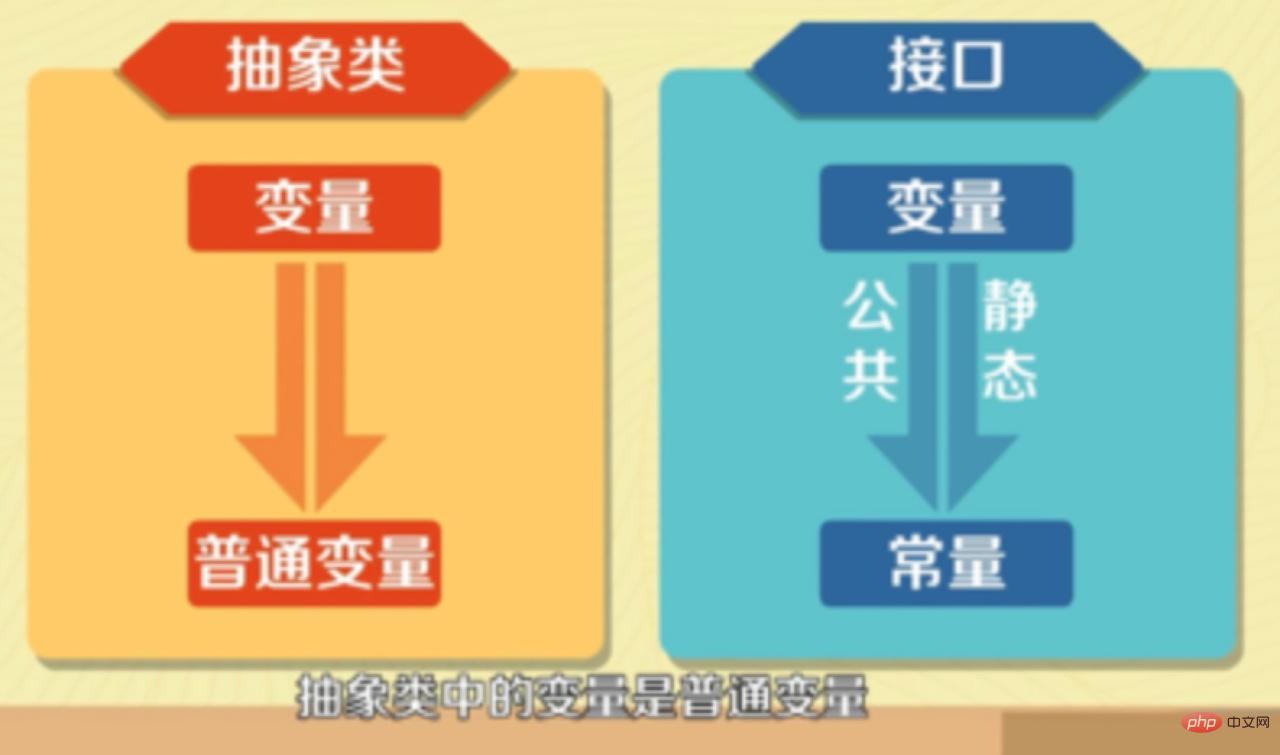
- 介面裡定義的變數只能是公共的靜態的常數,抽象類中的變數是普通變數。
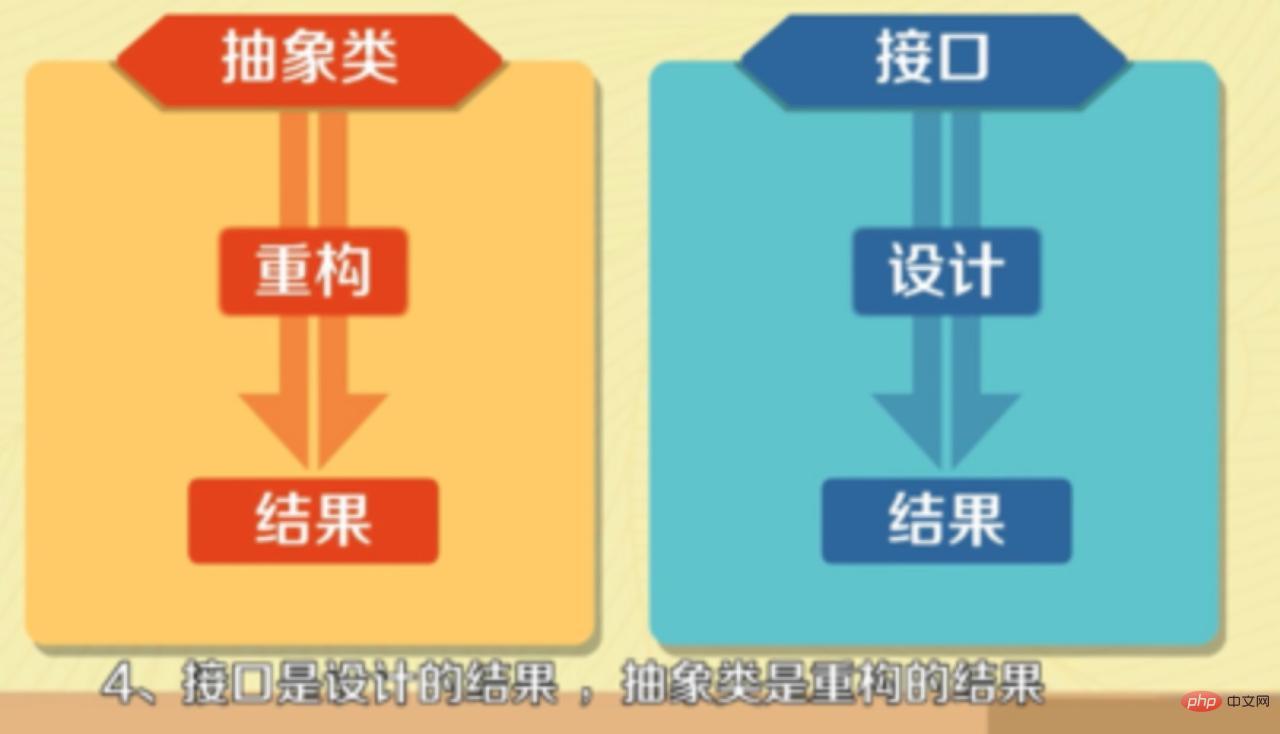
- 介面是設計的結果,抽象類是重構的結果。
- 抽象類和介面都是用來抽象具體物件的,但是介面的抽象級別最高。
- 抽象類可以有具體的方法和屬性,介面只能有抽象方法和不可變常數。
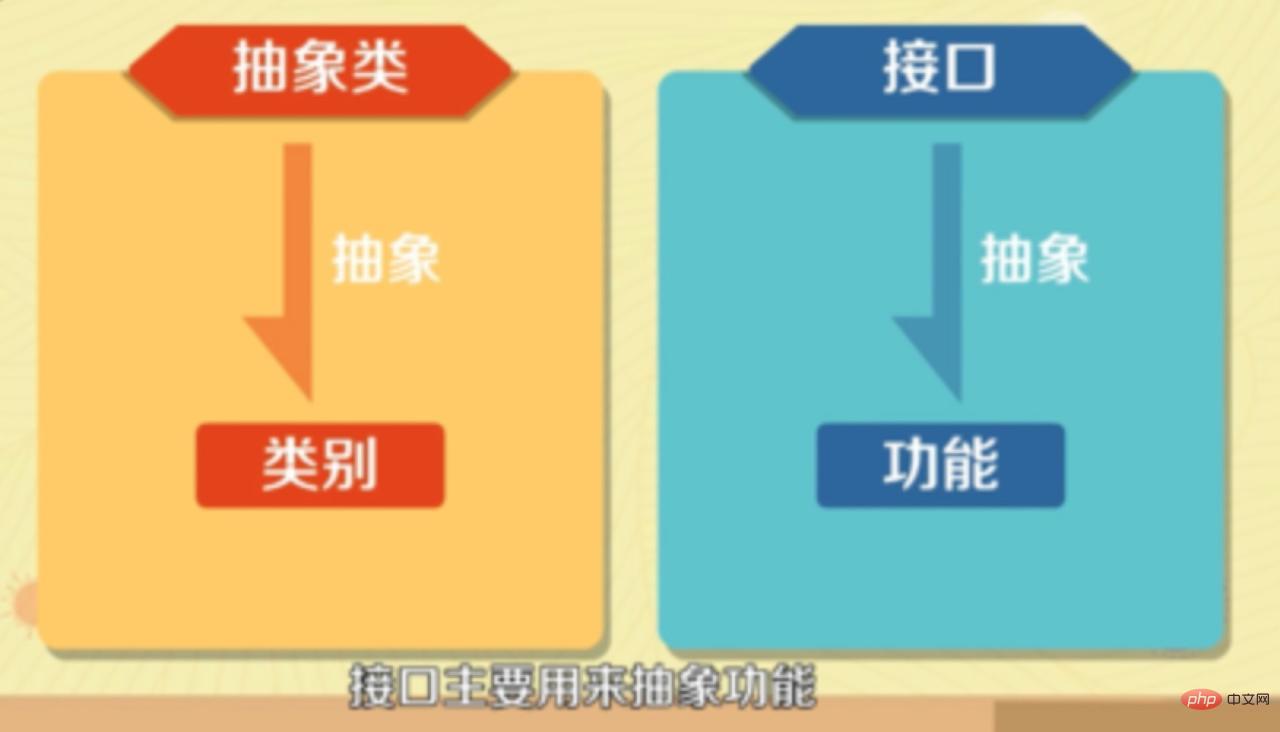
- 抽象類主要用來抽象類別,介面主要用來抽象功能。
8. 抽象類的意義
抽象類: 一個類中如果包含抽象方法,這個類應該用abstract關鍵字宣告為抽象類。
意義:
- 為子類提供一個公共的型別;
- 封裝子類中重複內容(成員變數和方法);
- 定義有抽象方法,子類雖然有不同的實現,但該方法的定義是一致的。
9. 抽象類與介面的應用場景
1.介面(interface)的應用場合:
- 類與類之間需要特定的介面進行協調,而不在乎其如何實現。
- 作為能夠實現特定功能的標識存在,也可以是什麼介面方法都沒有的純粹標識。
- 需要將一組類視為單一的類,而呼叫者只通過介面來與這組類發生聯絡。
- 需要實現特定的多項功能,而這些功能之間可能完全沒有任何聯絡。
2.抽象類(abstract.class)的應用場合:
一句話,在既需要統一的介面,又需要範例變數或預設的方法的情況下,就可以使用它。最常見的有:
- 定義了一組介面,但又不想強迫每個實現類都必須實現所有的介面。可以用abstract.class定義一組方法體,甚至可以是空方法體,然後由子類選擇自己所感興趣的方法來覆蓋。
- 某些場合下,只靠純粹的介面不能滿足類與類之間的協調,還必需類中表示狀態的變數來區別不同的關係。abstract的中介作用可以很好地滿足這一點。
- 規範了一組相互協調的方法,其中一些方法是共同的,與狀態無關的,可以共用的,無需子類分別實現;而另一些方法卻需要各個子類根據自己特定的狀態來實現特定的功能
10. 抽象類是否可以沒有方法和屬性?
答案是:可以
抽象類中可以沒有抽象方法,但有抽象方法的一定是抽象類。所以,java中 抽象類裡面可以沒有抽象方法。注意即使是沒有抽象方法和屬性的抽象類,也不能被範例化。
11. 介面的意義
- 定義介面的重要性:在Java程式設計,abstract class 和interface是支援抽象類定義的兩種機制。正是由於這兩種機制的存在,才使得Java成為物件導向的程式語言。
- 定義介面有利於程式碼的規範:對於一個大型專案而言,架構師往往會對一些主要的介面來進行定義,或者清理一些沒有必要的介面。這樣做的目的一方面是為了給開發人員一個清晰的指示,告訴他們哪些業務需要實現;同時也能防止由於開發人員隨意命名而導致的命名不清晰和程式碼混亂,影響開發效率。
- 有利於對程式碼進行維護:比如你要做一個畫板程式,其中裡面有一個面板類,主要負責繪畫功能,然後你就這樣定義了這個類。可是在不久將來,你突然發現現有的類已經不能夠滿足需要,然後你又要重新設計這個類,更糟糕是你可能要放棄這個類,那麼其他地方可能有參照他,這樣修改起來很麻煩。如果你一開始定義一個介面,把繪製功能放在介面裡,然後定義類時實現這個介面,然後你只要用這個介面去參照實現它的類就行了,以後要換的話只不過是參照另一個類而已,這樣就達到維護、拓展的方便性。
- 保證程式碼的安全和嚴密:一個好的程式一定符合高內聚低耦合的特徵,那麼實現低耦合,定義介面是一個很好的方法,能夠讓系統的功能較好地實現,而不涉及任何具體的實現細節。這樣就比較安全、嚴密一些,這一思想一般在軟體開發中較為常見。
12. Java泛型中的extends和super理解
在平時看原始碼的時候我們經常看到泛型,且經常會看到extends和super的使用,看過其他的文章裡也有講到上界萬用字元和下屆萬用字元,總感覺講的不夠明白。這裡備註一下,以免忘記。
- extends也成為上界萬用字元,就是指定上邊界。即泛型中的類必須為當前類的子類或當前類。
- super也稱為下屆萬用字元,就是指定下邊界。即泛型中的類必須為當前類或者其父類別。
這兩點不難理解,extends修飾的只能取,不能放,這是為什麼呢? 先看一個列子:
public class Food {}
public class Fruit extends Food {}
public class Apple extends Fruit {}
public class Banana extends Fruit{}
public class GenericTest {
public void testExtends(List<? extends Fruit> list){
//報錯,extends為上界萬用字元,只能取值,不能放.
//因為Fruit的子類不只有Apple還有Banana,這裡不能確定具體的泛型到底是Apple還是Banana,所以放入任何一種型別都會報錯
//list.add(new Apple());
//可以正常獲取
Fruit fruit = list.get(1);
}
public void testSuper(List<? super Fruit> list){
//super為下界萬用字元,可以存放元素,但是也只能存放當前類或者子類的範例,以當前的例子來講,
//無法確定Fruit的父類別是否只有Food一個(Object是超級父類別)
//因此放入Food的範例編譯不通過
list.add(new Apple());
// list.add(new Food());
Object object = list.get(1);
}
}在testExtends方法中,因為泛型中用的是extends,在向list中存放元素的時候,我們並不能確定List中的元素的具體型別,即可能是Apple也可能是Banana。因此呼叫add方法時,不論傳入new Apple()還是new Banana(),都會出現編譯錯誤。
理解了extends之後,再看super就很容易理解了,即我們不能確定testSuper方法的引數中的泛型是Fruit的哪個父類別,因此在呼叫get方法時只能返回Object型別。結合extends可見,在獲取泛型元素時,使用extends獲取到的是泛型中的上邊界的型別(本例子中為Fruit),範圍更小。
總結:在使用泛型時,存取元素時用super,獲取元素時,用extends。
13. 父類別的靜態方法能否被子類重寫
不能,父類別的靜態方法能夠被子類繼承,但是不能夠被子類重寫,即使子類中的靜態方法與父類別中的靜態方法完全一樣,也是兩個完全不同的方法。
class Fruit{
static String color = "五顏六色";
static public void call() {
System.out.println("這是一個水果");
}
}
public class Banana extends Fruit{
static String color = "黃色";
static public void call() {
System.out.println("這是一個香蕉");
}
public static void main(String[] args) {
Fruit fruit = new Banana();
System.out.println(fruit.color); //五顏六色
fruit.call(); //這是一個水果
}
}如程式碼所示,如果能夠被重寫,則輸出的應該是這是一個香蕉。與此類似的是,靜態變數也不能夠被重寫。如果想要呼叫父類別的靜態方法,應該使用類來呼叫。 那為什麼會出現這種情況呢? 我們要從重寫的定義來說:
重寫指的是根據執行時物件的型別來決定呼叫哪個方法,而不是根據編譯時的型別。
對於靜態方法和靜態變數來說,雖然在上述程式碼中使用物件來進行呼叫,但是底層上還是使用父類別來呼叫的,靜態變數和靜態方法在編譯的時候就將其與類繫結在一起。既然它們在編譯的時候就決定了呼叫的方法、變數,那就和重寫沒有關係了。
靜態屬性和靜態方法是否可以被繼承
可以被繼承,如果子類中有相同的靜態方法和靜態變數,那麼父類別的方法以及變數就會被覆蓋。要想呼叫就就必須使用父類別來呼叫。
class Fruit{
static String color = "五顏六色";
static String xingzhuang = "奇形怪狀";
static public void call() {
System.out.println("這是一個水果");
}
static public void test() {
System.out.println("這是沒有被子類覆蓋的方法");
}
}
public class Banana extends Fruit{
static String color = "黃色";
static public void call() {
System.out.println("這是一個香蕉");
}
public static void main(String[] args) {
Banana banana = new Banana();
banana.test(); //這是沒有被子類覆蓋的方法
banana.call(); //呼叫Banana類中的call方法 這是一個香蕉
Fruit.call(); //呼叫Fruit類中的方法 這是一個水果
System.out.println(banana.xingzhuang + " " + banana.color); //奇形怪狀 黃色
}
}從上述程式碼可以看出,子類中覆蓋了父類別的靜態方法的話,呼叫的是子類的方法,這個時候要是還想呼叫父類別的靜態方法,應該是用父類別直接呼叫。如果子類沒有覆蓋,則呼叫的是父類別的方法。靜態變數與此相似。
14. 執行緒和程序的區別
- 定義方面:程序是程式在某個資料集合上的一次執行活動;執行緒是程序中的一個執行路徑。(程序可以建立多個執行緒)
- 角色方面:在支援執行緒機制的系統中,程序是系統資源分配的單位,執行緒是CPU排程的單位。
- 資源共用方面:程序之間不能共用資源,而執行緒共用所在程序的地址空間和其它資源。同時執行緒還有自己的棧和棧指標,程式計數器等暫存器。
- 獨立性方面:程序有自己獨立的地址空間,而執行緒沒有,執行緒必須依賴於程序而存在。
- 開銷方面。程序切換的開銷較大。執行緒相對較小。(前面也提到過,引入執行緒也出於了開銷的考慮。)
可看下這篇文章:juejin.im/post/684490…
15. final,finally,finalize的區別
- final 用於宣告屬性,方法和類, 分別表示屬性不可變, 方法不可覆蓋, 類不可繼承.
- finally 是例外處理語句結構的一部分,表示總是執行.
- finalize 是Object類的一個方法,在垃圾收集器執行的時候會呼叫被回收物件的此方法,可以覆蓋此方法提供垃圾收集時的其他資源回收,例如關閉檔案等.
16. 序列化Serializable和Parcelable的區別
Android中Intent如果要傳遞類物件,可以通過兩種方式實現。
方式一:Serializable,要傳遞的類實現Serializable介面傳遞物件, 方式二:Parcelable,要傳遞的類實現Parcelable介面傳遞物件。
Serializable(Java自帶):Serializable是序列化的意思,表示將一個物件轉換成可儲存或可傳輸的狀態。序列化後的物件可以在網路上進行傳輸,也可以儲存到本地。Serializable是一種標記介面,這意味著無需實現方法,Java便會對這個物件進行高效的序列化操作。
Parcelable(Android 專用):Android的Parcelable的設計初衷是因為Serializable效率過慢(使用反射),為了在程式內不同元件間以及不同Android程式間(AIDL)高效的傳輸資料而設計,這些資料僅在記憶體中存在。Parcelable方式的實現原理是將一個完整的物件進行分解,而分解後的每一部分都是Intent所支援的資料型別,這樣也就實現傳遞物件的功能了。
效率及選擇:
Parcelable的效能比Serializable好,因為後者在反射過程頻繁GC,所以在記憶體間資料傳輸時推薦使用Parcelable,如activity間傳輸資料。而Serializable可將資料持久化方便儲存,所以在需要儲存或網路傳輸資料時選擇Serializable,因為android不同版本Parcelable可能不同,所以不推薦使用Parcelable進行資料持久化。 Parcelable不能使用在要將資料儲存在磁碟上的情況,因為Parcelable不能很好的保證資料的持續性在外界有變化的情況下。儘管Serializable效率低點,但此時還是建議使用Serializable 。
通過intent傳遞複雜資料型別時必須先實現兩個介面之一,對應方法分別是getSerializableExtra(),getParcelableExtra()。
17. 靜態屬性和靜態方法是否可以被繼承?是否可以被重寫?以及原因?
父類別的靜態屬性和方法可以被子類繼承
不可以被子類重寫:當父類別的參照指向子類時,使用物件呼叫靜態方法或者靜態變數,是呼叫的父類別中的方法或者變數。並沒有被子類改寫。
原因:
因為靜態方法從程式開始執行後就已經分配了記憶體,也就是說已經寫死了。所有參照到該方法的物件(父類別的物件也好子類的物件也好)所指向的都是同一塊記憶體中的資料,也就是該靜態方法。
子類中如果定義了相同名稱的靜態方法,並不會重寫,而應該是在記憶體中又分配了一塊給子類的靜態方法,沒有重寫這一說。
18 .java中靜態內部類的設計意圖
內部類
內部類,即定義在一個類的內部的類。為什麼有內部類呢?
我們知道,在java中類是單繼承的,一個類只能繼承另一個具體類或抽象類(可以實現多個介面)。這種設計的目的是因為在多繼承中,當多個父類別中有重複的屬性或者方法時,子類的呼叫結果會含糊不清,因此用了單繼承。
而使用內部類的原因是:每個內部類都能獨立地繼承一個(介面的)實現,所以無論外圍類是否已經繼承了某個(介面的)實現,對於內部類都沒有影響。
在我們程式設計中有時候會存在一些使用介面很難解決的問題,這個時候我們可以利用內部類提供的、可以繼承多個具體的或者抽象的類的能力來解決這些程式設計問題。可以這樣說,介面只是解決了部分問題,而內部類使得多重繼承的解決方案變得更加完整。
靜態內部類
說靜態內部類之前,先了解下成員內部類(非靜態的內部類)。
成員內部類
成員內部類也是最普通的內部類,它是外圍類的一個成員,所以它可以無限制的存取外圍類的所有成員屬性和方法,儘管是private的,但是外圍類要存取內部類的成員屬性和方法則需要通過內部類範例來存取。
在成員內部類中要注意兩點:
成員內部類中不能存在任何static的變數和方法;
成員內部類是依附於外圍類的,所以只有先建立了外圍類才能夠建立內部類。
靜態內部類
靜態內部類與非靜態內部類之間存在一個最大的區別:非靜態內部類在編譯完成之後會隱含地儲存著一個參照,該參照是指向建立它的外圍內,但是靜態內部類卻沒有。
沒有這個參照就意味著:
它的建立是不需要依賴於外圍類的。
它不能使用任何外圍類的非static成員變數和方法。
其它兩種內部類:區域性內部類和匿名內部類
區域性內部類
區域性內部類是巢狀在方法和作用域內的,對於這個類的使用主要是應用與解決比較複雜的問題,想建立一個類來輔助我們的解決方案,到那時又不希望這個類是公共可用的,所以就產生了區域性內部類,區域性內部類和成員內部類一樣被編譯,只是它的作用域發生了改變,它只能在該方法和屬性中被使用,出了該方法和屬性就會失效。
匿名內部類
匿名內部類是沒有存取修飾符的。
new 匿名內部類,這個類首先是要存在的。
當所在方法的形參需要被匿名內部類使用,那麼這個形參就必須為final。
匿名內部類沒有明面上的構造方法,編譯器會自動生成一個參照外部類的構造方法。
相關推薦:
以上就是2020全新java基礎面試題彙總的詳細內容,更多請關注TW511.COM其它相關文章!