瞭解為什麼說 Python 內建函數並不是萬能的?
欄目帶大家認識 Python 內建函數。

在Python貓的上一篇文章中,我們對比了兩種建立列表的方法,即字面量用法 [] 與內建型別用法 list(),進而分析出它們在執行速度上的差異。
在分析為什麼 list() 會更慢的時候,文中說到它需要經過名稱查詢與函數呼叫兩個步驟,那麼,這就引出了一個新的問題:list() 不是內建型別麼,為什麼它不能直接就呼叫建立列表的邏輯呢?也就是說,為什麼直譯器必須經過名稱查詢,才能「認識」到該做什麼呢?
其實原因很簡單:內建函數/內建型別的名稱並不是關鍵字,它們只是直譯器內建的一種便捷功能,方便開發者開箱即用而已。
PS:內建函數 built-in function 和內建型別 built-in type 很相似,但 list() 實際是一種內建型別而不是內建函數。我曾對這兩種易混淆的概念做過辨析,請檢視這篇文章。為了方便理解與表述,以下統稱為內建函數。
1、內建函數的查詢優先順序最低
內建函數的名稱並不屬於關鍵字,它們是可以被重新賦值的。
比如下面這個例子:
# 正常呼叫內建函數list(range(3)) # 結果:[0, 1, 2]# 定義任意函數,然後賦值給 listdef test(n):
print("Hello World!")
list = test
list(range(3)) # 結果:Hello World!複製程式碼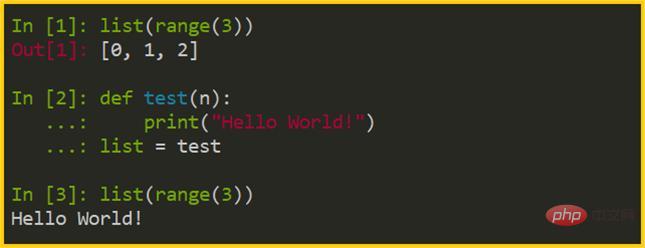
在這個例子中,我們將自定義的 test 賦值給了 list,程式並沒有報錯。這個例子甚至還可以改成直接定義新的同名函數,即"def list(): …"。
這說明了 list 並不是 Python 限定的關鍵字/保留字。
檢視官方檔案,可以發現 Python 3.9 有 35 個關鍵字,明細如下:

如果我們將上例的 test 賦值給任意一個關鍵字,例如"pass=test",就會報錯:SyntaxError: invalid syntax。
由此,我們可以從這個角度看出內建函數並不是萬能的:它們的名稱並不像關鍵字那般穩固不變,雖然它們處在系統內建作用域裡,但是卻可以被使用者區域性作用域的物件所輕鬆攔截掉!
因為直譯器查詢名稱的順序是「區域性作用域->全域性作用域->內建作用域」,因此內建函數其實是處在最低優先順序。
對於新手來說,這有一定的可能會發生意想不到的情況(內建函數有 69 個,要全記住是有難度的)。
那麼,為什麼 Python 不把所有內建函數的名稱都設為不可複寫的關鍵字呢?
一方面原因是它想控制關鍵字的數量,另一方面可能是想留給使用者更多的自由。內建函數只是直譯器的推薦實現而已,開發者可以根據需要,實現出與內建函數同名的函數。
不過,這樣的場景極少,而且開發者一般會定義成不同名的函數,以 Python 標準庫為例,ast模組有 literal_eval() 函數(對標 eval() 內建函數)、pprint 模組有 pprint() 函數(對標 print() 內建函數)、以及itertools模組有 zip_longest() 函數(對標 zip() 內建函數)……
2、內建函數可能不是最快的
由於內建函數的名稱並非保留的關鍵字,以及它處於名稱查詢的末位順序,所以內建函數有可能不是最快的。
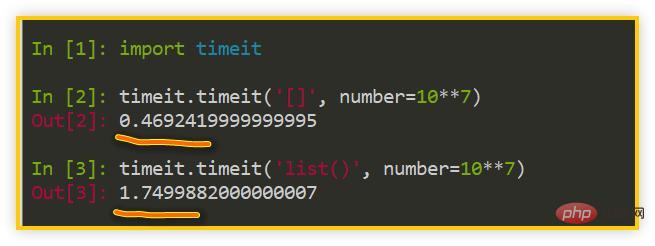
上篇文章展示了 [] 比 list() 快 2~3 倍的事實,其實這還可以推廣到 str()、tuple()、set()、dict() 等等內建型別中,都是字面量用法稍稍快於內建型別用法。
對於這些內建型別,當我們呼叫 xxx() 時,可以簡單理解成正在做類的範例化。在物件導向語言中,類先範例化再使用,這是再正常不過的。
但是,這樣的做法有時也顯得繁瑣。為了方便使用,Python 給一些常用的內建型別提供了字面量表示法,也就是""、[]、()、{} 等等,表示字串、列表、元組和字典等資料型別。

檔案出處:docs.python.org/3/reference…
一般而言,所有程式語言都必須有一些字面量表示,但基本都侷限在數位型別、字串、布林型別以及 null 之類的基礎型別。
Python 中還增加了幾種資料結構型別的字面量,所以是更為方便的,同時這也解釋了為什麼內建函數可能不是最快的。
一般而言,同樣的完備功能,內建函數總是比我們自定義的函數要快,因為直譯器可以做一些底層的優化,例如 len() 內建函數肯定比使用者定義的 x.len() 函數快。
有些人據此形成了「內建函數總是更快」的認識誤區。
直譯器內建函數相對於使用者定義函數,前者接近於走後門;而字面量表示法相對於內建函數,前者是在走更快的後門。
也就是說,在有字面量表示法的情況下,某些內建函數/內建型別並不是最快的!
小結
誠然,Python 本身並不是萬能的,那它的任何語法構成部分(內建函數/型別),就更不是萬能的了。但是,一般我們會認為內建函數/型別總歸是「高人一等」的,是受到諸多特殊優待的,顯得像是「萬能的」。
本文從「list() 竟然會敗給 []」破題,從兩個角度揭示了內建函數其實存在著某種不足:內建函數的名稱並不是關鍵字,而內建作用域位於名稱查詢的最低優先順序,因此在呼叫時,某些內建函數/型別的執行速度就明顯慢於它們對應的字面量表示法。
本文對上一個「Python為什麼」話題做了延展討論,一方面充實了前面的內容,另一方面,也有助於大家理解 Python 的幾個基礎概念及其實現。
如果你喜歡本文,請點贊支援下吧!另外,我還寫了 20+ 篇類似的話題,請關注Python貓檢視,並在 Github 上給我一顆小星星吧~~
相關免費學習推薦:
以上就是了解為什麼說 Python 內建函數並不是萬能的?的詳細內容,更多請關注TW511.COM其它相關文章!