記,在公司內部做的關於MySQL索引的分享
這一篇是講解Mysql中做使用到的「索引的種類」,「索引正確使用的原則」、「怎麼優化索引」、「以及兩種儲存引擎InnoDB和MyISAM索引的資料佈局原理」。
索引種類
在說索引之前,我們先來說一說什麼是索引呢?對於索引個人的理解就是,索引是一種加快查詢資料的資料結構。
所以,索引就是一種資料結構,作用就是發揮這種資料結構的作用,加快查詢的效率,例如:InnoDB儲存引擎中使用的是就是B+tree這種資料結構來組織索引。
Mysql中索引的種類也不是很多,不同型別的索引有不同的作用,索引的作用相互之間也存在交叉關係,Mysql中索引主要分為以下幾類:
- 「主鍵索引」(PRIMARY KEY):主鍵索引一般都是在建立表的時候指定,「一個表只有一個主鍵索引」,特點是「唯一、非空」。
- 「唯一索引」(UNIQUE):唯一索引具有的特點就是唯一性,可以在建立表的時候指定,也可以在建立表後建立。
- 「普通索引」(INDEX):普通索引唯一的作用就是加快查詢。
- 「組合索引」( INDEX):組合索引是建立一個「多個欄位的索引」,這個概念是相對於上上面的單列索引而言,組合索引查詢遵循「最左字首原則」。
- 「全文索引」(FULLTEXT):全文索引是針對一些大的「文字欄位」建立的索引,也稱為「全文檢索」。
- 「聚簇索引」和「非聚簇索引」:聚簇索引和非聚簇索引的概念比上面的概念要大,屬於包含和被包含的關係。例如:InnoDB中主鍵索引使用的就是聚簇索引。
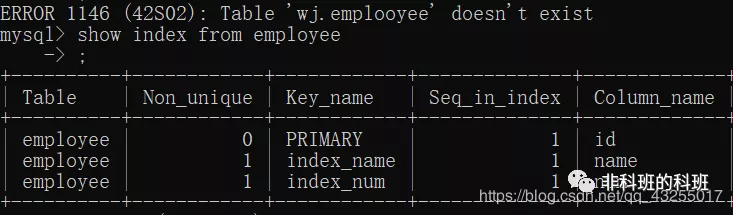
若是你想檢視一個表的所有索引,可以執行下面的sql來檢視:
show index from 表名例如,檢視我自己的測試表裡面的索引,如下圖所示,Key_name表示索引的名字,Column_name表示索引的欄位。
上面大概的說了主要索引的概念,下面詳細的介紹一下這幾大索引的特點和使用。
主鍵索引
主鍵索引在InnoDB儲存引擎中是最常見的索引型別,一個表都會有一個主鍵索引,它索引的欄位不允許為空值,並且唯一。
一般是在建立表的時候,可以通過RIMARY KEY指定主鍵索引,在InnoDB儲存引擎中,若是建立表的時候沒有主觀建立主鍵索引,Mysql就會看錶中是否有唯一索引,有,就會指定「非空的唯一索引」為主鍵索引;
沒有,就會預設生成一個6byte空間的自動增長主鍵作為主鍵索引,可以通過select _rowid from 表名查詢的是對應的主鍵值.。
MyISAM儲存引擎是可以不存在主鍵索引,MyISAM和InnoDB儲存資料的結構方式還是有明顯的區別,這個後面篇章會詳細講解。
唯一索引
唯一索引與主鍵索引的區別就是,唯一索引允許為空,若是在組合索引中,只要建立的列值是唯一的
唯一索引在實際中更多的是用來保證資料的唯一性,假如你僅僅要資料能夠快速查詢,你也可以使用普通索引,所以唯一索引重在體現它的唯一性。
實際的業務場景,有些目標欄位要求唯一,就可以使用唯一索引,建立唯一索引的方式有三種。
(1)一個是在建立表的時候指定,如下sql:
CREATE TABLE user(
id INT PRIMARY KEY NOT NULL,
name VARCHAR(16) NOT NULL,
UNIQUE unique_name (name(10))
);(2)也可以在表建立後建立,如下sql:
CREATE UNIQUE INDEX unique_name ON user(name(10));(3)通過修改表結構建立,如下sql:
ALTER user ADD UNIQUE unique_name ON (name(10))這裡有一個細節要注意的是建立的name欄位,指定的長度是16字元,而建立的索引的長度指定的是10字元,因為也沒有人的名字長度會超過10個字元,所以減少索引長度,能夠減少索引所佔的空間的大小。
普通索引
普通索引的唯一作用就是加快資料的查詢,一般對查詢語句WHERE和ORDER BY後面的欄位建立普通索引。
建立普通索引的方式也有三種,基本和建立唯一索引的方式一樣,只是把關鍵字UNIQUE換成INDEX,如下所示:
// 建立表的時候建立
CREATE TABLE user(
id INT PRIMARY KEY NOT NULL,
name VARCHAR(16) NOT NULL,
INDEX index_name (name(10))
);
// 建立表後建立
CREATE INDEX INDEX index_name ON user(name(10));
// 修改表結構建立
ALTER user ADD INDEX index_name ON (name(10))若是想刪除索引,可以通過執行下面的sql進行刪除索引:
DROP INDEX index_name ON user;組合索引
組合索引即用多個欄位建立一個索引,組合索引能夠避免「回表查詢」,相對於多欄位的單列索引,組合索引的查詢效率更高。
建立組合索引(聯合索引)的方式和上面建立普通索引的方式一樣,只不過欄位的數目多了,如下sql建立:
// 其它方式和上面的一樣,這裡就只列舉修改表結構的方式建立
ALTER TABLE employee ADD INDEX name_age_sex (name(10),age,sex);回表查詢
什麼是回表查詢呢?回表查詢簡單來說「通過二級索引查詢資料,得不到完整的資料行,需要再次查詢主鍵索引來獲得資料行」。
InnoDB儲存引擎中,索引分為 「聚簇索引」和「二級索引」,主鍵索引就是聚簇索引,其它的索引為二級索引。
聚簇索引中的葉子節點儲存著完整的資料行,而二級索引的葉子節點並不是儲存完整的資料行。
上面提到InnoDB表是一定要有主鍵索引的,雖然索引佔據空間,但是索引符合二分查詢的演演算法,查詢資料非常的快。
假設還是上面的employee表,裡面有主鍵索引id,和普通的索引name,那麼在InnoDB中就會存在兩棵B+Tree,一棵是主鍵索引樹:
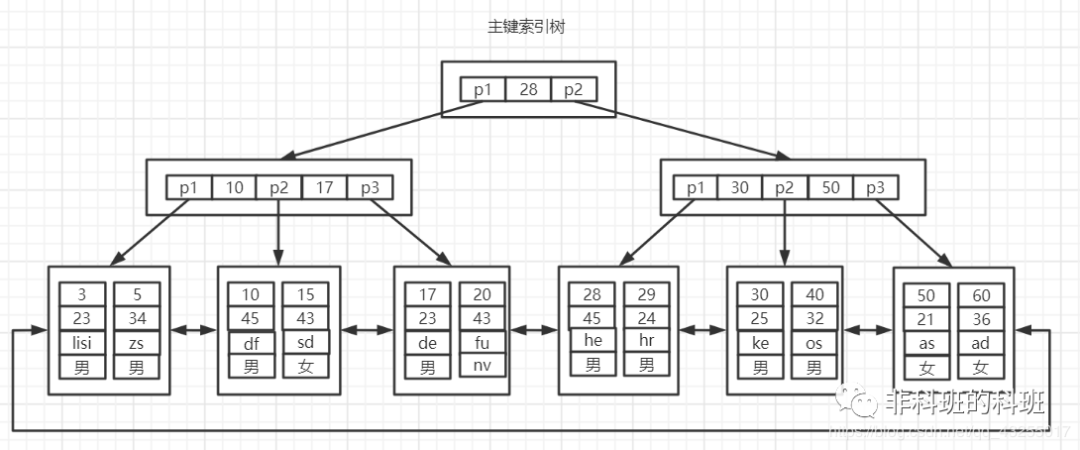
主鍵索引樹
在主鍵索引樹中的葉子節點儲存的是完整的資料行,另外一棵是name欄位的二級索引樹,如下圖所示:
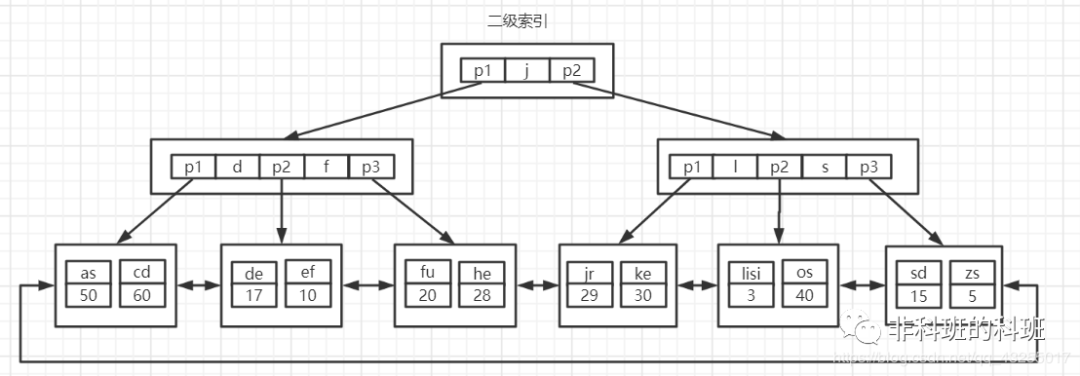
倘若你執行這條sql:select name, age, sex from employee where id ='as';就會先執行二級索引的查詢,當查詢name='as'時,得到主鍵為50,再根據主鍵查詢主鍵索引樹,得到完整的資料行,具體的執行流程如下:

回表原理圖
這個就是回表查詢,回表查詢會查詢兩次,這樣就會降低查詢的效率,為了避免回表查詢,只查詢一次就能得到完整的資料呢?
索引覆蓋
常見的方式就是「建立組合索引(聯合索引)「進行」索引覆蓋」,什麼是索引覆蓋呢?索引覆蓋就是「索引的葉子節點已經包含了查詢的資料,沒必要再回表進行查詢。」
假如我還是執行如下sql:select name, age, sex from employee where name ='as';因為普通索引只有name欄位才建立了索引,這必然會導致回表查詢。
為了提高查詢效率,就(name)「單列索引升級為聯合索引」(name, age, sex)就不同了。
因為建立的聯合索引,在二級節點的葉子階段就會同時存在name, age, sex三個的值,一次性就會獲得所需要的資料,這樣就避免了回表,但是所有的方案都不是完美的。
若是這個聯合索引哪一天某一個資料行的name值改變了或者age改變了,我就需要同時維護主鍵索引和聯合索引兩棵樹,這樣的維護成本就高了,效能開銷也大了。
相比之前資料的改變,我只需要維護主鍵索引即可,聯合索引的建立就導致了需要同時維護兩棵樹,這樣就會影響插入、更新資料的操作,所以並沒有哪種方案是完美的。
最左字首原則
我們知道單列索引是按照索引列有序性的進行組織B+Tree結構的,聯合索引又是怎麼組織B+Tree呢?
聯合索引其實也是按照建立索引的時候,最左邊的進行最開始的排序,也就是「最左字首原則」,比如一個表中有如下資料:
nameagesexad23男bc21男bc24女bc25男de21女
如上圖所示,對於聯合索引中name欄位是放在最前面的,所以name是完全有序的,但是age欄位就不是有序的,只有當name相同,例如:name='bc'此時age欄位的索引排序才是完全有序的。
所以你會發現,在聯合索引中你只有使用以下的規則的方式查詢才會使用到索引:
- name,age,sex
- name,age
- name
因為Mysql的底層有查詢優化器,會判斷sql執行的時候若是使用全表掃描的效率比使用索引的效率更高,就會使用全表掃描。
假如,我查詢的時候使用age>=23,sex='男';兩個欄位作為查詢條件,但是沒有使用name欄位,因為在name不知情的條件下,對於age是無序的。
對於age>=23條件可能在很多的name不同中都有符合條件的出現,所以就沒有辦法使用索引,這也是索引實現的原因,一定要遵循「查詢有序,充分的利用索引的有序性」。
假如你是分別在name,age,sex三個欄位中分別建立三個單列索引,就相當於建立三顆索引樹,那麼它的查詢效率,比我們使用一棵索引樹查詢效率就可想而知了。
有一種情況即使使用到了最左邊的name欄位也不會使用索引,例如:WHERE name like '%d%';這種like條件的模糊查詢是會使索引失效。
我們可以這樣理解,「查詢字串也是遵循最左字首原則的」,字串的查詢是對字串裡面的字元一個一個的匹配,「若是字串最左邊為%表示一個不確定的字串,那麼是沒辦法利用到索引的有序性」。
但是若是修改為 :WHERE name like 'd%';就可以使用索引,因為最左邊的字串是確定的,這種稱為「匹配列字首」。
實際業務場景中聯合索引的建立,「我們應該把識別度比較高的欄位放在前面,提高索引的命中率,充分的利用索引」。
索引下推
Mysql5.6版本提出了索引下推的原則,「用於查詢優化,主要是用於like關鍵字的查詢的優化」,什麼是索引下推呢?
下面通過演示來說明一下它的概念,還是利用原來的employee測試表,假如我要執行下面的sql進行查詢:SELECT * from user where name like '張%' and age=40;
假如沒有索引下推,執行的過程如下圖所示:
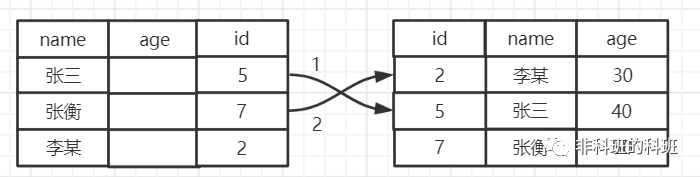
查詢會直接忽略age欄位,將name查詢的張開頭的id=5、id=7的結果返回給Mysql伺服器,再執行兩次的回表查詢。
若是上面的查詢操作使用了索引下推,執行的過程如下:
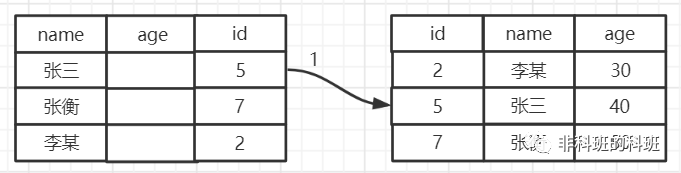
Mysql會將查詢條件age=40的查詢條件傳遞給儲存引擎,再次過濾掉age=50的資料行,這樣回表的次數就變為了一次,提高了查詢效率。
總結起來索引下推就是在執行sql查詢的時候,會將一部分的索引列的判斷條件傳遞給儲存引擎,由儲存引擎通過判斷是否符合條件,只有符合條件的資料才會返回給Mysql伺服器。
全文索引
全文索引也稱為全文檢索,可以通過以下sql建立全文索引:ALTER TABLE employee ADD FULLTEXT fulltext_name(name);或者CREATE INDEX的方式建立。
全文索引主要是針對CHAR、VARCHAR或TEXT這種文字類的欄位有效,有人說不也可以使用like關鍵字來查詢文字嗎。
普通索引(單列索引)的查詢只能加快欄位內容中最前面的字串的檢索,若是對於多個單片語成文字的查詢普通索引就無能為力了。
索引一經建立就沒有辦法修改,若是想要修改索引,必須重建,可以使用以下sql來刪除索引:DROP INDEX fulltext_name ON employee;
聚簇索引和非聚簇索引
聚簇索引和非聚簇索引是相對於儲存引擎的概念,範圍比較大,包含上面所提到的索引型別。
「聚簇索引就是葉子節點中儲存的就是完整的行資料,索引和資料儲存在一起;而非聚簇索引的索引檔案和資料檔案是分開的,所以查詢資料會多一次查詢」。
因此聚簇索引的查詢速度會快於非聚簇索引的查詢速度,在Mysql的儲存引擎中,「InnoDB支援聚簇索引,MyISAM不支援聚簇索引,MyISAM支援非聚簇索引」。
聚簇索引
下面我們來看看InnoDB中的聚簇索引,前面說到InnoDB都會有一個主鍵,該主鍵就是用於支援聚簇索引,聚簇索引結構圖,大致如下圖所示:
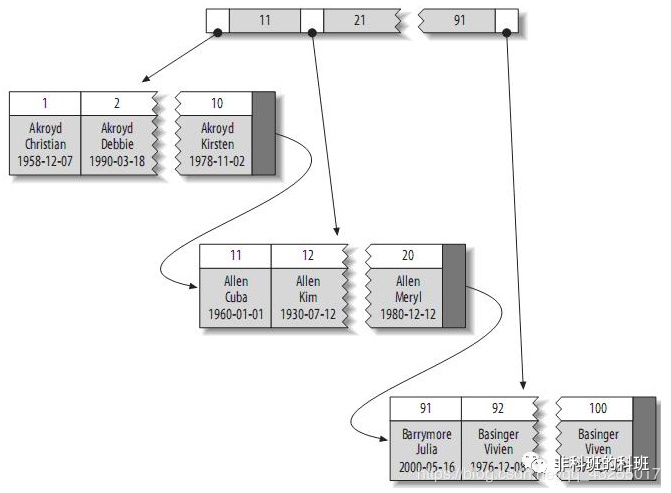
InnoDB中適用於最好的主鍵選擇就是給出一個AUTO_INCREMENT的列作為自增的主鍵,有的人可能會使用UUID作為隨機主鍵。
因為索引要維持有序性,若是使用隨機的主鍵,主鍵的插入需要尋找合適的位置進行放置,這樣維護主鍵索引樹的成本就會變得更高。
相反的,自增主鍵,主鍵都是自增變大,在維護主鍵索引樹的成本就會變得更小,所以應該儘量避免隨機主鍵。
非聚簇索引
MyISAM使用的是非聚簇索引,新插入資料的時候,會按順序的寫入的磁碟中,並且給每一行資料標記一個行號,從小逐漸增大。
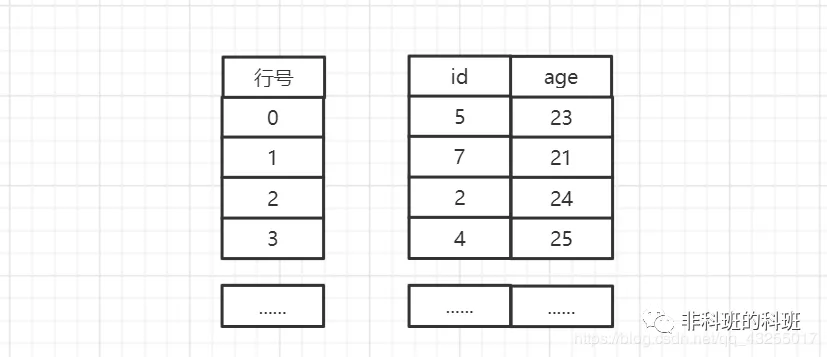
當MyISAM建立主鍵索引的時候,形成的主鍵索引樹的結構圖如下圖所示:
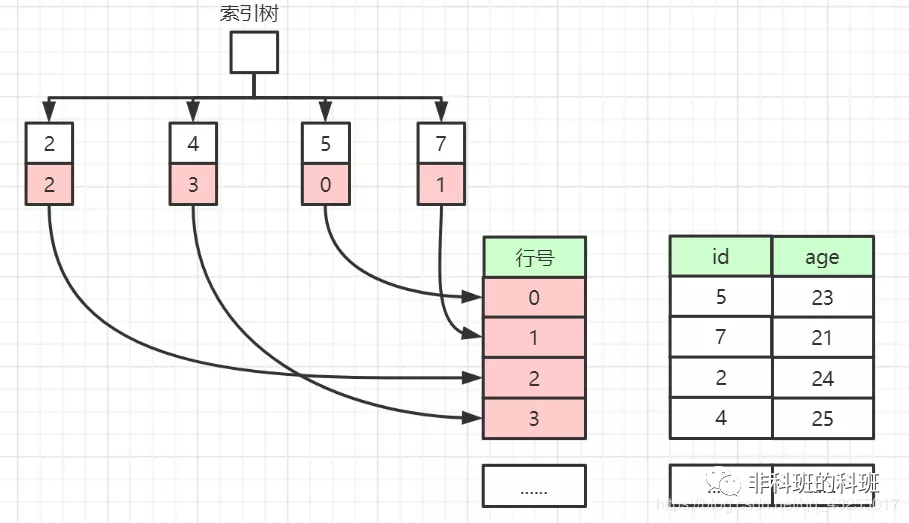
在主鍵索引中,資料也是非空且唯一,主鍵索引樹中儲存的是資料行的行號,當查詢資料的時候使用主鍵索引查詢需要查詢到行號,然後通過行號獲取資料。
非主鍵索引和主鍵索引一樣葉子節點也是儲存著行號,唯一的區別就是非主鍵索引不要求非空、唯一。
我們可以通對比圖來對比一下「InnoDB(聚簇索引)」 和 「MyISAM(非聚簇索引)」 的索引資料佈局,如下圖所示:
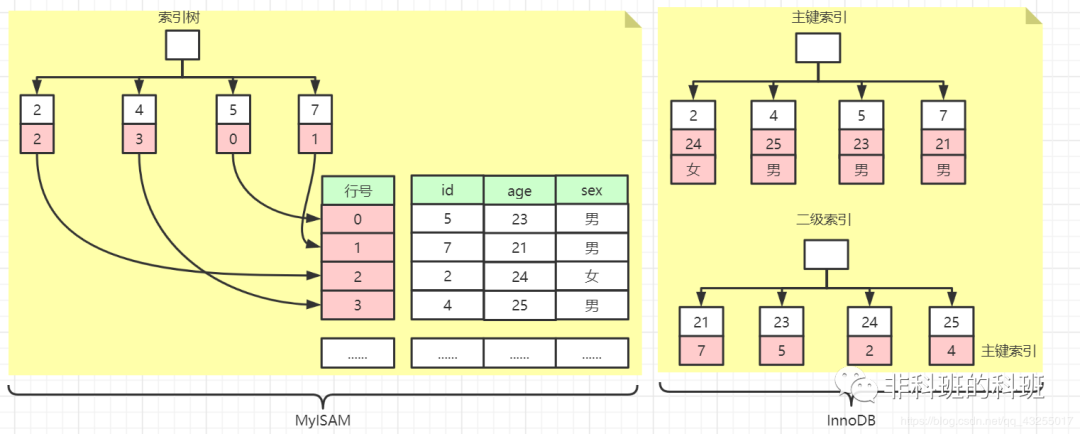
說到這裡相信應該大家對於「InnoDB(聚簇索引)」 和 「MyISAM(非聚簇索引)」 有了非常清晰的認識和理解,下面是來說一說索引的優化,這個也是和我們日常開發最密切相關的。
索引原則和優化
要正確的使用索引,就要正確的建立索引,用索引正確的查詢,不要使索引失效,因此索引的設計和優化的原則應該遵循下面的幾個原則:
- 索引列不要在表示式中出現,這樣會導致索引失效。如:「SELECT ...... WHERE id+1=5」;
- 索引列不要作為函數的引數使用。
- 索引列儘量不要使用like關鍵字。如:「SELECT ...... WHERE name like '%d%'」;
- 數位型的索引列不要當作字串型別進行條件查詢。如:「SELECT ...... WHERE id = '35'」;
- 儘量不要在條件NOT IN、<>、!= 中使用索引。
- 在索引列的欄位中不要出現NULL值,NULL值會使索引失效,可以用特殊的字元比如空字串' '或者0來代替NULL值。
- 聯合索引的查詢應該遵循最左字首原則。
- 一般對於區別性比較大的欄位建立索引,在聯合索引中區別性比較大(識別度比較高)放在最前面,提高索引的命中率。
- 索引的大小要適度,不宜過大,避免索引的冗餘。
總結
索引是我們工作經常會使用到的資料查詢方式,正確的使用索引可以大大提高查詢的效率。
- 一方面索引減少了索引伺服器需要掃描的資料行的數量,將原來的全表掃描,使用特定的資料結構,能夠快速的定位資料行。
- 另一方面使用有序的索引,避免了排序,將原來的隨機的IO操作,變成了順序的IO操作,執行有序。
但是索引也不是十全十美的,也有自己的缺點,不正確的使用索引,將會導致索引大量的佔據空間,索引並非是越多越好,索引檔案會越發的膨脹,這樣嚴重的影響查詢的效能。
對於插入、更新 、刪除資料,除了維護資料以外,還要維護索引檔案,這樣也會影響這些操作的效能,但是對於查詢的頻率遠高於更新和插入資料的業務場景,索引是再適合不過了。
以下文章來源於非科班的科班 ,作者黎杜