你不知道的redis六-redis主從複製,因為該命令redis作者曾攤上事?
目錄
一、什麼是主從複製
主從複製就是我們建立資料存檔的時候,將一份資料進行復制儲存多分儲存在不同的機器上。
二、為什麼要用主從複製
在redis持久化機制一文中,我們已經提到為了防止資料丟失,redis提供了RDB和AOF兩種方式持久化資料,將記憶體的資料持久化到磁碟上。但是當出現伺服器出現故障,比如服務磁碟壞掉導致資料不可恢復時。那又該怎麼辦呢?
那麼為了避免單點故障,我們需要將資料複製多份部署在多臺不同的伺服器上,即使有一臺伺服器出現故障其他伺服器依然可以繼續提供服務。這就要求當一臺伺服器上的資料更新後,自動將更新的資料同步到其他伺服器上,這就是主從複製。
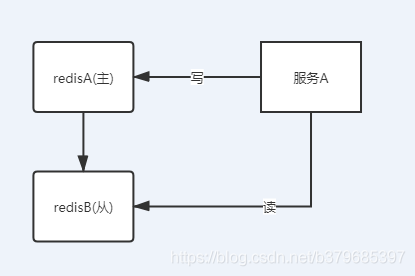
當我們主節點壓力比較大時,那麼我們可以通過讀寫分離的方式,對複製的節點資料進行讀操作,以增加我們的服務效能
,總結來講使用主從複製有以下原因
- 資料備份,容災恢復
- 業務資料讀寫分離
三、redis主從複製實現
redis實現主從很簡單,只需要增加啟動指令碼或者組態檔中設定slaveof命令即可
1、啟動命令
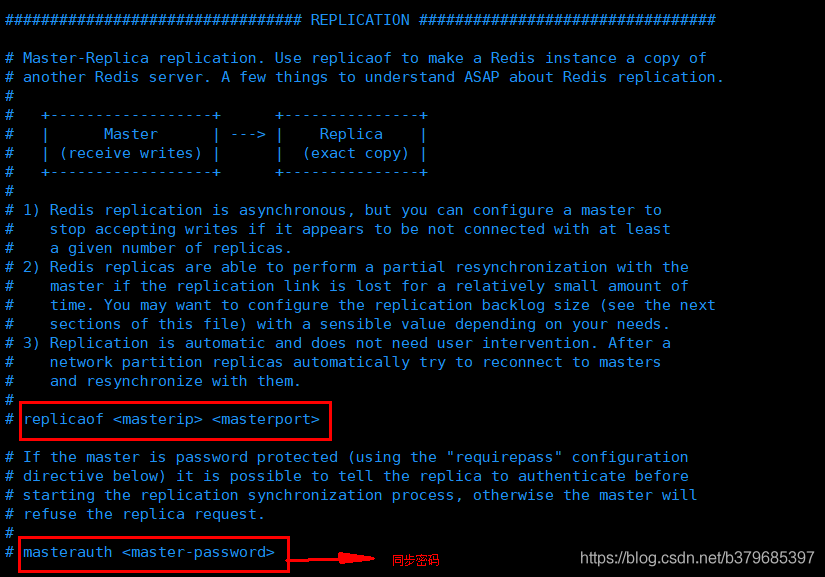
啟動redis服務時,後面新增 redis-server --slaveof ip(主redisip) port。
該設定到5.0版本以上改為了 replicaof <masterip> <masterport>,Redis 作者在 GitHub 上發起了一個「用其他詞彙代替 Redis 的主從複製術語」的 issue因為有人認為 Redis 中的術語 master/slave (主人 / 奴隸)冒犯到了別人(果然歪果仁們對這還是敏感啊,哈哈),要求 Redis 作者 ANTIREZ 修改這個術語,甚至連 ruby on rails 的作者 DHH 都在表態。

2、組態檔新增
環境兩臺機器:148.70.47.76(主),111.229.169.46(從)
1、148.70.47.76直接啟動redis
2、修改111.229.169.46redis設定,新增slaveof 148.70.47.76 6379 設定或者使用replicaof設定

5.0以上
3、啟動111.229.169.46 的redis
4、檢視148.70.47.76 redis狀態,發現role 為master主節點,有一個從節點,從節點ip為111.229.169.46(該資訊很重要,哨兵機制會用到)
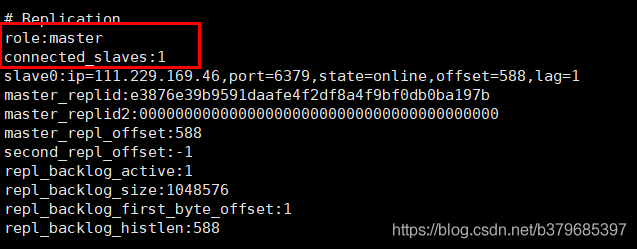
檢視111.229.169.46 redis狀態,發現role 為slave從節點,有一個主節點,主節點ip為148.70.47.76.
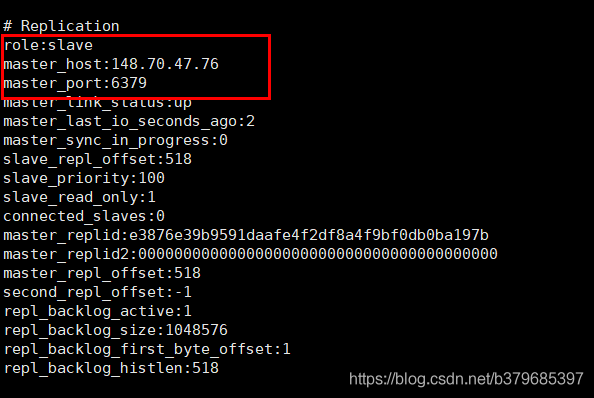
3、Tips:
- 設定主從為了安全性可以修改組態檔的masterauth屬性來增加同步密碼
- 從節點建議用唯讀模式slave-read-only=yes, 若從節點修改資料,主從資料不一致.
- 傳輸延遲:主從一般部署在不同機器上,複製時存在網路延時問題,redis 提供repl-disable-tcp-nodelay 引數決定是否關閉TCP_NODELAY,預設為關閉.引數關閉時:無論大小都會及時釋出到從節點,佔頻寬,適用於主從網路好的場景.引數啟用時:主節點合併所有資料成TCP 包節省頻寬,預設為40 毫秒發一次,取決於核心,主從的同步延遲40 毫秒,適用於網路環境複雜或頻寬緊張,如跨機房
四、主從複製原理
1、主要流程
redis主從主要流程如下:
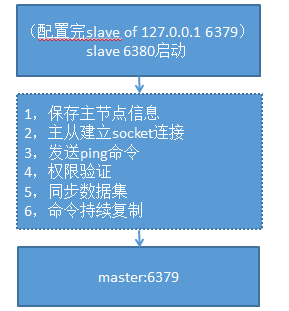
redis的資料同步主要分為全量同步和增量同步
2、全量同步
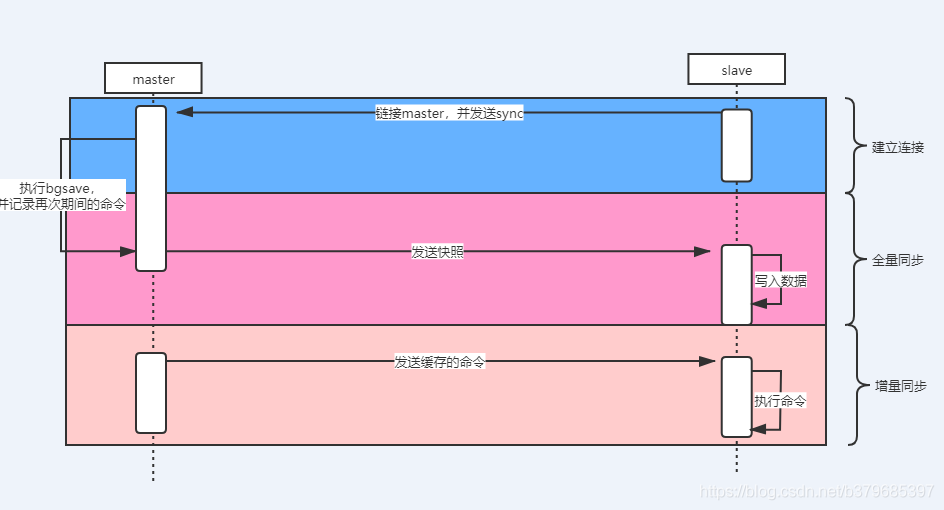
Redis全量複製一般發生在Slave初始化階段,這時Slave需要將Master上的所有資料都複製一份。
master伺服器會開啟一個後臺程序用於將redis中的資料生成一個rdb檔案,與此同時,伺服器會快取所有接收到的來自使用者端的寫命令(包含增、刪、改),當後臺儲存程序處理完畢後,會將該rdb檔案傳遞給slave伺服器,而slave伺服器會將rdb檔案儲存在磁碟並通過讀取該檔案將資料載入到記憶體,在此之後master伺服器會將在此期間快取的命令通過redis傳輸協定傳送給slave伺服器,然後slave伺服器將這些命令依次作用於自己原生的資料集上最終達到資料的一致性。
具體步驟如下:
- 從伺服器連線主伺服器,傳送SYNC命令;
- 主伺服器接收到SYNC命名後,開始執行BGSAVE命令生成RDB檔案並使用緩衝區記錄此後執行的所有寫命令;
- 主伺服器BGSAVE執行完後,向所有從伺服器傳送快照檔案,並在傳送期間繼續記錄被執行的寫命令;
- 從伺服器收到快照檔案後丟棄所有舊資料,載入收到的快照;
- 主伺服器快照傳送完畢後開始向從伺服器傳送緩衝區中的寫命令;
- 從伺服器完成對快照的載入,開始接收命令請求,並執行來自主伺服器緩衝區的寫命令;
3、增量同步
Redis增量複製是指Slave初始化後開始正常工作時主伺服器發生的寫操作同步到從伺服器的過程。
增量複製的過程主要是主伺服器每執行一個寫命令就會向從伺服器傳送相同的寫命令,從伺服器接收並執行收到的寫命令。
4、Redis主從同步策略
主從剛剛連線的時候,進行全量同步;全同步結束後,進行增量同步。當然,如果有需要,slave 在任何時候都可以發起全量同步。redis 策略是,無論如何,首先會嘗試進行增量同步,如不成功,要求從機進行全量同步。
五、主從複製幾種架構形式
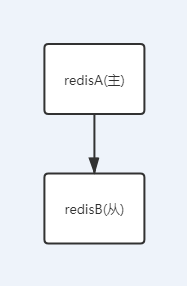
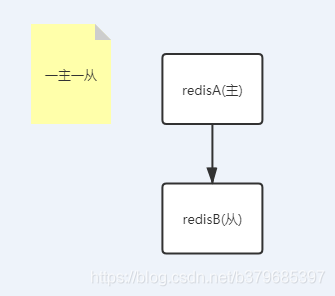
1、一主一從
用於主節點故障轉移從節點,當主節點的「寫」命令並行高且需要持久化,可以只在從節點開啟AOF(主節點不需要),增加主節點效能,主節點異常時可以通過從節點備份進行恢復。
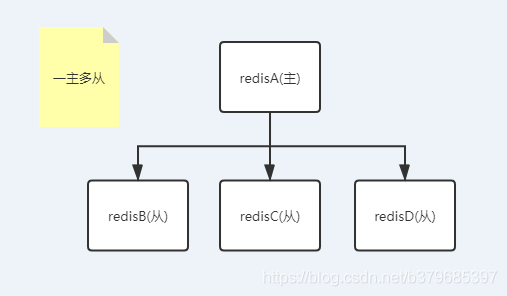
2、一主多從
針對「讀」較多的場景,「讀」由多個從節點來分擔,但節點越多,主節點同步到多節點的次數也越多,影響頻寬,也加重主節點的穩定
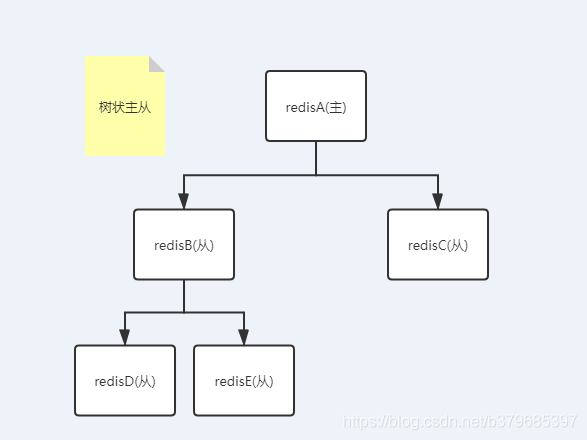
3、樹狀主從
一主多從的缺點(主節點推播次數多壓力大)可用些方案解決,主節點只推播一次資料到從節點1,再由從節點2推播到11,減輕主節點推播的壓力