終於來了...RocketMQ掃盲篇
欄目今天詳細介紹有關RocketMQ知識。

又是好久沒有寫部落格了,雖然可以找出無數個沒有寫的部落格的理由,但是說到底,還是一個字「懶」。今天我終於吃了一顆治療懶癌的藥丸,決定寫一篇部落格。介紹什麼好呢,思來想去,還是介紹下RocketMQ吧,畢竟寫了30多篇部落格,還沒有好好寫過關於MQ的部落格呢。本篇部落格比較基礎,不涉及到原始碼分析,只是掃盲。
MQ有什麼用
解耦
我覺得從某種角度來說,微服務促進了MQ的蓬勃發展,本來一個系統有N多個模組,所有模組都強耦合在一起,現在微服務了,一個模組就是一個系統,系統之間肯定需要互動,互動有三種常見的方法,一種是RPC,一種是HTTP,一種就是MQ了。
非同步
原本一個業務分為N步,要一步一步處理,才能把最終的結果返回給使用者,現在有了MQ,先把最關鍵的部分處理完畢,然後傳送訊息到MQ,直接返回給使用者OK,至於後面的步驟在後臺慢慢處理吧,真乃提升使用者體驗的神器。
削峰
某個介面的請求量突然飆升,勢必會對應用伺服器、資料庫伺服器造成很大的壓力,現在有了MQ,來多少請求都不在怕的,後臺慢慢處理唄。
RocketMQ簡介
RocketMQ是用Java編寫的,是阿里開源的訊息中介軟體,吸收了Kafka很多優點。Kafka也是比較熱門的訊息中介軟體,不過Kafka是用Scala編寫的,不利於Java程式設計師去閱讀原始碼,也不利於Java程式設計師做一些客製化化的開發。接觸過Kafka的小夥伴都知道,要用好Kafka實屬不易,相對來說,RocketMQ簡單多了,而且RocketMQ有阿里加持,經歷了N次雙11的考驗,比較適合國內網際網路公司,所以國內使用RocketMQ的公司很多。
RocketMQ四大元件
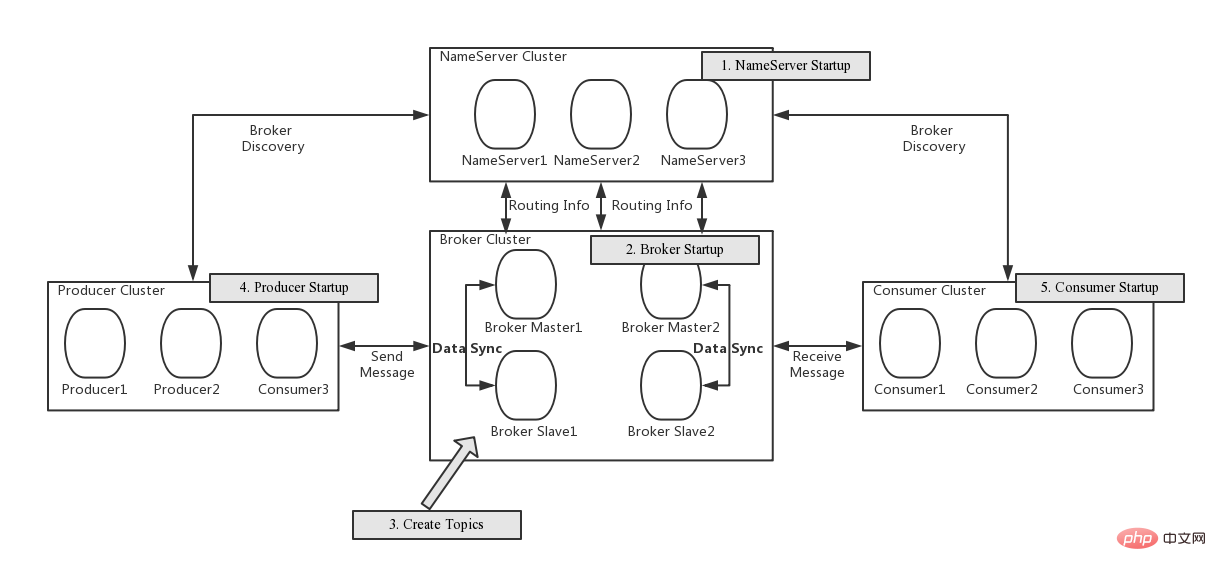 圖片來自gitee.com/mirrors/roc…
圖片來自gitee.com/mirrors/roc…
可以看到RocketMQ主要有四個元件:
NameServer
- 無狀態服務,註冊中心,可叢集部署,但是NameServer節點之間沒有任何資料互動。
- Borker會以定時把Topic路由資訊上報給所有的NameServer。Producer、Consumer會隨機選擇一個NameServer定時Topic更新路由資訊。
- Topic路由資訊在NameServer叢集中採用最終一致性。
- 保證AP。
Borker
- RocketMQ的伺服器端,用於儲存訊息、分發訊息。
- Borker會定時把自身擁有的所有的Topic路由資訊上報給NameServer。
- Borker有兩個角色:Master、Follower,Master承擔讀(消費訊息)寫(生產訊息)操作,如果Master比較忙,或者不可用,Follower可以承擔讀操作。BorkerId=0,代表是Matser,BorkerId!=0,代表是Follower,需要注意的有兩點: 其一,目前為止,BorkerId=1的Follower才可以承擔讀操作; 其二,只有較高版本的RocketMQ才支援當Master節點掛掉,Follower自動升級到Master。
Producer
生產者,每隔一定時間向NameServer發起Topic的路由資訊查詢。
Consumer
消費者,每隔一定時間向NameServer發起Topic的路由資訊查詢。
為什麼註冊中心不選用Zookeeper
其實,在低版本的RocketMQ中,確實是選用Zookeeper作為註冊中心的,但是後面改成了現在的NameServer,猜想主要原因是:
- RocketMQ已經是一箇中介軟體了,不想再依賴其他中介軟體。
- Zookeeper比較重,有很多功能RocketMQ是用不到的,不如寫一個輕量級的註冊中心。
- Zookeeper是CP,一旦觸發領導選舉,那麼註冊中心就不可用了,而RocketMQ的註冊中心,不需要強一致性,只要保證最終一致性。
RocketMQ訊息領域模型
Message
- 傳輸的訊息。
- 訊息必須有Topic。
- 訊息可以有多個Tag和多個Key,可以看做訊息的附加屬性。
Topic
- 一類訊息的集合。
- 每個訊息必須有一個Topic。
- 訊息的第一級型別。
Tag
- 一個訊息除了有Topic之外,還可以有Tag,用來細分同一個Topic下的不同種類的訊息。
- Tag不是必須的。
- 訊息的第二級型別。
Group
分為ProducerGroup,ConsumerGroup,我們更多的是關注ConsumerGroup,ConsumerGroup包含多個Consumer。
在叢集消費模式下,一個ConsumerGroup下的Consumer共同消費一個Topic,且每個Consumer會被分配到N個佇列,但是一個佇列只會被一個Consumer消費,不同的ConsumerGroup可以消費同一個Topic,一條訊息會被訂閱此Topic的所有ConsumerGroup消費。
Queue
- 一個Topic預設包含四個Queue。
- 在叢集消費模式下,同一個ConsumerGroup中的Consumer可以消費多個Queue的訊息,但是一個Queue只能被一個Consumer消費。
- Queue中的訊息是有序的。
- 分為讀Queue和寫Queue,一般來說,讀Queue的數量和寫Queue的數量是一致的,否則很容易出問題。
消費模式
消費模式有兩種:Clustering(叢集消費)和Broadcasting(廣播消費)。
和其他MQ不同,其他MQ是在傳送訊息的時候,指定是叢集消費還是廣播消費,RocketMQ是在消費者端設定是叢集消費還是廣播消費。
Clustering(叢集消費)
預設情況下是叢集消費模式,該模式下,ConsumerGroup所有的Consumer共同消費一個Topic的訊息,每個Consumer負責消費N個佇列的訊息(N也可能為1,甚至是0,沒有分配到佇列),但是一個佇列只會被一個Consumer消費。如果某個Consumer掛掉,ConsumerGroup下的其他Consumer會接替掛掉的Consumer繼續消費。
叢集消費模式下,消費進度維護在Borker端,儲存路徑為${ROCKET_HOME}/store/config/ consumerOffset.json,如下圖所示: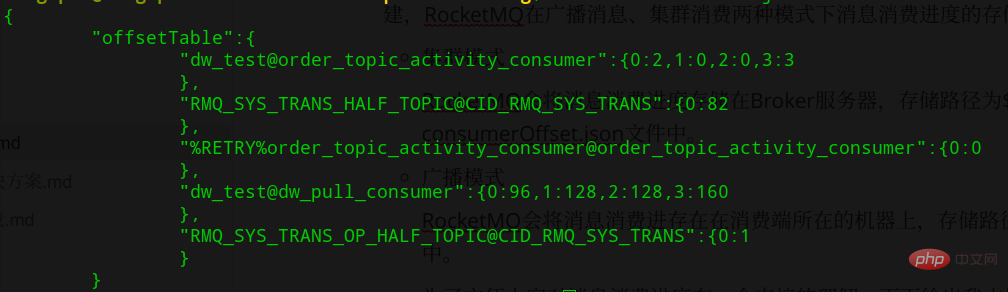 使用
使用topicName@consumerGroupName為Key,消費進度為Value,Value的形式是queueId:offset ,說明如果有多個ConsumerGroup,每個ConsumerGroup的消費進度是不同的,需要分開來儲存。
Broadcasting(廣播消費)
廣播消費訊息會發給ConsumerGroup中所有的Consumer。
廣播消費模式下,消費進度維護在Consumer端。
消費佇列負載演演算法與重平衡機制
消費佇列負載演演算法
我們知道了在叢集消費模式下,ConsumerGroup下所有的Consumer共同消費一個Topic的訊息,每個Consumer負責消費N個佇列的訊息,那麼具體是如何分配的呢?這就涉及到消費佇列負載演演算法了。
RocketMQ提供了眾多的消費佇列負載演演算法,其中最常用的是兩種演演算法,即AllocateMessageQueueAveragely、AllocateMessageQueueAveragelyByCircle。下面我們來看下這兩個演演算法的區別。
假設,現在一個Topic有16個佇列,用q0~q15表示,有3個Consumer,用c0-c2表示。
用AllocateMessageQueueAveragely消費佇列負載演演算法的結果如下:
- c0:q0 q1 q2 q3 q4 q5
- c1:q6 q7 q8 q9 q10
- c2:q11 q12 q13 q14 q15
用AllocateMessageQueueAveragelyByCircle消費佇列負載演演算法的結果如下:
- c0:q0 q3 q6 q9 q12 q15
- c1:q1 q4 q7 q10 q13
- c2:q2 q5 q8 q11 q14
ConsumerGroup下所有的Consumer共同消費一個Topic的訊息,每個Consumer負責消費N個佇列的訊息,但是一個佇列不能同時被N個Consumer消費,這意味著什麼?
聰明的你一定可以想到,如果一個Topic只有4個佇列,而有5個Consumer,那麼有一個Consumer將不能分配到任何佇列,所以在RocketMQ中,Topic下佇列的個數直接決定了Consumer的最大個數,也就說明,不能光靠增加Consumer來提高消費速度。
重平衡
雖然建議在建立Topic的時候,就應該充分考慮佇列的個數,但是實際情況往往是不盡人意的,哪怕佇列數沒有發生改變,Consumer的數量也一定會發生改變,比如Consumer的上下線,比如某個Consumer掛了,比如新增了Consumer。佇列的擴容、縮容,Consumer的擴容、縮容都會導致重平衡,也就是為Consumer重新分配消費的佇列。
在RocketMQ中,Consumer會定時查詢Topic的佇列的個數,Consumer的個數,如果發生了改變,就會觸發重平衡。
重平衡是RocketMQ內部實現的,程式設計師無需關心。
Pull OR Push?
一般來說,MQ有兩種方法獲取訊息:
- Pull:Consumer主動拉取訊息,好處是Consumer可以控制拉取訊息的頻率,條數,Consumer知道自身的消費能力,所以在Consumer端不容易造成訊息堆積,但是實時性不是太好,效率相對較低。
- Push:Broker主動傳送訊息,好處是實時性、效率比較高,但是Broker無法知道Consumer端的消費能力,如果發給Consumer的訊息過多,會造成Consumer端的訊息堆積;如果發給Consumer的資料太少,又會造成Consumer端的空閒。
不管是Pull,還是Push,Consumer總會與Broker產生互動,互動的方式一般有短連線、長連線、輪詢三種方式。
看起來,RocketMQ支援既支援Pull,也支援Push,但是實際上Push也是用Pull實現的,那麼Consumer是怎麼與Broker產生互動的呢?
這就是RocketMQ設計的巧妙的地方了,既不是短連線,也不是長連線,也不是輪詢,而是採用的長輪詢。
長輪詢
Consumer發起拉取訊息的請求,分為兩種情況:
- 有訊息:Consumer拿到訊息後,連線斷開。
- 沒有訊息:Borker Hold(保持)住連線一定時間,每隔5秒,檢查下是否有訊息,如果有訊息,給Consumer,連線斷開。
事務訊息
RocketMQ支援事務訊息,Producer把事務訊息傳送給Broker後,Broker會把訊息儲存在系統Topic:RMQ_SYS_TRANS_HALF_TOPIC,這樣Consumer就無法消費到這條訊息了。
Broker會有一個定時任務,消費RMQ_SYS_TRANS_HALF_TOPIC的訊息,向Producer發起回查,回查的狀態有三種:提交、回滾、未知。
- 如果回查的狀態是提交,回滾,會觸發訊息的提交和回滾;
- 如果是未知,會等待下一次回查,RocketMQ可以設定一條訊息的回查間隔與回查次數,超過一定的回查次數,訊息會自動回滾。
延遲訊息
延遲訊息是指息發到Broker後,不能立刻被Consumer消費,需要等待一定的時間才可以被消費到,RocketMQ只支援特定的延遲時間:1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h。
消費形式
RocketMQ支援兩種消費形式:並行消費、順序消費。 如果是順序消費,需要保證排序的訊息在同一個佇列。如何選擇佇列傳送呢,RocketMQ傳送訊息的方法有好幾個過載,其中有一個過載方法支援佇列的選擇。
同步刷盤、非同步刷盤
Producer把訊息傳送到Borker中,Borker是需要把訊息持久化的,RocketMQ支援兩種持久化策略:
- 同步刷盤:Borker把訊息持久後才返回ACK給Producer,好處是訊息可靠性高,但是效率較慢。
- 非同步刷盤:Broker把訊息寫入到PageCache中,就返回ACK給Producer。好處是效率極高,但是如果伺服器掛了,訊息可能會丟失,如果只是RocketMQ服務掛了,不會造成訊息丟失。
同步複製、非同步複製
為了MQ的可靠性、可用性,在生產環境,一般會部署Follower節點,Follower節點會複製Master的資料,RocketMQ支援兩種持複製策略:
- 同步複製:Master、Follower都把訊息寫入成功,才返回ACK給Producer,可靠性較高,但是效率較慢。
- 非同步複製:只要Master寫入成功,就返回ACK給Producer,效率較高,但是可能會丟失訊息。
"寫入"是寫入PageCache,還是寫入硬碟,要看Follower Broker的設定。
再談談Producer
RocketMQ提供了三種傳送訊息的方法:
- oneway:fire and forget,單向訊息,指訊息傳送出去後,就不管了,這個方法是沒有返回值的。
- 同步:訊息傳送出去後,同步等待Borker的響應。
- 非同步:訊息傳送出去後,立即返回,收到Boker的響應後,會執行函調方法。
在實際開發中,一般選用同步方法,如果要提高RocketMQ的效能,一般都是修改Borker端的引數,特別是刷盤策略和複製策略。
傳送訊息重試
訊息傳送時,如果使用了MessageQueueSelector,那訊息傳送的重試機制將會失效。
傳送訊息響應可能為以下四種:
public enum SendStatus {
SEND_OK,
FLUSH_DISK_TIMEOUT,
FLUSH_SLAVE_TIMEOUT,
SLAVE_NOT_AVAILABLE,
}複製程式碼除了第一種,其他情況都是有問題的,為了保證訊息不丟失,需要設定Producer引數:RetryAnotherBrokerWhenNotStoreOK為true。
故障規避機制
如果訊息傳送失敗了,重試的時候,還是傳送給這個Borker,那麼大概率傳送還是失敗的,RockteMQ設計精巧之處在於,重試的時候,會自動避開這個Borker,而選擇其他Borker,但是目前為止,非同步傳送沒有那麼智慧,只會在一個Borker上重試,所以強烈建議選擇同步傳送方式。
RocketMQ提供了兩種故障規避機制。用引數SendLatencyFaultEnable來控制。
- false:預設值,只有在重試的時候,才會啟用故障規避機制,比如傳送訊息給BorkerA失敗了,重試的時候,會選擇BorkerB,但是下次傳送訊息,還是會選擇傳送給BorkerA。
- true:開啟延遲退避機制,一旦訊息傳送給BorkerA失敗,就會悲觀的認為在一段時間內,BorkerA不可用,在將來的一段時間內,不會再向BorkerA傳送訊息。
延遲退避機制看起來很好用,但是一般來說Borker端繁忙,導致Borker不可用或者網路不可用只是一瞬間的事情,馬上就可以恢復,如果開啟了延遲退避機制,本來可用的Borker在一段時間內卻被規避了,其他Borker更加繁忙,那可能情況更糟糕。
再談談Consumer
Consumer執行緒注意事項
Consumer有兩個引數,可以消費的並行度,即ConsumeThreadMin、ConsumeThreadMax,看起來給人的感覺是,如果Consumer端堆積訊息比較少,消費執行緒數為ConsumeThreadMin;如果Consumer端堆積訊息比較多,就自動開啟新的執行緒來消費,直到消費執行緒數為ConsumeThreadMax。但是並不是這樣,Consumer內部持有一個執行緒池,選用的是無界佇列,也就是ConsumeThreadMax引數是無效的,所以在實際開發中,ConsumeThreadMin、ConsumeThreadMax往往設定成一樣。
ConsumeFromWhere
如果查詢不到消費進度的時候,Consumer從哪裡開始消費,RocketMQ支援從最新訊息、最早訊息、指定時間戳這三種方式進行消費。
消費訊息重試
RocketMQ會為每個ConsumerGroup都設定一個Topic名稱為%RETRY%+consumerGroup的重試佇列,用來儲存需要給ConsumerGroup重試的訊息,但是重試需要一定的延時時間,RocketMQ對於重試訊息的處理是先儲存至Topic名稱為SCHEDULE_TOPIC_XXXX的延遲佇列中,後臺定時任務按照對應的時間進行Delay後重新儲存至%RETRY%+consumerGroup的重試佇列中。
訊息堆積、消費能力不夠,怎麼辦
- 提高消費進度,這是最好的辦法。
- 增加佇列,增加Consumer。
- 原先的Consumer作為搬磚工,根據一定的規則把訊息「搬」到多個新的Topic,再開幾個ConsumerGroup去消費不同的Topic。
- 新開一個ConsumerGroup去消費,也就是兩個ConsumerGroup同時消費一個Topic,但是需要注意offset的判斷,比如一個ConsumerGroup消費offset為奇數的訊息,一個ConsumerGroup消費offset為偶數的訊息。
本來以為寫掃盲文,應該會寫的很順,但是還是想多了,因為是掃盲文,面向的是沒有怎麼接觸過RocketMQ的小夥伴,但是RocketMQ有沒有那麼簡單,不可能用一篇部落格,就讓沒有怎麼接觸過RocketMQ的小夥伴順利入門,所以在寫部落格的時候,一直在想,這個東西重要嗎,需要仔細描述嗎;這個東西可以忽視,可以不介紹嗎 等等,大家可以看到本文基本都是在介紹各種概念,幾乎沒有涉及到API的層面,因為一旦涉及到API,那麼估計寫兩個星期也寫不完。
End
相關免費學習推薦:
以上就是終於來了...RocketMQ掃盲篇的詳細內容,更多請關注TW511.COM其它相關文章!