Python爬蟲練習1_小作文下載
2020-10-20 11:00:40
作文下載
準備工具
- 本機環境:Windows10專業版
- 作業系統:64位元
- Python版本:python 3.8
- 執行工具:PyCharm 2020.2
步驟分析與程式碼實現
開始之前先匯入一些庫
import requests
from lxml import etree
-
獲取網頁原始碼
開啟一個網站分析一下
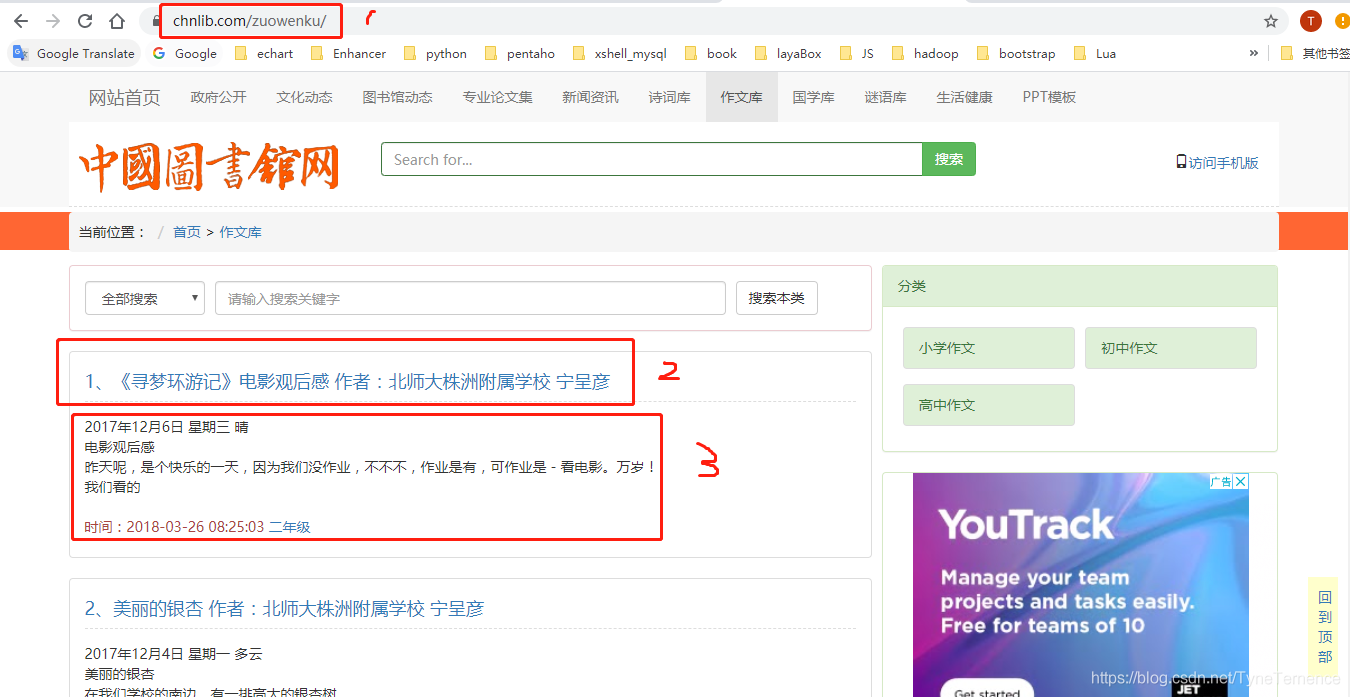
1就是url
2是文章標題
3是內容
之後會放程序式碼裡,先獲取到這個介面的網頁url = requests.get('https://www.chnlib.com/zuowenku/') html = url.content.decode()#對亂碼處理,這裡沒寫內容預設值就是‘UTF-8’ print(html)返回結果

這就是網頁的程式碼,這就證明我們存取到這個頁面了。 -
獲取作文篇章的url
已經可以獲取到網頁原始碼了,接下來就解析我們要的文章在哪裡,可以看到介面是每一個文章都是有一個連結的,F12可以檢視網頁原始碼。點選右上角小箭頭,選中網頁的作文,可以在右邊看見一個<a>標籤這就是文章的連結,每一個文章都需要開啟一個連結。
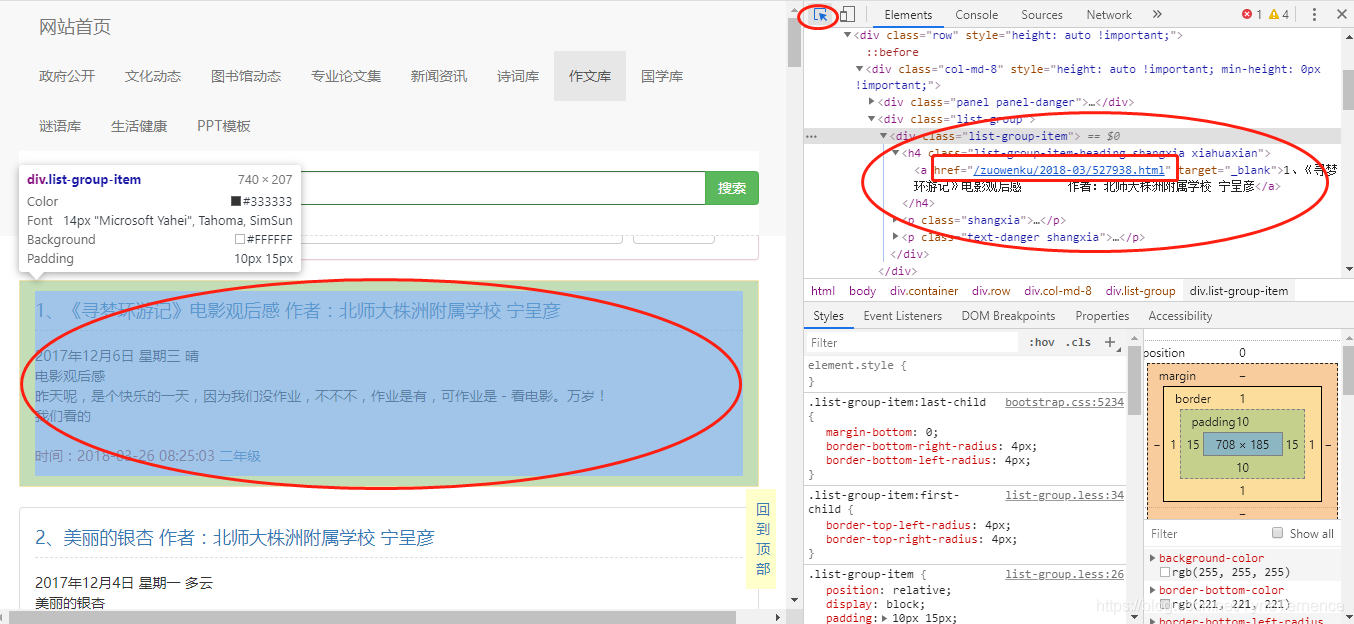
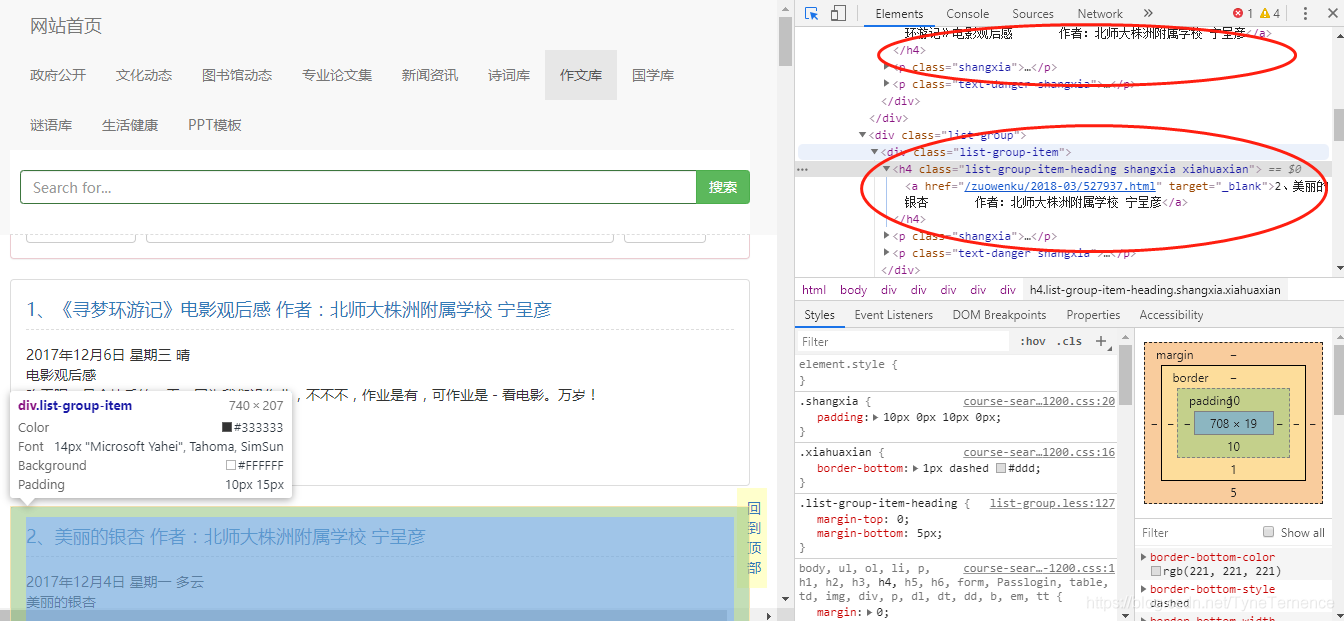
下面就要解析一下,怎麼獲取這些連結,通過原始碼可以看出他們都是統一的格式都是在一個<div>下面有一個<h4>再下面獲取<a>,下面就用xpath來獲取這個<h4>標籤,簡單的方法就是在頁面上右擊<h4>有一個copy-> copy xpath 可以直接獲取xpath路徑- 構造一個xpath用來解析
doc = etree.HTML(html) #構造xpath解析物件@選取物件 contents = doc.xpath('//*[@class="list-group"]/div') print(contents)
檢視一下contents發現是一個Element,看不到內容,這個時候就需要遍歷這個Element,用for in去取<h4>下面<a>中的href- 獲取每一個文章的url
for content in contents: links = content.xpath('h4/a/@href') #獲取超連結 print(links)
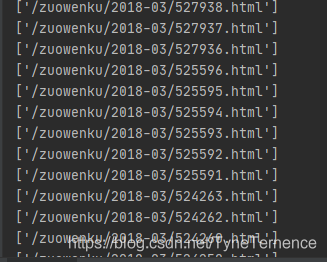
這樣每一篇文章的url都獲取到了,接下來就該獲取每一篇文章的標題以及內容。下面仍然用xpath的方式去獲取。- 獲取標題和文章內容
至此每一篇文章的標題和內容都獲取到,最後把獲取到的資料儲存下來content = doc.xpath('//*[@id="content"]/p/text()')#獲取文字 title = doc.xpath('/html/body/div[4]/div/div[1]/div/div[1]/h1/text()') #獲取標題 title1 = [t.replace('\r\n','') for t in title]
-
儲存資料
with open('download/%s.txt' %title1[0], 'w', encoding='utf-8') as f: for items in content: f.write(items)