巨量資料之坑:騰訊雲Hadoop3.1.3安裝及叢集環境搭建完全分散式
前言
因為課程學習需要,加上本機電腦的不便利性,筆者採用的是三臺騰訊雲的租用伺服器(學生款價效比挺高的),由於在安裝以及環境搭建過程中出現了許多問題,查詢了相當多的資料,歷經幾番波折,於是在此分享一下自己較為全面的操作過程,希望能夠幫到各位解決問題。
騰訊雲伺服器系統 CentOs
三臺伺服器分別名稱代號為:master slave1 slave2
1.環境設定
1.1 jdk安裝
Tips:機器已為Linux系統
在master機器節點(自行決定哪臺機器作為master節點)進行操作:
- 切換到root模式下,避免許可權問題。(執行程式碼:su root ,然後輸入密碼即可)(如果已經是root使用者模式下則忽略此條操作)
- 下載jdk檔案
此處推薦華為映象站的jdk(1.8.0)檔案網址
優點:下載速度賊快,非常絲滑
wget https://repo.huaweicloud.com/java/jdk/8u151-b12/jdk-8u151-linux-x64.tar.gz
- 新建java資料夾用於jdk解壓
下載完之後,在usr資料夾下建立一個java資料夾
mkdir /usr/java
-
解壓jdk檔案至剛剛建立的資料夾
tar -zxvf +jdk的名字(可從下載操作處檢視到) -C +解壓路徑(本文為/usr/java)
下述程式碼為本文執行程式碼(如果你完全按照本文操作可直接執行該程式碼)
tar -zxvf jdk-8u151-linux-x64.tar.gz -C /usr/java
- 設定java環境變數
1.開啟組態檔
vim /etc/profile
2.修改組態檔(隨便找個位置加入以下內容)
注:Linux下檔案內容修改:鍵入i之後即可編輯檔案內容,編輯完成之後按esc,輸入符號:加入末行模式,然後輸入wq儲存退出
export JAVA_HOME=/usr/java/jdk1.8.0_151
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
3.使環境變數生效
source /etc/profile
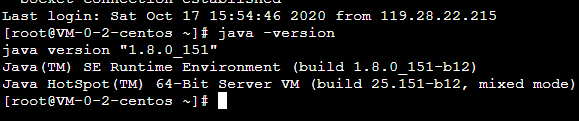
4.結果測試
java -version
如果能夠返回java版本號則jdk安裝成功(如下圖)
1.2 防火牆關閉
- 執行如下程式碼
sudo systemctl stop firewalld.service
sudo systemctl disable firewalld.service
1.3 修改hosts檔案
在前言中末尾提到過筆者的叢集為三臺機器,所以筆者的hosts檔案中ip對映有三行自己新增的程式碼,大家可以根據自己實際情況適當修改,但是此處ip對映關係一定不能出錯!!
-
對於master結點,需要在檔案末尾新增的內容為:
master結點的內網ip master
另一個機器1的公網ip slave1
另一個機器2的公網ip slave2 -
對於slave1結點,需要在檔案末尾新增的內容為:
master結點的公網ip master
slave1結點的內網ip slave1
另一個機器2的公網ip slave2 -
對於slave2結點,需要在檔案末尾新增的內容為:
master結點的公網ip master
slave1結點的公網ip slave1
slave2結點的內網ip slave2
總而言之,對於自己機器上的ip對映就填自己的內網ip,自己機器上對其他ip的對映就是他們的公網ip
1.4 建立hadoop使用者(跳過)
由於非root使用者可能涉及許可權問題,於是本文直接使用root使用者進行後續操作
2.建立機器間互信
2.1描述
由於hadoop必須機器之間免密登入,所以我們必須採取ssh金鑰認證方式去保證機器登入。
- 機器a向機器b建立免密登入的流程
1.機器a生成公鑰
2.機器a將認證檔案傳給機器b
3.機器a成功單向建立與機器b的免密登入(即a可以免密登入b但b不能免密登入a,只需要在b上執行上述機器a的所有操作即可完成b到a的免密登入)
2.2 生成公鑰
ssh-keygen
- 遇到提示直接全回車就行,成功後會出現一個奇形怪狀內容的矩形框,檔頭為RSA
- 成功之後會在 ~/.ssh資料夾下面看到id_rsa id_rsa.pub檔案(為root使用者登入情況下,可能會有authorized_keys檔案,問題不大)
跳轉至~/.ssh資料夾下
cd ~/.ssh
檢視檔案內容
ls
2.3 傳輸認證檔案
- 傳遞至localhost
ssh-copy-id localhost
檢查是否成功
ssh localhost
第一次登入時需要輸入一次本機root使用者登入密碼,輸入進去即可,然後再次鍵入程式碼:
ssh localhost
如果不需要輸入密碼即出現了日期資訊,則傳遞至localhost成功
- 傳遞至slave1
傳遞時需要輸入一次 slave1結點上的 root使用者的登入密碼
ssh-copy-id slave1
檢查是否成功
ssh slave1
如果不需要輸入密碼即出現了日期資訊,則傳遞至slave1成功
- 傳遞至slave2
傳遞時需要輸入一次 slave2結點上的 root使用者的登入密碼
ssh-copy-id slave2
檢查是否成功
ssh slave2
如果不需要輸入密碼即出現了日期資訊,則傳遞至slave2成功
3.安裝hadoop以及hadoop設定
3.1 hadoop下載(3.1.3)
- 跳轉至根目錄
cd
- hadoop檔案下載
此處推薦使用清華映象的下載連結(縱享絲滑+1了):
wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.1.3/hadoop-3.1.3.tar.gz
- 新建hadoop資料夾用於解壓
下載完之後,在usr資料夾下建立一個hadoop資料夾
mkdir /usr/hadoop
-
解壓hadoop檔案至剛剛建立的資料夾
tar -zxvf +下載檔案的名字(可從下載操作處檢視到) -C +解壓路徑(本文為/usr/hadoop)
下述程式碼為本文執行程式碼(如果你完全按照本文操作可直接執行該程式碼)
tar -zxvf hadoop-3.1.3.tar.gz -C /usr/hadoop
- 設定環境變數
vim /etc/profile
將之前設定jdk時候的內容替換為:
export JAVA_HOME=/usr/java/jdk1.8.0_151
export HADOOP_HOME=/usr/hadoop/hadoop-3.1.3
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$PATH
export PATH=$PATH:$HADOOP_HOME/sbin
export HADOOP_LOG_DIR=/usr/hadoop/hadoop-3.1.3/logs
export YARN_LOG_DIR=$HADOOP_LOG_DIR
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
- 使環境變數生效
source /etc/profile
- 測試
hadoop version
如果出現如下版本號資訊則安裝成功

3.2 設定hadoop
- 建立資料夾
mkdir /usr/hadoop/hadoop-3.1.3/tmp
mkdir /usr/hadoop/hadoop-3.1.3/hdfs
mkdir /usr/hadoop/hadoop-3.1.3/hdfs/name
mkdir /usr/hadoop/hadoop-3.1.3/hdfs/data
- 跳轉至目錄 /usr/hadoop/hadoop-3.1.3/etc/hadoop/
cd /usr/hadoop/hadoop-3.1.3/etc/hadoop/
- 修改core-site.xml(在檔案末尾的 之間新增如下程式碼)
<!--設定hdfs檔案系統的名稱空間-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value> <!--master處為主機名,9000為埠號-->
</property>
<!-- 設定操作hdfs的存衝大小 -->
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
<!-- 設定臨時資料儲存目錄 -->
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/hadoop/hadoop-3.1.3/tmp</value>
</property>
- 修改hdfs-site.xml
<!--設定副本數-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--hdfs的後設資料儲存位置-->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/hadoop/hadoop-3.1.3/hdfs/name</value>
</property>
<!--hdfs的資料儲存位置-->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/hadoop/hadoop-3.1.3/hdfs/data</value>
</property>
<!--hdfs的namenode的web ui 地址-->
<property>
<name>dfs.http.address</name>
<value>master:50070</value>
</property>
<!--hdfs的snn的web ui 地址-->
<property>
<name>dfs.secondary.http.address</name>
<value>0.0.0.0:50090</value>
</property>
<!--是否開啟web操作hdfs-->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<!--是否啟用hdfs許可權(acl)-->
<property>
<name>dfs.permissions</name>
<value>false</value> </property>
- 修改mapred-site.xml
<!--指定mapreduce執行框架-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value> </property>
<!--歷史服務的通訊地址-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<!--歷史服務的web ui地址-->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
- 修改yarn-site.xml
<!--指定resourcemanager所啟動的伺服器主機名-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<!--指定mapreduce的shuffle-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--指定resourcemanager的內部通訊地址-->
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<!--指定scheduler的內部通訊地址-->
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<!--指定resource-tracker的內部通訊地址-->
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<!--指定resourcemanager.admin的內部通訊地址-->
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<!--指定resourcemanager.webapp的ui監控地址-->
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
- 修改workers(hadoop3之前檔名為slaves)
直接將檔案內容替換為
master
slave1
slave2
- 設定hadoop-env.sh、yarn-env.sh、mapred-env.sh
加入自己的jdk路徑,即/usr/java/jdk1.8.0_151(隨便在檔案找個空行加入以下內容)
export JAVA_HOME=/usr/java/jdk1.8.0_151
- 組態檔拷貝
- 方法一:直接在另外兩臺機器上重複3.2的所有操作
- 方法二:master結點打包檔案直接傳輸至其他兩臺機器
打包指令:tar -zcvf +生成的壓縮檔名 + 被壓縮檔名。
傳送指令: scp +待傳送檔名+ 使用者名稱@主機名:另一臺機器的檔案接收路徑
例如(僅做格式參考例子):
scp hadoop-3.1.3.tar.gz root@slave1:/usr/hadoop
傳送完成之後在對應機器上執行對應適當解壓命令即可(至指定正確資料夾)
4.大功告成
4.1啟動hadoop
- 跳轉目錄
cd /usr/hadoop/hadoop-3.1.3/sbin
- 格式化namenode
hdfs namenode -format
如果出現了SHUTDOWN_MSG: Shutting down NameNode at xxx資訊也不要慌張,向上尋找資訊,如果能找到 INFO common.Storage:Storage directory ******省略 has been successfully formatted資訊,則格式化成功了,忽略後面的SHUTDOWN_MSG即可
- 啟動所有服務
start-all.sh
- 若出現很多ERROR的情況則進行下列操作
跳轉目錄
cd /usr/hadoop/hadoop-3.1.3/sbin
修改start-dfs.sh和stop-dfs.sh檔案,新增如下內容:
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
修改start-yarn.sh和stop-yarn.sh檔案,新增如下內容:
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
重新執行程式碼
start-all.sh
- 成功後輸入jps指令檢視情況
jps
應該能看到六行資訊包括如下內容:
NodeManager ResourceManager NameNode Jps DataNode SecondaryNameNode
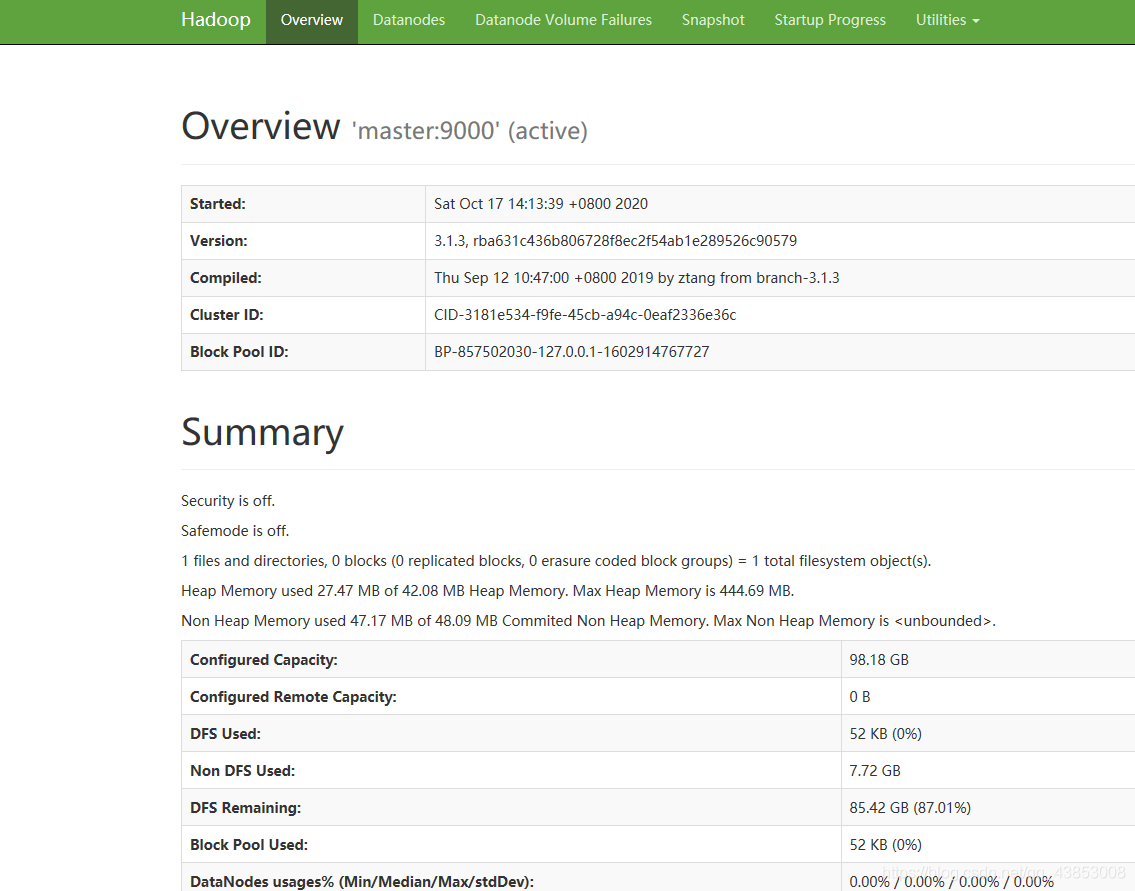
4.2然後即可在web網頁檢視到自己的頁面!!!
http://master伺服器的公網ip:50070/