(番外一)Arm32 中虛擬地址機制分析(Arm cortex-A系列 MMU工作機制分析)
Arm Cortex-A 系列 記憶體管理單元(MMU)
由於直接分析 linux arm32 mmu版 的啟動程式碼會涉及到記憶體直接物理對映模式到開啟虛擬地址對映模式的轉換,這需要對 ARM32 中的虛擬地址實現機制有足夠的瞭解才行,本文通過分析Arm Cortex-A 系列記憶體管理單元來分析ARM32中的虛擬地址機制。 Memory Management Unit 簡稱為 MMU ,它的一個最主要的功能就是進行地址轉換,將處理器發出的 虛擬地址 轉換為 實體地址 ,有了 MMU 的支援,才能讓我們更容易地設計處多工作業系統,以及在作業系統上開發應用程式,如果學習過逆向分析,就知道不同的可執行檔案(區別於動態連結庫與可重定向檔案)的裝載地址(entry point)在一般情況下都是相同的,並且在不同的程式中,也會有極大概率存取到相同的記憶體地址,為了防止衝突以及不必要的重定向任務, 虛擬地址 與地址轉換的概念應運而生,只要作業系統為每一個程序維護一個虛擬地址轉換表,這樣就可以通過地址轉換將處理器發出的相同地址轉換為不同的實體地址,程式中也不再存在存取同一個地址發生衝突的問題,也有效阻止了一個程序非法讀寫另一個程序的記憶體資料的現象發生。
在不同的處理器架構中,虛擬地址轉換的實現往往各不相同,本文主要分析 Arm Cortex-A 系列處理器的 MMU 與虛擬地址轉換過程。
首先拋開理論,憑感覺簡單考慮一下處理器發出記憶體存取請求後,按道理應該出現的一個操作流程:
-
1、首先處理器從記憶體中讀入一個指令,例如:ldr r0, [r1] ,而 r1 在之前已經被賦上了某個標號的值,這個值代表這個標號的所在地址,而此地址是一個虛擬地址,在程式原始碼 通過連結過程,將目標檔案連結為可執行檔案 的時候就已經確定下來了,可執行檔案和動態連結庫不同,可執行檔案沒有重對映表,所以當裝載到記憶體後,不會進行指令地址重對映操作,程式中的每一個指令對記憶體的認知就只侷限在被連結的時候所分配的虛擬地址,處理器通過檢視 opcode 發現這個指令需要寫記憶體,但是它知道這個是虛擬記憶體,通過這個記憶體地址直接找實體記憶體一定是一無所獲的,所以它將地址交給了另一個處理單元,即 MMU
-
2、 MMU 收到了虛擬地址後,它應該會通過某種對映機制來將此虛擬地址轉換為實體地址,這就需要在某處持續儲存且更新這個對映資訊,但是由於片內快取記憶體資源是非常有限的,不可能將所有的對映資訊全部儲存在片內快取記憶體中,並且在裝置重新啟動或掉電的時候,作業系統與其他應用程式會重新載入並執行,而不是繼續執行,所以也沒有必要將對映資訊持久化儲存;這樣我們可以猜測這個對映資訊應該是會被儲存在記憶體中的某個位置,並且很有可能為了提高查詢對映資訊的速度而將部分資訊儲存在快取記憶體中。
-
3、如果對映資訊在記憶體中,則 MMU 必須知道對映資訊位置的物理實際地址,而不是虛擬地址,要不然就發生永不停息的遞迴查詢了,而這個實體地址必須是 MMU 事先知道的,比如儲存在記憶體中的固定位置, MMU 通過存取記憶體能得到這個實體地址,或者是儲存在特殊的暫存器中。 MMU 獲取到這個實體地址後才能找到對映資訊,並使用對映資訊把虛擬地址對映為實體地址,最後在此轉換得到的實體地址上執行 ldr 指令。
在上文中需要注意的資訊有以下兩點:
- 對映資訊與其儲存位置
- 對映資訊的實體地址
這兩點是支援地址轉換的重要元素。
現在通過手冊仔細閱讀 MMU 實現原理與工作機制,來驗證我們的猜想,這裡我使用的手冊是 《Arm Cortex-A Series Programmer’s Guide》version 4 Chapter 9 (在本次分析中不涉及 Large Physical Address Extensions 技術)。
通過閱讀手冊知道,Arm 中的 translation table 就對應著上文提到的對映資訊, MMU 通過查詢 translation table 來獲取虛擬地址與實體地址的對映關係。而這個查詢與轉換過程如何實現,則與這個所謂的 translation table 的結構與定義有著很大的關係,這就需要深入瞭解這個 translation table 的結構組織了。根據手冊描述,Arm 將可定址的 4GB 大小的記憶體空間分為特定大小的塊,每一個塊被稱作頁(page),然後再給每一個塊建立一個對映關係表項來完成虛擬地址中的塊到實體地址中的塊的對映(這個與虛擬地址中的塊所對應的實體地址空間中的塊被稱作頁框 page frame),這個以分塊來對映的機制就叫做分頁技術(paging),為什麼要分塊呢?可以想象一下如果將每一個位元組,甚至每一個位元都設定一個特定的對映關係,那需要多少空間來儲存這個對映資訊呢?如果每一個實體記憶體都被對映到了虛擬記憶體上,是不是所有實體記憶體上儲存的都是對映資訊?那就不用幹別的事情了。所以要給虛擬地址空間進行分割區,每一個特定大小的塊做一個對映關係,每個塊內部地址對映關係則是線性的(虛擬地址空間塊中的每個位置到塊起始位置的偏移都與實體地址空間的塊中的相應位置到實體地址空間塊的起始位置的偏移相同),這樣就不用儲存過多的資訊了。但是這個塊又不能太大,不然如果每個應用程序都只佔用一個塊中的很小空間,那麼就會留下很多的記憶體碎片無法被利用,會產生極大的浪費,關於塊的大小,可以通過設定 translation table 表項的屬性來決定,Arm 留給了作業系統開發人員極大的可客製化空間。
瞭解了對映機制後,來具體探究一下 translation table 的結構:
每個 translation table 都佔據了一塊連續的實體地址,並將這塊實體地址分為大小相等的塊,每一塊代表一個表項 (translation table entry),可以認為 translation table 是一個陣列,每個元素都是一個 table entry。每個表項中都儲存有特定的資訊,或者是未對映,或者是對映到下一級 tranlation table(Arm 中的地址轉換可以是多級的,即通過多層對映來獲取虛擬地址對應的實體地址),或者是直接對映到一個實體地址上(Arm 中的地址轉換也可以是單級的,即表項中包含的地址即為虛擬地址所對應的實體地址)。在沒有啟用 LPAE 技術時,Arm 最多可以分成兩級頁表,即 L1 translation table 與 L2 translation table。
現在我們有 translation table 了,也知道 translation table 的表項中儲存有對映地址資訊了,那問題是 MMU 獲得一個虛擬地址後,怎麼知道去查詢哪個 translation table 和查詢 translation table 中的哪個表項?
查詢哪個地址轉換表
上文說過,想要查詢 translation table , MMU 一定需要通過某種方式獲得這個 translation table 的實際實體地址,而這個實體地址就儲存在協處理器 CP15 的 C2 暫存器中(在 《ARM 體系結構與程式設計》第二版的第 178 頁有全部的 CP15 協處理器的暫存器的作用),叫做地址轉換表基址。當 MMU 收到一個虛擬地址,它通過查詢協處理器 CP15 的 C2 暫存器來獲取地址轉換表的基址,然後通過這個地址轉換表來進行地址轉換。當考慮多工作業系統時,往往每一個程序都會儲存一個地址轉換表基址,當發生程序切換時,會將這個儲存的基址載入到處理器 CP15 的 C2 暫存器中,然後就能對這個程序對虛擬地址的存取進行轉換工作了。
查詢哪個地址轉換表表項
MMU 收到的所有與記憶體存取有關的資訊只有處理器傳過來的虛擬地址,所以查詢哪個表項這個問題只能通過這個虛擬地址本身來決定。對於 ARM32 平臺下,這個虛擬地址一定是 32bits 長的, MMU 使用虛擬地址的高 12bits 來決定查詢的地址轉換表項,虛擬地址高 12bits 表示的數值代表表項的下標索引,即從頭開始的 第幾個 表項(注意這個數值不代表偏移地址,而是代表「第幾個表項」),所以當設虛擬地址高 12bits 的值為 INDEX ,並且協處理器 CP15 的 C2 暫存器的值為 BASE 那這個表項在記憶體中的實際實體地址就是 INDEX * 4 + BASE 。從這一點我們也可以看出,我們用了高 12bits 去尋找一級地址轉換表的表項,還剩下 20 bits沒有使用,這就代表每個表項可以分割 2^20 bytes 的地址空間,即 1MB 的記憶體段。以類似的方式我們可以在虛擬地址中提取出二級地址轉換表表項的索引值,或者直接使用這 20bits 去對映實體記憶體,這些具體細節將在下文描述。
L1 Translation Table
上文已經解釋過如何定位一級地址轉換表,也提到了一級地址轉換表可以指向二級地址轉換表,也可以直接指向實體地址進行對映,現在來看一下一級地址轉換表的表項的結構來明確一下怎麼分辨表項指向的是實體地址還是下一級地址轉換表。一級地址轉換表一共有 4096 個表項,每個表項的大小為 32bits,他將整個 4GB 虛擬記憶體空間分為 4096份,每份 1MB 大小。一級地址轉換表的表項一共有 4種,如下圖所示:

可以看到表項之間通過第0、1位來判斷表項的種類,像 00 代表沒有進行對映的表項,01 代表表項指向下一級(圖中的 Level 2 Descriptor Base Address ),即二級地址轉換表的基地址。而 10 的情況比較特殊,這兩個都是直接對映實體地址,但是 section 類表項代表直接對映 1MB 大小的實體地址空間,而 supersection 通過幾個表項組合的方式來對映 16MB 大小的實體地址空間,supersection 比較特殊,就不展開討論,這塊內容在手冊的 9.4 節有具體描述。在這裡主要描述 01 表項的情況,我們注意到 Level 2 Descriptor Base Address 的大小為 22bits 這顯然不能覆蓋所有 4GB 大小的記憶體空間,看來二級地址轉換表的儲存位置必定會受到限制。22bits 表示的大小可以將記憶體均勻分為 4194304 個區域,每個區域大小為 1KB,而 Arm 剛好定義二級地址轉換表的大小為 1KB,並且二級轉換表的起始位置為 1KB 對齊的,所以我們均勻分出來的 4194304 個區域,每個區域都正好能儲存一個二級地址轉換表,嗯,二級地址轉換表的基地址在記憶體中 1KB 對齊,並且大小為 1KB,這樣就能通過一級地址轉換表的表項中的 22bits 大小的 Level 2 Descriptor Base Address 來尋找二級地址轉換表。
L2 Translation Table
通過上文的方式我們已經找到了二級地址轉換表的位置,現在我們要利用二級地址轉換表繼續進行地址對映(注:我們已經利用了虛擬地址的高 12bits 來進行一級地址轉換表表項的定址工作,只剩下 20bits 來尋找二級地址轉換表表項了)。這裡要強調一下,進行地址轉換的過程是不存在浪費地址空間的行為,即一級地址轉換表將記憶體劃分為 1MB 大小的塊,如果不進行直接實體地址對映的話,那麼二級地址轉換表必須保證能夠將每個 1MB 的塊全部分配出去,現在我們還剩下 20bits,理論上可以進行 1MB 大小的記憶體定址,但是需要利用這 20bits 的前幾位來尋找二級地址表的表項,後幾位來作為這個表項所對映的實體地址空間的地址偏移值,而我們也知道二級地址轉換表的大小為 1KB,如果我們利用前 8bits 來進行地址表項的尋找,這樣可以將轉換表分為 256 個表項,每個表項 4bytes,並且每個表項應該表示 1MB / 256 = 4KB 大小的頁框(上文已經提到頁框這個術語)的起始地址,而 4bytes 全部用來尋找頁框起始實體地址才能讓頁框的起始實體地址在記憶體的任意位置,但是為了給頁框加一些必要的存取屬性(可讀可寫之類的屬性),不能用表項的全部 4bytes 表示頁框的起始實體地址,這樣就引出了經典問題,頁框的起始地址不能是 4GB 空間中的任意位置,當然如果細想一下也不應該是任意位置,如果一個頁框起始地址往上1KB又是另一個頁框的起始地址,那麼這兩個頁框不就重疊了麼?這必定會引起存取衝突。所以最好的辦法還是讓 4KB 的頁框的起始地址以 4KB 進行對齊,這樣就能將 4GB 地址空間均勻分為 1048576 份,這個數量正好能用 20bits 來定址,所以二級地址轉換表的表項中的 20bits 應該用於對映頁框,而剩下的 12bits 可以用來表示頁框的屬性。上述分析只是二級地址轉換表表項的其中一種表示方法,二及地址轉換表表項也有 3 個表示方法,如下圖所示:
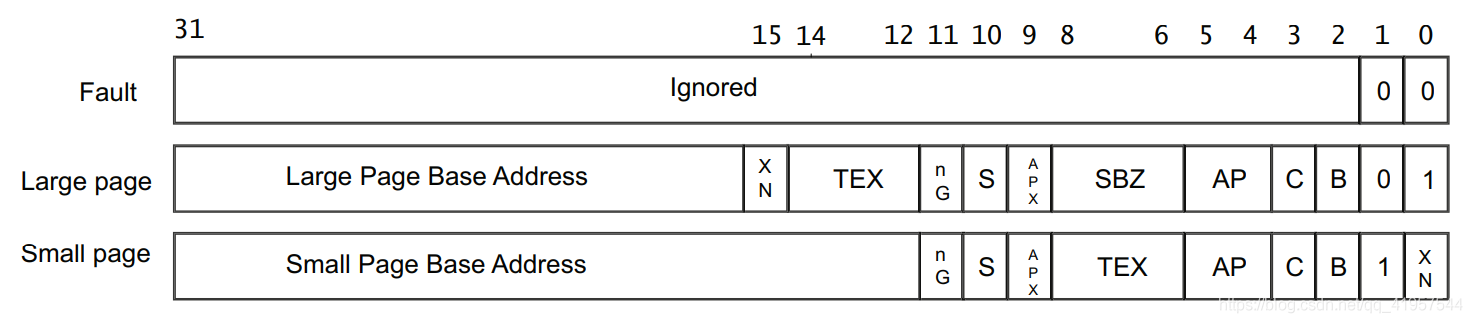
未完待續