看完這份MySQL核心知識點+面試檔案去面試後,面試官小聲嘀咕:「這人活這麼好?」
概述
為什麼要優化
- 系統的吞吐量瓶頸往往出現在資料庫的存取速度上
- 隨著應用程式的執行,資料庫的中的資料會越來越多,處理時間會相應變慢
- 資料是存放在磁碟上的,讀寫速度無法和記憶體相比
如何優化
- 設計資料庫時:資料庫表、欄位的設計,儲存引擎
- 利用好MySQL自身提供的功能,如索引等
- 橫向擴充套件:MySQL叢集、負載均衡、讀寫分離
- SQL語句的優化(收效甚微)

1 說說自己對於 MySQL 常見的兩種儲存引擎:MyISAM與InnoDB的理解
關於二者的對比與總結:
count運算上的區別:因為MyISAM快取有表meta-data(行數等),因此在做COUNT(*)時對於一個結構很好的查詢是不需要消耗多少資源的。而對於InnoDB來說,則沒有這種快取。
是否支援事務和崩潰後的安全恢復: MyISAM 強調的是效能,每次查詢具有原子性,其執行數度比InnoDB型別更快,但是不提供事務支援。但是InnoDB 提供事務支援事務,外部鍵等高階資料庫功能。 具有事務(commit)、回滾(rollback)和崩潰修復能力(crash recovery capabilities)的事務安全(transaction-safe (ACIDcompliant))型表。
是否支援外來鍵: MyISAM不支援,而InnoDB支援。
MyISAM更適合讀密集的表,而InnoDB更適合寫密集的的表。 在資料庫做主從分離的情況下,經常選擇MyISAM作為主庫的儲存引擎。 一般來說,如果需要事務支援,並且有較高的並行讀取頻率(MyISAM的表鎖的粒度太大,所以當該表寫並行量較高時,要等待的查詢就會很多了),InnoDB是不錯的選擇。如果你的資料量很大(MyISAM支援壓縮特性可以減少磁碟的空間佔用),而且不需要支援事務時,MyISAM是最好的選擇。
2 資料庫索引瞭解嗎?

下面是我補充的一些內容
為什麼索引能提高查詢速度?
先從 MySQL 的基本儲存結構說起
MySQL的基本儲存結構是頁(記錄都存在頁裡邊):
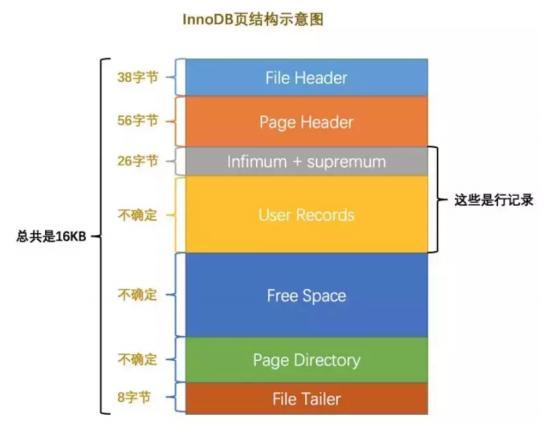
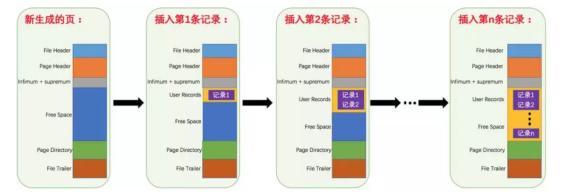
各個資料頁可以組成一個雙向連結串列
每個資料頁中的記錄又可以組成一個單向連結串列
每個資料頁都會為儲存在它裡邊兒的記錄生成一個頁目錄,在通過主鍵查詢某條記錄的時候可以在頁目錄中使用二分法快速定位到對應的槽,然後再遍歷該槽對應分組中的記錄即可快速找到指定的記錄
以其他列(非主鍵)作為搜尋條件:只能從最小記錄開始依次遍歷單連結串列中的每條記錄。
所以說,如果我們寫select * from user where indexname = 'xxx'這樣沒有進行任何優化的sql語句,預設會這樣做:
定位到記錄所在的頁:需要遍歷雙向連結串列,找到所在的頁
從所在的頁內中查詢相應的記錄:由於不是根據主鍵查詢,只能遍歷所在頁的單連結串列了
很明顯,在資料量很大的情況下這樣查詢會很慢!這樣的時間複雜度為O(n)。
使用索引之後
索引做了些什麼可以讓我們查詢加快速度呢?其實就是將無序的資料變成有序(相對):
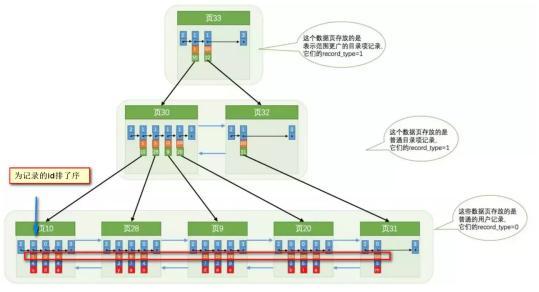
要找到id為8的記錄簡要步驟:
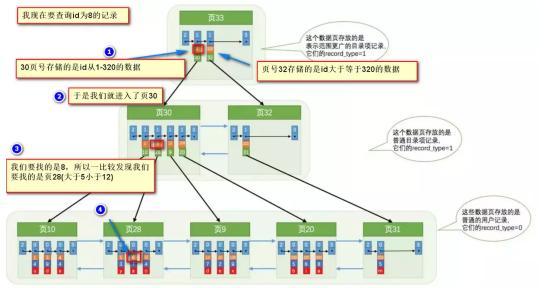
很明顯的是:沒有用索引我們是需要遍歷雙向連結串列來定位對應的頁,現在通過 「目錄」 就可以很快地定位到對應的頁上了!(二分查詢,時間複雜度近似為O(logn))其實底層結構就是B+樹,B+樹作為樹的一種實現,能夠讓我們很快地查詢出對應的記錄。
以下內容整理自:《Java工程師修煉之道》
最左字首原則
MySQL中的索引可以以一定順序參照多列,這種索引叫作聯合索引。如User表的name和city加聯合索引就是(name,city)o而最左字首原則指的是,如果查詢的時候查詢條件精確匹配索引的左邊連續一列或幾列,則此列就可以被用到。如下:
select * from user where name=xx and city=xx ; //可以命中索引
select * from user where name=xx ; // 可以命中索引
select * from user where city=xx; // 無法命中索引
這裡需要注意的是,查詢的時候如果兩個條件都用上了,但是順序不同,如 city= xx and name =xx ,那麼現在的查詢引擎會自動優化為匹配聯合索引的順序,這樣是能夠命中索引的.
由於最左字首原則,在建立聯合索引時,索引欄位的順序需要考慮欄位值去重之後的個數,較多的放前面。
ORDERBY子句也遵循此規則。
注意避免冗餘索引
冗餘索引指的是索引的功能相同,能夠命中 就肯定能命中 ,那麼 就是冗餘索引如(name,city )和(name )這兩個索引就是冗餘索引,能夠命中後者的查詢肯定是能夠命中前者的 在大多數情況下,都應該儘量擴充套件已有的索引而不是建立新索引。
MySQLS.7 版本後,可以通過查詢 sys 庫的 schemal_r dundant_indexes 表來檢視冗餘索引
Mysql如何為表欄位新增索引???
1.新增PRIMARY KEY(主鍵索引)
ALTER TABLE `table_name` ADD PRIMARY KEY ( `column` )
2.新增UNIQUE(唯一索引)
ALTER TABLE `table_name` ADD UNIQUE ( `column` )
3.新增INDEX(普通索引)
ALTER TABLE `table_name` ADD INDEX index_name ( `column` )
4.新增FULLTEXT(全文索引)
ALTER TABLE `table_name` ADD FULLTEXT ( `column`)
5.新增多列索引
ALTER TABLE `table_name` ADD INDEX index_name ( `column1`, `column2`, `column3` )
3 對於大表的常見優化手段說一下
4 當MySQL單表記錄數過大時,資料庫的CRUD效能會明顯下降,一些常見的優化措施如下:
當MySQL單表記錄數過大時,資料庫的CRUD效能會明顯下降,一些常見的優化措施如下:
1.限定資料的範圍: 務必禁止不帶任何限制資料範圍條件的查詢語句。比如:我們當使用者在查詢訂單歷史的時候,我們可以控制在一個月的範圍內。;
2.讀/寫分離: 經典的資料庫拆分方案,主庫負責寫,從庫負責讀;
3.垂直分割區: 根據資料庫裡面資料表的相關性進行拆分。 例如,使用者表中既有使用者的登入資訊又有使用者的基本資訊,可以將使用者表拆分成兩個單獨的表,甚至放到單獨的庫做分庫。簡單來說垂直拆分是指資料表列的拆分,把一張列比較多的表拆分為多張表。 如下圖所示,這樣來說大家應該就更容易理解了。
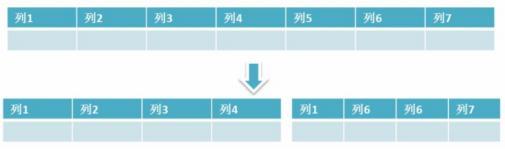
垂直拆分的優點: 可以使得行資料變小,在查詢時減少讀取的Block數,減少I/O次數。此外,垂直分割區可以簡化表的結構,易於維護。
垂直拆分的缺點: 主鍵會出現冗餘,需要管理冗餘列,並會引起Join操作,可以通過在應用層進行Join來解決。此外,垂直分割區會讓事務變得更加複雜;
4. 水平分割區: 保持資料表結構不變,通過某種策略儲存資料分片。這樣每一片資料分散到不同的表或者庫中,達到了分散式的目的。 水平拆分可以支撐非常大的資料量。 水平拆分是指資料表行的拆分,表的行數超過200萬行時,就會變慢,這時可以把一張的表的資料拆成多張表來存放。
舉個例子:我們可以將使用者資訊表拆分成多個使用者資訊表,這樣就可以避免單一表資料量過大對效能造成影響。
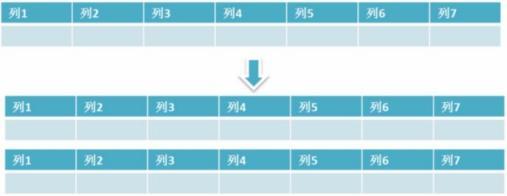
水平拆分可以支援非常大的資料量。需要注意的一點是:分表僅僅是解決了單一表資料過大的問題,但由於表的資料還是在同一臺機器上,其實對於提升MySQL並行能力沒有什麼意義,所以 水平拆分最好分庫 。水平拆分能夠 支援非常大的資料量儲存,應用端改造也少,但 分片事務難以解決 ,跨界點Join效能較差,邏輯複雜。
《Java工程師修煉之道》的作者推薦儘量不要對資料進行分片,因為拆分會帶來邏輯、部署、運維的各種複雜度 ,一般的資料表在優化得當的情況下支撐千萬以下的資料量是沒有太大問題的。如果實在要分片,儘量選擇使用者端分片架構,這樣可以減少一次和中介軟體的網路I/O。
下面補充一下資料庫分片的兩種常見方案:
使用者端代理: 分片邏輯在應用端,封裝在jar包中,通過修改或者封裝JDBC層來實現。 噹噹網的 Sharding-JDBC 、阿里的TDDL是兩種比較常用的實現。
中介軟體代理: 在應用和資料中間加了一個代理層。分片邏輯統一維護在中介軟體服務中。 我們現在談的 Mycat 、360的Atlas、網易的DDB等等都是這種架構的實現。
寫在最後
由於篇幅原因,上面只是列舉了了很少的一部分,我已經整理成pdf檔案,免費分享給那些有需要的朋友
我這邊給大家整理了一份Java架構師學習視訊以及針對"金九銀十"跳槽季的Java後端面試資料;
Java架構師學習資料:
- 手寫Mybatis
- 阿里面試必問的JVM應該怎麼學?
- 並行程式設計底層原理——手寫JDK鎖
- Spring事務原始碼解析
- 高並行下秒天秒地效能特技
- 等等
Java面試題:
- Linux面試專題及答案
- JVM面試專題及答案
- Java基礎面試題
- Kafka面試專題及答案
- Dubbo面試及答案
- Netty面試專題及答案
- ActiveMQ訊息中介軟體面試專題
- 訊息中介軟體面試專題及答案
- 資料庫面試專題及答案
- 微服務面試專題及答案
- 面試必備之樂觀鎖與悲觀鎖
- 開源框架面試專題及答案
- 設計模式面試專題及答案
- 多執行緒面試專題及答案
- zookeeper面試專題及答案
- 並行程式設計面試專題及答案
- 等等
本著"無私分享的精神",需要本文總結的課程大綱(PDF版本)、Java架構師學習視訊、Java面試題的朋友
