2020阿里最新巨量資料面試題集合:Spark+Zookeeper+Hadoop+HBase
2020-10-16 11:01:53
Hadoop面試題
- 講述HDFS上傳檔案和讀檔案的流程?
- HDFS在上傳檔案的時候,如果其中一個塊突然損壞了怎麼辦?
- NameNode的作用?
- 4.NameNode在啟動的時候會做哪些操作?
- NameNode的HA?
- Hadoop的作業提交流程?
- Hadoop怎麼分片?
- 如何減少Hadoop Map端到Reduce端的資料傳輸量?
- Hadoop的Shuffle?
- 哪些場景才能使用Combiner呢?
- HMaster的作用?
- 如何實現hadoop的安全機制?
- hadoop的排程策略的實現,你們使用的是那種策略,為什麼?
- 資料傾斜怎麼處理?
- 評述hadoop執行原理?
- 簡答說一下hadoop的map-reduce程式設計模型?
- hadoop的TextInputFormat作用是什麼,如何自定義實現?
- map-reduce程式執行的時候會有什麼比較常見的問題?
- Hadoop平臺叢集設定、環境變數設定?
- Hadoop效能調優?
- .Hadoop高並行?
- Hadoop組態檔以及簡單的Hadoop叢集搭建
- Hadoop引數調優
- Hadoop宕機
- Hadoop 高可用設定
- 設定 HDFS-HA叢集
- 設定HDFS-HA自動故障轉移
- 設定Yarn-HA

HBase面試題
- HBase的特點是什麼?
- HBase和Hive有什麼區別?
- HBase的rowkey 設計原則
- HBase中的scan和get的功能以及實現的異同
- 請描述Hbase中scan物件的setCache和setBatch 方法的使用
- 以 start-hbase.sh 為起點,Hbase 啟動的流程是什麼?
- 簡述 HBASE中compact用途是什麼,什麼時候觸發,分為哪兩種,有什麼區別,有哪些相關設定引數?
- HBase 如何給WEB前端提供介面來存取?
- HBase的匯入匯出方式
- HBase搭建過程中需要注意什麼?
spark面試題
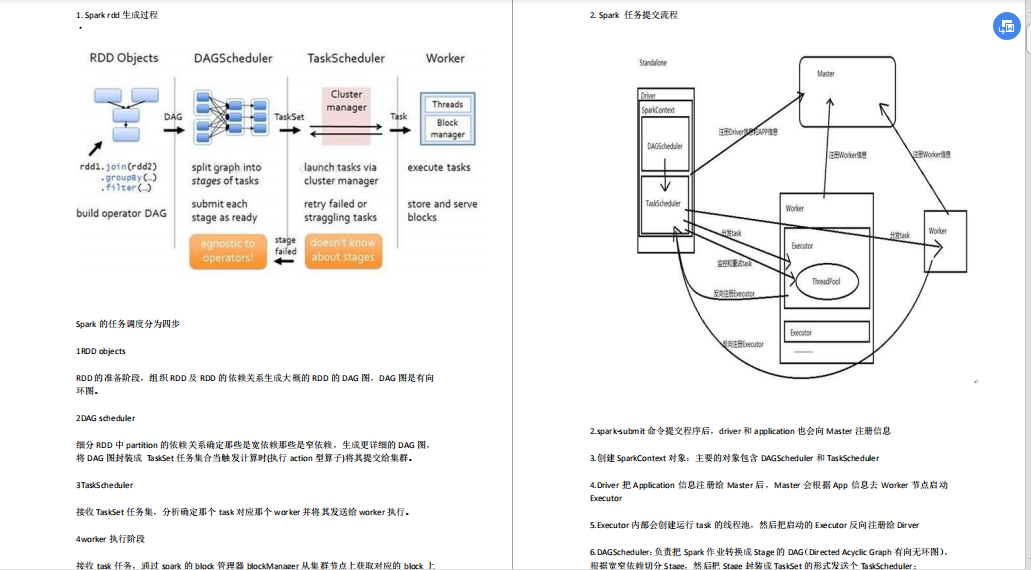
- Spark的Shuffle原理及調優?
- hadoop和spark使用場景?
- spark如何保證宕機迅速恢復?
- hadoop和spark的相同點和不同點?
- RDD持久化原理?
- checkpoint檢查點機制?
- checkpoint和持久化機制的區別?
- Spark Streaming和Storm有何區別?
- RDD機制?
- Spark streaming以及基本工作原理?
- DStream以及基本工作原理?
- spark有哪些元件?
- spark工作機制?
- Spark工作的一個流程?
- spark核心程式設計原理?
- spark基本工作原理?
- spark效能優化有哪些?
- updateStateByKey詳解?
- 寬依賴和窄依賴?
- spark streaming中有狀態轉化操作?
- spark常用的計算框架?
- spark整體架構?
- Spark的特點是什麼?
- 搭建spark叢集步驟?
- Spark的三種提交模式是什麼?
- spark核心架構原理?
- Spark yarn-cluster架構?
- Spark yarn-client架構?
- SparkContext初始化原理?
- Spark主備切換機制原理剖析?
- spark支援故障恢復的方式?
- spark解決了hadoop的哪些問題?
- 資料傾斜的產生和解決辦法?
- spark 實現高可用性:High Availability?
- spark實際工作中,是怎麼來根據任務量,判定需要多少資源的?
- spark中怎麼解決記憶體漏失問題?

Zookeeper面試題
- zookeeper是什麼框架?
- 有哪些應用場景?
- 使用什麼協定?
- 說說分散式一致性演演算法Paxos
- 說一說選舉演演算法及流程
- zookeeper有哪幾種節點型別?
- zookeeper對節點的watch監聽通知是永久的嗎?
- 有哪幾種部署模式?
- 叢集中的機器角色都有哪些?
- 叢集最少要幾臺機器,叢集規則是怎樣的
- 叢集如果有3臺機器,掛掉一臺叢集還能工作嗎?掛掉兩臺呢?
- 叢集支援動態新增機器嗎?
- zookeeper的java使用者端都有哪些?
- chubby是什麼,和zookeeper比你怎麼看?
- 說幾個zookeeper常用的命令。


針對以上問題小編已經整理好了 面試題+答案檔案,除了這份面試專題檔案,小編者裡還有一些針對性的實戰檔案都可以免費提供給大家學習。
需要獲取面試專題檔案和實戰檔案的朋友:點贊文章並關注我,加助理VX:mxx2020666,即可免費領取