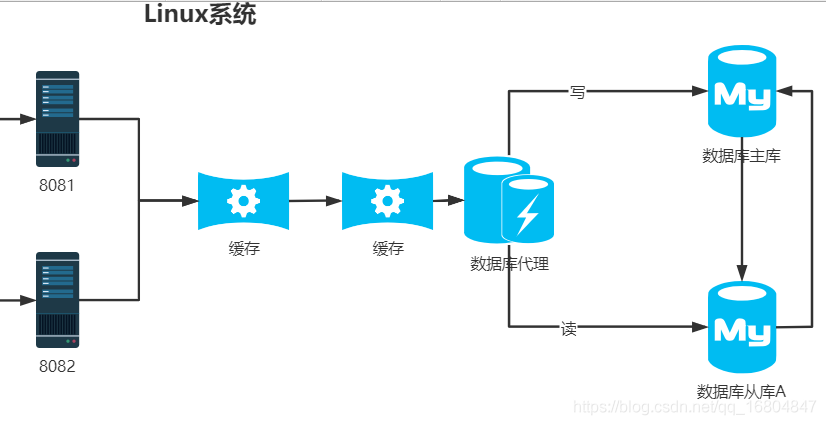
2006-京淘Day13
1 AOP實現Redis快取
1.1 如何理解AOP
名稱: 面向切面程式設計
作用: 降低系統中程式碼的耦合性,並且在不改變原有程式碼的條件下對原有的方法進行功能的擴充套件.
公式: AOP = 切入點表示式 + 通知方法
1.2 通知型別
1.前置通知 目標方法執行之前執行
2.後置通知 目標方法執行之後執行
3.異常通知 目標方法執行過程中丟擲異常時執行
4.最終通知 無論什麼時候都要執行的通知
特點: 上述的四大通知型別 不能干預目標方法是否執行.一般用來做程式執行狀態的記錄.監控
5.環繞通知 在目標方法執行前後都要執行的通知方法 該方法可以控制目標方法是否執行.joinPoint.proceed(); 功能作為強大的.
1.3 切入點表示式
理解: 切入點表示式就是一個程式是否進入通知的一個判斷(IF)
作用: 當程式執行過程中 ,**滿足了切入點表示式時才會去執行通知方法,**實現業務的擴充套件.
種類(寫法):
1. bean(bean的名稱 bean的ID) 只能攔截具體的某個bean物件 只能匹配一個物件
lg: bean(「itemServiceImpl」)
2. within(包名.類名) within(「com.jt.service.*」) 可以匹配多個物件
粗粒度的匹配原則 按類匹配
3. execution(返回值型別 包名.類名.方法名(參數列)) 最為強大的用法
lg : execution(* com.jt.service..*.*(..))
返回值型別任意 com.jt.service包下的所有的類的所有的方法都會被攔截.
4.@annotation(包名.註解名稱) 按照註解匹配.
1.4 AOP入門案例
package com.jt.aop;
import org.aspectj.lang.JoinPoint;
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.annotation.*;
import org.springframework.stereotype.Component;
import org.springframework.stereotype.Service;
import java.util.Arrays;
@Aspect //我是一個AOP切面類
@Component //將類交給spring容器管理
public class CacheAOP {
//公式 = 切入點表示式 + 通知方法
/**
* 關於切入點表示式的使用說明
* 粗粒度:
* 1.bean(bean的Id) 一個類
* 2.within(包名.類名) 多個類
* 細粒度
*/
//@Pointcut("bean(itemCatServiceImpl)")
//@Pointcut("within(com.jt.service..*)") //匹配多級目錄
@Pointcut("execution(* com.jt.service..*.*(..))") //方法引數級別
public void pointCut(){
//定義切入點表示式 只為了佔位
}
//區別: pointCut() 表示切入點表示式的參照 適用於多個通知 共用切入點的情況
// @Before("bean(itemCatServiceImpl)") 適用於單個通知.不需要複用的
// 定義前置通知,與切入點表示式進行繫結. 注意繫結的是方法
/**
* 需求:獲取目標物件的相關資訊.
* 1.獲取目標方法的路徑 包名.類名.方法名
* 2.獲取目標方法的型別 class
* 3.獲取傳遞的引數
* 4.記錄當前的執行時間
*/
@Before("pointCut()")
//@Before("bean(itemCatServiceImpl)")
public void before(JoinPoint joinPoint){
String className = joinPoint.getSignature().getDeclaringTypeName();
String methodName = joinPoint.getSignature().getName();
Class targetClass = joinPoint.getTarget().getClass();
Object[] args = joinPoint.getArgs();
Long runTime = System.currentTimeMillis();
System.out.println("方法路徑:" +className+"."+methodName);
System.out.println("目標物件型別:" + targetClass);
System.out.println("引數:" + Arrays.toString(args));
System.out.println("執行時間:" + runTime+"毫秒");
}
/* @AfterReturning("pointCut()")
public void afterReturn(){
System.out.println("我是後置通知");
}
@After("pointCut()")
public void after(){
System.out.println("我是最終通知");
}*/
/**
* 環繞通知說明
* 注意事項:
* 1.環繞通知中必須新增引數ProceedingJoinPoint
* 2.ProceedingJoinPoint只能環繞通知使用
* 3.ProceedingJoinPoint如果當做引數 則必須位於引數的第一位
*/
@Around("pointCut()")
public Object around(ProceedingJoinPoint joinPoint){
System.out.println("環繞通知開始!!!");
Object result = null;
try {
result = joinPoint.proceed(); //執行下一個通知或者目標方法
} catch (Throwable throwable) {
throwable.printStackTrace();
}
System.out.println("環繞通知結束");
return result;
}
}
2 關於AOP實現Redis快取
2.1 自定義快取註解
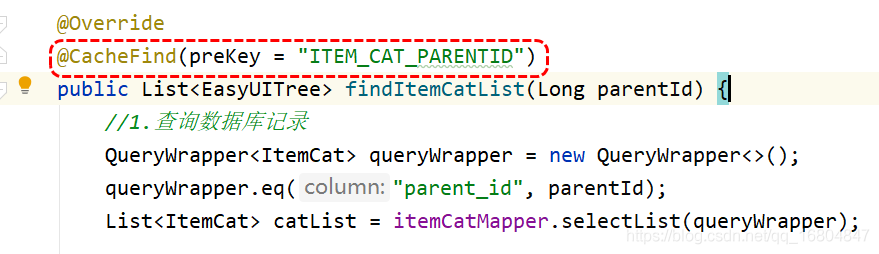
問題: 如何控制 哪些方法需要使用快取? cacheFind()
解決方案: 採用自定義註解的形式 進行定義,如果 方法執行需要使用快取,則標識註解即可.
關於註解的說明:
1.註解名稱 : cacheFind
2.屬性引數 :
2.1 key: 應該由使用者自己手動新增 一般新增業務名稱 之後動態拼接形成唯一的key
2.2 seconds: 使用者可以指定資料的超時的時間
@Target(ElementType.METHOD) //註解對方法有效
@Retention(RetentionPolicy.RUNTIME) //執行期有效
public @interface CacheFind {
public String preKey(); //使用者標識key的字首.
public int seconds() default 0; //如果使用者不寫表示不需要超時. 如果寫了以使用者為準.
}
2.2 編輯CacheAOP
package com.jt.aop;
import com.jt.anno.CacheFind;
import com.jt.config.JedisConfig;
import com.jt.util.ObjectMapperUtil;
import org.aspectj.lang.JoinPoint;
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.annotation.*;
import org.aspectj.lang.reflect.MethodSignature;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import org.springframework.stereotype.Service;
import redis.clients.jedis.Jedis;
import java.lang.reflect.Method;
import java.util.Arrays;
@Aspect //我是一個AOP切面類
@Component //將類交給spring容器管理
public class CacheAOP {
@Autowired
private Jedis jedis;
/**
* 切面 = 切入點 + 通知方法
* 註解相關 + 環繞通知 控制目標方法是否執行
*
* 難點:
* 1.如何獲取註解物件
* 2.動態生成key prekey + 使用者引數陣列
* 3.如何獲取方法的返回值型別
*/
@Around("@annotation(cacheFind)")
public Object around(ProceedingJoinPoint joinPoint,CacheFind cacheFind){
Object result = null;
try {
//1.拼接redis儲存資料的key
Object[] args = joinPoint.getArgs();
String key = cacheFind.preKey() +"::" + Arrays.toString(args);
//2. 查詢redis 之後判斷是否有資料
if(jedis.exists(key)){
//redis中有記錄,無需執行目標方法
String json = jedis.get(key);
//動態獲取方法的返回值型別 向上造型 向下造型
MethodSignature methodSignature = (MethodSignature) joinPoint.getSignature();
Class returnType = methodSignature.getReturnType();
result = ObjectMapperUtil.toObj(json,returnType);
System.out.println("AOP查詢redis快取");
}else{
//表示資料不存在,需要查詢資料庫
result = joinPoint.proceed(); //執行目標方法及通知
//將查詢的結果儲存到redis中去
String json = ObjectMapperUtil.toJSON(result);
//判斷資料是否需要超時時間
if(cacheFind.seconds()>0){
jedis.setex(key,cacheFind.seconds(),json);
}else {
jedis.set(key, json);
}
System.out.println("aop執行目標方法查詢資料庫");
}
} catch (Throwable throwable) {
throwable.printStackTrace();
}
return result;
}
}
3 關於Redis 設定說明
3.1 關於Redis持久化的說明
redis預設條件下支援資料的持久化操作. 當redis中有資料時會定期將資料儲存到磁碟中.當Redis伺服器重新啟動時 會根據組態檔讀取指定的持久化檔案.實現記憶體資料的恢復.
3.2持久化方式介紹
3.2.1 RDB模式
特點:
1.RDB模式是redis的預設的持久化策略.
2.RDB模式記錄的是Redis 記憶體資料的快照. 最新的快照會覆蓋之前的內容 所有RDB持久化檔案佔用空間更小 持久化的效率更高.
3.RDB模式由於是定期持久化 所以可能導致資料的丟失.
命令:
1. save 要求立即馬上持久化 同步的操作 其他的redis操作會陷入阻塞的狀態.
2. bgsave 開啟後臺執行 非同步的操作 由於是非同步操作,所以無法保證rdb檔案一定是最新的需要等待.
設定:
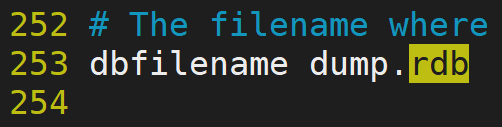
1.持久化檔名稱:
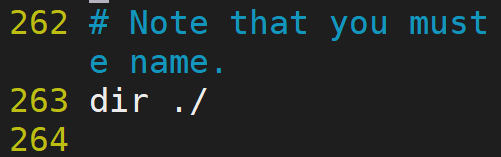
2.持久化檔案位置
dir ./ 相對路徑的寫法
dir /usr/local/src/redis 絕對路徑寫法
3.RDB模式持久化策略

3.2.2 AOF模式
特點:
1.AOF模式預設條件下是關閉的,需要使用者手動的開啟
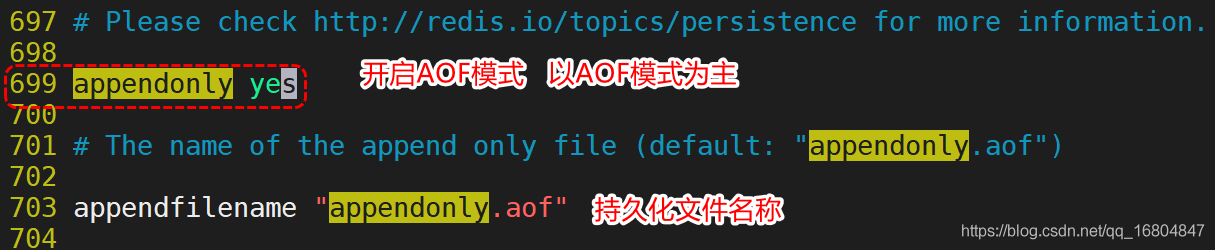
2. AOF模式是非同步的操作 記錄的是使用者的操作的過程 可以防止使用者的資料丟失
3. 由於AOF模式記錄的是程式的執行狀態 所以持久化檔案相對較大,恢復資料的時間長.需要人為的優化持久化檔案
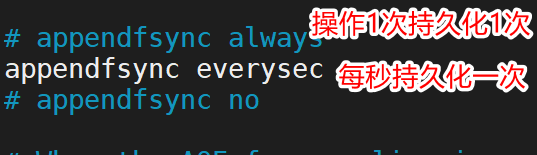
設定:
3.2.2 關於持久化操作的總結
1.如果不允許資料丟失 使用AOF方式
2.如果追求效率 執行少量資料丟失 採用RDB模式
3.如果既要保證效率 又要保證資料 則應該設定redis的叢集 主機使用RDB 從機使用AOF
3.3 關於Redis記憶體策略
3.3.1 關於記憶體策略的說明
說明:Redis資料的儲存都在記憶體中.如果一直想記憶體中儲存資料 必然會導致記憶體資料的溢位.
解決方式:
1. 儘可能為儲存在redis中的資料新增超時時間.
2. 利用演演算法優化舊的資料.
3.3.2 LRU演演算法
特點: 最好用的記憶體優化演演算法.
LRU是Least Recently Used的縮寫,即最近最少使用,是一種常用的頁面置換演演算法,選擇最近最久未使用的頁面予以淘汰。該演演算法賦予每個頁面一個存取欄位,用來記錄一個頁面自上次被存取以來所經歷的時間 t,當須淘汰一個頁面時,選擇現有頁面中其 t 值最大的,即最近最少使用的頁面予以淘汰。
維度: 時間 T
3.3.3 LFU演演算法
LFU(least frequently used (LFU) page-replacement algorithm)。即最不經常使用頁置換演演算法,要求在頁置換時置換參照計數最小的頁,因為經常使用的頁應該有一個較大的參照次數。但是有些頁在開始時使用次數很多,但以後就不再使用,這類頁將會長時間留在記憶體中,因此可以將引用計數暫存器定時右移一位,形成指數衰減的平均使用次數。
維度: 使用次數
3.3.4 RANDOM演演算法
隨機刪除資料
3.3.5 TTL演演算法
把設定了超時時間的資料將要移除的提前刪除的演演算法.
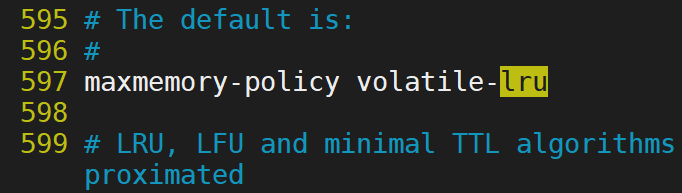
3.3.6 Redis記憶體資料優化
- volatile-lru 設定了超時時間的資料採用lru演演算法
2.allkeys-lru 所有的資料採用LRU演演算法
3.volatile-lfu 設定了超時時間的資料採用lfu演演算法刪除
4.allkeys-lfu 所有資料採用lfu演演算法刪除
5.volatile-random 設定超時時間的資料採用隨機演演算法
6.allkeys-random 所有資料的隨機演演算法
7.volatile-ttl 設定超時時間的資料的TTL演演算法
8.noeviction 如果記憶體溢位了 則報錯返回. 不做任何操作. 預設值
4 關於Redis 快取面試題
問題描述: 由於海量的使用者的請求 如果這時redis伺服器出現問題 則可能導致整個系統崩潰.
執行速度:
1. tomcat伺服器 150-250 之間 JVM調優 1000/秒
2. NGINX 3-5萬/秒
3. REDIS 讀 11.2萬/秒 寫 8.6萬/秒 平均 10萬/秒
4.1 快取穿透
問題描述: 由於使用者高並行環境下存取 資料庫中不存在的資料時 ,容易導致快取穿透.
如何解決: 設定IP限流的操作 nginx中 或者微軟服務機制 API閘道器實現.
4.2 快取擊穿
問題描述: 由於使用者高並行環境下, 由於某個資料之前存在於記憶體中,但是由於特殊原因(資料超時/資料意外刪除)導致redis快取失效. 而使大量的使用者的請求直接存取資料庫.
俗語: 趁他病 要他命
如何解決:
1.設定超時時間時 不要設定相同的時間.
2.設定多級快取
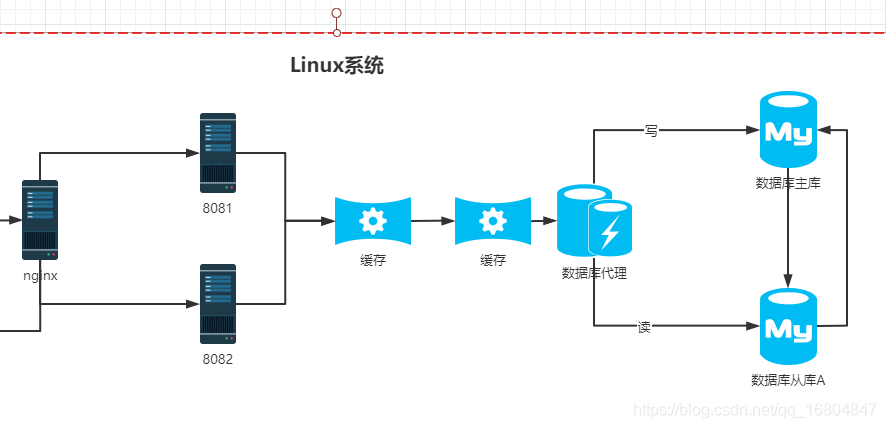
4.3 快取雪崩
說明: 由於高並行條件下 有大量的資料失效.導致redis的命中率太低.而使得使用者直接存取資料庫(伺服器)導致奔潰,稱之為快取雪崩.
解決方案:
1.不要設定相同的超時時間 亂數
2.設定多級快取.
3.提高redis快取的命中率 調整redis記憶體優化策略 採用LRU等演演算法.