條件隨機場之淺出
1.隨機場
當給每個位置中,按照某種分佈隨機賦予相空間(值空間)的值,其全體就叫做隨機場。簡單說就是給定一些候選值,然後隨機的把這些候選值填入到每個位置。
2.概率圖模型
概率圖模型就是用圖來表示變數概率的依賴關係,如下圖所示我們看到概率圖模型主要分為有向圖模型和無向圖模型。有向圖模型如我們之前所介紹過的貝葉斯網路和隱馬爾科夫模型;無向圖網路如馬爾科夫隨機場、條件隨機場等;
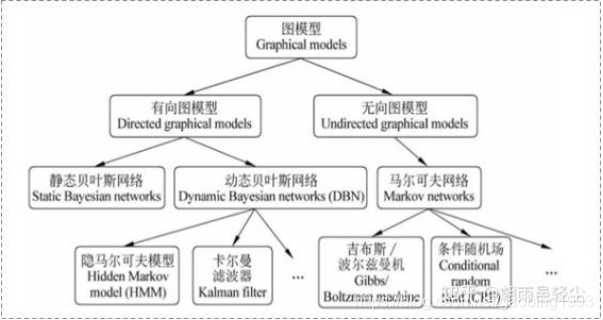
3.馬爾科夫隨機場
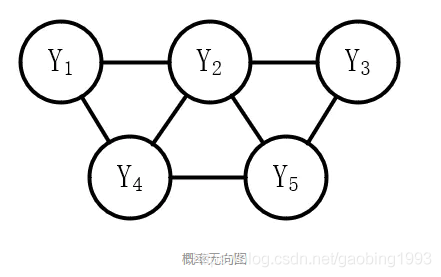
馬爾科夫隨機場就是符合馬爾科夫性質的隨機場,如下圖所示,是一種概率無向圖模型。馬爾科夫性質如下:
區域性馬爾科夫性:給定了某個變數的鄰接變數,則該變數和所有其它的變數無關(獨立)
全域性馬爾科夫性:將區域性馬爾科夫性由變數擴充套件到集合,給定某個變數集的鄰接變數集,則該變數集和其它的變數其無關。
成對馬爾科夫性:將區域性馬爾科夫性反推,所有其它變數都已給定的情況下,兩個不相鄰的變數無關。
符合上面性質中任意一條,我們稱為馬爾科夫隨機場。
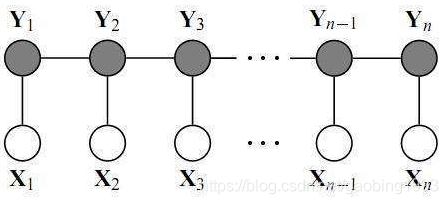
4.條件隨機場概述
條件隨機場就是有條件的馬爾科夫隨機場,即給定X的條件下,Y的分佈符合馬爾科夫隨機場性質。有點類似於隱馬爾可夫模型,不同的是條件隨機場是一種判別式的概率無向圖模型。
生成式:使用聯合概率分佈進行建模,更關注的是變數和結果之間的關係,通俗的來說就是通過條件直接得到結果(可以理解為一道填空題)。常見的生成式模型有:隱馬爾可夫模型、樸素貝葉斯模型、高斯混合模型GMM、LDA等;
判別式:使用條件概率建模,更關注結果之間的差異性,簡單來說就是得到多個結果,然後選擇概率最大的一個(可以理解為一道 選擇題)。常見的判別式模型有:線性迴歸、決策樹、支援向量機SVM、k近鄰、神經網路等
使用條件隨機場解決標註問題,一般更多考慮的是線性鏈條件隨機場,即Y是線性分佈的。其表示式為:P(Yi|X,Y1,Y2...Yn)=P(Yi|X,Yi−1,Yi+1)。對比HMM我們發現,因為HMM是有向圖模型,所以其只需考慮上一個時刻(只有上一個時刻可以到達當前時刻)。而線性鏈條件隨機場是無向圖模型,所以前面和後面的相鄰元素都會考慮(前後兩條路徑都可以到達當前位置)。
5.條件隨機場的引數化表示
為了求解,我們需要將條件隨機場使用數學公式表達出來。
上面已經知道條件分佈函數為:P(Yi|X,Y1,Y2...Yn)=P(Yi|X,Yi−1,Yi+1)
現在需要將P(Yi|X,Yi−1,Yi+1)表達出來,更進一步的我們需要將P(Y|X)表達出來。其表示式如下:
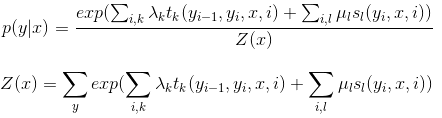
接下來對上面的公式進行簡單的解釋:
1.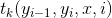 和
和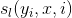 稱為特徵函數。為狀態序列特徵得分,表示
稱為特徵函數。為狀態序列特徵得分,表示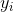 受到
受到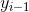 的影響;表示觀測序列特徵得分,表示受到
的影響;表示觀測序列特徵得分,表示受到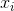 的影響;特徵函數的取值為1或者0,表示滿足特徵或者不滿足特徵。
的影響;特徵函數的取值為1或者0,表示滿足特徵或者不滿足特徵。
2.λk和μl為權重,表示對應特徵函數的重要程度或者正負方向
3.p(y|x)的分母Z(x)為所有可能的狀態序列總的得分,分子為某一個序列的得分。都進行了exp指數化處理,用來拉開線性條件下高分與低分的距離。類似於邏輯迴歸進行多分類的softmax公式,最終得到的是某一個序列對應的概率。
6.構建條件隨機場的特徵函數
特徵函數其實就是對序列進行打分的函數,用來表示不同序列的準確程度。上面的表示式是對特徵函數的高度抽象,下面我們針對詞性標註問題來具體構建我們的特徵函數:
詞性標註就是標出一個句子中每個詞的詞性,比如:袁冰妍是當今世界上最好看的人,對這句話進行詞性標註會得到:袁冰妍(名詞)是(連詞)當今(副詞)世界上(名詞)最好看的(形容詞)人(名詞)。
上面的句子有6個片語成,正確的標註序列是:(名詞、連詞、副詞、名詞、形容詞、名詞),但是不正確的標註序列會有很多個。如何判斷序列的正確程度,這是就該特徵函數出馬了。
現在我們正式定義一下CRF的特徵函數,它是這樣一個函數,接受四個引數:
1.x表示句子資訊
2.i表示詞的下標
3.表示當前詞的詞性
4.表示相鄰的前一個詞的詞性
特徵函數並不像我們所熟悉的其它函數一樣,是一個具體的公式。而是一種高度的抽象,接受句子和相鄰詞的標註資訊,對當前詞的標註結果進行打分。好處就是我們可以針對具體的任務定義不同的特徵函數,靈活性更高。不好的就是還得自己去定義,有點麻煩。可以看到特徵函數中已經有了當前序列的資訊,這就是我們上面說的判別式。已經得到序列的基礎上,使用特徵函數進行篩選過濾。結果為1表示符合特徵函數,為0表示不符合特徵函數。
特徵函數的例子:
下面針對詞性標註問題舉幾個具體的特徵函數的例子:
1.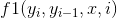 ,當為形容詞時為名詞,f1為1,否則f1為0;這是一個正確的判別式,所以其λ權重應該為正,並且權重較大。
,當為形容詞時為名詞,f1為1,否則f1為0;這是一個正確的判別式,所以其λ權重應該為正,並且權重較大。
2.,當為形容詞為形容詞f1為1,否則f1為0;這是一個錯誤的判別式,所以其權重應該為負,表示相反的方向。
簡化表達損失
我們將特徵函數統一用f(y,x)表示,權重統一用w來表示。則最初的引數化表示就簡化為下面這樣:
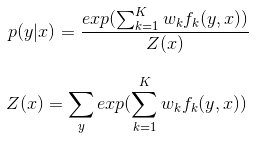
7.CRF+BiLSTM
下面聊一下具體的CRF應用,使用BiLSTM+CRF來進行命名實體識別(實體可以理解為名詞的範例,比如袁冰妍是美女這個名詞的一個範例,命名實體識別就是把這些範例屬於哪些名詞給找出來);
下面簡要解釋一下流程:
1.BiLSTM可以得到每一個單詞對應的實體的得分值;
2.使用CRF對BiLSTM得到的組合進行過濾,以確保實體組合的有效性。
3.CRF目標函數如下,即真實路徑概率比所有可能路徑的概率(就是我們上一節所說的表示式的具體化)。如果要列舉所有的可能路徑計算量會非常的大,為了簡化計算。我們使用動態規劃演演算法(將大問題分解為多個子問題,使用歷史子問題的結果來求下一個子問題,是一種以空間換時間的演演算法)來求解每一時刻的全部路徑,然後求和(其實就是前面說過的前向演演算法);然後我們可以使用梯度下降法進行優化。
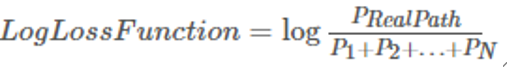
4.當我們得到了模型之後,推理使用維特比演演算法(每一個時刻都取最大概率值,使用最後一時刻的最大概率進行回溯,過濾掉多餘的路徑,得到我們的最優序列,具體不在贅述!)
8.總結
本篇中我們介紹了條件隨機場,類似於HMM,但是比HMM更加強大和靈活。是一種有條件的無向概率圖模型,一種判別式模型。然後介紹了特徵函數,這是其真正的強大之處。最後我們將條件隨機場使用數學公式進行表達出來,然後將CRF和BiLSTM結合起來,作為神經網路中的一層,來進行命名實體識別。於HMM一樣,在學習的時候我們使用前向演演算法,動態的求出下一位置的分值。在預測的時候使用維特比演演算法,得到最終的最優序列。
9.鬼滅之刀
我前生是一個給周武王趕車的車伕,面對仇敵的追殺,我毅然決然的選擇了左邊的彎道。再往前是一個下坡,我將馬趕的飛快,回過頭敵人就已經看不見了。文人雅士們都喜歡梅蘭竹菊,高雅、淡泊、有氣節。可是我只對韭菜情有獨鍾,因為韭菜包餃子好吃。它極其常見,還有點重口味,卻讓我得到了實實在在的快樂。對於生活中那些樸素卻又不可缺少的事物,我總是沒有什麼抵抗力。作為一個男人,40多年的趕馬生涯中,我唯一學會的就是,面對生活的苦難,咬著後槽牙說無所謂。我只是歷史中一個寂寂無名的小人物,不會被任何人記住,即使活著的時候也沒有什麼人會在意我。為了使自己的意志不至於完全的消失,我曾在黑夜中將自己的祕密寫進一個小盒子裡。幾千年來,我一直等待某一世能在夢中找到自己。昨天晚上盒子裡的我終於又聽到了人類微弱的呼吸聲,我在等待,等待著被完全的喚醒。我要好好的看一看這21世紀,繽紛絢麗、美女如雲。
燃爆全場!LiSA首唱《鬼滅之刃》最燃神曲《紅蓮華》完整版~【最高音畫質收藏】【老織首次現場激情演唱動漫歌曲《紅蓮華》完整版】