3道常見的SQL筆試題,你要不要來試試!
都說「金九銀十」,馬上十月份即將結束,相信還有相當多的小夥伴沒找到合適的工作。在筆試過程中,總會出現那麼一兩道「有趣」的SQL題,來檢測應聘者的一個邏輯思維,這對於初入職場的「小白」也是非常不友好。不用擔心,本篇部落格,博主整理了幾道在面試中高頻出現的「SQL」筆試題,助你在接下來的面試中一往無前,勢如破竹!

文章目錄
1、查詢連續登陸3天以上的使用者
這是一道非常經典的問題,這裡提供其中一種思路。
表資訊如下圖:
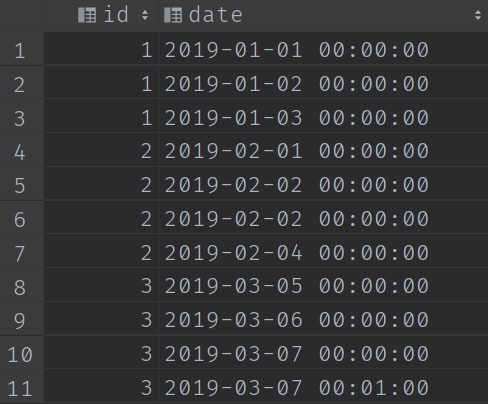
step1: 使用者登入日期去重
因為一個使用者同一天可能登入多次,所以我們首先需要用使用者登入日期去重。
select DISTINCT date(date) as "日期",id from demo01;
查詢結果:
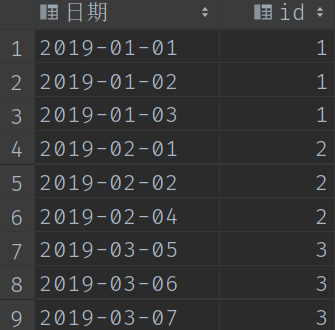
step2: 用row_number() over()函數計數
有了第一步去重後的結果,我們可以對其進行開窗,以id分組,日期升序排序,獲取到每個日期的排名。
select *,row_number() over(PARTITION by id order by `日期`) as cum from (select DISTINCT date(date) as `日期`,id from demo01)a;
查詢結果:
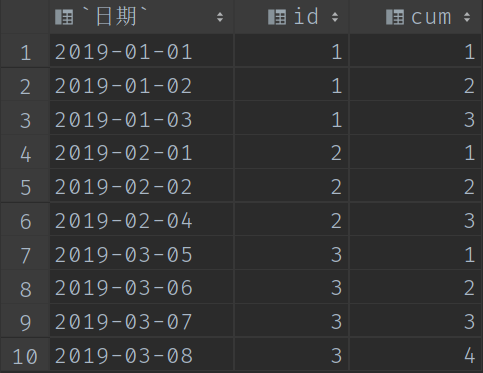
相信看到這裡,各位小夥伴已經看出其中的「玄機」了~為什麼我們需要在這一步對時間進行一個排序呢?
可以發現,用row_number開窗之後的名次是連續的,那麼如果日期也是連續的,它們的差值不就是一個固定的值了嗎?
step3:日期減去計數值得到結果
因為菌哥這裡演示用的是hql,所以這裡獲取日期差值使用了date_sub函數。
select *,date_sub(`日期`,cum) as `結果` from (select *,row_number() over(PARTITION by id order by `日期`) as cum from (select DISTINCT date(date) as `日期`,id from demo01)a)b;
查詢結果:
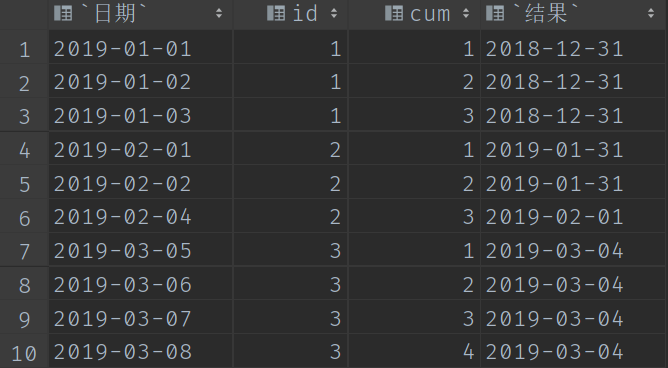
step4:根據id和結果分組並計算count
最後一步,我們直接根據step3中獲取到的差值,根據id和差值進行一個分組求count即可。如果是要求連續登入3天以上,我們直接判斷 count 的個數大於等於3即可。
select id,count(*) from (select *,date_sub(`日期`,cum) as `結果` from (select *,row_number() over(PARTITION by id order by `日期`) as cum from (select DISTINCT date(date) as `日期`,id from demo01)a)b)c GROUP BY id,`結果` having count(*)>=3;
執行結果:
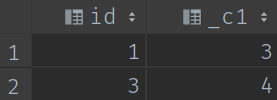
答案已經出來了,id為1和3的使用者至少連續登入了3天及以上,他們分別連續登入的時長為3天和4天。
2、統計每個使用者的累計存取次數
這個同樣也是經常在筆試中出現的題目,大家可以根據作者的思路回顧一下:
表資訊如下圖:
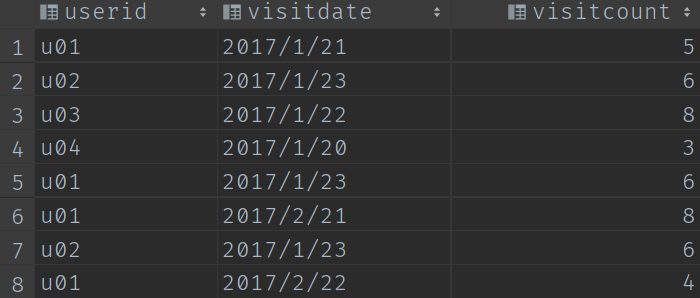
要求使用SQL統計出每個使用者的累積存取次數,如下表所示:
| 使用者id | 月份 | 小計 | 累積 |
|---|---|---|---|
| u01 | 2017-01 | 11 | 11 |
| u01 | 2017-02 | 12 | 23 |
| u02 | 2017-01 | 12 | 12 |
| u03 | 2017-01 | 8 | 8 |
| u04 | 2017-01 | 3 | 3 |
step1: 修改資料格式
從結果反推,需要查詢實現按照 年-月 分組的資料,所以我們這一步先對原資料進行一個處理。
select
userId,
date_format(regexp_replace(visitDate,'/','-'),'yyyy-MM') mn,
visitCount
from
action;t1
處理結果:
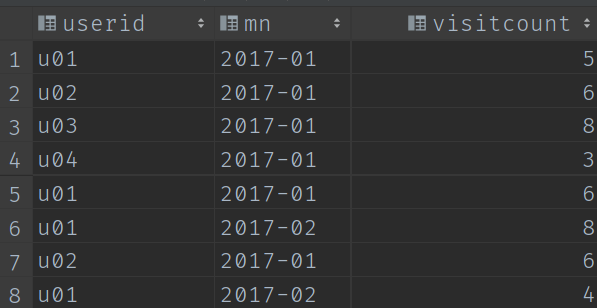
step2: 計算每人單月存取量
為了讓子查詢看起來更加的美觀,我們這裡先用t1代替上一步的結果。通過這一步,我們就可以獲取到每個使用者,每個月的存取量。
select
userId,
mn,
sum(visitCount) mn_count
from
t1
group by userId,mn;t2
查詢的結果:
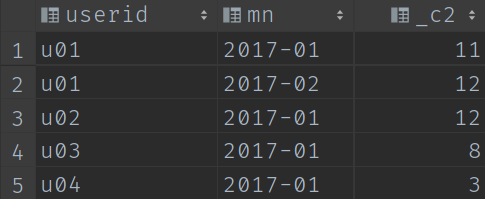
step3: 按月累計計算存取量
我們將第二步的結果用變數 t2 來表示。到這一步,我們用一個sum開窗函數,對userid進行分組,mn時間進行排序即可大功告成。
select
userId,
mn,
mn_count,
sum(mn_count) over(partition by userId order by mn) mn_all
from t2;
最終結果:
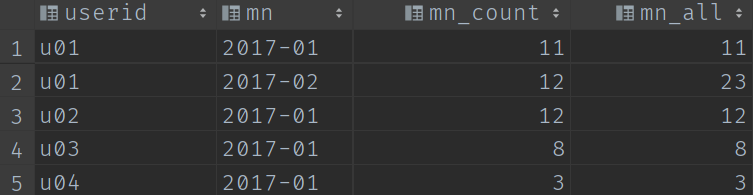
完整SQL
溫馨提示:上述的步驟展示的都是不完整的SQL,每步使用變數代替前一步的SQL語句只是為了方便給大家展示,實際上執行的結果都是作者將完整的SQL放進去跑的哈~
select
userId,
mn,
mn_count,
sum(mn_count) over(partition by userId order by mn) mn_all
from
( select
userId,
mn,
sum(visitCount) mn_count
from
(select
userId,
date_format(regexp_replace(visitDate,'/','-'),'yyyy-MM') mn,
visitCount
from
action)t1
group by userId,mn)t2;
3、分組TopN
有50W個店鋪,每個顧客訪客存取任何一個店鋪的任何一個商品時都會產生一條存取紀錄檔,存取紀錄檔儲存的表名為Visit,訪客的使用者id為user_id,被存取的店鋪名稱為shop。
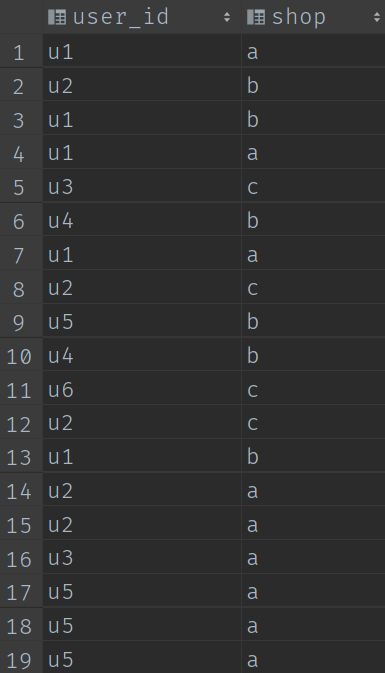
需求:每個店鋪存取次數top3的訪客資訊。輸出店鋪名稱、訪客id、存取次數。
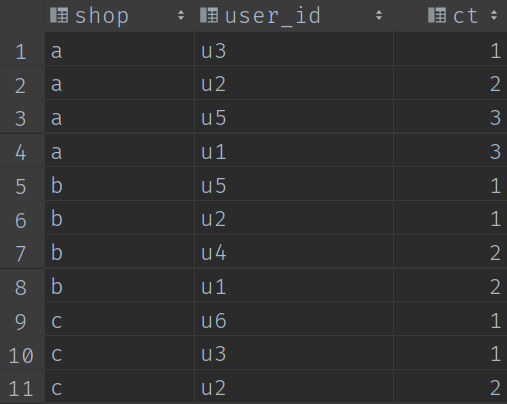
step1:查詢每個店鋪被每個使用者存取次數
因為我們最終需要獲取每個店鋪存取量top3的使用者資訊,所以在這一步,我們就先把每個店鋪的每個使用者的存取次數計算出來。
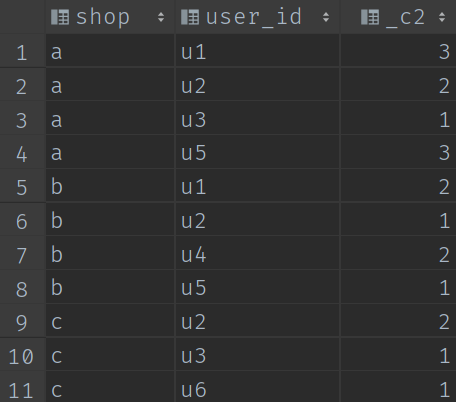
select shop,user_id,count(*) ct
from visit
group by shop,user_id;t1
計算結果:
step2:計算每個店鋪被使用者存取次數排名
有了第一步每個店鋪下所被存取使用者的存取量,我們想獲取前三,毫無疑問,我們需要使用到開窗函數 rank。
可能就有朋友問了,為什麼不能用 row_number ?
主要還是 row_number 對於相同資料的排名不是一樣的,如果我們取Topic3,出現了相同存取次數的資料,那我們肯定都得保留下來的對吧~~
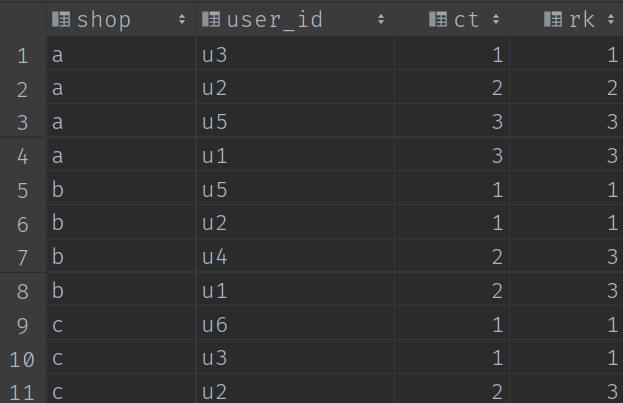
select shop,user_id,ct,rank() over(partition by shop order by ct) rk
from t1;t2
計算結果:
step3: 取每個店鋪排名前3的資料
有了 step2 的結果,我們想要取每個店鋪前三的資料豈不是輕而易舉~
select shop,user_id,ct
from t2
where rk<=3;
計算結果:
完整SQL
好了,結果已經查詢出來了,這裡把上面step的SQL整合到一起~
select
shop,
user_id,
ct
from
(select
shop,
user_id,
ct,
rank() over(partition by shop order by ct) rk
from
(select
shop,
user_id,
count(*) ct
from visit
group by
shop,
user_id)t1
)t2
where rk<=3;
結語
我們不論是看書還是刷題,不在於數量多少,而一定要求「精」。這就要求我們學會去思考,學會舉一反三。真正具備解題能力的人,我相信一定不是把時間花在大量刷題上,而是懂得從不同型別的習題上,及時總結複習的人。
以上3道SQL「小菜」怕是滿足不了大夥,以後有機會再為大家總結些別的題目,本篇文章到這裡就結束了。對技術宇宙充滿好奇,喜歡本文的朋友,可以掃碼關注作者原創公眾號【猿人菌】,我們下期見!


