騰訊面試:MySQL事務與MVCC如何實現的隔離級別?
有情懷,有乾貨,微信搜尋【三太子敖丙】關注這個不一樣的程式設計師。
本文 GitHub https://github.com/JavaFamily 已收錄,有一線大廠面試完整考點、資料以及我的系列文章。
前言
其實資料庫章節基本上的知識點我都寫過一遍了,包括這篇事務和MVCC的,但是國慶期間我翻閱資料的時候我發現之前寫的還差點意思,例子舉得也差點意思,那我就根據我自己最新的理解,加上之前的總結相當於重寫了,希望你也有新的收穫。
資料庫事務介紹
事務的四大特性(ACID)
-
原子性(atomicity): 事務的最小工作單元,要麼全成功,要麼全失敗。
-
一致性(consistency): 事務開始和結束後,資料庫的完整性不會被破壞。
-
隔離性(isolation): 不同事務之間互不影響,四種隔離級別為RU(讀未提交)、RC(讀已提交)、RR(可重複讀)、SERIALIZABLE (序列化)。
-
永續性(durability): 事務提交後,對資料的修改是永久性的,即使系統故障也不會丟失。
事務的隔離級別
讀未提交(Read UnCommitted/RU)
又稱為髒讀,一個事務可以讀取到另一個事務未提交的資料。這種隔離級別歲最不安全的一種,因為未提交的事務是存在回滾的情況。
讀已提交(Read Committed/RC)
又稱為不可重複讀,一個事務因為讀取到另一個事務已提交的修改資料,導致在當前事務的不同時間讀取同一條資料獲取的結果不一致。
舉個例子,在下面的例子中就會發現SessionA在一個事務期間兩次查詢的資料不一樣。原因就是在於當前隔離級別為 RC,SessionA的事務可以讀取到SessionB提交的最新資料。
| 發生時間 | SessionA | SessionB |
|---|---|---|
| 1 | begin; | |
| 2 | select * from user where id=1;(張三) | |
| 3 | update user set name=‘李四’ where id=1;(預設隱式提交事務) | |
| 4 | select * from user where id=1;(李四) | |
| 5 | update user set name=‘王二’ where id=1;(預設隱式提交事務) | |
| 6 | select * from user where id=1;(王二) |
可重複讀(Repeatable Read/RR)
又稱為幻讀,一個事物讀可以讀取到其他事務提交的資料,但是在RR隔離級別下,當前讀取此條資料只可讀取一次,在當前事務中,不論讀取多少次,資料任然是第一次讀取的值,不會因為在第一次讀取之後,其他事務再修改提交此資料而產生改變。因此也成為幻讀,因為讀出來的資料並不一定就是最新的資料。
舉個例子:在SessionA中第一次讀取資料時,後續其他事務修改提交資料,不會再影響到SessionA讀取的資料值。此為可重複讀。
| 發生時間 | SessionA | SessionB |
|---|---|---|
| 1 | begin; | |
| 2 | select * from user where id=1;(張三) | |
| 3 | update user set name=‘李四’ where id=1; (預設隱式提交事務) | |
| 4 | select * from user where id=1;(張三) | |
| 5 | update user set name=‘王二’ where id=1;(預設隱式提交事務) | |
| 6 | select * from user where id=1;(張三) |
序列化(Serializable)
所有的資料庫的讀或者寫操作都為序列執行,當前隔離級別下只支援單個請求同時執行,所有的操作都需要佇列執行。所以種隔離級別下所有的資料是最穩定的,但是效能也是最差的。資料庫的鎖實現就是這種隔離級別的更小粒度版本。
| 發生時間 | SessionA | SessionB |
|---|---|---|
| 1 | begin; | |
| 2 | begin; | |
| 3 | update user set name=‘李四’ where id=1; | |
| 4 | select * from user where id=1;(等待、wait) | |
| 5 | commit; | |
| 6 | select * from user where id=1;(李四) |
事務和MVCC原理
不同事務同時操作同一條資料產生的問題
範例:
| 發生時間 | SessionA | SessionB |
|---|---|---|
| 1 | begin; | |
| 2 | begin; | |
| 3 | 查詢餘額 = 1000元 | |
| 4 | 查詢餘額 = 1000元 | |
| 5 | 存入金額 100元,修改餘額為 1100元 | |
| 6 | 取出現金100元,此時修改餘額為900元 | |
| 8 | 提交事務(餘額=1100) | |
| 9 | 提交事務(餘額=900) |
| 發生時間 | SessionA | SessionB |
|---|---|---|
| 1 | begin; | |
| 2 | begin; | |
| 3 | 查詢餘額 = 1000元 | |
| 4 | 查詢餘額 = 1000元 | |
| 5 | 存入金額 100元,修改餘額為 1100元 | |
| 6 | 取出現金100元,此時修改餘額為900元 | |
| 8 | 提交事務(餘額=1100) | |
| 9 | 復原事務(餘額恢復為1000元) |
上面的兩種情況就是對於一條資料,多個事務同時操作可能會產生的問題,會出現某個事務的操作被覆蓋而導致資料丟失。
LBCC 解決資料丟失
LBCC,基於鎖的並行控制,Lock Based Concurrency Control。
使用鎖的機制,在當前事務需要對資料修改時,將當前事務加上鎖,同一個時間只允許一條事務修改當前資料,其他事務必須等待鎖釋放之後才可以操作。
MVCC 解決資料丟失
MVCC,多版本的並行控制,Multi-Version Concurrency Control。
使用版本來控制並行情況下的資料問題,在B事務開始修改賬戶且事務未提交時,當A事務需要讀取賬戶餘額時,此時會讀取到B事務修改操作之前的賬戶餘額的副本資料,但是如果A事務需要修改賬戶餘額資料就必須要等待B事務提交事務。
MVCC使得資料庫讀不會對資料加鎖,普通的SELECT請求不會加鎖,提高了資料庫的並行處理能力。 藉助MVCC,資料庫可以實現READ COMMITTED,REPEATABLE READ等隔離級別,使用者可以檢視當前資料的前一個或者前幾個歷史版本,保證了ACID中的I特性(隔離性)。
InnoDB的MVCC實現邏輯
InnoDB儲存引擎儲存的MVCC的資料
InnoDB的MVCC是通過在每行記錄後面儲存兩個隱藏的列來實現的。一個儲存了行的事務ID(DB_TRX_ID),一個儲存了行的回滾指標(DB_ROLL_PT)。每開始一個新的事務,都會自動遞增產 生一個新的事務id。事務開始時刻的會把事務id放到當前事務影響的行事務id中,當查詢時需要用當前事務id和每行記錄的事務id進行比較。
下面看一下在REPEATABLE READ隔離級別下,MVCC具體是如何操作的。
SELECT
InnoDB 會根據以下兩個條件檢查每行記錄:
-
InnoDB只查詢版本早於當前事務版本的資料行(也就是,行的事務編號小於或等於當前事務的事務編號),這樣可以確保事務讀取的行,要麼是在事務開始前已經存在的,要麼是事務自身插入或者修改過的。
-
刪除的行要事務ID判斷,讀取到事務開始之前狀態的版本,只有符合上述兩個條件的記錄,才能返回作為查詢結果。
INSERT
InnoDB為新插入的每一行儲存當前事務編號作為行版本號。
DELETE
InnoDB為刪除的每一行儲存當前事務編號作為行刪除標識。
UPDATE
InnoDB為插入一行新記錄,儲存當前事務編號作為行版本號,同時儲存當前事務編號到原來的行作為行刪除標識。
儲存這兩個額外事務編號,使大多數讀操作都可以不用加鎖。這樣設計使得讀資料操作很簡單,效能很好,並且也能保證只會讀取到符合標準的行。不足之處是每行記錄都需要額外的儲存空間,需要做更多的行檢查工作,以及一些額外的維護工作。
MVCC只在REPEATABLE READ和READ COMMITIED兩個隔離級別下工作。其他兩個隔離級別都和 MVCC不相容 ,因為READ UNCOMMITIED總是讀取最新的資料行,而不是符合當前事務版本的資料行。而SERIALIZABLE則會對所有讀取的行都加鎖。
MVCC 在mysql 中的實現依賴的是 undo log 與 read view 。
undo log
根據行為的不同,undo log分為兩種: insert undo log 和 update undo log
- insert undo log:
insert 操作中產生的undo log,因為insert操作記錄只對當前事務本身課件,對於其他事務此記錄不可見,所以 insert undo log 可以在事務提交後直接刪除而不需要進行purge操作。
purge的主要任務是將資料庫中已經 mark del 的資料刪除,另外也會批次回收undo pages
資料庫 Insert時的資料初始狀態:
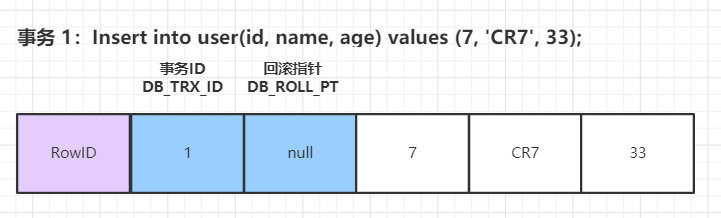
-
update undo log:
update 或 delete 操作中產生的 undo log。 因為會對已經存在的記錄產生影響,為了提供 MVCC機制,因此update undo log 不能在事務提交時就進行刪除,而是將事務提交時放到入 history list 上,等待 purge 執行緒進行最後的刪除操作。
資料第一次被修改時:
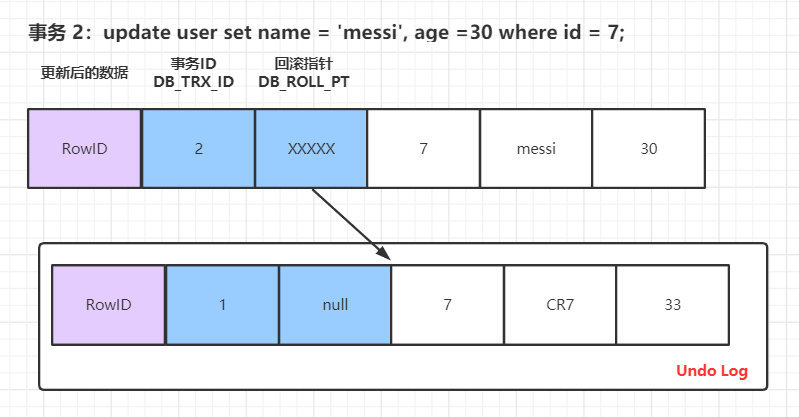
當另一個事務第二次修改當前資料:
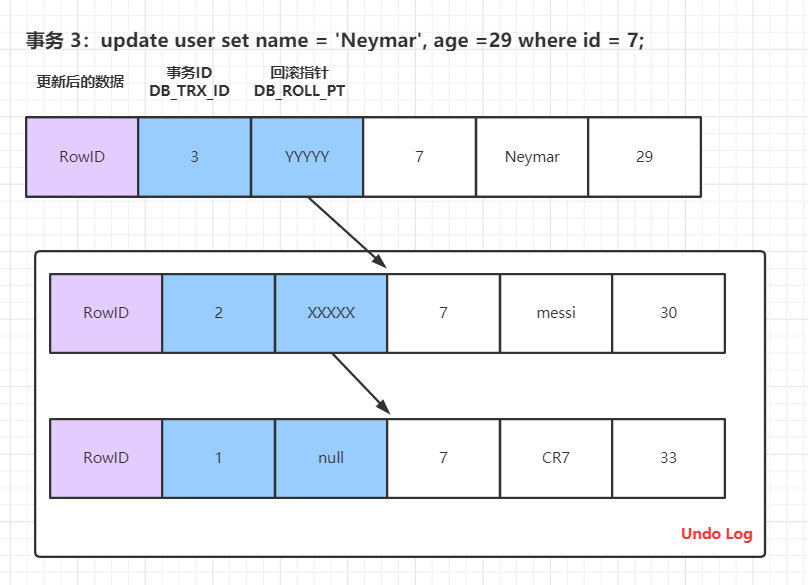
為了保證事務並行操作時,在寫各自的undo log時不產生衝突,InnoDB採用回滾段的方式來維護undo log的並行寫入和持久化。回滾段實際上是一種 Undo 檔案組織方式。
ReadView
對於 RU(READ UNCOMMITTED) 隔離級別下,所有事務直接讀取資料庫的最新值即可,和 SERIALIZABLE 隔離級別,所有請求都會加鎖,同步執行。所以這對這兩種情況下是不需要使用到 Read View 的版本控制。
對於 RC(READ COMMITTED) 和 RR(REPEATABLE READ) 隔離級別的實現就是通過上面的版本控制來完成。兩種隔離界別下的核心處理邏輯就是判斷所有版本中哪個版本是當前事務可見的處理。針對這個問題InnoDB在設計上增加了ReadView的設計,ReadView中主要包含當前系統中還有哪些活躍的讀寫事務,把它們的事務id放到一個列表中,我們把這個列表命名為為m_ids。
對於查詢時的版本鏈資料是否看見的判斷邏輯:
-
如果被存取版本的 trx_id 屬性值小於 m_ids 列表中最小的事務id,表明生成該版本的事務在生成 ReadView 前已經提交,所以該版本可以被當前事務存取。
-
如果被存取版本的 trx_id 屬性值大於 m_ids 列表中最大的事務id,表明生成該版本的事務在生成 ReadView 後才生成,所以該版本不可以被當前事務存取。
-
如果被存取版本的 trx_id 屬性值在 m_ids 列表中最大的事務id和最小事務id之間,那就需要判斷一下 trx_id 屬性值是不是在 m_ids 列表中,如果在,說明建立 ReadView 時生成該版本的事務還是活躍的,該版本不可以被存取;如果不在,說明建立 ReadView 時生成該版本的事務已經被提交,該版本可以被存取。
舉個例子:
READ COMMITTED 隔離級別下的ReadView
每次讀取資料前都生成一個ReadView (m_ids列表)
| 時間 | Transaction 777 | Transaction 888 | Trasaction 999 |
|---|---|---|---|
| T1 | begin; | ||
| T2 | begin; | begin; | |
| T3 | UPDATE user SET name = ‘CR7’ WHERE id = 1; | ||
| T4 | … | ||
| T5 | UPDATE user SET name = ‘Messi’ WHERE id = 1; | SELECT * FROM user where id = 1; | |
| T6 | commit; | ||
| T7 | UPDATE user SET name = ‘Neymar’ WHERE id = 1; | ||
| T8 | SELECT * FROM user where id = 1; | ||
| T9 | UPDATE user SET name = ‘Dybala’ WHERE id = 1; | ||
| T10 | commit; | ||
| T11 | SELECT * FROM user where id = 1; |
這裡分析下上面的情況下的ReadView
時間點 T5 情況下的 SELECT 語句:
當前時間點的版本鏈:
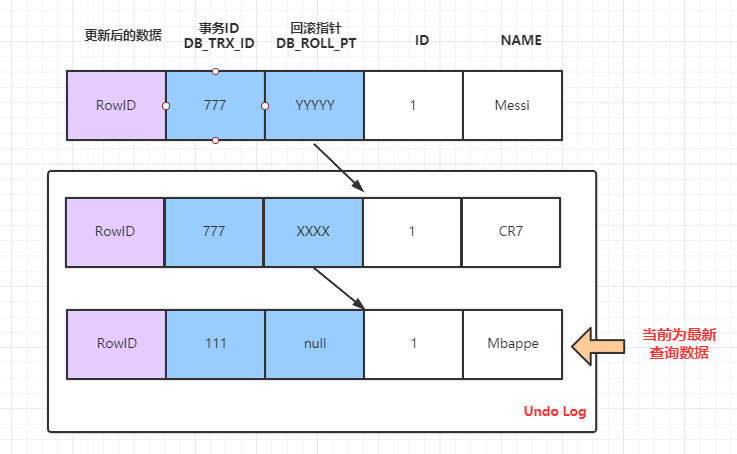
此時 SELECT 語句執行,當前資料的版本鏈如上,因為當前的事務777,和事務888 都未提交,所以此時的活躍事務的ReadView的列表情況 m_ids:[777, 888] ,因此查詢語句會根據當前版本鏈中小於 m_ids 中的最大的版本資料,即查詢到的是 Mbappe。
時間點 T8 情況下的 SELECT 語句:
當前時間的版本鏈情況:
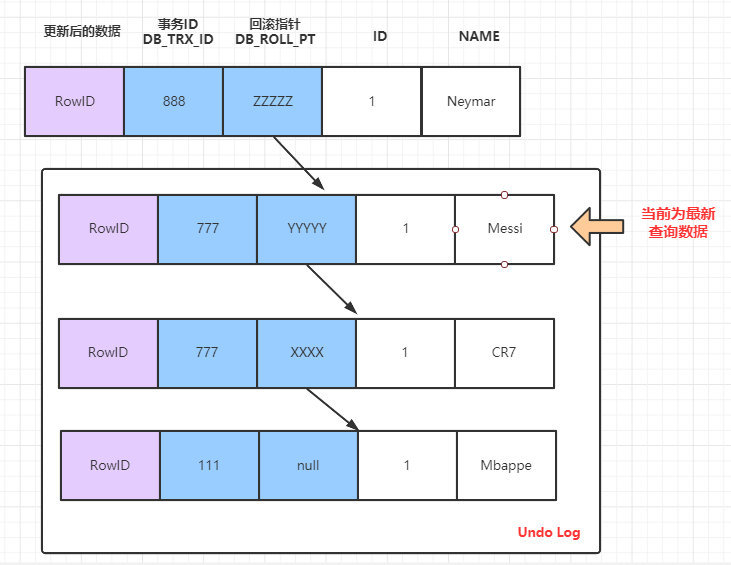
此時 SELECT 語句執行,當前資料的版本鏈如上,因為當前的事務777已經提交,和事務888 未提交,所以此時的活躍事務的ReadView的列表情況 m_ids:[888] ,因此查詢語句會根據當前版本鏈中小於 m_ids 中的最大的版本資料,即查詢到的是 Messi。
時間點 T11 情況下的 SELECT 語句:
當前時間點的版本鏈資訊:
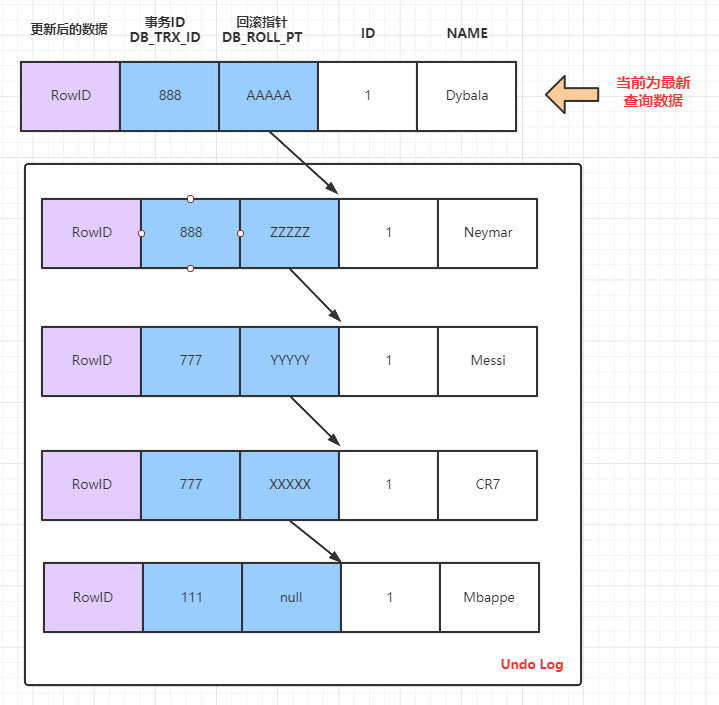
此時 SELECT 語句執行,當前資料的版本鏈如上,因為當前的事務777和事務888 都已經提交,所以此時的活躍事務的ReadView的列表為空 ,因此查詢語句會直接查詢當前資料庫最新資料,即查詢到的是 Dybala。
總結: 使用READ COMMITTED隔離級別的事務在每次查詢開始時都會生成一個獨立的 ReadView。
REPEATABLE READ 隔離級別下的ReadView
在事務開始後第一次讀取資料時生成一個ReadView(m_ids列表)
| 時間 | Transaction 777 | Transaction 888 | Trasaction 999 |
|---|---|---|---|
| T1 | begin; | ||
| T2 | begin; | begin; | |
| T3 | UPDATE user SET name = ‘CR7’ WHERE id = 1; | ||
| T4 | … | ||
| T5 | UPDATE user SET name = ‘Messi’ WHERE id = 1; | SELECT * FROM user where id = 1; | |
| T6 | commit; | ||
| T7 | UPDATE user SET name = ‘Neymar’ WHERE id = 1; | ||
| T8 | SELECT * FROM user where id = 1; | ||
| T9 | UPDATE user SET name = ‘Dybala’ WHERE id = 1; | ||
| T10 | commit; | ||
| T11 | SELECT * FROM user where id = 1; |
時間點 T5 情況下的 SELECT 語句:
當前版本鏈:
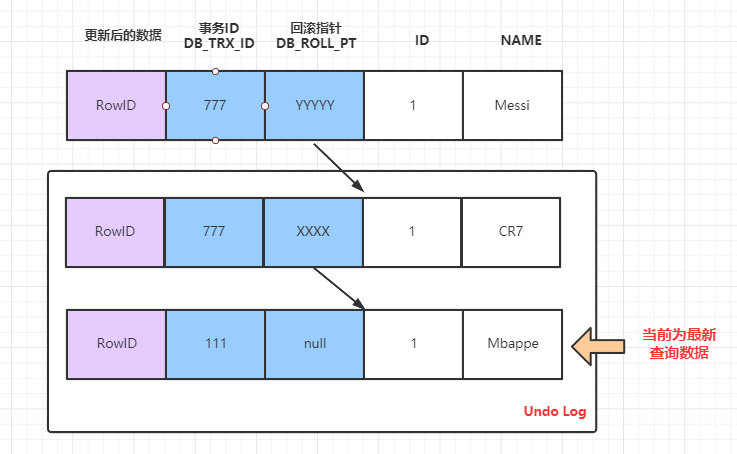
再當前執行select語句時生成一個ReadView,此時 m_ids 內容是:[777,888],所以但前根據ReadView可見版本查詢到的資料為 Mbappe。
時間點 T8 情況下的 SELECT 語句:
當前的版本鏈:
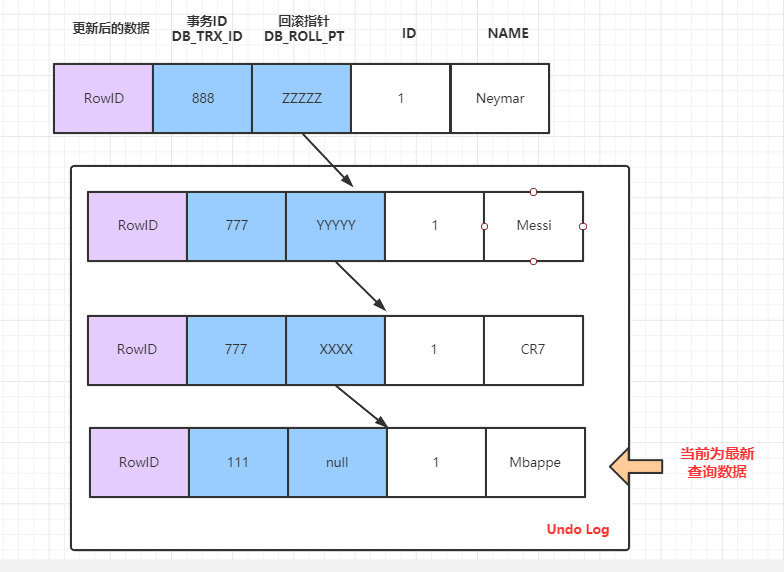
此時在當前的 Transaction 999 的事務裡。由於T5的時間點已經生成了ReadView,所以再當前的事務中只會生成一次ReadView,所以此時依然沿用T5時的m_ids:[777,999],所以此時查詢資料依然是 Mbappe。
時間點 T11 情況下的 SELECT 語句:
當前的版本鏈:
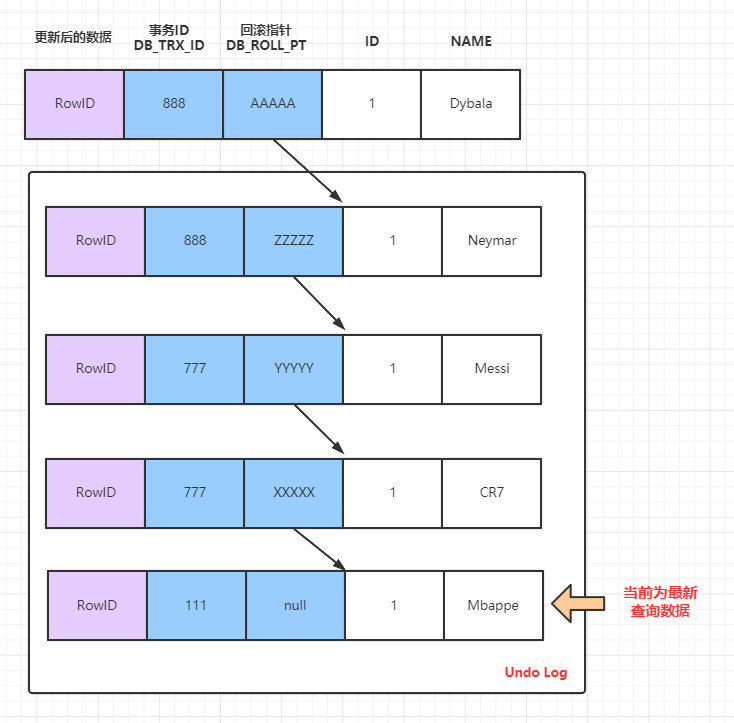
此時情況跟T8完全一樣。由於T5的時間點已經生成了ReadView,所以再當前的事務中只會生成一次ReadView,所以此時依然沿用T5時的m_ids:[777,999],所以此時查詢資料依然是 Mbappe。
MVCC總結:
所謂的MVCC(Multi-Version Concurrency Control ,多版本並行控制)指的就是在使用 READ COMMITTD 、REPEATABLE READ 這兩種隔離級別的事務在執行普通的 SEELCT 操作時存取記錄的版本鏈的過程,這樣子可以使不同事務的 讀-寫 、 寫-讀 操作並行執行,從而提升系統效能。
在 MySQL 中, READ COMMITTED 和 REPEATABLE READ 隔離級別的的一個非常大的區別就是它們生成 ReadView 的時機不同。在 READ COMMITTED 中每次查詢都會生成一個實時的 ReadView,做到保證每次提交後的資料是處於當前的可見狀態。而 REPEATABLE READ 中,在當前事務第一次查詢時生成當前的 ReadView,並且當前的 ReadView 會一直沿用到當前事務提交,以此來保證可重複讀(REPEATABLE READ)。
好啦以上就是本期的全部內容了,如果你覺得寫得不錯,請給我一個免費的在看,你知道的越多,你不知道的越多,我是敖丙,我們下期見,拜拜!
絮叨
敖丙把自己的面試文章整理成了一本電子書,共 1630頁!
乾貨滿滿,字字精髓。目錄如下,還有我複習時總結的面試題以及簡歷模板,現在免費送給大家。
連結:https://pan.baidu.com/s/1ZQEKJBgtYle3v-1LimcSwg 密碼:wjk6
我是敖丙,你知道的越多,你不知道的越多,感謝各位人才的:點贊、收藏和評論,我們下期見!
文章持續更新,可以微信搜一搜「 三太子敖丙 」第一時間閱讀,回覆【資料】有我準備的一線大廠面試資料和簡歷模板,本文 GitHub https://github.com/JavaFamily 已經收錄,有大廠面試完整考點,歡迎Star。


