鐵汁,MySQL索引優化規則送你!!
今天欄目為大家介紹MySQL的索引優化規則。

前言
- 索引的相信大家都聽說過,但是真正會用的又有幾人?平時工作中寫SQL真的會考慮到這條SQL如何能夠用上索引,如何能夠提升執行效率?
- 此篇文章詳細的講述了索引優化的幾個原則,只要在工作中能夠隨時應用到,相信你寫出的SQL一定是效率最高,最牛逼的。
- 文章的腦圖如下:
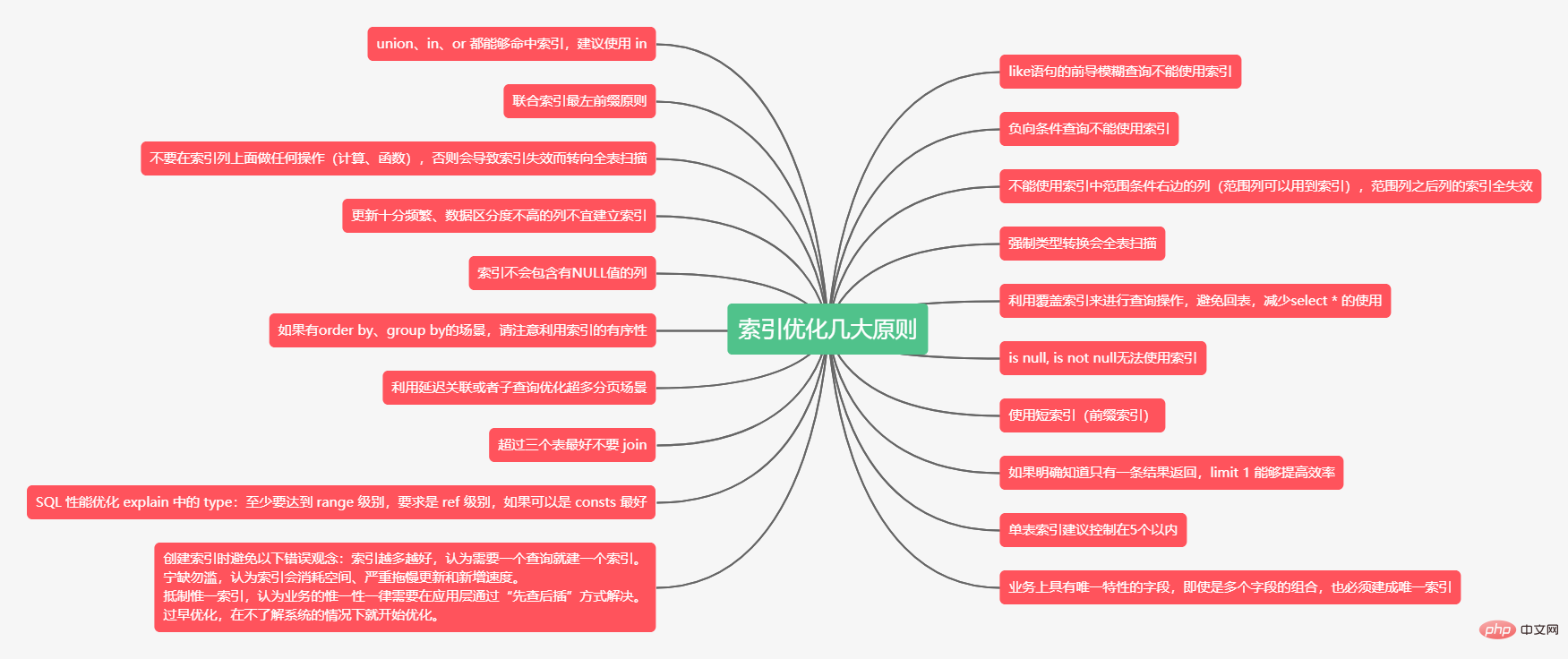
索引優化規則
1、like語句的前導模糊查詢不能使用索引
select * from doc where title like '%XX'; --不能使用索引select * from doc where title like 'XX%'; --非前導模糊查詢,可以使用索引複製程式碼
- 因為頁面搜尋嚴禁左模糊或者全模糊,如果需要可以使用搜尋引擎來解決。
2、union、in、or 都能夠命中索引,建議使用 in
union能夠命中索引,並且MySQL 耗費的 CPU 最少。
select * from doc where status=1union allselect * from doc where status=2;複製程式碼
in能夠命中索引,查詢優化耗費的 CPU 比union all多,但可以忽略不計,一般情況下建議使用in。
select * from doc where status in (1, 2);複製程式碼
or新版的 MySQL 能夠命中索引,查詢優化耗費的 CPU 比in多,不建議頻繁用or。
select * from doc where status = 1 or status = 2複製程式碼
- 補充:有些地方說在
where條件中使用or,索引會失效,造成全表掃描,這是個誤區:
①要求
where子句使用的所有欄位,都必須建立索引;②如果資料量太少,mysql制定執行計劃時發現全表掃描比索引查詢更快,所以會不使用索引;
③確保mysql版本
5.0以上,且查詢優化器開啟了index_merge_union=on, 也就是變數optimizer_switch裡存在index_merge_union且為on。
3、負向條件查詢不能使用索引
負向條件有:
!=、<>、not in、not exists、not like等。例如下面SQL語句:
select * from doc where status != 1 and status != 2;複製程式碼
- 可以優化為 in 查詢:
select * from doc where status in (0,3,4);複製程式碼
4、聯合索引最左字首原則
如果在
(a,b,c)三個欄位上建立聯合索引,那麼他會自動建立a|(a,b)|(a,b,c)組索引。登入業務需求,SQL語句如下:
select uid, login_time from user where login_name=? andpasswd=?複製程式碼
- 可以建立
(login_name, passwd)的聯合索引。因為業務上幾乎沒有passwd的單條件查詢需求,而有很多login_name的單條件查詢需求,所以可以建立(login_name, passwd)的聯合索引,而不是(passwd, login_name)。
- 建立聯合索引的時候,區分度最高的欄位在最左邊
- 存在非等號和等號混合判斷條件時,在建立索引時,把等號條件的列前置。如
where a>? and b=?,那麼即使a的區分度更高,也必須把b放在索引的最前列。
- 最左字首查詢時,並不是指SQL語句的where順序要和聯合索引一致。
- 下面的 SQL 語句也可以命中
(login_name, passwd)這個聯合索引:
select uid, login_time from user where passwd=? andlogin_name=?複製程式碼
- 但還是建議
where後的順序和聯合索引一致,養成好習慣。
- 假如
index(a,b,c),where a=3 and b like 'abc%' and c=4,a能用,b能用,c不能用。
5、不能使用索引中範圍條件右邊的列(範圍列可以用到索引),範圍列之後列的索引全失效
- 範圍條件有:
<、<=、>、>=、between等。 - 索引最多用於一個範圍列,如果查詢條件中有兩個範圍列則無法全用到索引。
- 假如有聯合索引
(empno、title、fromdate),那麼下面的 SQL 中emp_no可以用到索引,而title和from_date則使用不到索引。
select * from employees.titles where emp_no < 10010' and title='Senior Engineer'and from_date between '1986-01-01' and '1986-12-31'複製程式碼
6、不要在索引列上面做任何操作(計算、函數),否則會導致索引失效而轉向全表掃描
- 例如下面的 SQL 語句,即使
date上建立了索引,也會全表掃描:
select * from doc where YEAR(create_time) <= '2016';複製程式碼
- 可優化為值計算,如下:
select * from doc where create_time <= '2016-01-01';複製程式碼
- 比如下面的 SQL 語句:
select * from order where date < = CURDATE();複製程式碼
- 可以優化為:
select * from order where date < = '2018-01-2412:00:00';複製程式碼
7、強制型別轉換會全表掃描
- 字串型別不加單引號會導致索引失效,因為mysql會自己做型別轉換,相當於在索引列上進行了操作。
- 如果
phone欄位是varchar型別,則下面的 SQL 不能命中索引。
select * from user where phone=13800001234複製程式碼
- 可以優化為:
select * from user where phone='13800001234';複製程式碼
8、更新十分頻繁、資料區分度不高的列不宜建立索引
更新會變更 B+ 樹,更新頻繁的欄位建立索引會大大降低資料庫效能。
「性別」這種區分度不大的屬性,建立索引是沒有什麼意義的,不能有效過濾資料,效能與全表掃描類似。
一般區分度在80%以上的時候就可以建立索引,區分度可以使用
count(distinct(列名))/count(*)來計算。
9、利用覆蓋索引來進行查詢操作,避免回表,減少select * 的使用
- 覆蓋索引:查詢的列和所建立的索引的列個數相同,欄位相同。
- 被查詢的列,資料能從索引中取得,而不用通過行定位符 row-locator 再到 row 上獲取,即「被查詢列要被所建的索引覆蓋」,這能夠加速查詢速度。
- 例如登入業務需求,SQL語句如下。
Select uid, login_time from user where login_name=? and passwd=?複製程式碼
- 可以建立
(login_name, passwd, login_time)的聯合索引,由於login_time已經建立在索引中了,被查詢的uid和login_time就不用去row上獲取資料了,從而加速查詢。
10、索引不會包含有NULL值的列
- 只要列中包含有NULL值都將不會被包含在索引中,複合索引中只要有一列含有
NULL值,那麼這一列對於此複合索引就是無效的。所以我們在資料庫設計時,儘量使用not null約束以及預設值。
11、is null, is not null無法使用索引
12、如果有order by、group by的場景,請注意利用索引的有序性
order by最後的欄位是組合索引的一部分,並且放在索引組合順序的最後,避免出現file_sort 的情況,影響查詢效能。
- 例如對於語句
where a=? and b=? order by c,可以建立聯合索引(a,b,c)。
- 如果索引中有範圍查詢,那麼索引有序性無法利用,如
WHERE a>10 ORDER BY b;,索引(a,b)無法排序。
13、使用短索引(字首索引)
對列進行索引,如果可能應該指定一個字首長度。例如,如果有一個
CHAR(255)的列,如果該列在前10個或20個字元內,可以做到既使得字首索引的區分度接近全列索引,那麼就不要對整個列進行索引。因為短索引不僅可以提高查詢速度而且可以節省磁碟空間和I/O操作,減少索引檔案的維護開銷。可以使用count(distinct leftIndex(列名, 索引長度))/count(*)來計算字首索引的區分度。但缺點是不能用於
ORDER BY和GROUP BY操作,也不能用於覆蓋索引。不過很多時候沒必要對全欄位建立索引,根據實際文字區分度決定索引長度即可。
14、利用延遲關聯或者子查詢優化超多分頁場景
- MySQL 並不是跳過
offset行,而是取offset+N行,然後返回放棄前 offset 行,返回 N 行,那當 offset 特別大的時候,效率就非常的低下,要麼控制返回的總頁數,要麼對超過特定閾值的頁數進行 SQL 改寫。 - 範例如下,先快速定位需要獲取的
id段,然後再關聯:
selecta.* from 表1 a,(select id from 表1 where 條件 limit100000,20 ) b where a.id=b.id;複製程式碼
15、如果明確知道只有一條結果返回,limit 1 能夠提高效率
- 比如如下 SQL 語句:
select * from user where login_name=?;複製程式碼
- 可以優化為:
select * from user where login_name=? limit 1複製程式碼
- 自己明確知道只有一條結果,但資料庫並不知道,明確告訴它,讓它主動停止遊標移動。
16、超過三個表最好不要 join
需要 join 的欄位,資料型別必須一致,多表關聯查詢時,保證被關聯的欄位需要有索引。
例如:
left join是由左邊決定的,左邊的資料一定都有,所以右邊是我們的關鍵點,建立索引要建右邊的。當然如果索引在左邊,可以用right join。
17、單表索引建議控制在5個以內
18、SQL 效能優化 explain 中的 type:至少要達到 range 級別,要求是 ref 級別,如果可以是 consts 最好
consts:單表中最多隻有一個匹配行(主鍵或者唯一索引),在優化階段即可讀取到資料。ref:使用普通的索引(Normal Index)。range:對索引進行範圍檢索。當
type=index時,索引物理檔案全掃,速度非常慢。
19、業務上具有唯一特性的欄位,即使是多個欄位的組合,也必須建成唯一索引
- 不要以為唯一索引影響了
insert速度,這個速度損耗可以忽略,但提高查詢速度是明顯的。另外,即使在應用層做了非常完善的校驗控制,只要沒有唯一索引,根據墨菲定律,必然有髒資料產生。
20.建立索引時避免以下錯誤觀念
- 索引越多越好,認為需要一個查詢就建一個索引。
- 寧缺勿濫,認為索引會消耗空間、嚴重拖慢更新和新增速度。
- 抵制惟一索引,認為業務的惟一性一律需要在應用層通過「先查後插」方式解決。
- 過早優化,在不瞭解系統的情況下就開始優化。
索引選擇性與字首索引
既然索引可以加快查詢速度,那麼是不是隻要是查詢語句需要,就建上索引?答案是否定的。因為索引雖然加快了查詢速度,但索引也是有代價的:索引檔案本身要消耗儲存空間,同時索引會加重插入、刪除和修改記錄時的負擔,另外,MySQL在執行時也要消耗資源維護索引,因此索引並不是越多越好。一般兩種情況下不建議建索引。
第一種情況是表記錄比較少,例如一兩千條甚至只有幾百條記錄的表,沒必要建索引,讓查詢做全表掃描就好了。至於多少條記錄才算多,這個個人有個人的看法,我個人的經驗是以2000作為分界線,記錄數不超過 2000可以考慮不建索引,超過2000條可以酌情考慮索引。
另一種不建議建索引的情況是索引的選擇性較低。所謂索引的選擇性(Selectivity),是指不重複的索引值(也叫基數,Cardinality)與表記錄數(#T)的比值:
Index Selectivity = Cardinality / #T複製程式碼
- 顯然選擇性的取值範圍為
(0, 1]``,選擇性越高的索引價值越大,這是由B+Tree的性質決定的。例如,employees.titles表,如果title`欄位經常被單獨查詢,是否需要建索引,我們看一下它的選擇性:
SELECT count(DISTINCT(title))/count(*) AS Selectivity FROM employees.titles; +-------------+| Selectivity | +-------------+| 0.0000 | +-------------+複製程式碼
title的選擇性不足0.0001(精確值為0.00001579),所以實在沒有什麼必要為其單獨建索引。有一種與索引選擇性有關的索引優化策略叫做字首索引,就是用列的字首代替整個列作為索引key,當字首長度合適時,可以做到既使得字首索引的選擇性接近全列索引,同時因為索引key變短而減少了索引檔案的大小和維護開銷。下面以
employees.employees表為例介紹字首索引的選擇和使用。假設employees表只有一個索引<emp_no>,那麼如果我們想按名字搜尋一個人,就只能全表掃描了:
EXPLAIN SELECT * FROM employees.employees WHERE first_name='Eric' AND last_name='Anido'; +----+-------------+-----------+------+---------------+------+---------+------+--------+-------------+| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-----------+------+---------------+------+---------+------+--------+-------------+| 1 | SIMPLE | employees | ALL | NULL | NULL | NULL | NULL | 300024 | Using where | +----+-------------+-----------+------+---------------+------+---------+------+--------+-------------+複製程式碼
- 如果頻繁按名字搜尋員工,這樣顯然效率很低,因此我們可以考慮建索引。有兩種選擇,建
<first_name>或<first_name, last_name>,看下兩個索引的選擇性:
SELECT count(DISTINCT(first_name))/count(*) AS Selectivity FROM employees.employees; +-------------+| Selectivity | +-------------+| 0.0042 | +-------------+SELECT count(DISTINCT(concat(first_name, last_name)))/count(*) AS Selectivity FROM employees.employees; +-------------+| Selectivity | +-------------+| 0.9313 | +-------------+複製程式碼
<first_name>顯然選擇性太低,`<first_name, last_name>選擇性很好,但是first_name和last_name加起來長度為30,有沒有兼顧長度和選擇性的辦法?可以考慮用first_name和last_name的前幾個字元建立索引,例如<first_name, left(last_name, 3)>,看看其選擇性:
SELECT count(DISTINCT(concat(first_name, left(last_name, 3))))/count(*) AS Selectivity FROM employees.employees; +-------------+ | Selectivity | +-------------+ | 0.7879 | +-------------+複製程式碼
- 選擇性還不錯,但離0.9313還是有點距離,那麼把last_name字首加到4:
SELECT count(DISTINCT(concat(first_name, left(last_name, 4))))/count(*) AS Selectivity FROM employees.employees; +-------------+| Selectivity | +-------------+| 0.9007 | +-------------+複製程式碼
- 這時選擇性已經很理想了,而這個索引的長度只有
18,比<first_name, last_name>短了接近一半,我們把這個字首索引建上:
ALTER TABLE employees.employees ADD INDEX `first_name_last_name4` (first_name, last_name(4));複製程式碼
- 此時再執行一遍按名字查詢,比較分析一下與建索引前的結果:
SHOW PROFILES; +----------+------------+---------------------------------------------------------------------------------+ | Query_ID | Duration | Query | +----------+------------+---------------------------------------------------------------------------------+ | 87 | 0.11941700 | SELECT * FROM employees.employees WHERE first_name='Eric' AND last_name='Anido' | | 90 | 0.00092400 | SELECT * FROM employees.employees WHERE first_name='Eric' AND last_name='Anido' | +----------+------------+---------------------------------------------------------------------------------+複製程式碼
效能的提升是顯著的,查詢速度提高了120多倍。
字首索引兼顧索引大小和查詢速度,但是其缺點是不能用於
ORDER BY和GROUP BY操作,也不能用於Covering index(即當索引本身包含查詢所需全部資料時,不再存取資料檔案本身)。
總結
- 本文主要講了索引優化的二十個原則,希望讀者喜歡。
本篇文章
腦圖和PDF檔案已經準備好,有需要的夥伴可以回覆關鍵詞索引優化獲取。
更多相關免費學習推薦:(視訊)
以上就是鐵汁,MySQL索引優化規則送你!!的詳細內容,更多請關注TW511.COM其它相關文章!