最全JVM與效能調優知識點總結,看看哪些是你還沒掌握的?
前言
JVM調優是每個高階程式設計師的必修課,在本章中,我會從發展過程以及核心價值來剖析JVM的體系結構。為了讓大家更好的理解JVM的工作機制,
我會在講解完執行時資料區之後,再通過一個類的載入過程到這個類最終在執行時資料區中的儲存來更進一步理解JVM的工作原理。最後,通過對記憶體的回收機制和垃圾回收演演算法的講解,引出到JVM的效能調優這一主題,在這個部分會著重講解垃圾回收演演算法以及常見的垃圾回收器的區別和使用場景。
JVM記憶體區域劃分
程式計數器(執行緒私有)
程式計數器(Program Counter Register),也有稱作為 PC 暫存器。儲存的是程式當 前執行的指令的地址(也可以說儲存下一條指令的所在儲存單元的地址),當 CPU 需要執 行指令時,需要從程式計數器中得到當前需要執行的指令所在儲存單元的地址,然後根據得 到的地址獲取到指令,在得到指令之後,程式計數器便自動加 1 或者根據轉移指標得到下 一條指令的地址,如此迴圈,直至執行完所有的指令。也就是說是用來指示執行哪條指令的。
java棧
Java 棧中存放的是一個個的棧幀,每個棧幀對應一個被呼叫的方法,在棧幀中包括局 部變數表、運算元棧、指向當前方法所屬的類的執行時常數池的參照、方法返回地址、額 外的附加資訊。當執行緒執行一個方法時,就會隨之建立一個對應的棧幀,並將建立的棧幀壓 棧。當方法執行完畢之後,便會將棧幀出棧。因此可知,執行緒當前執行的方法所對應的棧幀 必定位於 Java 棧的頂部。
本地方法棧
本地方法棧與 Java 棧的作用和原理非常相似。區別只不過是 Java 棧是為執行 Java 方法服務的,而本地方法棧則是為執行本地方法(Native Method)服務的。在 JVM 規 範中,並沒有對本地方發展的具體實現方法以及資料結構作強制規定,虛擬機器器可以自由實現 它。在 HotSopt 虛擬機器器中直接就把本地方法棧和 Java 棧合二為一。
堆
Java 中的堆是用來儲存物件本身的以及陣列(當然,陣列參照是存放在 Java 棧中的), 堆是被所有執行緒共用的,在 JVM 中只有一個堆。所有物件範例以及陣列都要在堆上分配內 存,單隨著 JIT 發展,棧上分配,標量替換優化技術,在堆上分配變得不那麼到絕對,只能 在 server 模式下才能啟用逃逸分析。
方法區
方法區中,儲存了每個類的資訊(包括類的名稱、方法資訊、欄位資訊)、靜態變 量、常數以及編譯器編譯後的程式碼等。 在 Class 檔案中除了類的欄位、方法、介面等描述資訊外,還有一項資訊是常數池, 用來儲存編譯期間生成的字面量和符號參照。
直接記憶體
NIO,使用 native 函數庫直接分配堆外記憶體,不經過 JVM 記憶體直接存取系統實體記憶體的類 ——DirectBuffer。 DirectBuffer 類繼承自 ByteBuffer,但和普通的 ByteBuffer 不同, 普通的 ByteBuffer 仍在 JVM 堆上分配記憶體,其最大記憶體受到最大堆記憶體的限制;而 DirectBuffer 直接分配在實體記憶體中,並不佔用堆空間,其可申請的最大記憶體受作業系統 限制
JVM執行子系統
Class 類檔案結構
各種不同平臺的虛擬機器器與所有平臺都統一使用的程式儲存格式——位元組碼(ByteCode)是 構成平臺無關性的基石,也是語言無關性的基礎。Java 虛擬機器器不和包括 Java 在內的任何語 言繫結,它只與「Class 檔案」這種特定的二進位制檔案格式所關聯,Class 檔案中包含了 Java 虛擬機器器指令集和符號表以及若干其他輔助資訊。
Java 跨平臺的基礎
各種不同平臺的虛擬機器器與所有平臺都統一使用的程式儲存格式——位元組碼(ByteCode)是 構成平臺無關性的基石,也是語言無關性的基礎。Java 虛擬機器器不和包括 Java 在內的任何語 言繫結,它只與「Class 檔案」這種特定的二進位制檔案格式所關聯,Class 檔案中包含了 Java 虛擬機器器指令集和符號表以及若干其他輔助資訊。
Class 類的本質
任何一個 Class 檔案都對應著唯一一個類或介面的定義資訊,但反過來說,Class 檔案實際 上它並不一定以磁碟檔案的形式存在。 Class 檔案是一組以 8 位位元組為基礎單位的二進位制流。
位元組碼指令
Java 虛擬機器器的指令由一個位元組長度的、代表著某種特定操作含義的數位(稱為操作碼, Opcode)以及跟隨其後的零至多個代表此操作所需引數(稱為運算元,Operands)而構成。 由於限制了 Java 虛擬機器器操作碼的長度為一個位元組(即 0~255),這意味著指令集的操作 碼總數不可能超過 256 條。
大多數的指令都包含了其操作所對應的資料型別資訊。例如: iload指令用於從區域性變數表中載入int型的資料到運算元棧中,而fload指令載入的則是float 型別的資料。
大部分的指令都沒有支援整數型別 byte、char 和 short,甚至沒有任何指令支援 boolean 類 型。大多數對於 boolean、byte、short 和 char 型別資料的操作,實際上都是使用相應的 int 型別作為運算型別
類載入機制
類從被載入到虛擬機器器記憶體中開始,到解除安裝出記憶體為止,它的整個生命週期包括:載入 (Loading)、驗證(Verification)、準備(Preparation)、解析(Resolution)、初始化 (Initialization)、使用(Using)和解除安裝(Unloading)7 個階段。其中驗證、準備、解析 3 個部分統稱為連線(Linking) 於初始化階段,虛擬機器器規範則是嚴格規定了有且只有 5 種情況必須立即對類進行「初始化」 (而載入、驗證、準備自然需要在此之前開始)
垃圾回收器和記憶體分配策略
Java 中是值傳遞還是參照傳遞?
在執行棧中,基本型別和參照的處理是一樣的,都是傳 值,所以,如果是傳參照的方法呼叫,也同時可以理解為「傳參照值」的傳值呼叫,即參照的 處理跟基本型別是完全一樣的。但是當進入被呼叫方法時,被傳遞的這個參照的值,被程式 解釋(或者查詢)到堆中的物件,這個時候才對應到真正的物件。如果此時進行修改,修 改的是參照對應的物件,而不是參照本身,即:修改的是堆中的資料。所以這個修改是可以 保持的了!
物件,從某種意義上說,是由基本型別組成的。可以把一個物件看作為一棵樹,物件的屬性 如果還是物件,則還是一顆樹(即非葉子節點),基本型別則為樹的葉子節點。程式引數傳 遞時,被傳遞的值本身都是不能進行修改的,但是,如果這個值是一個非葉子節點(即一個 物件參照),則可以修改這個節點下面的所有內容。
參照型別
物件參照型別分為強參照、軟參照、弱參照和虛參照。 強參照:就是我們一般宣告物件是時虛擬機器器生成的參照,強參照環境下,垃圾回收時需要嚴 格判斷當前物件是否被強參照,如果被強參照,則不會被垃圾回收
軟參照
軟參照一般被做為快取來使用。與強參照的區別是,軟參照在垃圾回收時,虛擬機器器 會根據當前系統的剩餘記憶體來決定是否對軟參照進行回收。如果剩餘記憶體比較緊張,則虛擬 機會回收軟參照所參照的空間;如果剩餘記憶體相對富裕,則不會進行回收。換句話說,虛擬 機在發生 OutOfMemory 時,肯定是沒有軟參照存在的。
弱參照
弱參照與軟參照類似,都是作為快取來使用。但與軟參照不同,弱參照在進行垃圾 回收時,是一定會被回收掉的,因此其生命週期只存在於一個垃圾回收週期內。 強參照不用說,我們系統一般在使用時都是用的強參照。而「軟參照」和「弱參照」比較少見。 他們一般被作為快取使用,而且一般是在記憶體大小比較受限的情況下做為快取。因為如果內 存足夠大的話,可以直接使用強參照作為快取即可,同時可控性更高。因而,他們常見的是 被使用在桌面應用系統的快取。
基本垃圾回收演演算法
參照計數(Reference Counting):
比較古老的回收演演算法。原理是此物件有一個參照,即增加一個計數,刪除一個參照則減少一 個計數。垃圾回收時,只用收集計數為 0 的物件。此演演算法最致命的是無法處理迴圈參照的 問題。
可達性分析清理
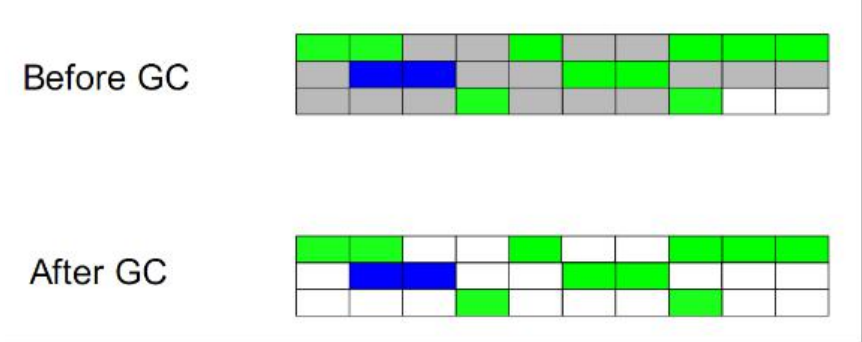
標記-清除(Mark-Sweep):
此演演算法執行分兩階段。第一階段從參照根節點開始標記所有被 參照的物件,第二階段遍歷整個堆,把未標記的物件清除。此演演算法需要暫停整個應用,同時, 會產生記憶體碎片
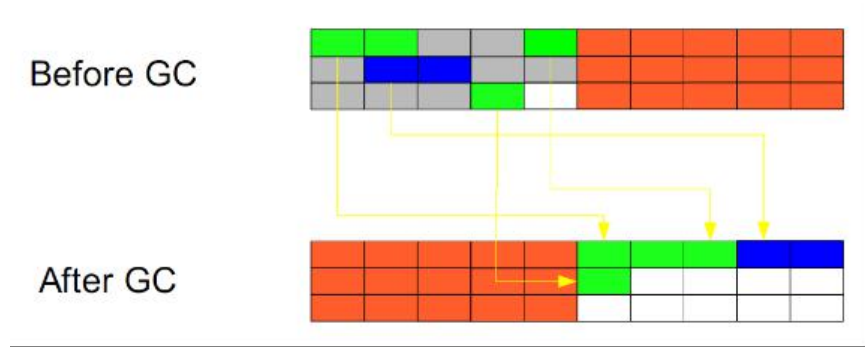
複製(Copying):
此演演算法把記憶體空間劃為兩個相等的區域,每次只使用其中一個區域。垃 圾回收時,遍歷當前使用區域,把正在使用中的物件複製到另外一個區域中。次演演算法每次只 處理正在使用中的物件,因此複製成本比較小,同時複製過去以後還能進行相應的記憶體整理, 不會出現「碎片」問題。當然,此演演算法的缺點也是很明顯的,就是需要兩倍記憶體空間。

標記-整理(Mark-Compact):
此演演算法結合了「標記-清除」和「複製」兩個演演算法的優點。也是分 兩階段,第一階段從根節點開始標記所有被參照物件,第二階段遍歷整個堆,清除標記對 象,並未標記物件並且把存活物件「壓縮」到堆的其中一塊,按順序排放。此演演算法避免了「標 記-清除」的碎片問題,同時也避免了「複製」演演算法的空間問題。
效能優化
一個 web 應用不是一個孤立的個體,它是一個系統的部分,系統中的每一部分都會影響整 個系統的效能
常用的效能評價/測試指標
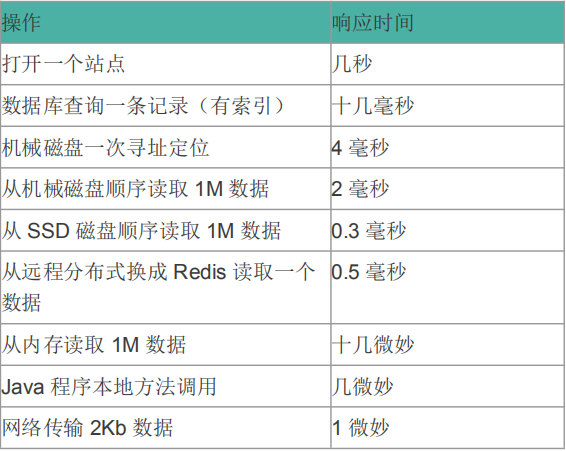
響應時間
提交請求和返回該請求的響應之間使用的時間,一般比較關注平均響應時間。 常用操作的響應時間列表:
並行數
同一時刻,對伺服器有實際互動的請求數。 和網站線上使用者數的關聯:1000 個同時線上使用者數,可以估計並行數在 5%到 15%之間, 也就是同時並行數在 50~150 之間。
吞吐量
對單位時間內完成的工作量(請求)的量度
關係
系統吞吐量和系統並行數以及響應時間的關係: 理解為高速公路的通行狀況: 吞吐量是每天通過收費站的車輛數目(可以換算成收費站收取的高速費), 並行數是高速公路上的正在行駛的車輛數目, 響應時間是車速。 車輛很少時,車速很快。但是收到的高速費也相應較少;隨著高速公路上車輛數目的增多, 車速略受影響,但是收到的高速費增加很快; 隨著車輛的繼續增加,車速變得越來越慢,高速公路越來越堵,收費不增反降; 如果車流量繼續增加,超過某個極限後,任務偶然因素都會導致高速全部癱瘓,車走不動, 當然後也收不著,而高速公路成了停車場(資源耗盡)。
常用的效能優化手段
避免過早優化
不應該把大量的時間耗費在小的效能改進上,過早考慮優化是所有噩夢的根源。 所以,我們應該編寫清晰,直接,易讀和易理解的程式碼,真正的優化應該留到以後,等到性 能分析表明優化措施有巨大的收益時再進行。
進行系統效能測試
所有的效能調優,都有應該建立在效能測試的基礎上,直覺很重要,但是要用資料說話,可 以推測,但是要通過測試求證。
尋找系統瓶頸,分而治之,逐步優化
效能測試後,對整個請求經歷的各個環節進行分析,排查出現效能瓶頸的地方,定位問題, 分析影響效能的的主要因素是什麼?記憶體、磁碟 IO、網路、CPU,還是程式碼問題?架構設 計不足?或者確實是系統資源不足?
##小結
由於文章篇幅原因,更多的細節知識點已經寫不完了,我全部總結在下面這份【JVM與效能調優知識點】裡面了,各位需要的話可以關注我的公眾號前程有光免費領取
最後
歡迎關注公眾號:前程有光,領取這份【JVM與效能調優知識點】+一線大廠Java面試題總結+各知識點學習思維導+一份300頁pdf檔案的Java核心知識點總結!