去噪論文 Attention-Guided CNN for Image Denoising
Attention-Guided CNN for Image Denoising
發表期刊 : Neural Networks 124 (2020) 117–129 https://doi.org/10.1016/j.neunet.2019.12.024
Paper and Code Sci-Hub 實時更新 : https://tool.yovisun.com/scihub/
Abstract: 提出一種注意力導向的去噪折積神經網路(ADNet),主要包括稀疏塊(SB),特徵增強塊(FEB),注意力塊(AB)和重構塊(RB)影象降噪。
SB通過使用膨脹和普通折積來去除噪聲,從而在效能和效率之間進行權衡。
FEB通過很長的路徑整合了全域性和區域性特徵資訊,以增強去噪模型的表達能力。
AB用於精細提取隱藏在複雜背景中的噪聲資訊,對於複雜的噪點影象(真實噪點影象)和繫結去噪非常有效。此外,FEB與AB整合在一起,可提高效率並降低訓練降噪模型的複雜度。
RB旨在通過獲得的噪聲對映和給定的噪聲影象來構造清晰影象。
ADNet在三個任務(即合成和真實的噪點影象以及盲降噪)中均表現出色。
Contributions:(1)提出了由擴張折積和普通折積組成的SB,用於減小深度以提高去噪效能和效率。
(2)FEB使用長路徑融合來自淺層和深層的資訊,增強去噪模型的表達能力。
(3)AB用於從給定的噪點影象中深度挖掘隱藏在複雜背景中的噪聲資訊,例如真實的噪點影象和盲降噪。
(4)FEB與AB整合在一起,可以提高效率並降低訓練降噪模型的複雜度。
(5)在六個基準資料集上,ADNet在合成和真實噪點影象以及盲降噪方面均優於最新技術(2020)。
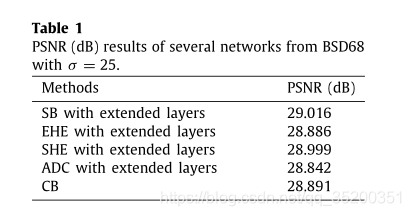
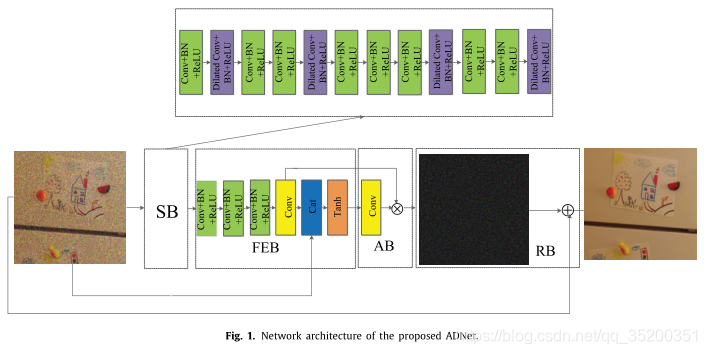
As shown in Fig. 1,17層ADNet由四個塊組成,分別是SB,FEB,AB和RB。 12層稀疏塊SB用於增強影象去噪的效能和效率。
loss function:
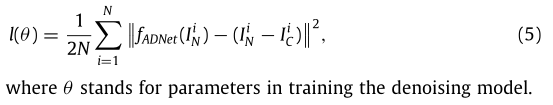
SB:
12層SB包括兩種型別:dilated Conv+BN+ReLU和Conv+BN+ReLU。dilated Conv+BN+ReLU表示擴張率為2的折積,BN 和啟用函數ReLU 是相連的。另一種是 Conv,BN和ReLU 相連。dilated Conv+BN+ReLU位於SB的第二、第五、第九和第十二層(圖1中紫色),這些層可以視為高能點。Conv+BN+ReLU在第一、第三、第四、第六、第七、第八、第十和第十一層(圖1中綠色),為低能點。1–12層的折積濾波器大小為3 × 3。第一層的輸入是c:輸入噪聲影象的通道數。2–12層的輸入和輸出為64。幾個高能量點和幾個低能量點的組合可以認為是稀疏性。稀疏塊的實現轉換為公式 6,D代表擴張折積的函數。R和B分別代表ReLU和BN。CBR是Conv+BN+ReLU的函數。根據前面的描述,用下面的等式來表示SB。
O
S
B
=
R
(
B
(
D
(
C
B
R
(
C
B
R
(
R
(
B
(
D
(
C
B
R
(
C
B
R
(
C
B
R
(
R
(
B
(
D
(
C
B
R
(
C
B
R
(
R
(
B
(
D
(
C
B
R
(
I
N
)
)
)
)
)
)
)
)
)
)
)
)
)
)
)
)
)
)
)
)
(
6
)
O^{SB}= R(B(D(CBR(CBR(R(B(D(CBR(CBR(CBR(R(B(D(CBR(CBR(R(B(D (CBR(I^N)))))))))))))))))))) (6)
OSB=R(B(D(CBR(CBR(R(B(D(CBR(CBR(CBR(R(B(D(CBR(CBR(R(B(D(CBR(IN))))))))))))))))))))(6)
FEB:(深層網路可能會受到淺層的弱化影響)
FEB通過一條長路徑充分利用全域性和區域性特徵來挖掘更魯棒的特徵,這與SB在處理給定噪聲影象方面是互補的。4層FEB由三種型別組成:Conv+BN+ReLU、Conv和Tanh,其中Tanh是activate function。Conv+BN+ReLU在13–15層,filter size=64×3×3×64。Conv用於第16層,ilter size=64×3×3×c。第17層使用concatenation operation來融合輸入的噪聲影象和第16層的輸出,以增強去噪模型的表示能力。因此,最終輸出尺寸為64×3×3× 2c。此外,Tanh用於將獲得的特徵轉換成非線性。該過程如公式7 描述解釋。
O
F
E
B
=
T
(
C
a
t
(
C
(
C
B
R
(
C
B
R
(
C
B
R
(
O
S
B
)
)
)
)
,
I
N
)
)
(
7
)
O^{FEB}= T(Cat(C(CBR(CBR(CBR(O^{SB})))), I^N)) (7)
OFEB=T(Cat(C(CBR(CBR(CBR(OSB)))),IN))(7)其中C、Cat和T分別是折積、級聯和Tanh的函數。在圖1中,Cat用於表示連線的功能。此外,OFEB也用於AB。
AB:(複雜的背景很容易隱藏影象和視訊應用的特徵)
AB利用當前階段指導前一階段學習噪聲資訊,對於未知噪聲影象,即盲去噪和真實噪聲影象非常有用。1層AB僅包括一個Conv,其大小為2c × 1 × 1 × c,其中c是給定損壞影象的通道數。AB利用以下兩個步驟來實現注意機制。第一步使用來自第十七層的大小為1 × 1的折積將獲得的特徵壓縮成向量作為調整前一階段的權重,這也可以提高去噪效率。第二步利用獲得的權重乘以第十六層的輸出,以提取更顯著的噪聲特徵。其過程可以轉換為以下公式。
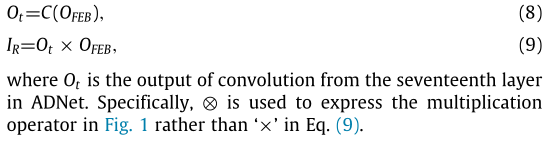
Training datasets:
訓練資料集使用伯克利分割資料集(BSD)的400幅大小為180 × 180的影象和滑鐵盧勘探資料庫的3,859幅影象來訓練高斯合成去噪模型。影象的不同區域包含不同的詳細資訊,因此將訓練噪聲影象分成大小為50 × 50的1,348,480個小塊,有助於促進更魯棒的特徵並提高訓練去噪模型的效率;缺點是噪音在現實世界中是變化的和複雜的。基於這個原因,使用來自基準資料集(徐,李,樑,張,&張,2018)的100幅尺寸為512 × 512的真實噪聲影象來訓練真實噪聲去噪模型。為了加快訓練速度,100幅真實噪聲影象也被分成211,600個大小為50 × 50的小塊。此外,上面的每個訓練影象從八種方式中隨機旋轉一種方式:原始影象,90♀,180♀,270♀,原始影象自身水平翻轉,90♀,自身水平翻轉,180♀,自身水平翻轉,270♀,自身水平翻轉。
測試資料集:
通過6個資料集,即BSD68,Set12,CBSD68 ,Kodak24,McMaster和cc ,分別由68,12,68,24,18和15幅影象組成,來評估ADNet的去噪效能。BSD68和Set12是灰色影象。其他資料集是彩色影象。BSD68和CBSD68的場景是一樣的。真實噪聲的cc資料集是從三個不同的相機採集的,每個真實噪聲影象的大小是512 × 512。