強化學習經典入門教學
文章目錄
Introduction of Reinforcement Learning
Deep Reinforcement Learning
深度強化學習等價於強化學習加上深度學習。

什麼是強化學習
如下圖所示,有一個Agent,也就是機器,然後它將自己觀察到的場景作為輸入,然後去執行某個行為去改變這種場景,比如他觀察到一杯水,然後他做了一個行為,就是打翻水杯,然後會得到一個reward,也就是獎勵,如果為正,說明它做得好,如果為負,就說明它那樣做不對。強化學習是機器與環境做互動!!
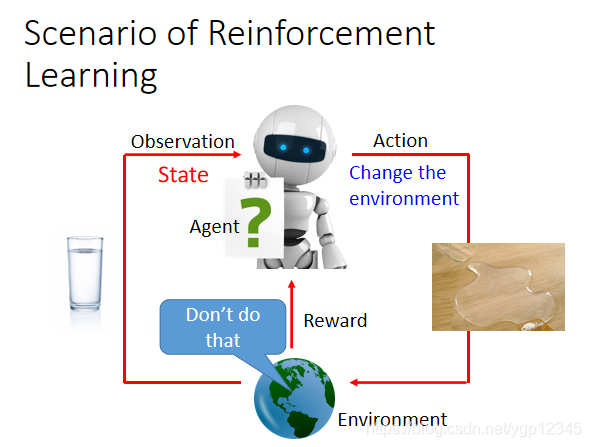
Agent可以學到採取哪些行動可以最大化獎勵!!
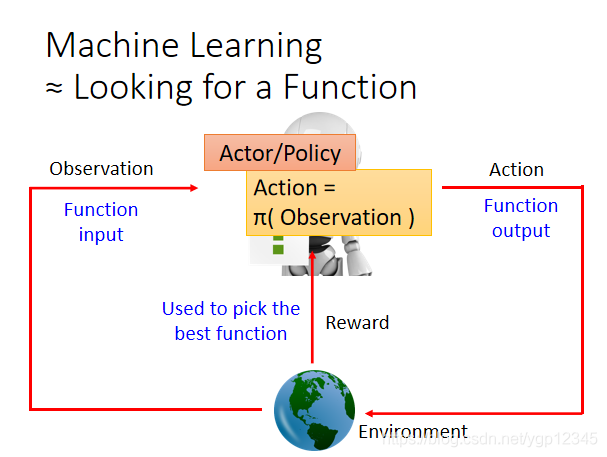
如下圖,Agent去學習採取哪些行動可以看成一個函數。假設這個函數是Π,然後Agent將觀察到的場景作為輸入傳到Π裡,並且做出預測,下一步該做什麼行動,然後會反饋一個reward,然後選取reward最大的函數。
強化學習的應用
下棋
下圍棋可以用強化學習,棋盤就是agent觀察到的,他下一步會做出下哪裡的決定,然後每下一步會得到一個reward。
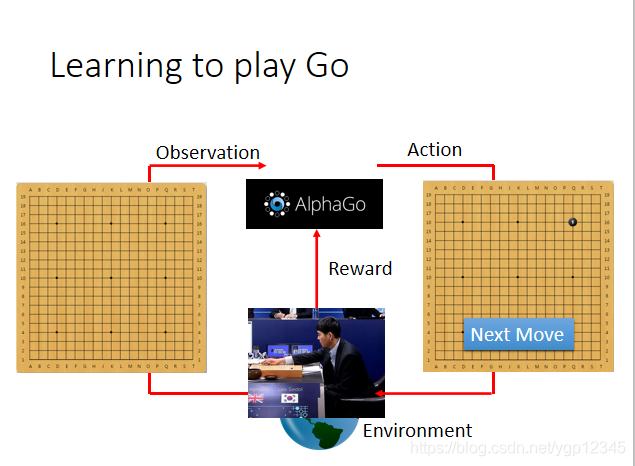
但是,下圍棋的時候是關乎勝負的,勝負與下的每一步都有關係,也就是說大多數的時候reward都是0,只有win的時候reward是1,loss的時候reward是-1.
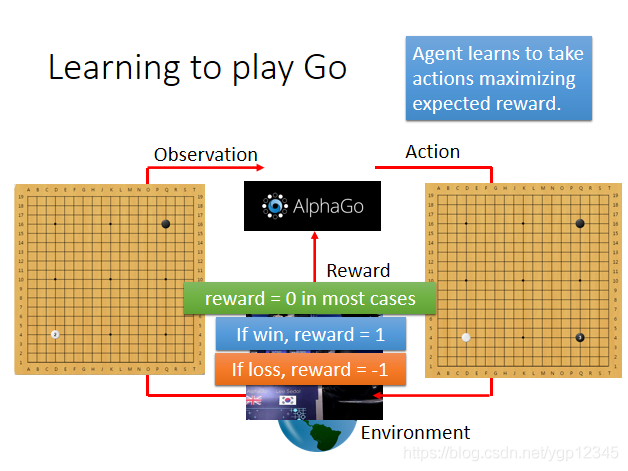
我們來對比一下監督學習和強化學習在下棋的時候的區別:監督學習就像有一個老師,要教機器一些基本知識,它才會下棋,而強化學習是根據經驗下棋,機器從每次落子能否勝利中學會如何去下棋。Alpha Go是先用監督學習讓機器具備一定的知識基礎,然後再利用強化學習讓機器自己去學,通常情況下是讓兩臺機器互相下棋。

聊天機器人
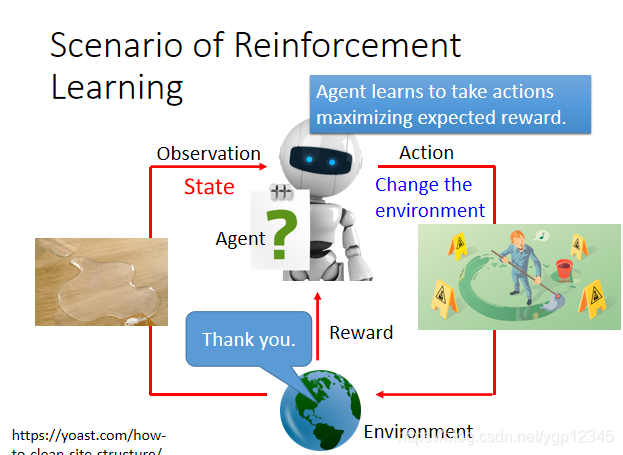
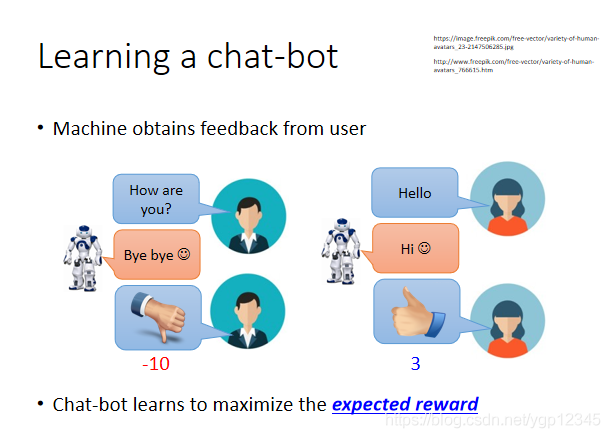
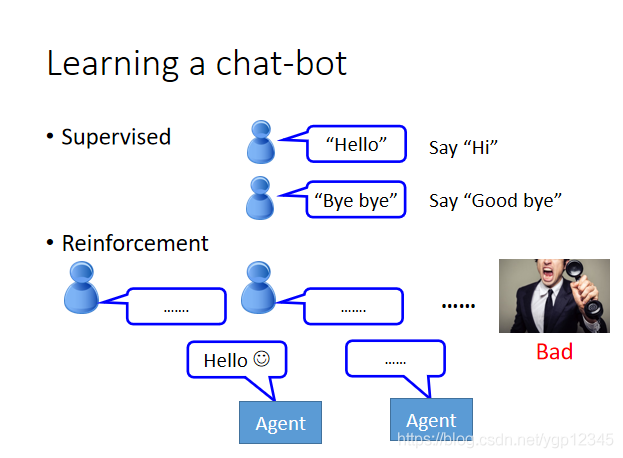
如下圖場景,我們訓練一個聊天機器人,比如人類說你好嗎,然後機器說拜拜,我就給他一個負的reward,反之是正的。
如果我們完全用人去和機器訓練,那不累死了?所以我們讓兩個機器自己聊。
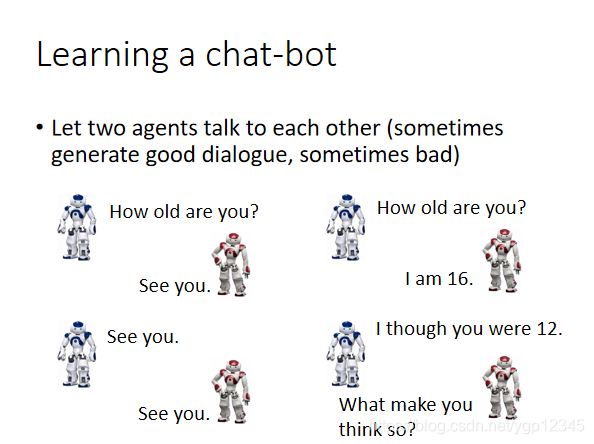
通過這種方式,我們能產生一些對話,使用一些預先定義的規則去評價一個對話的好壞。

對比一下監督學習的聊天機器人,你要告訴利用監督學習的機器人遇到不同的聊天場景應該怎麼回答,而強化學習都是自己利用經驗去學習。
然後強化學習還有如下的應用:

Example: Playing Video Game
我們來詳細說一下利用強化學習打遊戲的案例:
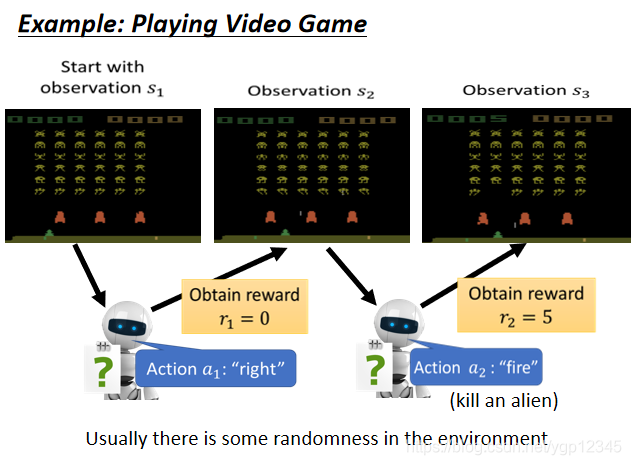
機器像人類玩家一樣去打遊戲,機器觀察的就是整個遊戲畫面,然後靠它自己決定下一步該怎麼做。

下面這個遊戲,擊殺了外星人可以獲得獎勵,然後整個action就只有三個,向左移,向右移,以及開火。遊戲結束的標誌是所有外星人被消滅或者是你的飛船被外星人擊毀。

機器先觀察畫面,然後做出了一個action,向右移動,這個action的獎勵是0,然後機器又觀察畫面,做出了開火的action,然後觀察畫面,發現有外星人被擊落,然後獲得reward。
從遊戲開始到遊戲結束被稱為一個episode,那麼機器就是要找到每一個episode中,誰的reward總和最大,然後總和最大的reward的episode所包含的各個action是比較好的!
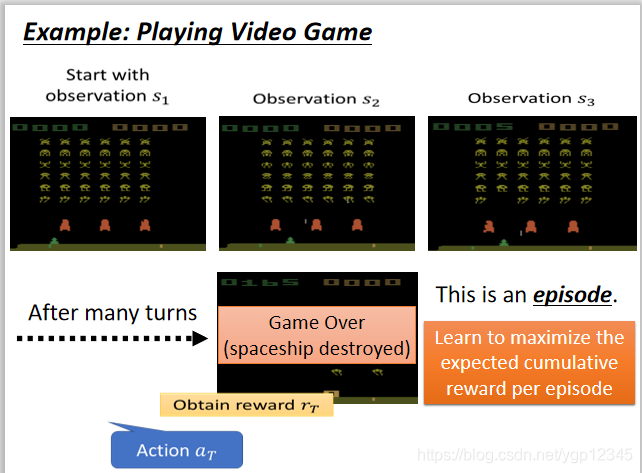
強化學習具有以下特點,獎勵延遲,在剛剛那個遊戲中,只有開火可能獲得獎勵,但是開火之前的移動也十分重要。在下圍棋的時候,可能犧牲當前的reward來獲得更長久的reward。Agent的行為影響接下來的事情,它具有探索精神,沒走過的路它都想走一遍,萬一能得到好的結果呢?

Alpha Go是個大雜燴,以下方式都用上了。
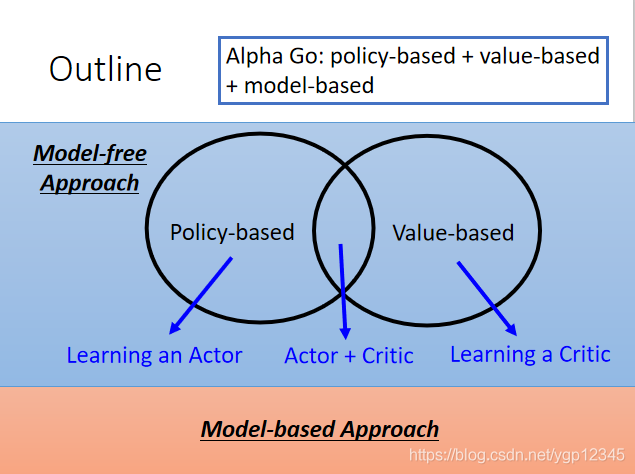
基於策略的方式(Policy-based Approach)-Learning an Actor

我們要如何尋找一個actor?也就是一個根據場景做出行為的函數。第一步,當然是選擇神經網路作為這個actor
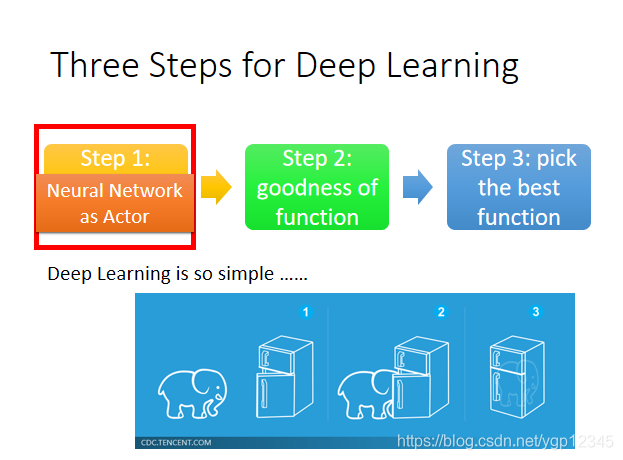
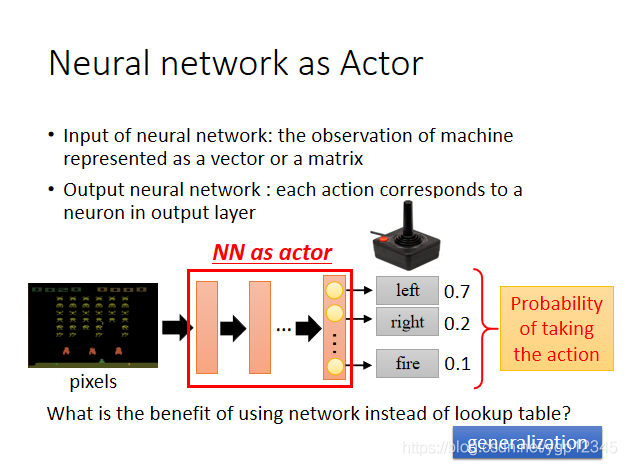
神經網路的輸入是機器觀察到的場景轉化的向量或者矩陣,輸出是每一個行為的概率。像這種彩圖我們一般用CNN,然後取代了最早的查表方式,以前的actor是table,然後遇到某張圖片就去table裡找對應的行為,用在下棋裡還可能窮舉,如果在自動駕駛領域,這圖片是無法用表存完的。可能你之前沒有給神經網路看過某張圖,但是它還是能得出比較靠譜的結果,所以他具有generalization的特性。
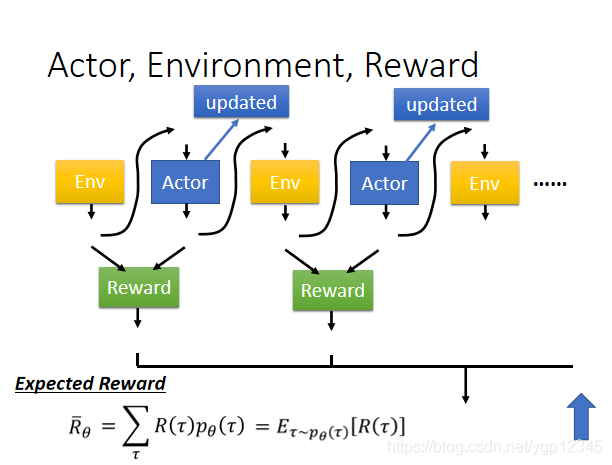
下面的這圖看起來不就是一個巨大的network嗎?然後環境和reward是無法改變的,就相當於下棋的時候機器無法控制對手的操作,機器也無法改變獎勵制度,唯一能改變的就是自己的引數,去適應環境,來使獎勵最大化。
第二步我們要找衡量這個function好壞的函數。
回顧一下之前的神經網路定義的loss,因為有目標值,所以他是監督學習,然後loss用的交叉熵。
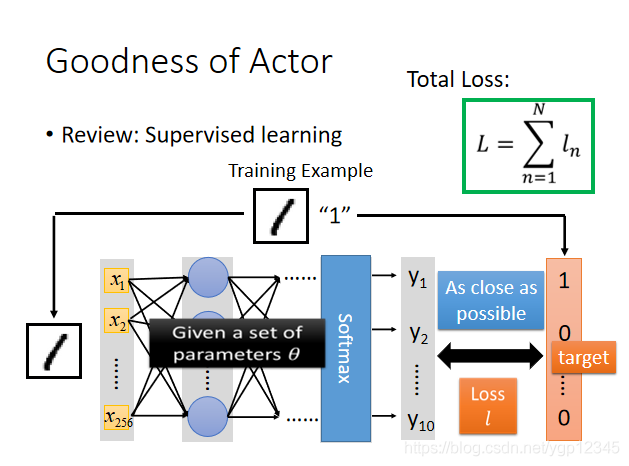
那麼這個Actor的損失函數該怎麼定義呢?給定一個actor,記為Π,然後下表θ代表該神經網路的引數,然後input的s就是機器所看到的場景,然後讓機器實際去玩一下這個遊戲,然後我們要求總的Total reward最大,我們就要將所有的r加起來。但由於即使是使用相同的actor,每一次的總的獎勵也可能不同,於是我們就求總的獎勵的期望即可。

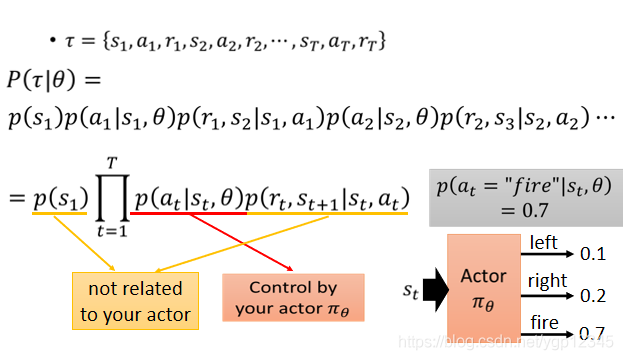
┏是場景,行動,獎勵所組成的向量,如下圖所示,比如說玩遊戲,一個┏就代表了機器看到了第一個畫面,做了某個行為,然後得到什麼獎勵,然後看到第二個畫面,做了某個行為,然後得到什麼獎勵,以此類推,迴圈往復,直到遊戲結束。然後每一個┏都有可能被經歷。當你選擇了某一個actor,也就是選擇了某一個神經網路,那麼會使某一些┏容易出現,某一些不容易出現。那麼Rθ的期望就等於每一次遊戲過程┏的獎勵R與該過程┏出現的機率的乘積之和。那麼窮舉所有的┏顯然不可能,那麼我們就玩N場遊戲,相當於N個訓練資料。

經過上面的演算,我找到了衡量一個actor好壞的式子,那麼下一步,我要將這個式子的結果求最大。
求最大你會想到梯度上升的求法,這裡的梯度上升是策略梯度的一部分。

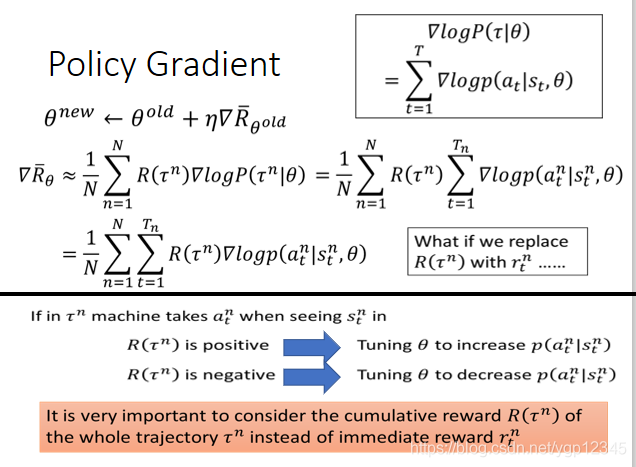
那麼對Rθ期望求微分具體應該怎麼做呢?如下圖,R(┏)肯定不可微,但是沒關係,它的表示式裡沒有θ,所以我只需對P(┏|θ)求導數,然後我們要對其做一下變換,巧用log!!然後畫紅框的兩部分之前推導過可以化為1/N,然後整個表示式就可以化為一個近似的表示式。使用Πθ這個神經網路去玩N次遊戲,可以得到N個┏

下面我們來看看P(┏|θ)開啟是什麼,畫黃線的部分與你的actor無關,取決於外部環境,也就是遊戲,然後紅線部分與你的actor有關。
利用上述開啟的結論,然後我們利用對數的性質化簡,如下圖所示:然後我們對θ求導!忽視與θ無關的項。然後得出來一個等式。

然後我們將Rθ得期望求導之後得算式寫出來,如下圖:其中,log裡面的那個p所代表的意思就是當前第n回玩遊戲時,t時刻機器所看到的畫面的情況下做出a行為的概率,R(┏n)是指第n回完遊戲時的總的獎勵,然後利用上述得到的結果進行梯度上升。注意:如果我將R(┏n)換成rtn,也就是將第n回玩遊戲的總的獎勵換成第n回玩遊戲時t時刻的獎勵,那麼會發生什麼後果??如果在剛剛那個射擊遊戲裡,只有開火能得到獎勵,那麼就會導致機器只會開火。
如果在某一次玩遊戲時,機器在看到某個場景時,採取了一個行動,然後總的獎勵是正的,那麼機器就會自己去增加看到這個場景下做出該行動的概率。
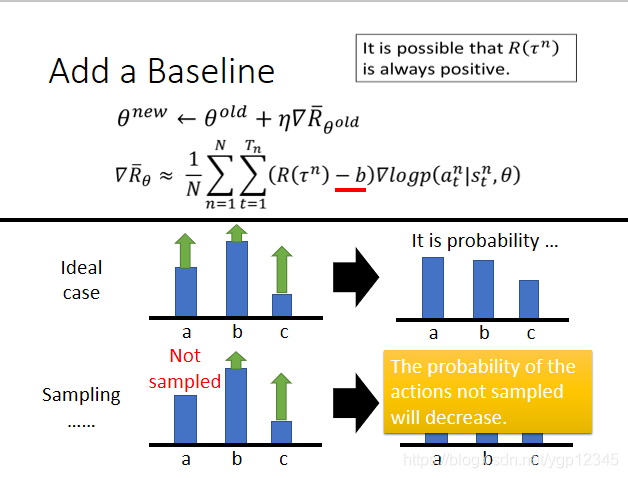
那麼這裡有一個問題,我們看下圖,ideal case的第一張圖,a和c的會使總的獎勵變多,那麼機器會傾向於執行a和c的操作,所以a和c的執行機率就變大了,相對的b的機率就減少了。然後我們再看看sampling那一行,b和c可能使我的總的獎勵一直是正的,那麼機器根本就不知道a的情況,萬一a的操作更好呢??機器只會去學更positive的,b和c的機率也會越來越大,a只會越來越小。這時,我們需要引入一個baseline,如下圖的b,我們將總的獎勵減去一個b值,也就是某一步的獎勵一定要達到某一個標準我才能說它好,否則就是不好。
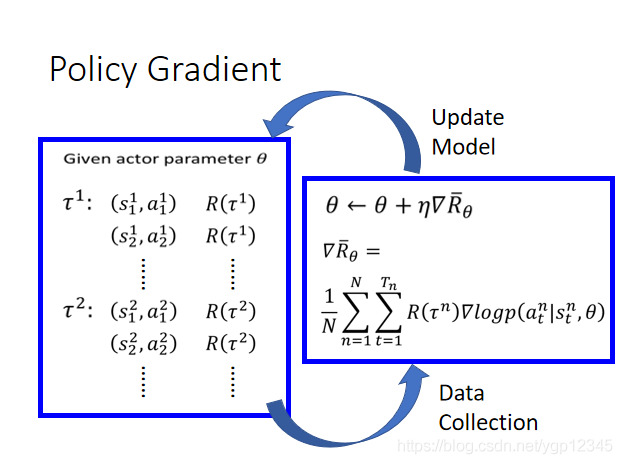
下面我們來看看更新model的過程,先是給了一個actor,然後給actor一個┏,然後算出獎勵總和,然後用梯度上升,更新θ,然後再將另一個┏傳給actor,迴圈往復執行。
那麼到底如何理解log這一項呢,我們暫且把強化學習看成一個分類問題,如下圖所示,向左,向右,開火就是三個類別,然後下圖給了一個目標值的向量(1,0,0),然後做交叉熵,然後將minimize去掉負號變成求maximize,現在我只有left的目標值是1,所以maximize變成logy1,然後它等於logP(「left」|s),然後我們利用梯度上升找最大。
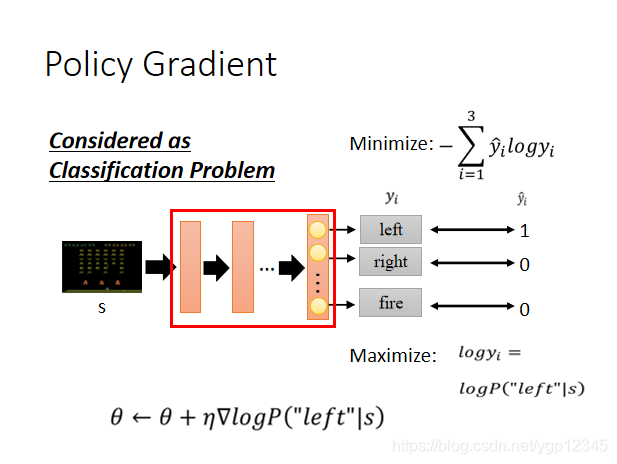
我們暫時先不看R的總和,然後我們會發現這就是一個分類問題,將s場景傳入,然後預測是向左向右還是開火。
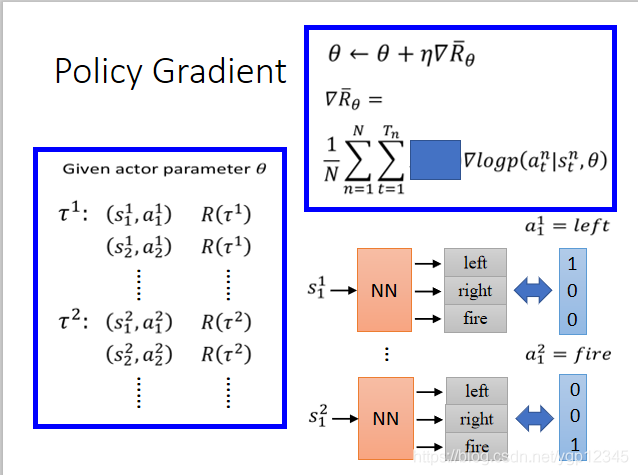
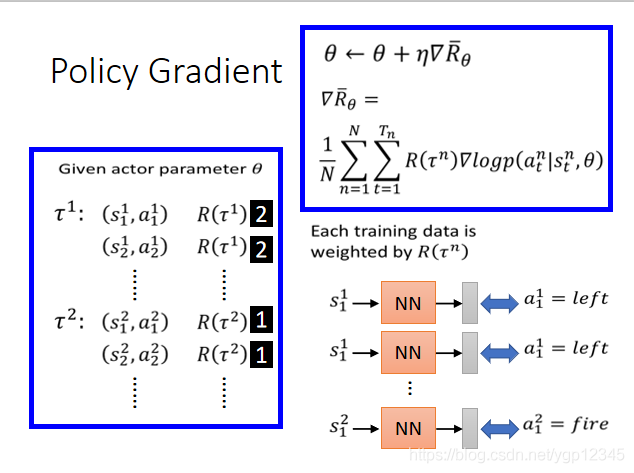
現在我們加上R(┏),每一個訓練資料被這一項賦予了權重。比如說第一回玩遊戲的R(┏)=2,那麼就相當於傳入s,然後預測action為向左執行了兩次。
基於價值的方式(Value-based Approach)Learning a Critic

一個Critic無法決定Action,給定一個actor,記為Π,critic可以評估這個actor的好壞。

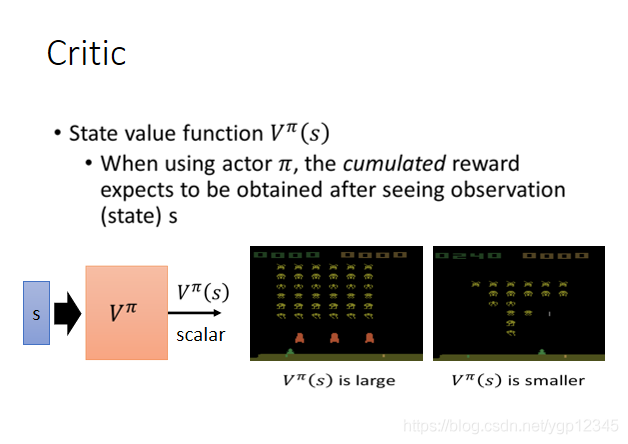
我們定義一個狀態價值函數,記為VΠ,然後傳一個畫面s給這個函數,意思就是當使用Π作為actor時,看到畫面s直到遊戲結束所獲得的獎勵期望是多少,也就是從看到s一直到遊戲結束這段期間總的獎勵。如下圖,先是看到一張外星人很多的圖,然後V就很大,因為畫面裡還有很多外星人可以擊殺,然後第二張圖裡外星人很少,那麼從機器看到這張圖一直到遊戲結束時,V就很小。
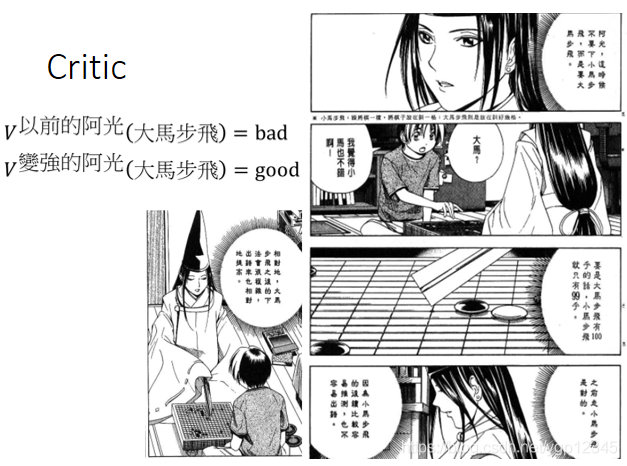
如下圖漫畫,看到同一張圖,如果actor越好,那麼得到的V就越大。
如何去評估V(S)
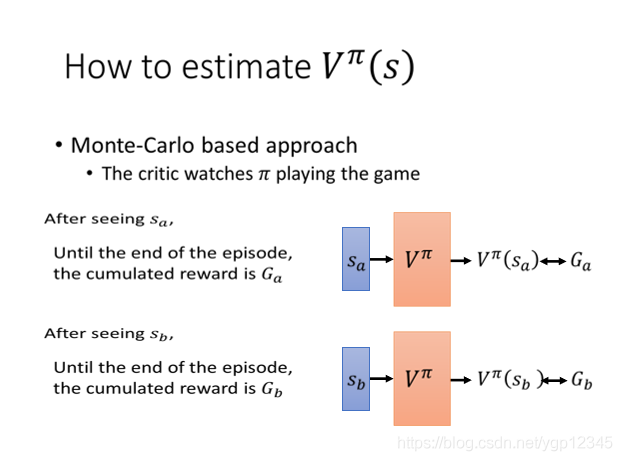
第一種比較直觀的方式就是蒙特卡洛方法,讓critic去觀察Π玩遊戲,當看到畫面sa時,計算出到遊戲結束時的獎勵之和Ga,然後與VΠ所預測出的VΠ(sa)作比較,如果越接近當然就越好。
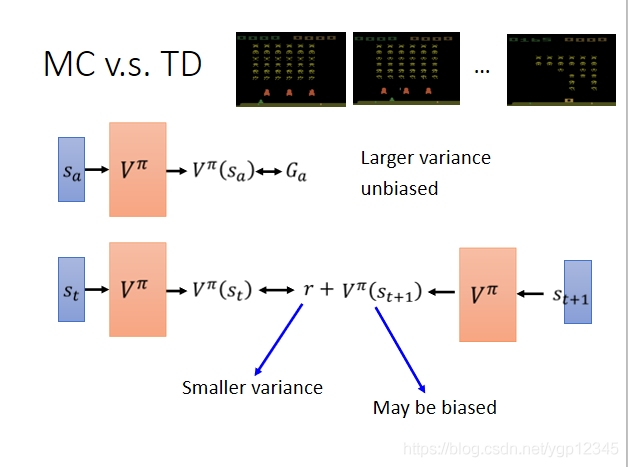
第二種是Temporal-difference方式,我們之前說過,VΠ(S)是指當看到這個畫面時,一直到遊戲結束所估計得總的獎勵,那麼在遊戲流程中,(s,a,r)是一個小的完整流程,也就是觀察->行動->獎勵,這是一個小的週期,那麼我在t時間點觀察到的畫面所得到的V與在t+1時刻觀察到的畫面所得到的V之間就差rt獎勵。(仔細看一下V的定義,再結合下面的圖很容易理解),那麼我只需看這兩個V只差是否和rt接近,越接近越好。


Q-Learning
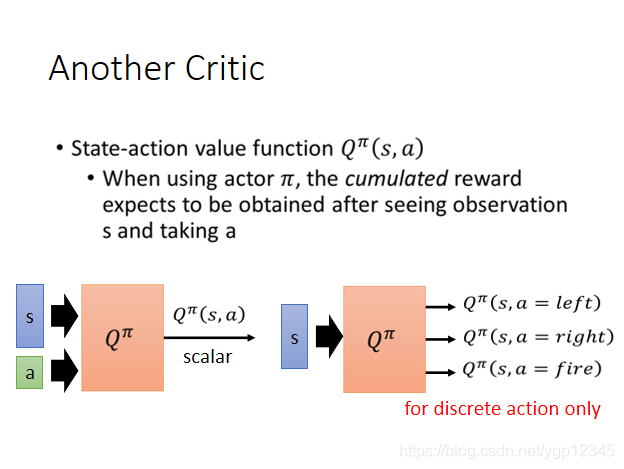
我們使用狀態行動價值函數能決定actor,因為該函數是將畫面與行動都考慮在內了,也稱Q-Learning。當使用一個actor,記為Π,然後計算在看到某畫面並作出某行動之後的所有獎勵的期望。如下圖所示,這裡的輸入就有兩個了,s和a,當a可以窮盡時,比如玩遊戲就三種情況,向左,向右,開火,那麼就變成下圖所示的分類問題。
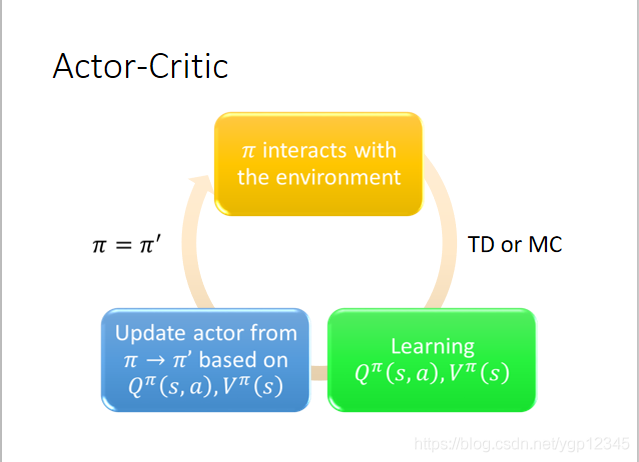
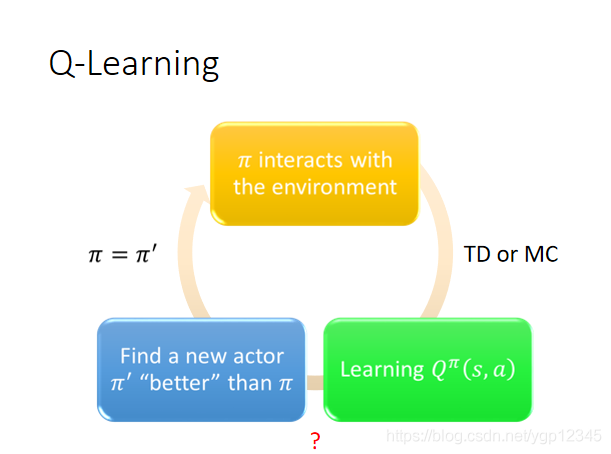
下圖是Q-Learning的流程,先初始化一個Π與環境互動,然後通過TD或者MC去學習一個Q函數,然後通過學習的這個Q函數找到比剛剛更好的Π,迴圈往復。
那麼給定一個QΠ(s,a),去找一個新的更好的Π應該怎麼做呢?何為更好?如下圖所示,更好的定義就是對於所有的畫面s,V在新的Π下的值大於舊的Π下的值,那麼這個新的Π就更好!!那麼如何找新Π呢,我們只需在舊Π下,找到某個action使Q最大,那麼新Π必須要滿足看到當前s時,所作的反應與使Q最大的action一致即可。新Π不是額外的引數,它取決於Q。當然,這不適用於a無窮或者a連續的時候。