第十八章 Java I/O系統
文章目錄
1.目錄列表器
- 如果我們呼叫不帶引數的list()方法,便可以獲得此File物件包含的全部列表
- 如果想獲得一個受限的列表,可以使用「目錄過濾器」
- boolean accept(File dir,String name)
- (1) dir:特定檔案所在目錄的File物件
- (2) name:檔名
- (1)
package Chapter18.Example01;
import java.io.File;
import java.io.FilenameFilter;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import java.util.regex.Pattern;
public final class Directory {
public static File[] local(File dir, final String regex){
return dir.listFiles(new FilenameFilter() {
private Pattern pattern = Pattern.compile(regex);
@Override
public boolean accept(File dir, String name) {
return pattern.matcher(new File(name).getName()).matches();
}
});
}
public static File[] local(String path, final String regex){ //過載
return local(new File(path), regex);
}
public static class TreeInfo implements Iterable<File>{
public List<File> files = new ArrayList<>();
public List<File> dirs = new ArrayList<>();
public Iterator<File> iterator(){
return files.iterator();
}
void addAll(TreeInfo other){
files.addAll(other.files);
dirs.addAll(other.dirs);
}
public String toString(){
return "dirs: "+ dirs + "\n\nfiles: " +files;
}
}
public static TreeInfo walk(String start, String regex){
return recurseDir(new File(start), regex);
}
public static TreeInfo walk(File start, String regex){
return recurseDir(start, regex);
}
public static TreeInfo walk(File start){
return recurseDir(start, ".*");
}
public static TreeInfo walk(String start){
return recurseDir(new File(start), ".*");
}
static TreeInfo recurseDir(File startDir, String regex){
TreeInfo result = new TreeInfo();
for(File item : startDir.listFiles()){
if(item.isDirectory()){
result.dirs.add(item);
result.addAll(recurseDir(item,regex));
}else {
if(item.getName().matches(regex))
result.files.add(item);
}
}
return result;
}
public static void main(String[] args) {
if(args.length == 0)
System.out.println(walk("."));
else
for(String arg :args)
System.out.println(walk(arg));
}
}
- (2) local()
- local()方法產生本地目錄中的檔案構成的File物件陣列
- local()方法使用被稱為listFile()的File.list()的變體來產生File陣列
- (3) walk()
- walk()方法產生給定目錄下的由整個目錄樹中的所有檔案構成的List
- walk()方法將開始目錄的名字轉換為File物件,然後呼叫recurseDirs(),該方法將遞迴地遍歷目錄,並在每次遞迴中都收集更多的資訊
- 目錄的檢查及建立
- (1) File類不僅僅只代表存在的檔案或目錄。也可以用File物件來建立新的目錄或尚不存在的整個目錄路徑。
- (2) 我們還可以檢視檔案的特性(如:大小,最後修改日期,讀/寫),檢查某個File對昂代表的是一個檔案還是一個目錄,並可以刪除檔案
2.輸入和輸出
-
流:它代表任何有能力產出資料的資料來源物件或者是有能力接收資料的接收端物件。」流「遮蔽了實際的I/O裝置中處理資料的細節
-
任何自InputStream或Reader派生而來的類都含有名為reader()的基本方法,用於讀取單個位元組或者位元組陣列
-
任何自OutputStream或Writer派生而來的類都含有名為write()的基本方法,用於讀取單個位元組或者位元組陣列
-
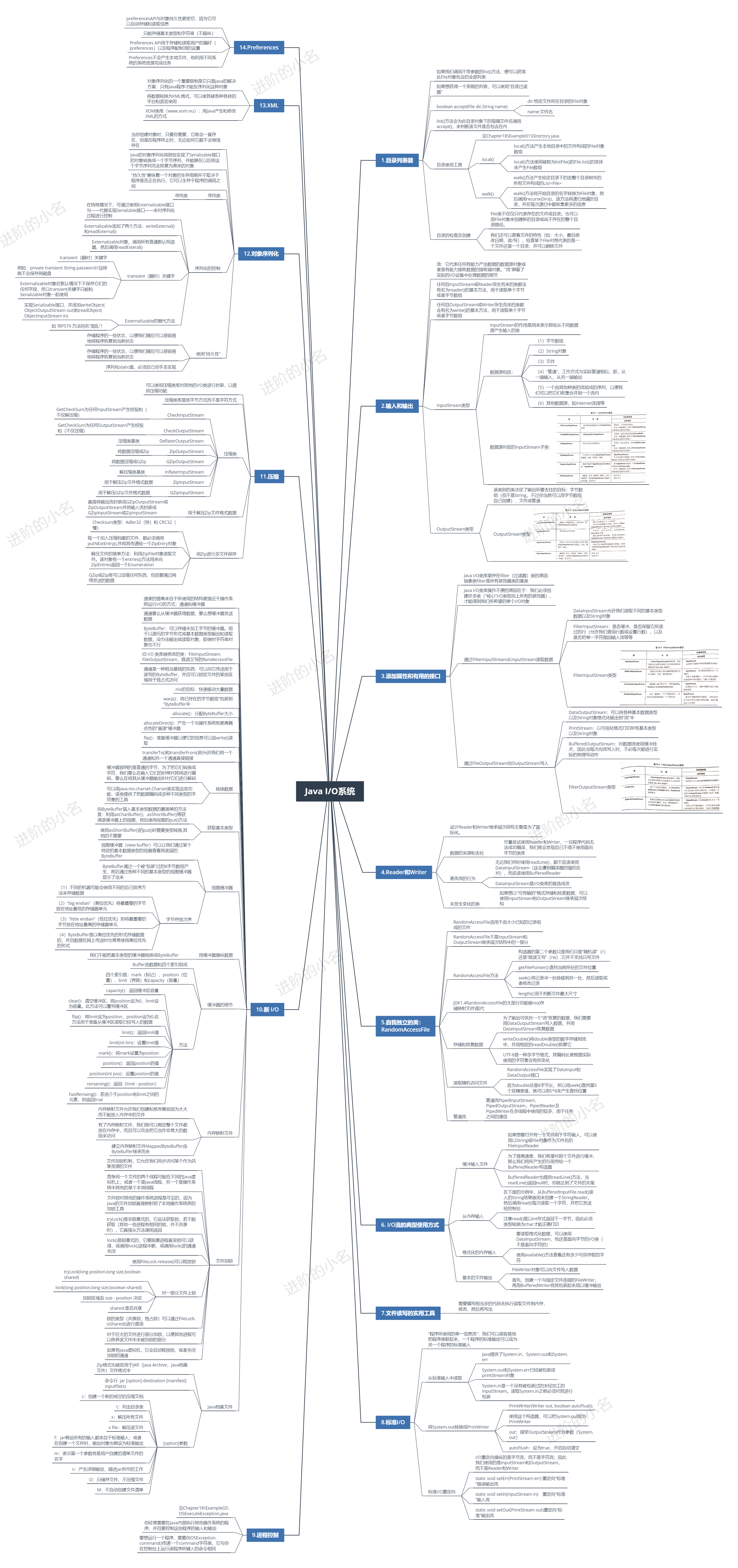
InputStream型別
- (1) InputStream的作用是用來表示那些從不同資料來源產生輸入的類
- (2) 資料來源包括:
- i.位元組陣列
- ii.String物件
- iii.檔案
- iv.「管道」,工作方式與實際管道相似,即,從一端輸入,從另一端輸出
- v.一個由其他種類的流組成的序列,以便我們可以把它們收集合併到一個流內
- iv.其他資料來源,如Internet連線等
- (3) 資料來源對應的InputStream子類:
- (1) 該類別的類決定了輸出所要去往的目標:位元組陣列(但不是String,不過你當然可以用位元組陣列自己建立)、檔案或管道
- (2) OutputStream型別:

3.新增屬性和有用的介面
-
Java I/O類庫裡存在filter(過濾器)類的原因:抽象類filter是所有裝飾器類的基礎類別
-
Java I/O類庫操作不便的原因在於:我們必須建立許多類(「核心」I/O型別加上所有的裝飾器),才能得到我們所希望的單個I/O物件
-
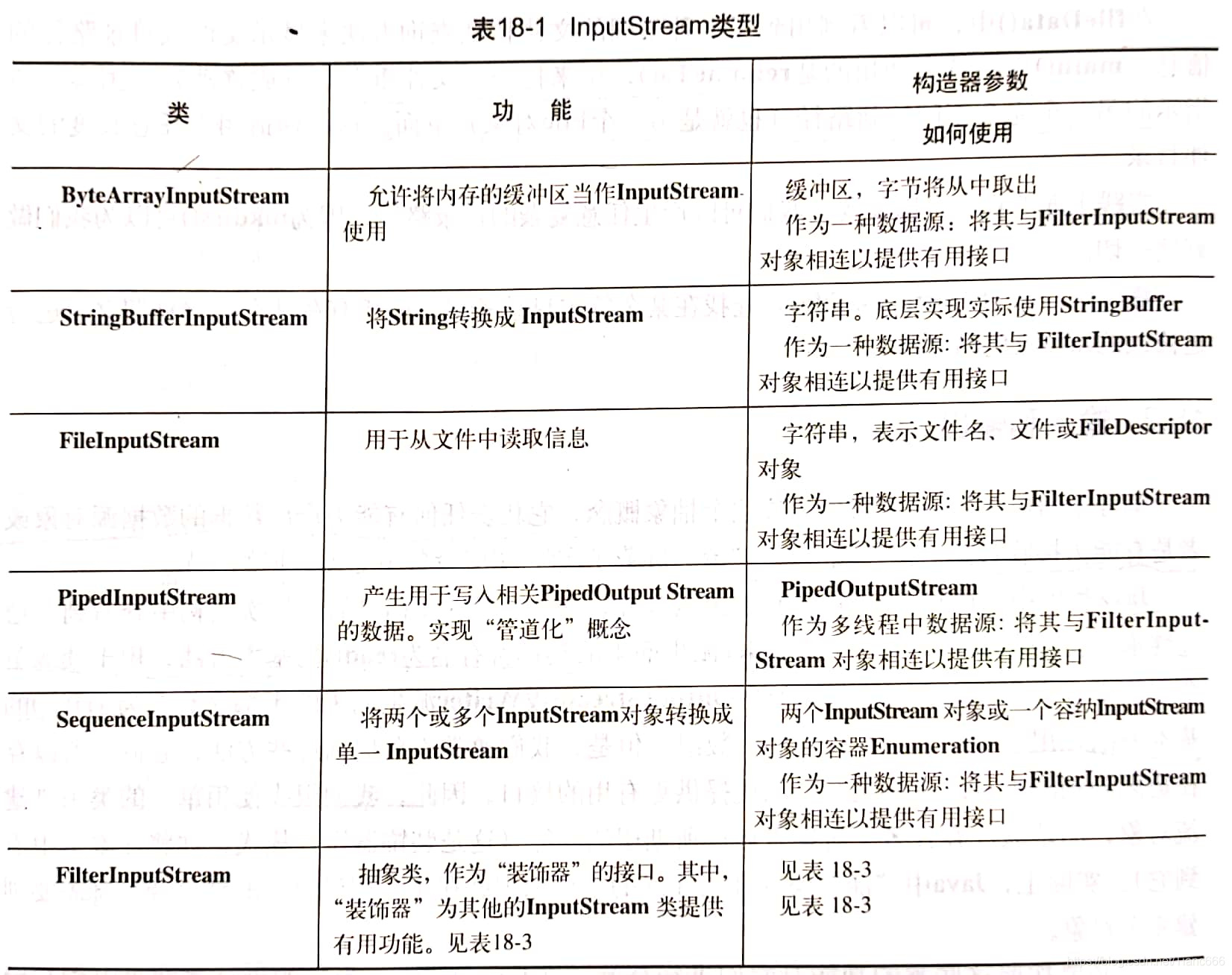
通過FilterInputStream從InputStream讀取資料
- (1) DataInputStream允許我們讀取不同的基本型別資料以及String物件
- (2) FilterInputStream:是否緩衝,是否保留它所讀過的行(允許我們查詢行數或設定行數),以及是否把單一字元推回輸入流等等
- (3) FilterInputStream型別
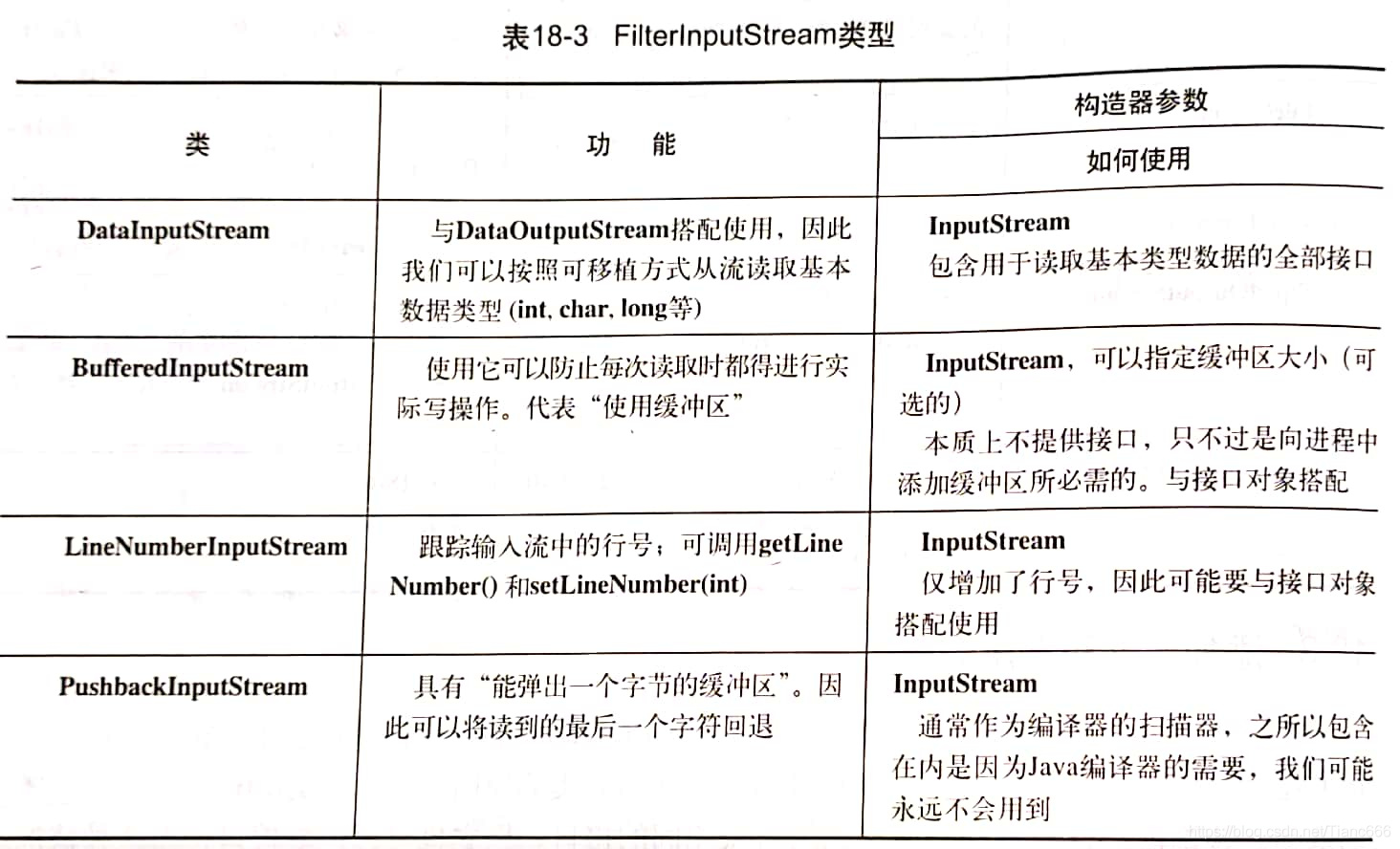
- (1) DataOutputStream:可以將各種基本資料型別以及String物件格式化輸出到「流」中
- (2) PrintStream:以視覺化格式列印所有基本型別以及String物件
- (3) BufferedOutputStream:對資料流使用緩衝技術,因此當每次向流寫入時,不必每次都進行實際的物理寫動作
- (4) FilterOutputStream型別
4.Reader和Writer
- 設計Reader和Writer繼承層次結構主要是為了國際化。
- 資料的來源和去處
- 儘量嘗試使用Reader和Writer,一旦程式程式碼無法成功編譯,我們就會發現自己不得不使用面向位元組的類庫
- (1) 無論我們何時使用readLine(),都不應該使用DataInputStream(這會遭到編譯器的強烈反對),而應該使用BufferedReader
- (2) DataInputStream是I/O類庫的首選成員
- 未發生變化的類
- 如果想以「可傳輸的」格式儲存和檢索資料,可以使用InputStream和OutputStream繼承層次結構
5.自我獨立的類:RandomAccessFile
-
RandomAccessFile適用於由大小已知的記錄組成的檔案
-
RandomAccessFile不是InputStream和OutputStream繼承層次結構中的一部分
-
RandomAccessFile方法
- (1) 構造器的第二個引數只是我們只是「隨機讀」(r)還是「既讀又寫」(rw),它並不支援只寫檔案
- (2) getFilePointer():查詢當前所處的檔案位置
- (3) seek():將記錄衝一處轉移到另一處,然後讀取或者修改記錄
- (4) length():用於判斷檔案最大尺寸
- (1) 為了輸出可供另一個「流」恢復的資料,我們需要用DataOutputStream寫入資料,並用DataInputStream恢復資料
- (2) writeDouble()將double型別的數位儲存到流中,並用相應的readDouble()恢復它
- (3) UTF-8是一種多位元組格式,其編碼長度根據實際使用的字元集會有所變化
- (1) RandomAccessFile實現了DataInput和DataOutput介面
- (2) 應為double總是8位元組長,所以用seek()查詢第5個雙精度值,就可以用5*8來產生查詢位置
- 管道流
- 管道流PipedInputStream、PipedOutputStream、PipedReader及PipedWriter在多執行緒中使用的較多,用於任務之間的通訊
6. I/O流的典型使用方式
- (1) 如果想要開啟有一個檔案用於字元輸入,可以使用以String或File物件作為檔名的FileInputReader
- (2) 為了提高速度,我們希望對那個檔案進行緩衝,那麼我們將所產生的參照傳給一個BufferedReader構造器
- (3) BufferedReader也提供readLine()方法,當readLine()返回null時,你就達到了檔案的末尾
- (1) 在下面的範例中,從BufferedInputFile.read()讀入的String結果被用來建立一個StringReader。然後呼叫read()每次讀取一個字元,並把它傳送給控制檯
- (2) 注意read()是以int形式返回下一位元組,因此必須型別轉換為char才能正確列印
- (1) 要讀取格式化資料,可以使用DataInputStream,他還是面向位元組的I/O類(不是面向字元的)
- (2) 使用available()方法檢視還有多少可供存取的字元
- (1) FileWriter物件可以向檔案寫入資料
- (2) 首先,建立一個與指定檔案連線的FileWriter,再用BufferedWriter將其包裝起來用以緩衝輸出
7.檔案讀寫的實用工具
- 需要編寫相當多的程式碼去執行讀取檔案到記憶體,修改,然後再寫出
8.標準I/O
- 「程式所使用的單一資訊流」:我們可以很容易地把程式串聯起來,一個程式的標準輸出可以成為另一個程式的標準輸入
- 從標準輸入中讀取
- (1) Java提供了System.in、System.out和System.err
- (2) System.out和System.err已經被包裝成printStream物件
- (3) System.in是一個沒有被包裝過的未經加工的InputStream。讀取System.in之前必須對其進行包裝
- (1) PrintWriter(Writer out, boolean autoFlush)
- (2) 使用這個構造器,可以把System.out轉為PrintWriter
- (3) out:接受OutputStream作為引數(System.out)
- (4) autoFlush:設為true,開啟自動清空
- (1) I/O重定向操縱的是位元組流,而不是字元流;因此我們使用的是InputStream和OutputStream,而不是Reader和Writer
- (2) static void setErr(PrintStream err) 重定向「標準」錯誤輸出流
- (3) static void setIn(InputStream in) 重定向「標準」輸入流
- (4) static void setOut(PrintStream out)重定向「標準」輸出流
9.程序控制
// Run an operating system command
// and send the output to the console.
package Chapter18.Example02;
import net.mindview.util.OSExecuteException;
import java.io.*;
public class OSExecute {
public static void command(String command) {
boolean err = false;
try {
Process process =
new ProcessBuilder(command.split(" ")).start();
BufferedReader results = new BufferedReader(
new InputStreamReader(process.getInputStream()));
String s;
while((s = results.readLine())!= null)
System.out.println(s);
BufferedReader errors = new BufferedReader(
new InputStreamReader(process.getErrorStream()));
// Report errors and return nonzero value
// to calling process if there are problems:
while((s = errors.readLine())!= null) {
System.err.println(s);
err = true;
}
} catch(Exception e) {
// Compensate for Windows 2000, which throws an
// exception for the default command line:
if(!command.startsWith("CMD /C"))
command("CMD /C " + command);
else
throw new RuntimeException(e);
}
if(err)
throw new OSExecuteException("Errors executing " +
command);
}
} ///:~
package Chapter18.Example02;
public class OSExecuteDemo {
public static void main(String[] args) {
OSExecute.command("javap OSExecuteDemo");
}
}
package Chapter18.Example02;
public class OSExecuteException extends RuntimeException {
public OSExecuteException(String why) { super(why); }
} ///:~
- 你經常需要在Java內部執行其他作業系統的程式,並且要控制這些程式的輸入和輸出
- 要想執行一個程式,需要向OSException.command()傳遞一個command字串,它與你在控制檯上執行該程式所鍵入的命令相同
10.新 I/O
-
速度的提高來自於所使用的結構更接近於作業系統執行I/O的方式:通道和緩衝器
-
通道要麼從緩衝器獲得資料,要麼想緩衝器傳送資料
-
ByteBuffer:可以儲存未加工位元組的緩衝器。用於以源氏的位元組形式或基本資料型別輸出和讀取資料,沒辦法輸出或讀取物件,即使時字串物件也不行
-
舊 I/O 類庫被修改的類:FileInputStream、FileOutputStream、既讀又寫的RandAccessFile
-
通道是一種相當基礎的東西:可以向它傳送用於讀寫的ByteBuffer,並且可以鎖定檔案的某些區域用於獨佔式存取
-
nio的目標:快速移動大量資料
-
warp():將已存在的位元組陣列「包裝到」ByteBuffer中
-
allocate():分配ByteBuffer大小
-
allocateDirect():產生一個與作業系統有更高耦合性的「直接」緩衝器
-
flip():準備緩衝器以便它的資訊可以由write()讀取
-
transferTo()和transferFrom()則允許我們將一個通道和另一個通道直接連結
-
轉換資料
- (1) 緩衝器容納的是普通的位元組,為了把它們轉換成字元,我們要麼在輸入它們的時候對其將進行編碼,要麼在將其從緩衝器輸出時對它們進行解碼
- (2) 可以用java.nio.charset.Charset類實現這些功能,該類提供了把資料編碼成多種不同型別的字元集的工具
- (1) 向ByteBuffer插入基本型別資料的最簡單的方法是:利用asCharBuffer()、asShortBuffer()等獲得該緩衝器上的檢視,然後使用檢視的put()方法
- (2) 使用asShortBuffer()的put()時需要型別轉換,其他的不需要
- (1) 檢視緩衝器(view buffer)可以讓我們通過某個特定的基本資料型別的視窗檢視其底層的ByteBuffer
- (2) ByteBuffer通過一個被」包裝「過的8位元組陣列產生,然後通過各種不同的基本型別的檢視緩衝器顯示了出來
- (3) 位元組存放次序
- i.不同的機器可能會使用不同的自己排序方法來儲存資料
- ii.「big endian」(高位優先)將最重要的位元組放在地址最低的記憶體單元
- iii.「little endian」(低位優先)則將最重要的位元組放在地址最高的記憶體單元
- iv.ByteBuffer是以高位優先的形式儲存資料的,並且資料在網上傳送時也常常使用高位優先的形式
- 用緩衝器操縱資料
- 我們不能把基本型別的緩衝器轉換成ByteBuffer
- (1) Buffer由資料和四個索引組成
- (2) 四個索引是:mark(標記)、position(位置)、limit(界限)和capacity(容量)
- (3) 方法
- capacity():返回緩衝區容量
- clear():清空緩衝區,將position設為0,limit設為容量。此方法可以覆寫緩衝區
- flip():將limit設為position,position設為0.此方法用於準備從緩衝區讀取已經寫入的資料
- limit():返回limit值
- limit(int lim):設定limit值
- mark():將mark設定為position
- position():返回position的值
- position(int pos):設定position的值
- remaining():返回(limit - position)
- hasRemaing():若由介於position和limit之間的元素,則返回true
- (1) 記憶體對映檔案允許我們建立和修改哪些因為太大而不能放入記憶體中的檔案
- (2) 有了記憶體對映檔案,我們就可以假定整個檔案都放在記憶體中,而且可以完全把它當作非常大的陣列來存取
- (3) 建立記憶體對映檔案MappedByteBuffer由ByteBuffer繼承而來
- (1) 檔案加鎖機制,它允許我們同步存取某個作為共用資源的檔案
- (2) 競爭同一個檔案的兩個執行緒可能在不同的Java虛擬機器器上;或者一個是Java執行緒,另一個是作業系統中其他的某個本地執行緒
- (3) 檔案鎖對其他的作業系統程序是可見的,因為Java的檔案加鎖直接對映到了本地作業系統弄的加鎖工具
- (4) tryLock()是非阻塞式的,它設法獲取鎖,若不能獲取(其他一些程序有相同的鎖,並不共用時),它直接從方法呼叫返回
- (5) lock()是阻塞式的,它要阻塞程序直至鎖可以獲得,或呼叫lock()程序中斷,或呼叫lock()的通道關閉
- (6) 使用FileLock.release()可以釋放鎖
- (7) 對一部分檔案上鎖
- tryLock(long position,long size,boolean shared)
- lock(long position,long size,boolean shared)
- 加鎖區域由 size - position 決定
- shared:是否共用
- (8) 鎖的型別(共用鎖,獨佔鎖)可以通過FileLock.isShared()進行查詢
- (9) 對於巨大的檔案進行部分加鎖,以便其他程序可以修養該檔案中未被加鎖的部分
- (10) 如果有Java虛擬機器器,它會自動釋放鎖,或者關閉加鎖的通道
- (1) Zip格式也被應用於JAR(Java Archive,Java檔案檔案)檔案格式中
- (2) 命令列 jar [option] destination [manifest] inputfile(s)
- (3) [option]引數
- c:建立一個新的或空的壓縮檔案
- t:列出目錄表
- x:解壓所有檔案
- x file:解壓該檔案
- f:jar假設所有的輸入都來自於標準輸入;或者在建立一個檔案時,輸出物件也假設為標準輸出
- m:表示第一個引數將是使用者自建的清單檔案的名字
- v:產生詳細輸出,描述jar所作的工作
- O:只儲存檔案,不壓縮檔案
- M:不自動建立檔案清單
11.壓縮
- (1) CheckInputStream:GetCheckSum為任何InputStream產生校驗和(不僅解壓縮)
- (2) CheckOutputStream:GetCheckSum為任何OutputStream產生校驗和(不僅壓縮)
- (3) DeflaterOutputStream:壓縮類基礎類別
- (4) ZipOutputStream:將資料壓縮成Zip
- (5) GZipOutputStream:將資料壓縮成GZip
- (6) InflaterInputStream:解壓縮類基礎類別
- (7) ZipInputStream:用於解壓Zip檔案格式資料
- (8) GZipInputStream:用於解壓GZip檔案格式資料
- 用於解壓Zip檔案格式資料
- 直接將輸出流封裝成GZipOutputStream或ZipOutputStream並將輸入流封裝成GZipInputStream或ZipInputStream
- (1) Checksum型別:Adler32(快)和 CRC32(慢)
- (2) 每一個加入壓縮檔案的檔案,都必須呼叫putNExtEntry(),並將其傳遞給一個ZipEntry物件
- (3) 解壓檔案的簡單方法:利用ZipFile物件讀取檔案。該物件有一個entries()方法用來向ZipEntries返回一個Enumeration
- (4) GZip或Zip庫可以壓縮任何東西,包括要通過網路傳送的資料
12.物件序列化
-
當你建立物件時,只要你需要,它就會一直存在,但是在程式終止時,無論如何它都不會繼續存在
-
Java的物件序列化將那些實現了Serializable介面的物件轉換成一個位元組序列,並能夠在以後將這個位元組序列完全恢復為原來的物件
-
「永續性」意味著一個物件的生存週期並不取決於程式是否正在執行;它可以生存於程式的呼叫之間
-
尋找類
-
序列化的控制
- (1) 在特殊情況下,可通過使用Externalizable介面與——代替實現Serializble介面——來對序列化過程進行控制
- (2) Externalizable新增了兩個方法:writeExternal()和readExternal()
- (3) Externalizable物件,呼叫所有普通預設構造器,然後呼叫readExteral()
- (4) transient(瞬時)關鍵字
- transient(瞬時)關鍵字
- 例如:private transient String password//這樣就不會儲存到磁碟
- Externalizable物件在預設情況下不儲存它們的任何欄位,所以transient關鍵字只能和Serializable物件一起使用
- (5) Externaliizable的替代方法
- 實現Serializable介面,並新增writeObject(ObjectOutputStream out)和readObject(ObjectInputStream in)
- 如 書P579 方法同名「混亂」!
- (1) 儲存程式的一些狀態,以便我們隨後可以很容易地將程式恢復到當前狀態
- (2) 儲存程式的一些狀態,以便我們隨後可以很容易地將程式恢復到當前狀態
- (3) 序列化static值,必須自己動手去實現
13.XML
- 物件序列化的一個重要限制是它只是Java的解決方案:只有Java程式才能反序列化這種物件
- 將資料轉換為XML格式,可以使其被各種各樣的平臺和語言使用
- XOM類庫(www.xom.nu):用Java產生和修改XML的方式
14.Preferences
- preferencesAPI與物件永續性更密切,因為它可以自動儲存和讀取資訊
- 只能儲存基本型別和字串(不超8k)
- Preferences API用於儲存和讀取使用者的偏好(preferences)以及程式配製項的設定
- Preferences不會產生本地檔案,他利用不同系統的系統資源完成任務