「面試」拿到小紅書的意向書
上一篇給大家分享了B站的面試之旅,大家的反響還不錯,居然催更了,小手不禁顫抖。所以決定把剩下的這些公司給安排明白了。這不,今天就看看小紅書伺服器端/後臺面了啥,不為別的,就想遇到漂亮的HR小姐姐,開工。
一面
一面面試官看著二十七八歲,文質彬彬,這哪裡是寫程式碼的,頭髮都飄起來了好麼。上來就幹專案,由於大家的專案都不太一樣,所以對於專案部分我就說說我面試的時候經常遇到的問題
- 描述下專案
一口是吃不了胖子的,描述之前先憋著氣掂量掂量自己所說的東西能不能唬住自己,然後唬住面試官。
- 專案中擔任的角色
對於大多數的我們而言,就是開發的角色,同樣的道理,角色對應相應的職務,闡述自己做的內容能引面試官上鉤,拉鉤上吊一百年不許變。
- 在專案遇到什麼困難
這三個問題,是不是可以拎著腳趾拇都可以想出來,除非不是你做的,哈哈哈哈哈。不慌,不是我們做的也不怕,我們必須知道有個網站叫做Github,大牛這麼多,自己不是大牛,難道不會學學人家麥。Clone下來,搭建環境跑起來,開始偵錯修改,通過將模組拆分,進一步修改,這不就是你的專案嗎,當然我不怎麼建議大家這麼操作啦。
專案被問的差不多了,開始懟基礎知識,基礎知識老四套,計算機網路,資料庫,作業系統,資料結構(來吧,時刻準備著,真沒吹牛逼)
我看你簡歷中寫著網路流量的還原,你應該對計算機網路比較熟悉?(注意哈,簡歷上寫上去的東西,自己心裡一定要有點B數),那我們說說計算機網路
- 說說計算機網路中TCP的三次握手吧
首先 Client 給 Server 傳送一個SYN包,Server 接收到 SYN 回覆 SYN+ACK,然後使用者端回覆 ACK 表示收到。
你這樣回答肯定是不會讓面試官滿意的,那就加點配料,不放佐料的菜怎麼香?那就詳細的安排一下
首先使用者端的協定棧向伺服器端傳送SYN包,同時告訴伺服器端當前傳送的序列號是X,此時使用者端進入 SYNC_SENT狀態
伺服器端的協定棧收到這個包以後,使用 ACK 應答,此時應答的值為 X+1,表示對 SYN 包 J 的確認,同時伺服器端也傳送一個SYN包,告訴使用者端當前我的傳送序列號是Y,此時伺服器端進入SYNC_RCVD狀態
使用者端協定棧收到 ACK 以後,應用程式通過connect呼叫表示伺服器端的單向連線成功,此時狀態為ESTABLISHED,同時使用者端協定棧對伺服器端的 SYN 進行應答,此時資料為Y+1
伺服器端收到使用者端的應答包,通過accept阻塞呼叫返回,此時伺服器端到客戶單的單向連線也建立成功,伺服器將進入ESTABLISHED狀態
這樣是不是稍微有B格一點呢,而且還比較形象,當然為了加深大家對這個過程的印象,我再舉個例子
***第一次握手:***小藍給某女娃告白,說我喜歡你,然後我傻乎乎的等著迴應
第二次握手:女生看我這顏值,秒回,自然就答應我啊,並回復我也喜歡你拉
第三次握手:我收到女生的迴應說:「那晚上去吃火鍋,看電影,理療」
就這樣在一起啦,那麼後續是啥樣呢?是不是得往下看看什麼是四次揮手了(渣男石錘),非也,還在熱戀期呢,專一的好嗎。面試官會繼續問你三次握手
面試官說:「那我問你,如果使用者端傳送的SYN丟失了或者其他原因導致Server無法處理,是什麼原因?
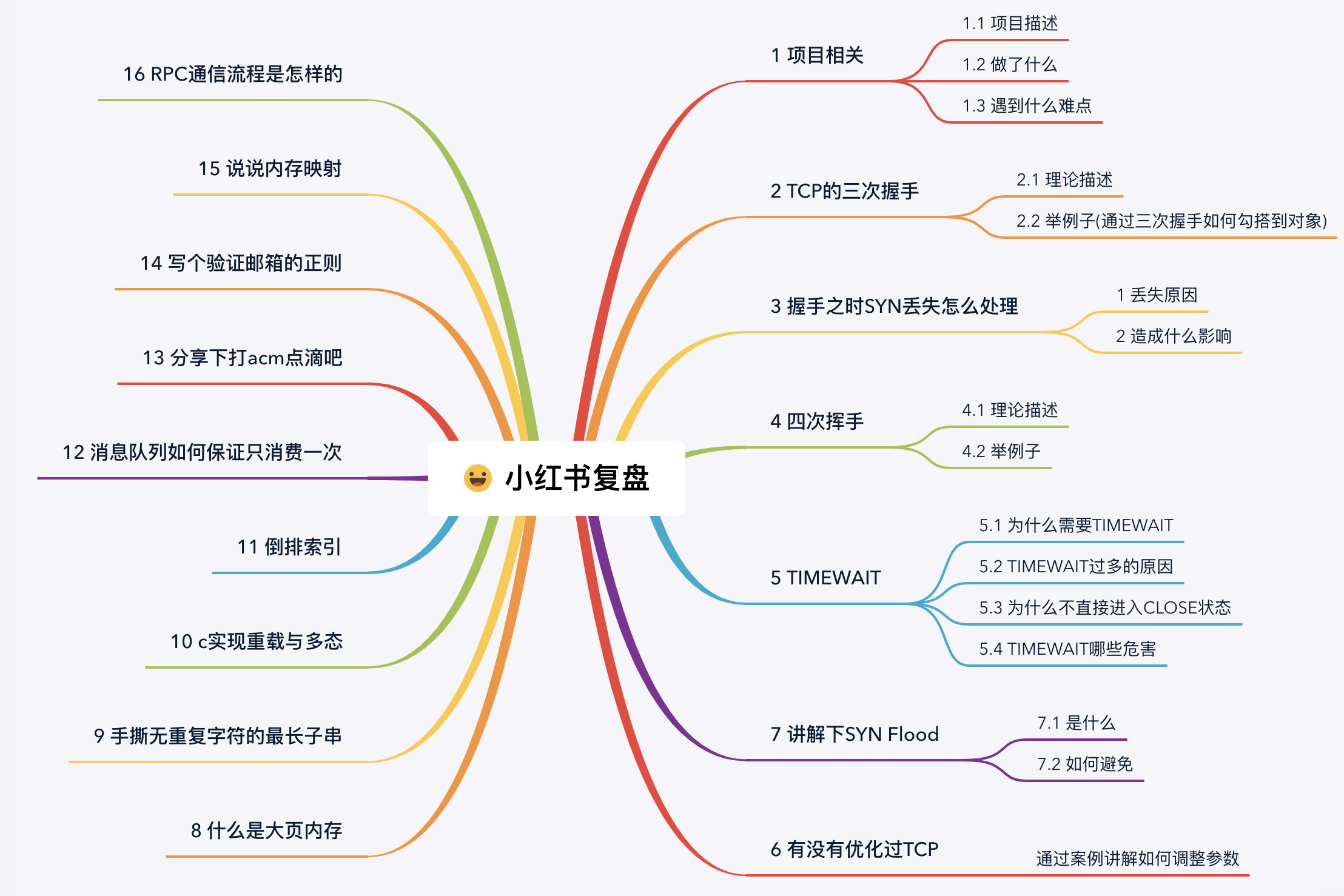
這個場景非常常見,沒有萬無一失。在TCP的可靠傳輸中,如果SYN包在傳輸的過程中丟失,此時Client段會觸發重傳機制,但是也不是無腦的一直重傳過去,重傳的次數是受限制的,可以通過 tcp_syn_retries 這個設定項來決定。如果此時 tcp_syn_retries 的設定為3,那麼其過程如下
當 Client 傳送 SYN 後,如果過了1s還沒有收到 Server 的迴應,那麼進行第一次的重傳。如果經過了2s沒有收到Sever的響應進行第二次的重傳,一直重傳tcp_syn_retries次。這裡的重傳三次,意味著當第一次傳送SYN後,需要等待(1 +2 +4 +8)秒,如果還是沒有響應,connect就會通過ETIMEOUT的錯誤返回。
說說四次揮手吧,哎,卑微的藍藍
第一次揮手:女生覺得和這個男生不太合適,但是是個好人,決定提出分手,等待男生迴應
第二次揮手:這男生吧,也是會玩兒,直接說:」分就分「
第三次揮手:過了一段時間,男生覺得好沒得面子:「我一個大老爺們,應該是我提出分手啊」,於是給女生說:我們分手吧
第四次揮手:女生看到這個訊息,你是「憨批」還是「神經病」?
TIMEWAIT瞭解哈,過多的TIMEWAIT怎麼辦,什麼原因造成的?
回答問題的方法無外乎即是什麼,為什麼會出現以及可以解決的方案
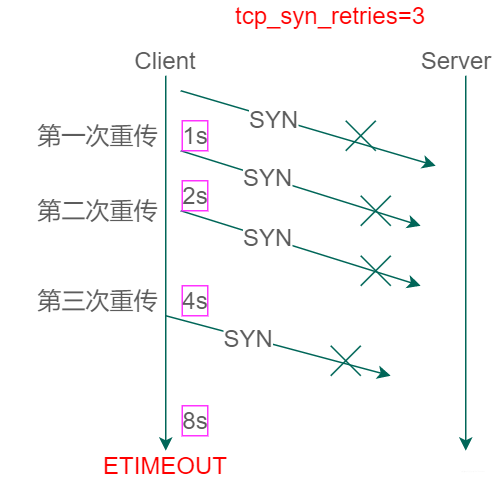
在TCP的四次揮手過程中,發起連線斷開的一方會進入TIME_WAIT的狀態。通常一個TCP連線通過對外開發埠的方式提供服務,在高並行的情況下,每個連線佔用一個埠,但是埠是有限的以致於可能導致埠耗盡,所以就會出現’「服務時而好時而壞的情況」。
如下圖所示的TCP四次揮手,TCP連線準備終止的時候會傳送FIN報文,主機2進入CLOSE_WAIT狀態並行送ACK應答。主機1會在TIMEWAIT停留2MSL的時間。
為什麼不直接進入CLOSE轉態,而是需要先等待2MSL,這段時間在幹啥?
第一個原因是為了確保最後的ACK能夠正常接收,從而有效的正常關閉。怎麼理解,科學家們在設計TCP的時候,假設TCP】 報文會出錯從而開始重傳,如果主機1的報文沒有傳輸成功,那麼主機2就會重發FIN報文,此時主機1沒有維護TIME_WAIT狀態,就會失去上下文從而恢復RST,導致服被動關閉一方出現錯誤。
第二個原因是讓舊連結的重複分節在網路中自然消失。
一次網路通訊可能經過無數個路由器,交換機,不知道到底會是哪個環節出問題。我們為了標識一個連線,通過四元組的方式[源IP,源埠,目的IP,目的埠]。假設此時兩個連線A,B。A連線在中途中斷了,此時重新建立B連線,這個B連線的四元組和A連線一樣,如果A連線經過一段時間到達了目的地,那麼B連線很有可能被認為是A連線的一部分,這樣就會造成混亂。所以TCP設定了這樣一個機制,讓兩個方向的分組都被丟棄。
那麼TIME_WAIT有哪些危害?
過多的連線勢必造成記憶體資源的浪費
對埠的佔用。可開啟的埠也就32768~61000
有沒有對TCP進行優化過
開玩笑,這東西複習過,儘管問,錘子不怕。優化的點很多,隨便提一點,讓後比較深的描述下這個過程就行比如調整哪些引數在某些特定的條件下會最優
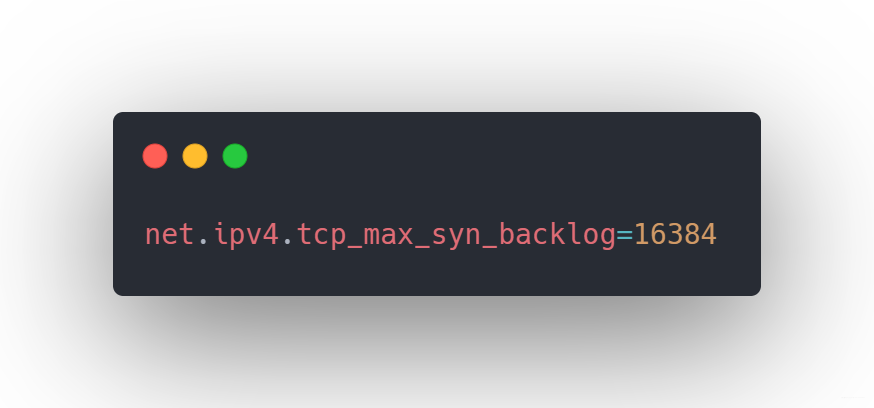
我們應該都知道半連線,即收到SYN以後沒有回覆SYN+ACK的連線,那麼Server每收到新的SYN包,都會建立一個半連線,然後將這個半連線加入到半連線的佇列(syn queue)中,syn queue的長度又是有限的,可以通過tcp_max_syn_backlog進行設定,當佇列中積壓的半連線數超過了設定的值,新的SYN包就會被拋棄。對於伺服器而言,可能瞬間多了很多新的連線,所以通過調大該值,以防止SYN包被丟棄而導致Client收不到SYN+ACK。
就這樣是不是就可以讓面試官感覺,這小夥子有點東西。那怎麼設定呢
你以為面試官是傻子?當然不是,萬一面試官問你:半連線積壓較多,還有其他的原因?
哈哈哈,這說明面試官上鉤了哇,來,我們看看還有啥原因
還有可能是因為惡意的Client在進行SYN Flood攻擊。
SYN Flood攻擊是個啥過程?
首先Client以較高頻率傳送SYN包,且這個SYN包的源IP不停的更換,對於Server來說,這是新的連結,就會給它分配一個半連線
Server的SYN+ACK會根據之前的SYN包找IP,發現不是原來的IP,所以無法收到Client的ACK包,從而導致無法正確的建立連線,自然就讓Server的半連線佇列耗盡,無法響應正常的SYN包
那有沒有什麼方案解決這個問題?
那必須,畢竟面試嘛,需要讓面試官問我們知道的內容。在Linux核心中引入了SYN Cookies機制,那看看這個機制是啥意思
首先Server收到SYN包,不分配資源儲存Client的資訊,而是根據SYN計算出Cookie值,然後將Cookie記錄到SYN ACK並行送出去
如果是正常的情況,這個Cookies值會伴隨著Client的ACK報文帶回來
Server會根據這個Cookies檢查ACK包的合法性,合法則建立連線
那麼開啟SYN Cookies的方法?
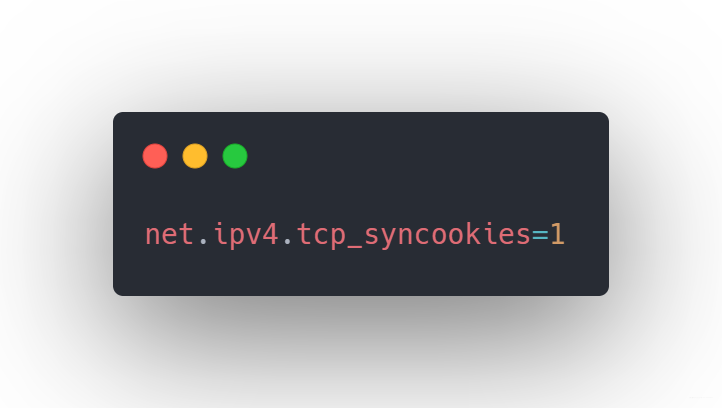
網路問到這就差不多了,挺好的,完全按照我的套路出牌。開始懟我作業系統
- 說下什麼是大頁記憶體
我擦,我差點沒反應過來,「大爺記憶體」,不過確實牛逼,大頁記憶體,記住了,是大頁記憶體。
我們知道作業系統堆記憶體的管理採用多級頁表和分頁進行管理,作業系統給每個頁的預設大小是4KB。假設當前程序使用的記憶體比較大為1GB,那麼此時在頁表中會佔用1GB/4KB=26211個頁表項,但是系統的TLB可容乃的頁表項遠遠小於這個數量。所以當多個記憶體密集型應用存取記憶體的時候,就會導致過多的TLB沒有命中,因此在特定的情況下會需要減少未命中次數,一個可行的辦法即是增大每個頁的尺寸。
作業系統預設支援的大頁為2MB,當使用1GB記憶體的時候,頁表將佔用512頁表項,大大的提高TLB命中率從而提高效能。另外需要注意的是,大頁記憶體分配的是實體記憶體,所以不會有換出磁碟的操作,所以沒有缺頁中斷,也就不會引入存取磁碟的時延。
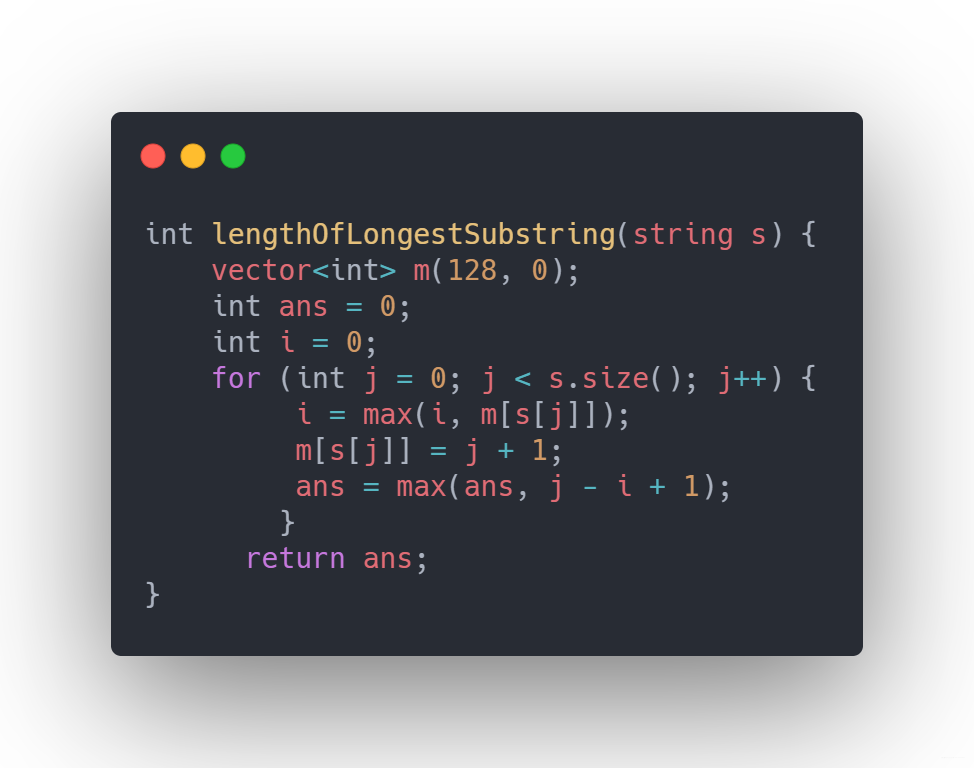
行,差不多時間了,寫個簡單程式碼吧,實現一個無重複字元的最長子串
思路:使用滑動視窗保證每個視窗的字母都是唯一的
-
使用 vector m 來記錄一個字母如果後面出現重複時,i 應該調整到的新位置
-
所以每次更新的時候都會儲存 j + 1 ,即字母后面的位置
-
j 表示子串的最後一個字母,計運算元串長度為 j - i + 1
二面
一面感覺還不錯,果不其然二面來了,HR小姐姐打電話通知週三二面,行,對於從來不遲到的暖藍,肯定守時。拿著咖啡,等到2:30,至於為什麼拿著茶,這是我的習慣,面試前喝杯茶等待面試官的捧擊(面試官其實大部分很溫柔的啦)。
可耐,面試官到點了居然還沒來,等不及的我打電話給HR,HR說不好意思,得等幾分鐘,行,對這甜美的聲音我忍了,可是等了十分鐘都沒音信,我下午還有個筆試,無奈給HR說,我下午還有事兒,要不改天面?
不知道什麼情況,直接說,我馬上給你換個面試官,我擦,還有這種事兒,我這鄉卡卡的娃兒有這種的待遇?是我一面表現的太太突出?不會吧,反正小紅書我愛了。
「staty with me」響起,這正是我的手機鈴聲。。
"您好」
「你好,請問是XX?」
「嗯嗯,你好面試官」
「我是你的二面面試官,先自我介紹吧」
我叫小藍,來自XX大學,本科XX,碩士XXX,期間做了XX,謝謝面試官。自我介紹不用那麼花裡胡哨,挑重點說,不會在意你本科談了幾次戀愛,也不會在意你XXXX,簡單明瞭完事,開始二面
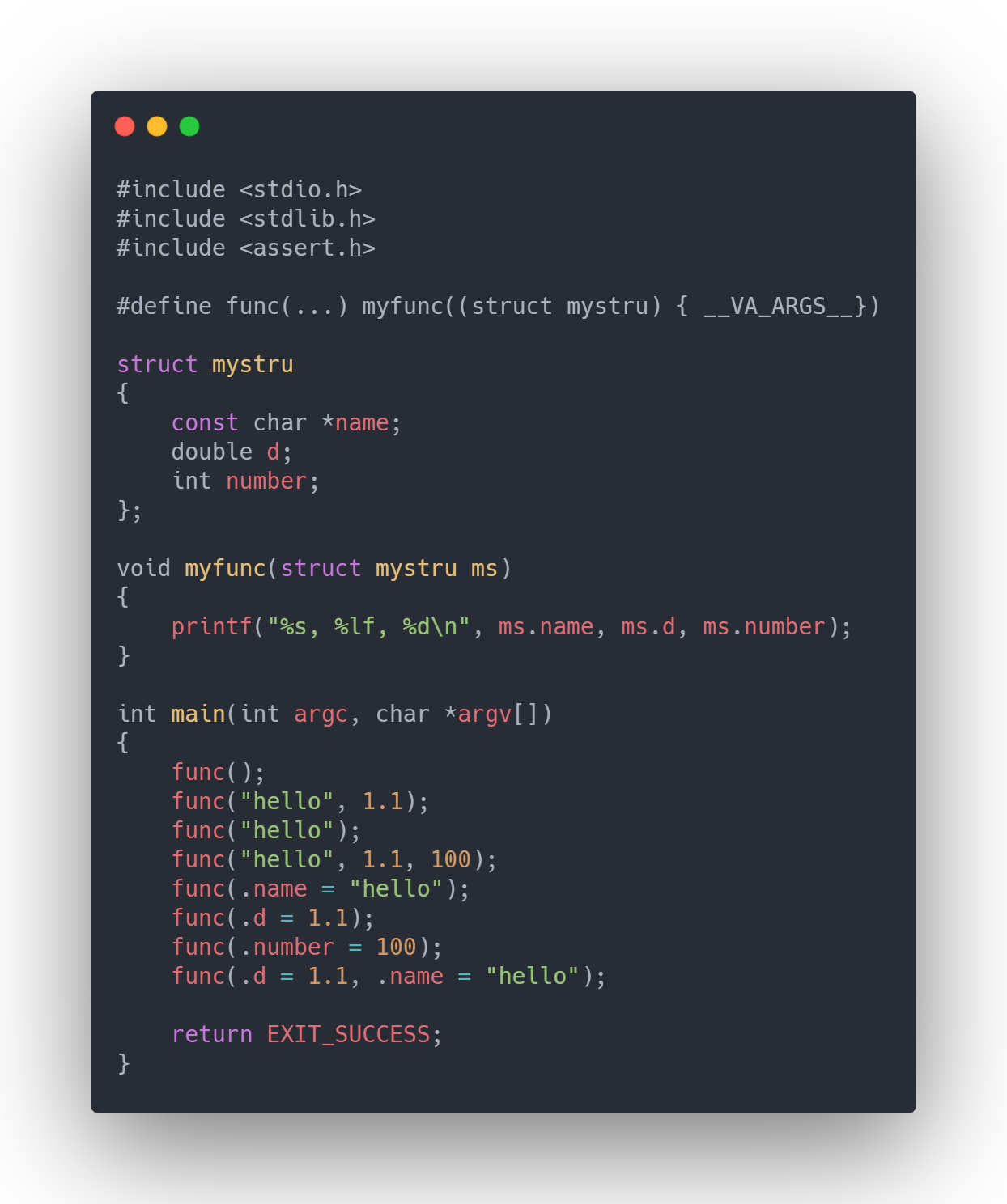
- 應該學過C的吧,用C實現多型怎麼個思路
至於這個題,我還是比較驚訝的,怎麼突然問到了C,想了想可能還是考慮對於物件導向中多型,繼承等的理解。
多型無外乎就是編譯時多型和執行時多型,編譯時多型理解為過載,執行時多型理解為重寫。那麼要實現過載,需要用到c中的宏,V_ARGS。

理解上面的方法,實現多型就更輕鬆了
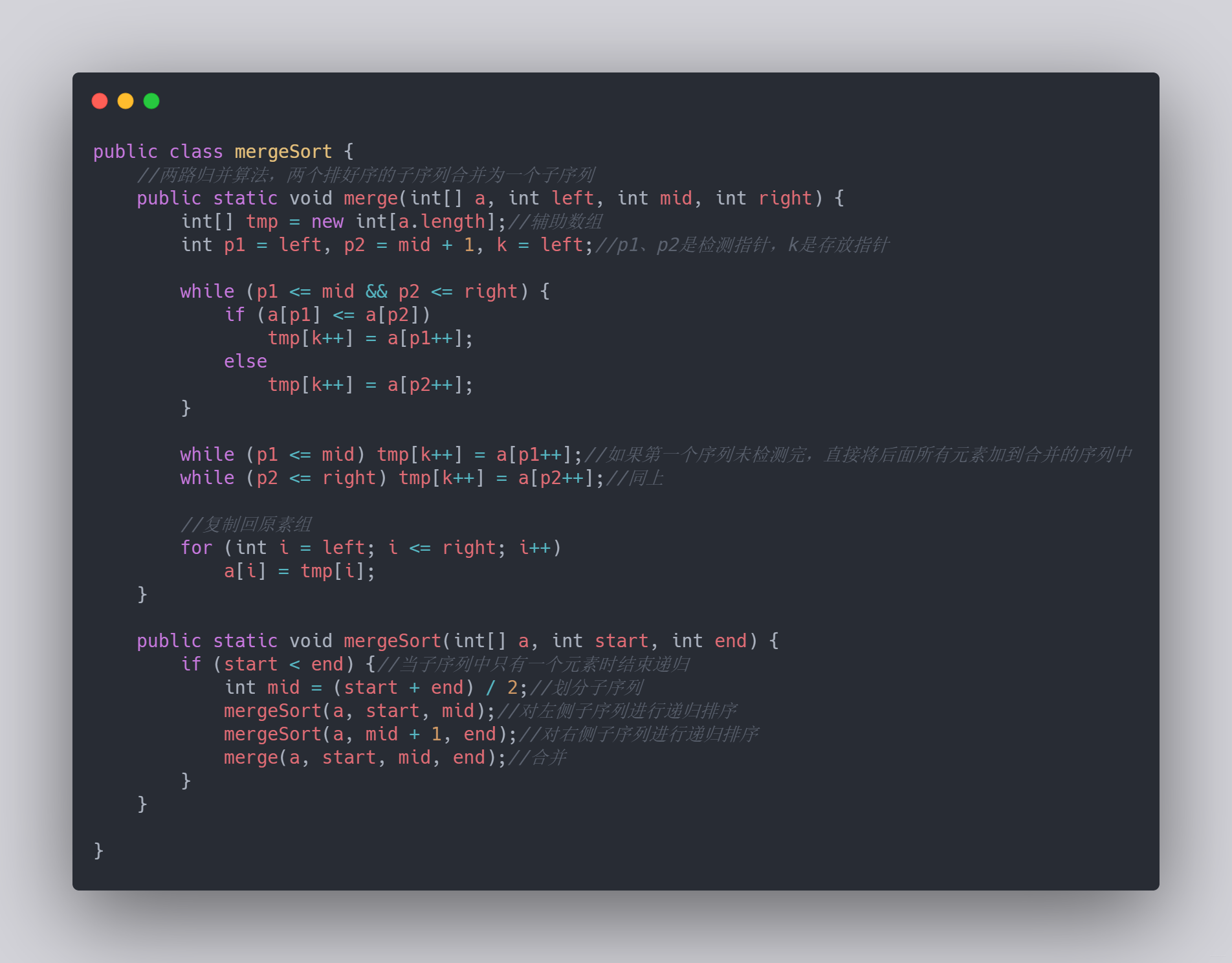
感覺沒啥問的,先寫個程式碼,二路歸併
哈哈,讓我想起了歌詞"來左邊跟我花個龍,在你右邊畫一道彩虹"(腦補畫面)
停!!這是我之前說過的常考演演算法之一,中心思想即分治,可通過遞迴一直拆分,遞迴的結束條件即不可再分,即分為1個的時候就停止。從第一個開始時將每一個模組當作一個已經排序好的陣列,有如雙指標,在兩個陣列頭設立指標,進行值的比較,然後插入到新陣列中,上程式碼咯
倒排索引瞭解不?
假設我這裡有幾十本檔案,每個檔案題目不一樣,如果我給你檔案的題目,你可能很快就可以找到相應的檔案。但是如果我讓你找論文中包含"暖"和「藍」這兩個字,你可能直接給我"兩兒巴「。因為多半很難很快就找出來。從稍微專業的角度來分,前一種是正排索引,後一個是倒排索引。
我們先看簡單的正排索引。此時給每個檔案一個唯一ID,然後使用雜湊表將檔案的ID作為鍵,將檔案內容作為鍵對應的值。這樣我們就可以在O(1)的時間代價完成key的檢索。這也正是正排索引
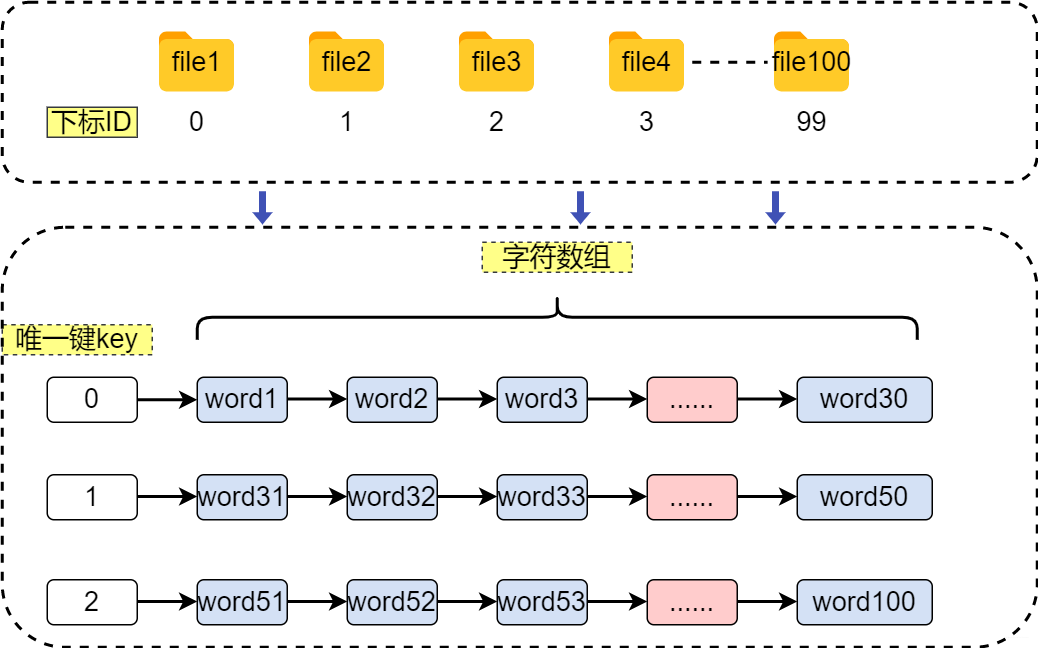
這裡遍歷雜湊表的時間代價為O(n)。每遍歷一個檔案都需要遍歷每個字元判斷是否包含兩字。假設每個檔案的平均長度為k,那麼遍歷一個檔案的時間代價為O(K)。
有沒有什麼優化的方法?
其實以上就是兩種方案,一種是根據題目找到內容,另一種是根據關鍵字查詢題目。這完全相反的方案,那我們反著試試
我們將關鍵字當做key,將包含這個關鍵字的檔案的列表當做儲存的內容。同樣建立一個雜湊表,在O(1)的時間我就可以找到包含該關鍵字的檔案列表。這種根據內容或者欄位反過來的索引結構即倒排索引。
如何建立倒排索引?
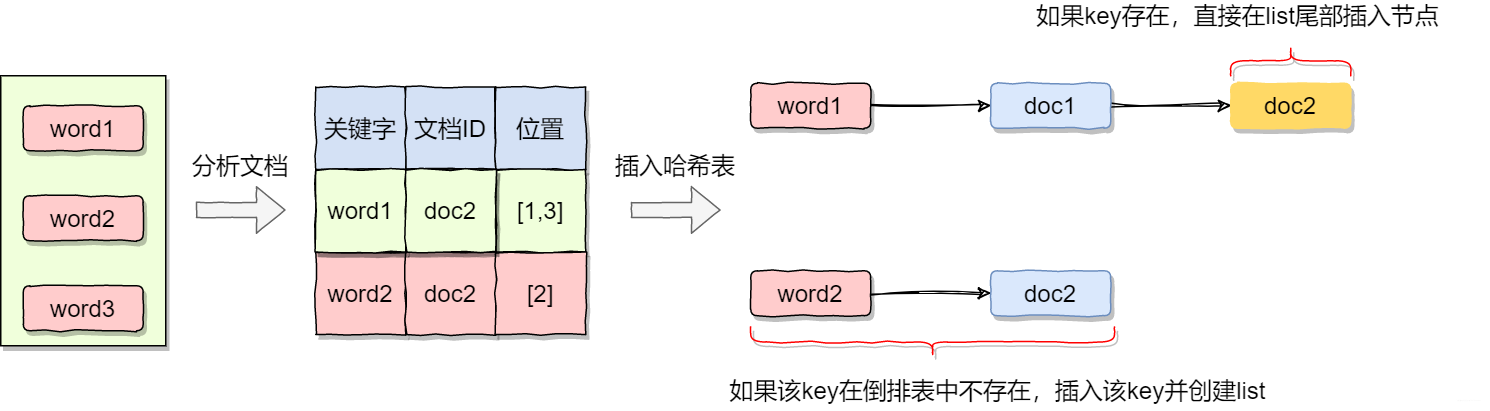
- 首先給檔案編個號表示唯一表示,然後排序遍歷檔案
- 解析每個檔案的關鍵字並生成<關鍵字,檔案ID,關鍵字位置>。這裡的關鍵字位置主要是為了檢索的時候顯示關鍵字前後資訊
- 將關鍵字key插入雜湊表。如果雜湊表已存在這個key,就在對應的posting list中追加節點,記錄檔案ID。如果雜湊表沒有響應的key則插入該key並建立posting list和對應的節點
- 重複2 3步處理完所以檔案
如果要查詢同時包含"暖"「藍」兩個key怎麼辦?
順藤摸瓜啦,分別用兩個key去倒排索引中檢索,這樣使用的兩個不同list:A和B。A中的檔案都包含了"暖"字,B中的檔案都包含了"藍"字。如果檔案即出現"暖"也出現"藍",是不是就正好包含了兩個字?所以只需要找到AB公共元素即可
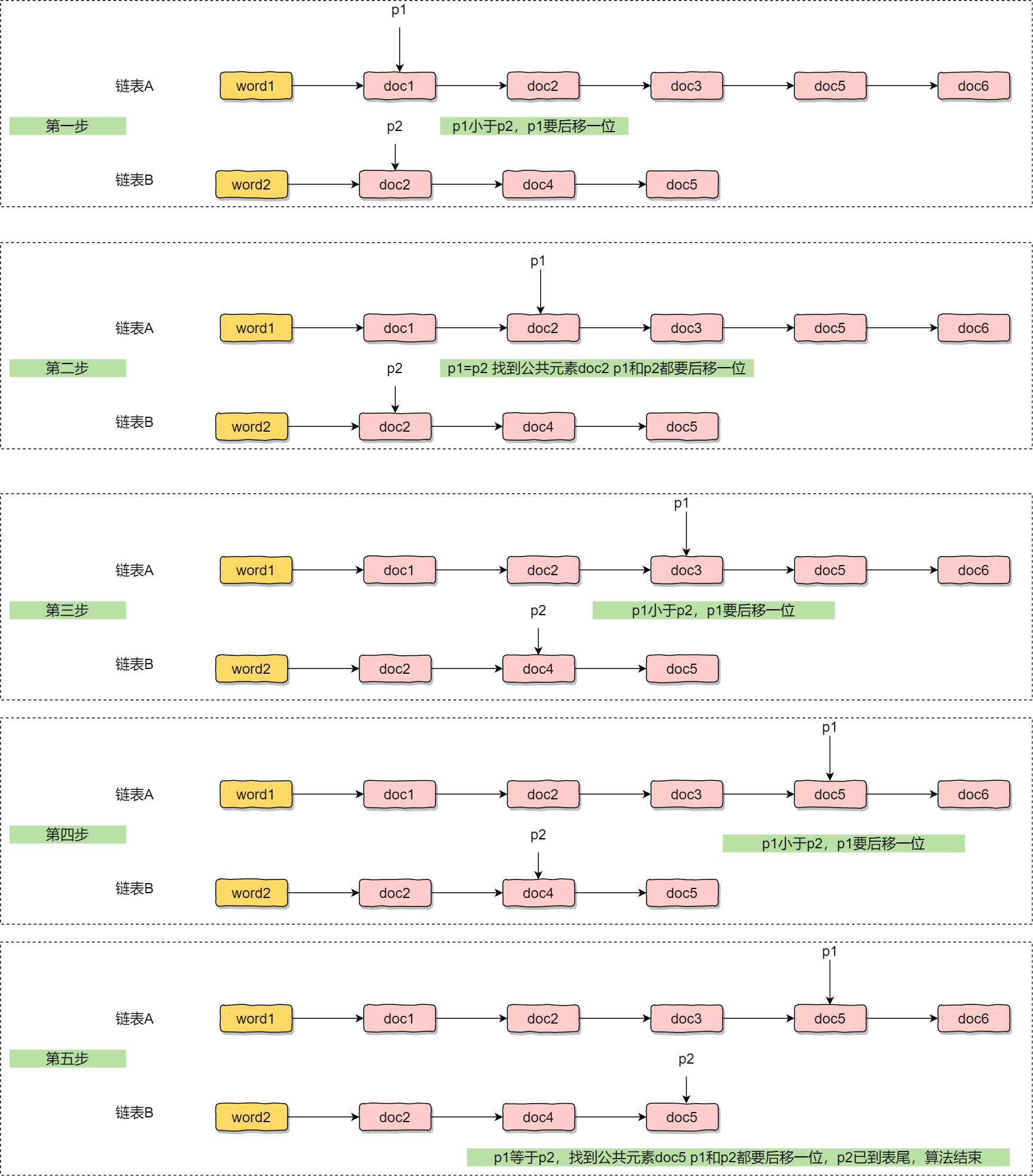
如何找到AB兩個連結串列的公共元素?希望小夥伴們思考下,經常在手撕演演算法中被問到
- 首先使用兩個指標P1 P2分別指向有序連結串列AB的第一個元素
- 然後對比兩個指標所指節點是否相同,這可能出現三種情況
- 兩者id相同則是公共元素,直接歸併即可,然後P1 P2後移
- p1元素小於p2元素,p1後裔,指向A連結串列的下一個元素
- p1元素大於p2元素,p2後裔,指向B連結串列中下一個元素
- 重複第二步 直到p1和p2移動到連結串列尾
你說使用過kafka,那麼使用訊息佇列的時候如何保證只消費一次?
首先引入kafka等訊息佇列是為了對峰值寫流量做削峰填谷,對不同系統做解耦合。
舉個例子,我們開發了一個電商系統,其中一個功能是當使用者購買了A產品5份就送一個紅包從而鼓勵使用者消費。但是如果在訊息傳遞的過程中丟失了,使用者很可能會因為沒有收到紅包而不開心,甚至取消訂單,在這裡如何保證訊息被消費到且一次?
我們先看看這個訊息寫入訊息佇列會有幾個階段,首先有訊息從生產者寫入訊息到佇列,訊息儲存在訊息佇列,訊息被消費者消費這個階段,任何一個階段都有可能丟失,我們分別檢視這幾個階段

第一個階段:訊息生產
訊息的生產通常會是業務伺服器,業務伺服器和獨立部署的訊息佇列伺服器通過內網通訊,很可能因為網路抖動導致訊息的丟失,這樣可以採用訊息重傳的機制保證訊息的送達。但是容易出現重複消費的情況,意思收到兩個紅包,使用者開心了,但是。。。
第二個階段:在佇列中丟失
kafka為了減少訊息儲存對磁碟的隨機IO,採用的非同步刷盤的方式將訊息儲存在磁碟中。
我看你簡歷上打過acm,說說你的策略或者經歷吧
哈哈哈,終於到我正兒八經吹水的時候了。低調,才是最牛逼的炫耀
寫個驗證郵箱的正則
當時沒有寫出來,確實記不住,每次都是用的時候才去查,誰知道面試的時候遇見誰呢,手撕KMP?這裡給大家個答案,後續我詳細安排一篇正則的套路

瞭解記憶體對映?說說,儘量說
既然是儘量說,就不客氣了。從什麼是記憶體到如何檢視伺服器記憶體,最後怎麼能夠更好地用好記憶體來答就完事
首先記憶體作為儲存系統和應用程式的指令,資料等。在Linux中,管理記憶體使用到了記憶體對映。平時我們經常說的記憶體容量,主要指的是實體記憶體,也叫做主記憶體。只有核心才能直接存取,那麼問題來了,進城如果要存取記憶體怎麼辦呢?
Linux核心為每個程序提供了一個虛擬地址空間且空間地址連續,這樣的話,程序存取虛擬記憶體將非常的方便。
虛擬地址又分為核心空間和使用者空間,不同字長的處理器地址範圍也不同。我們下面分別看看32位元和64位元的虛擬地址空間
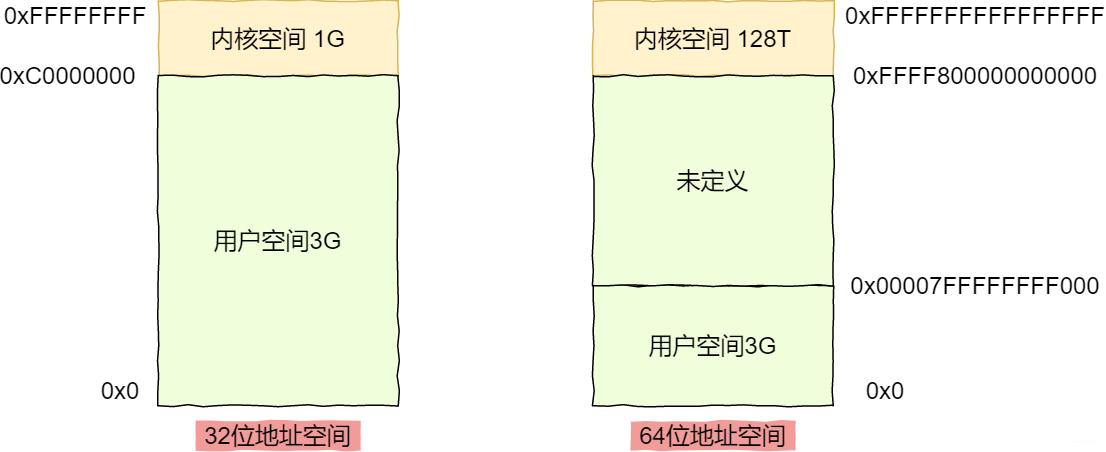
從這個圖很明顯的看出32位元系統中核心空間1G,而64位元的核心空間與使用者空間都是128T。
記憶體對映即虛擬記憶體地址對映到實體記憶體地址,完了順利完成對映,需要給每個程序維護一張頁表記錄兩者的關係。
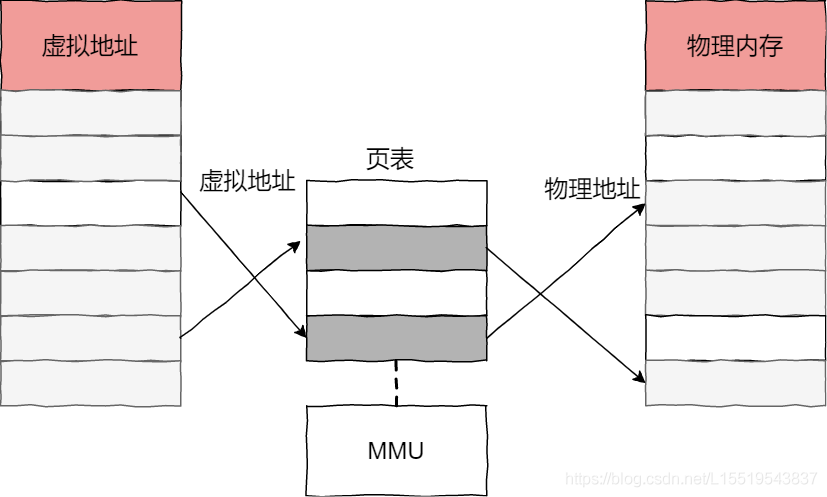
這樣,如果程序存取的虛擬地址不在則通過缺頁異常進入核心空間分配實體記憶體,更新程序頁表,最終返回使用者空間。
說到虛擬記憶體又不得不說說使用者空間的各個段
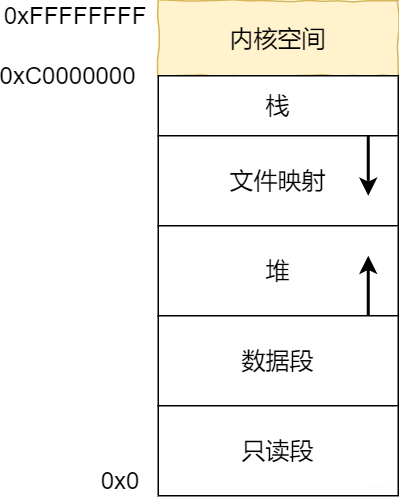
忍不住悄悄咪咪問了下HR,二面面試官對我的評價,基礎和code的能力不錯,專案講述的不清楚
- 我自己可能沒有把專案更本質的東西理解清楚
- 從事的不同的方向,有些專業術語的理解的不同)
三面
三面面試官,真的不能用"禿"來描述了,就感覺我的眼睛被閃了一分鐘,怎麼說,面嘛
執行緒的鎖有哪些,我說到了讀寫鎖打斷我了,問我讀寫鎖會有什麼些問題,無非就是寫鎖飢餓問題,我說沒看過核心原始碼,然後如果讓我來實現,我怎麼來避免
分散式Hash表,當進行擴容的時候(會花費很長的時間),我說P肯定一定要保證的,CA只能選其一,但是我們可以使用弱一致性來保證其可用性
多個隨機Request請求,然後不同的請求有不同的權重,進行隨機抽樣,要求權重大更可能被抽到
有了解過RPC?
RPC翻譯過來為遠端過程呼叫。幫助我們遮蔽網路細節,實現呼叫遠端方法就跟呼叫本地一樣的體驗。舉個例子,如果沒有橋,我們要過河只好划船,繞道等方式,如果有橋,我們就像在路面行走一樣自如到目的地。
RPC的通訊流程是怎樣的?
剛才說RPC遮蔽了網路細節,也就是意味著它處理好了網路部分,它為了保證可靠性,預設採用TCP傳輸,網路傳輸的資料是二進位制,但是呼叫所請求的引數是物件,所以需要將物件轉換為二進位制,這就需要用到序列化技術
服務提供方接收到資料以後,並不知道哪裡是結尾,所以需要一些邊界條件來標識請求的資料哪裡是開始,哪裡是結束,就像高速路上各種指路牌引領我們前進的方向。這種格式的約定叫做「協定」
根據協定規定的格式,就可以正確的提取出相應的請求,根據請求的型別和序列化的型別,將二進位制訊息體逆向還原為請求物件,這叫做反序列化
服務提供方通過反序列化的物件找到對應的實現類完成整正的呼叫,這樣就是一次rcp的呼叫。畫個圖加深下印象

其他問的一些問題感覺在前面的面試問過了就沒有寫在這部分內容了,還問了幾個資料庫的問題,很常規的了,之前的文章寫過,篇幅太長,看著累,要不先三連,我們下期再見?麼麼噠
5 總結
請記下以下幾點:
- 公司招你去是幹活了,不會因為你怎麼怎麼的而降低對你的要求標準。
- 工具上面寫程式碼和手撕程式碼完全不一樣。
- 珍惜每一次面試機會並學會覆盤。
- 對於應屆生主要考察的還是計算機基礎知識的掌握,專案要求沒有那麼高,是自己做的就使勁摳細節,做測試,只有這樣,才知道會遇到什麼問題,遇到什麼難點,如何解決的。從而可以侃侃而談了。
- 非科班也不要怕,怕了你就輸了!一定要多嘗試。

我是小藍,一個專為大家分享面試經驗的藍人。如果覺得文章不錯或者對你有點幫助,感謝分享給你的朋友,也可在下方給小藍給個在看,這對小藍非常重要,謝謝你們,下期再會。