基於pytorch神經網路的公眾健康問句分類(多標籤分類NLP)
2020-10-12 11:00:16
引言:本此專案為參加醫學資料探勘演演算法評測大賽所寫,所有資料均來自大賽官方,僅供學習交流使用,如有冒犯請留言博主。另感謝許玉龍博主的指導。
內容概述
一、專案描述
1、賽題描述
一、賽題描述
公眾健康問句分類
基於給出的與健康有關的中文問句,對問句的主題進行分類(共包含 6 個大類:A 診斷、B 治療、C 解剖學/生理學、D 流行病學、E 健康生活方式、F 擇醫)。由於一箇中文健康問句往往歸屬於多個主題類別,因此該自動分類任務是一個多標籤分類的問題(Multilabel Classification)。
2、資料描述
訓練集:共 5,000 條與健康有關的中文提問資料,格式如下:
| 欄位名稱 | 資料型別 | 說明 | 類別含義 |
|---|---|---|---|
| ID | Sring | 資料的唯一標識 | 無 |
| Question Sentence | String | 0 或 1,0 代表不屬於該類別,1 代表屬於該類別 | 無 |
| category_A(診斷) | int | 0 或 1,0 代表不屬於該類別,1 代表屬於該類別 | 與診斷有關的問題,包括詢問對病因或臨床發現的解釋,疾病診斷標準或疾病的臨床表現,檢驗檢查,疾病或情況介紹等 |
| category_B(治療) | int | 0 或 1,0 代表不屬於該類別,1 代表屬於該類別 | 與治療有關的問題,包括詢問藥物的用法用量,藥物的選擇、適應症和效力,藥物副作用與不良反應,用藥禁忌與注意事項,藥物相互作用,以及其他治療方法等。 |
| category_C(解剖學/生理學) | int | 0 或 1,0 代表不屬於該類別,1 代表屬於該類別 | 與解剖學/生理學有關的問題,包括詢問人體組織器官、人體代謝等。 |
| category_D(流行病學 | int | 0 或 1,0 代表不屬於該類別,1 代表屬於該類別 | 與流行病學有關的問題,包括詢問疾病患病率或發病率,病因學、病原學、疾病影響,疾病程序、預後/並行症、後遺症等。 |
| category_E(健康生活方式) | int | 0 或 1,0 代表不屬於該類別,1 代表屬於該類別 | 與健康生活方式有關的問題,包括飲食、運動、減肥、壓力和情緒管理等 |
| category_F(擇醫) | int | 0 或 1,0 代表不屬於該類別,1 代表屬於該類別 | 與擇醫有關的問題,包括詢問醫療機構選擇、醫療科室選擇、醫生選擇等。 |
3、資料樣例
欄位名稱 欄位範例
| ID | QC0000000012 |
|---|---|
| Question Sentence | 總膽固醇 7.38,屬於什麼程度?病情描述(發病時間、主要症狀、症狀變化等):1,2 年曆史,有輕度腦梗。年齡 67.謝謝。在服瑞舒伐他汀,隔日一片。行嗎? |
| category_A(診斷) | 1 |
| category_B(治療) | 1 |
| category_C(解剖學/生理學) | 0 |
| category_D(流行病學) | 0 |
| category_E(健康生活方式) | 0 |
| category_F(擇醫) | 0 |

4、解決思路
a、對所有問題正則匹配去除非漢字部分
b、統計所有不同的字。並建立字典
c、將訓練資料根據字典轉化為矩陣
d、搭建神經網路
c、訓練資料,並完成預測
e、獲取訓練指標
二、程式碼實現
1、資料清理處理
import pandas as pd
import numpy as np
import re
import torch
import torch.nn.functional as F
CSV_FILE_PATH_TRAIN = 'D:/alltrain/train.csv' #訓練集
dfTrain = pd.read_csv(CSV_FILE_PATH_TRAIN)
#正則匹配,清除非漢字部分
def findChinese(sentence):
pattern = re.compile(r'[^\u4e00-\u9fa5]')
sentence = re.sub(pattern, '', sentence)
return sentence
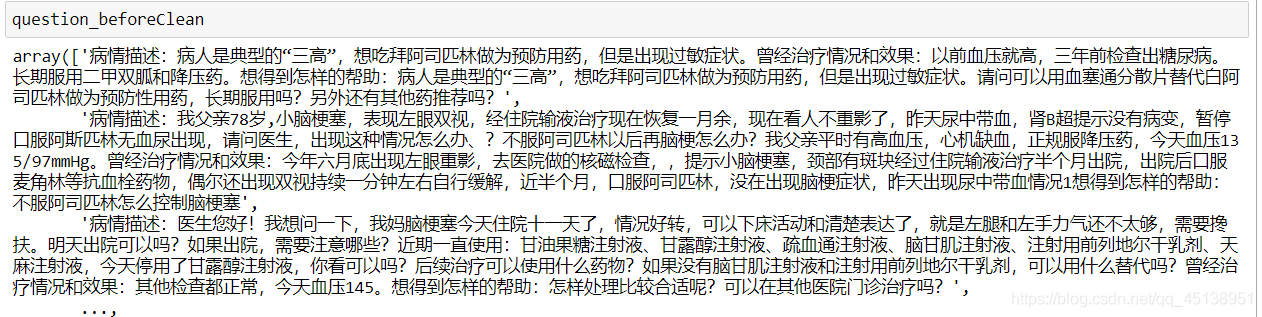
question_beforeClean = np.array(dfTrain.iloc[:, dfTrain.shape[1] - 1])
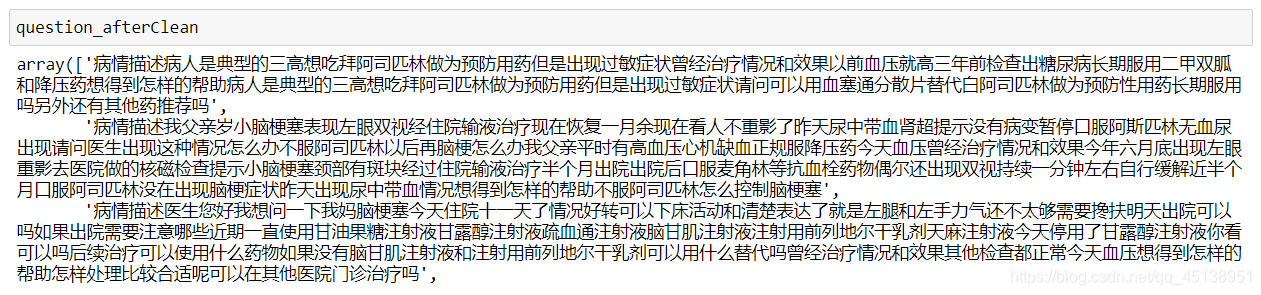
question_afterClean = np.array([findChinese(x) for x in question_beforeClean])
question_beforeClean
question_afterClean
2、建立字典
def getDifferentWord(data):#獲取所有不同的字
dic_key = []
for question in data:
for tip in list(question): #將整局話分解成單個的字元
if tip not in dic_key:
dic_key.append(tip)
return dic_key
dic_key = getDifferentWord(question_afterClean)
dic_key前15個元素

dic = {} #生成字典,每個字對應一個數值
value = 0
for key in dic_key:
dic[key] = value
value += 1
dic

3、生成訓練矩陣
#找到最長的句子的長度,作為訓練矩陣的維度
def findDimension(data):
dimension = np.max([len(list(x)) for x in data])
return dimension
dimension = findDimension(question_afterClean) #最大維度為1622
X = np.zeros((len(question_afterClean), dimension)) #生成都是零的矩陣 5000 * 1622
#獲取單個問題所有文字在字典中對應的值
def getValues(sentence, dic):
result = []
for word in list(sentence):
result.append(dic.get(word))
return np.array(result)
for i in range(len(question_afterClean)):
X[i][:len(list(question_afterClean[i]))] = getValues(question_afterClean[i], dic)
y = np.array(dfTrain.iloc[:,1:7]) #6類標籤
X 5000 * 1622
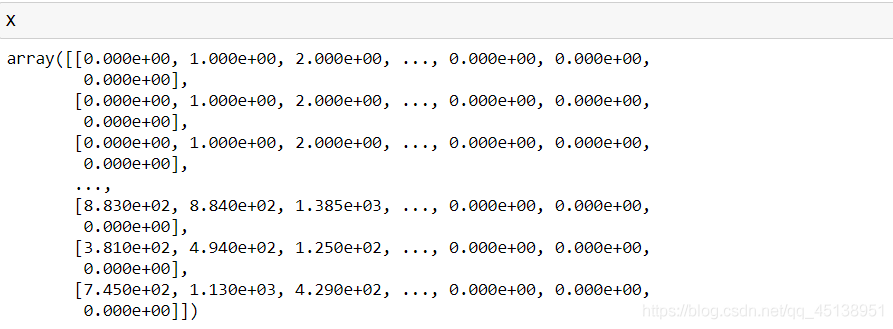
y 5000 * 6

4、用pytorch框架搭建神經網路(使用GPU進行運算)
if torch.cuda.is_available():
device = torch.device("cuda") # a CUDA device object 若不使用GPU可將所有涉及gpu資料轉換的程式碼刪除即可
def changeType(X_data, y_data): #將array資料轉化為longTensor, pytorch 檔案規定
return torch.from_numpy(X_data).float(), torch.from_numpy(y_data).float()
X_train = X
y_train = y
X_torch_train, y_torch_train = changeType(X_train, y_train)
class Net(torch.nn.Module):
def __init__(self, n_feature, n_hidden, n_output):
super(Net, self).__init__() # 繼承 __init__ 功能
self.hidden = torch.nn.Linear(n_feature, n_hidden) # 隱藏層線性輸出
self.out = torch.nn.Linear(n_hidden, n_output) # 輸出層線性輸出
def forward(self, x):
# 正向傳播輸入值, 神經網路分析出輸出值
x = F.relu(self.hidden(x)) # 激勵函數(隱藏層的線性值)
x = self.out(x) # 輸出值, 但是這個不是預測值, 預測值還需要再另外計算
return x
5、訓練資料並預測資料
net=Net(n_feature=X_train.shape[1], n_hidden=1000, n_output=6) #1622 個輸入 1層隱藏層 1000個神經元 6個輸出
net = net.cuda() #將net遷移至gpu
optimizer = torch.optim.SGD(net.parameters(), lr=0.02) # 傳入 net 的所有引數, 學習率
loss_func = torch.nn.BCEWithLogitsLoss()#BCEWithLogitsLoss()針對多標籤分類 整合sigmoid,輸出的為概率
loss_func = loss_func.cuda() #將損失函數遷移至gpu
X_torch_train, y_torch_train = X_torch_train.cuda(), y_torch_train.cuda() #將訓練集遷移至gpu
#%%time
for t in range(2000): #訓練1000此
out = net(X_torch_train) # 餵給 net 訓練資料 X_torch_train, 輸出分析值
loss = loss_func(out, y_torch_train) # 計算兩者的誤差
optimizer.zero_grad() # 清空上一步的殘餘更新引數值
loss.backward() # 誤差反向傳播, 計算引數更新值
optimizer.step() # 將引數更新值施加到 net 的 parameters 上
net = net.cpu() #訓練後需將net遷移至cpu否則無法運算
def predict(X_test): #用於轉換輸出值為標籤
test_out = net(X_test)
predictRs = F.sigmoid(test_out).data.numpy() > 0.5 #新版本也可用torch.sigmoid
predictRs = predictRs.astype(np.int32)
return predictRs
X_torch_train, y_torch_train = X_torch_train.cpu(), y_torch_train.cpu() #將資料遷移至cpu
y_pred = predict(X_torch_train) #獲得預測資料
6、獲取指標
準確率
from sklearn.metrics import accuracy_score
accuracySet = []
for i in range(6):
accuracySet.append(accuracy_score(y_train[:,i], y_pred[:,i]))
accuracySet
精準率
from sklearn.metrics import precision_score
precisionSet = []
for i in range(6):
precisionSet.append(precision_score(y_train[:,i], y_pred[:,i]))
precisionSet
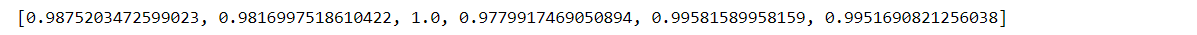
召回率
from sklearn.metrics import recall_score
recallSet = []
for i in range(6):
recallSet.append(recall_score(y_train[:,i], y_pred[:,i]))
recallSet

F1-score
from sklearn.metrics import f1_score
f1Set = []
for i in range(6):
f1Set.append(f1_score(y_train[:,i], y_pred[:,i]))
f1Set
f1Set

6類平均F1-score
def getF1Score(y_test, y_pred):
totalF1 = 0
for i in range(y_test.shape[1]):
totalF1 += f1_score(y_test[:,i], y_pred[:,i])
print(f1_score(y_test[:,i], y_pred[:,i]))
return totalF1 / y_test.shape[1]
getF1Score(y_train, y_pred)
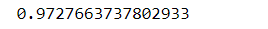
!!!!由於第三個標籤中只有一個為一,若模型學習不到,則平均F1為0.72左右