【資料結構Python描述】優先順序佇列描述「銀行VIP客戶插隊辦理業務」及「被插隊客戶憤而離去」的模型實現
文章目錄
【資料結構Python描述】優先順序佇列簡介及Python手工實現給出了優先順序佇列ADT的典型方法,這些方法對於如排序等常見應用已經足夠,但在如下述的一些場景中,仍需要對優先順序佇列的ADT所包含的方法進行擴充:
- 一位土豪正在某銀行排隊辦理業務,在等待過程中土豪突然發現自己是該行的VIP,在告知工作人員後,該土豪的排隊優先順序被提至最高;
- 本來排在土豪前面準備存錢的普通客戶見狀便找工作人員理論,後者告知前者土豪是VIP,根據該行規定有權享受這樣的待遇,普通客戶見溝通無果便要求刪除自己取的號,然後憤而離去將存款存到了隔壁銀行。
如果你想要直接體驗實現上述情景的程式碼,請直接跳至第四部分。
一、支援插隊模型的優先順序佇列
佇列ADT擴充
分別對應上述兩種情況,還需要在一般優先順序佇列ADT的基礎上對其進行擴充,以增加下列兩個方法:
update(item, key, value):將item中的key和value範例屬性進行更新替換;remove(item):從優先順序佇列中刪除item並返回(key, value)。
佇列記錄描述
需要注意的是,由於update()和remove()方法的執行都有賴於先在優先順序佇列中找到對應的item,為了避免需要遍歷儲存所有item的列表,這裡需要對item範例所屬的類_Item進行升級,即為在其鍵值對(key, value)的基礎上增添該條記錄在列表中的索引idx,即一個item物件具有三個範例屬性(key, value, idx)。
方法理論步驟
為了使得後續給出的上述兩個新增方法的實現更容易理解,下面通過具體案例先從理論上分析每一個方法操作的步驟。
首先,假設分別通過以下兩種形式給出一個已有的優先順序佇列的所有記錄集合:
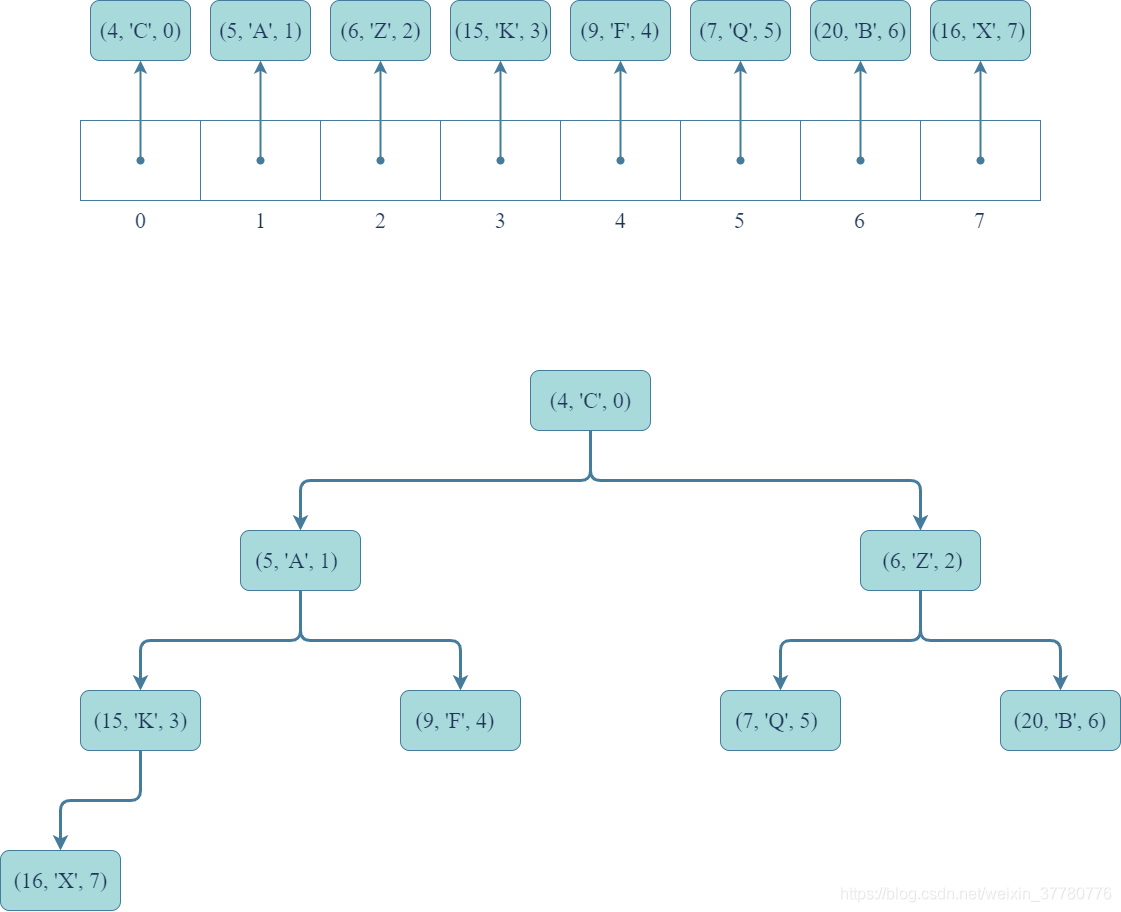
update(item, key, value)
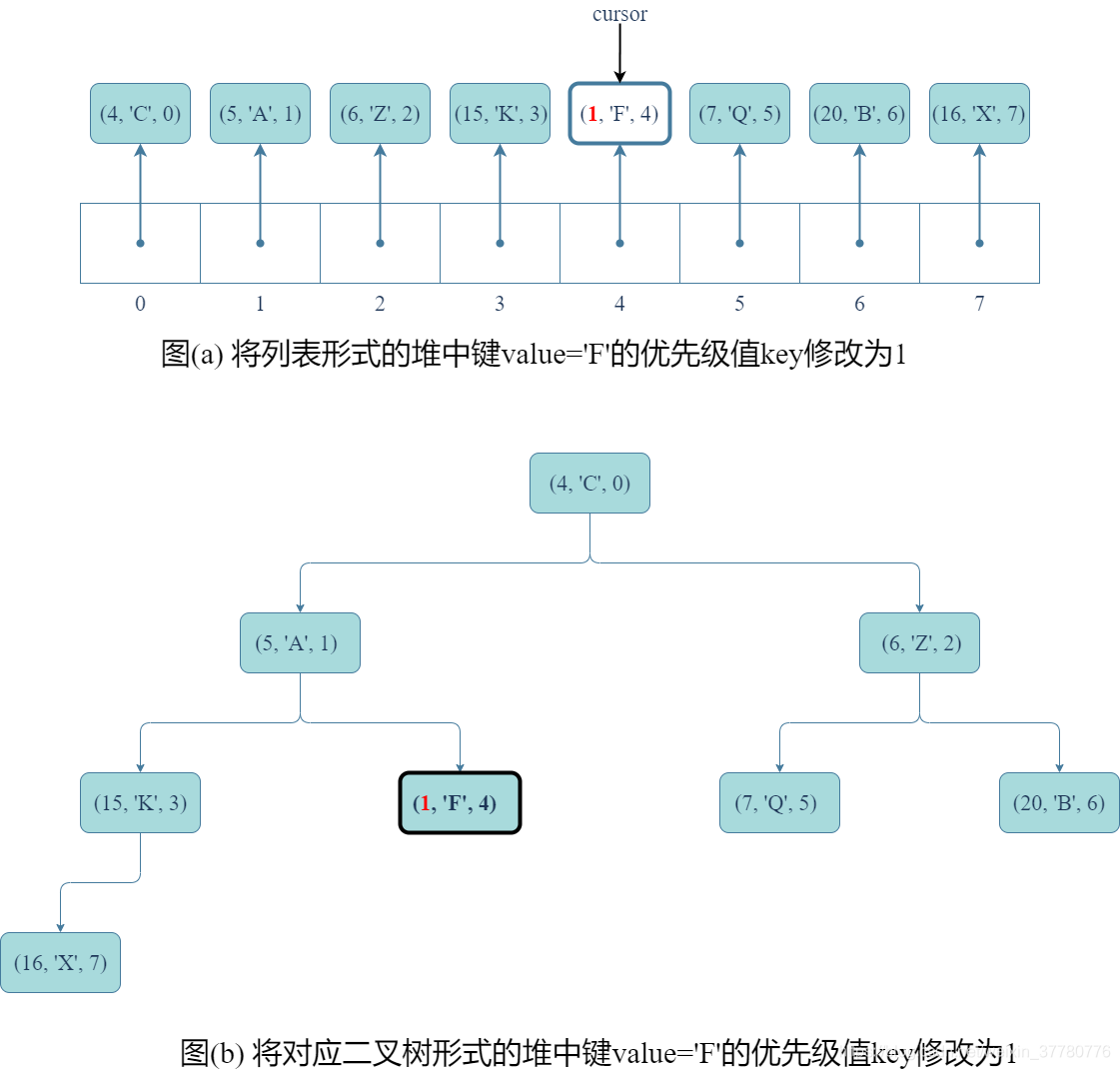
如果cursor = Item(9, 'F', 4),則執行q.update(cursor, 1, 'F')的具體步驟如下:
- 首先,如圖(a)和(b)所示,將
cursor所參照記錄(9, 'F', 4)中的鍵修改為1(也可以此時同時修改值'F'為任意物件)。
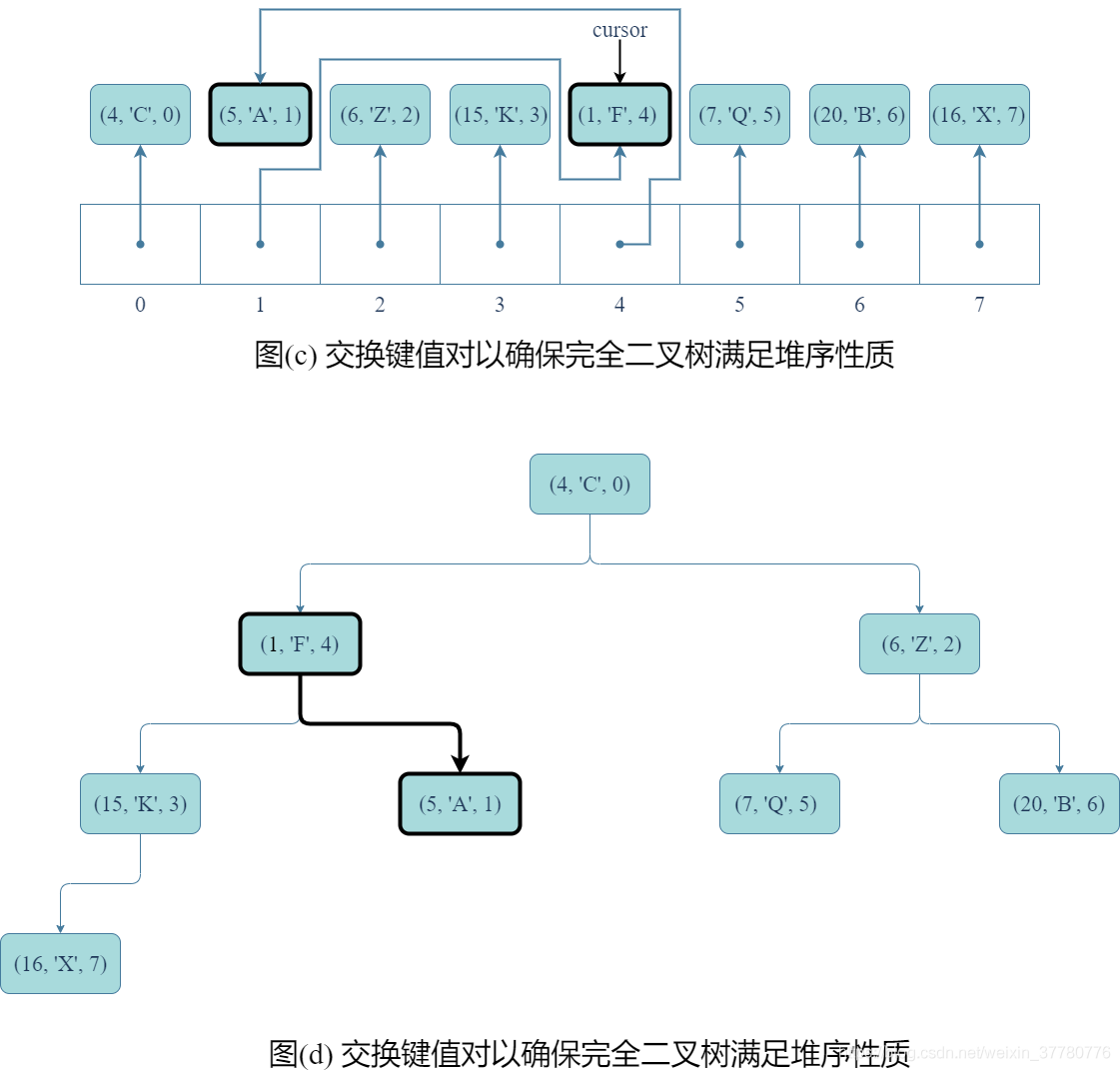
- 其次,如圖(c)和(d)所示,為確保優先順序佇列某記錄的鍵值修改後,底層的完全二元樹仍然是一個堆,需要進行結點間記錄的交換;
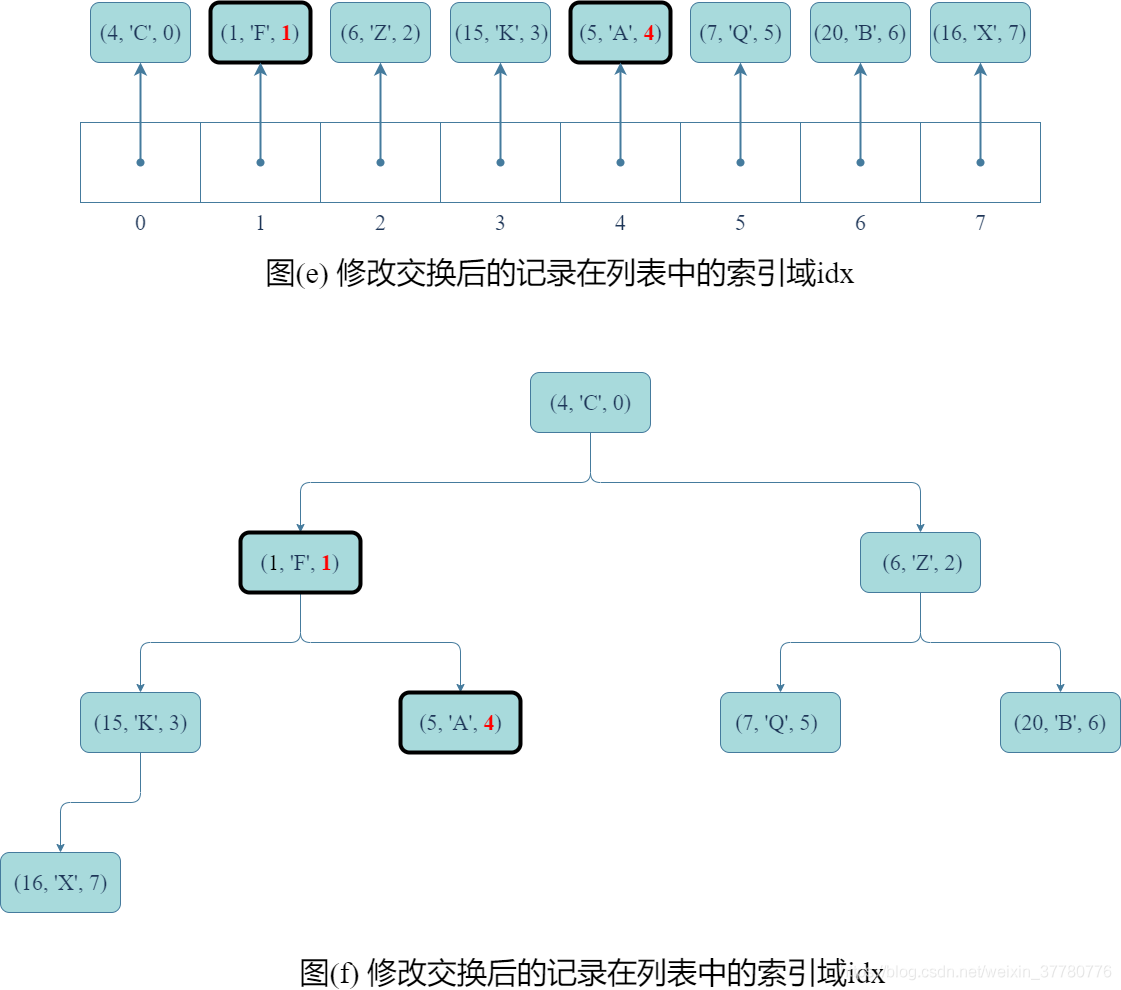
- 然後,如圖(e)和(f)所示,為了使得交換後的記錄的
idx域都如實反應該條記錄在列表中的索引,需要分別修改兩條記錄的idx;
- 接著,重複圖©、(d)、(e)、(f)的步驟直到完全二元樹滿足堆序性質且每條
(key, value, idx)記錄的idx域均如實反應該條記錄在列表的位置。
remove(item)
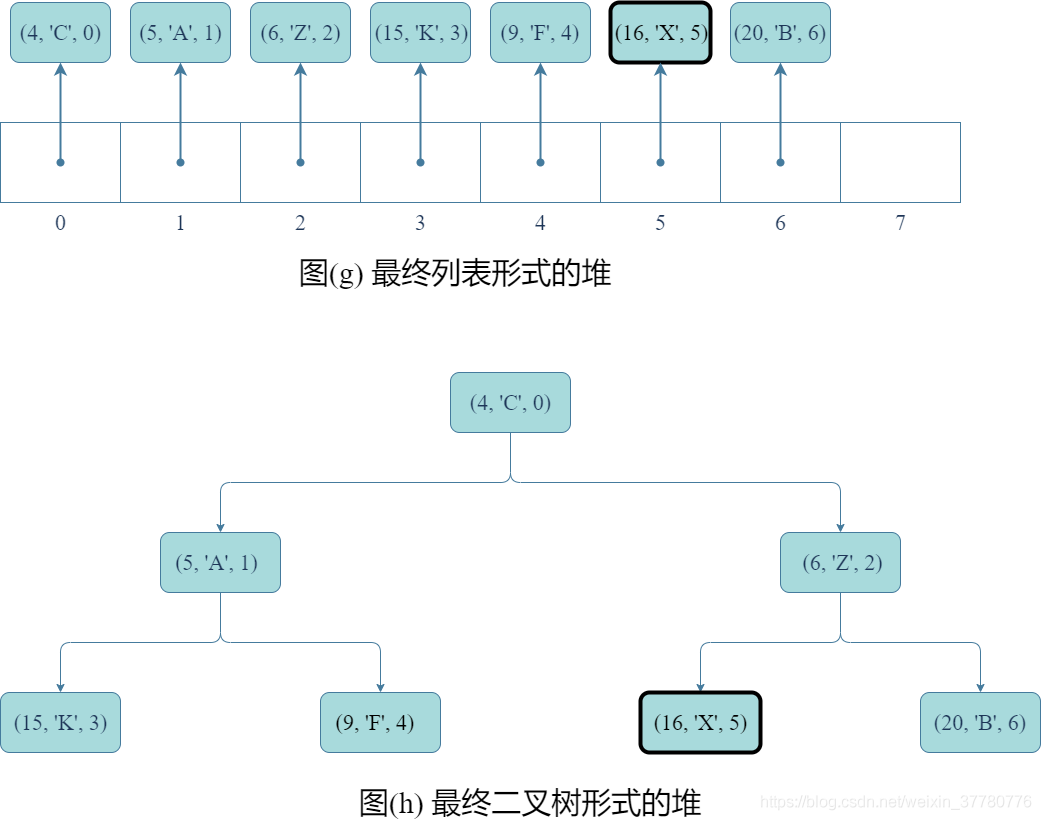
下面還是以本節一開始的案例分析該方法操作的理論步驟,即如果item= Item(9, 'F', 4),則執行q.remove(item)的具體步驟如下:
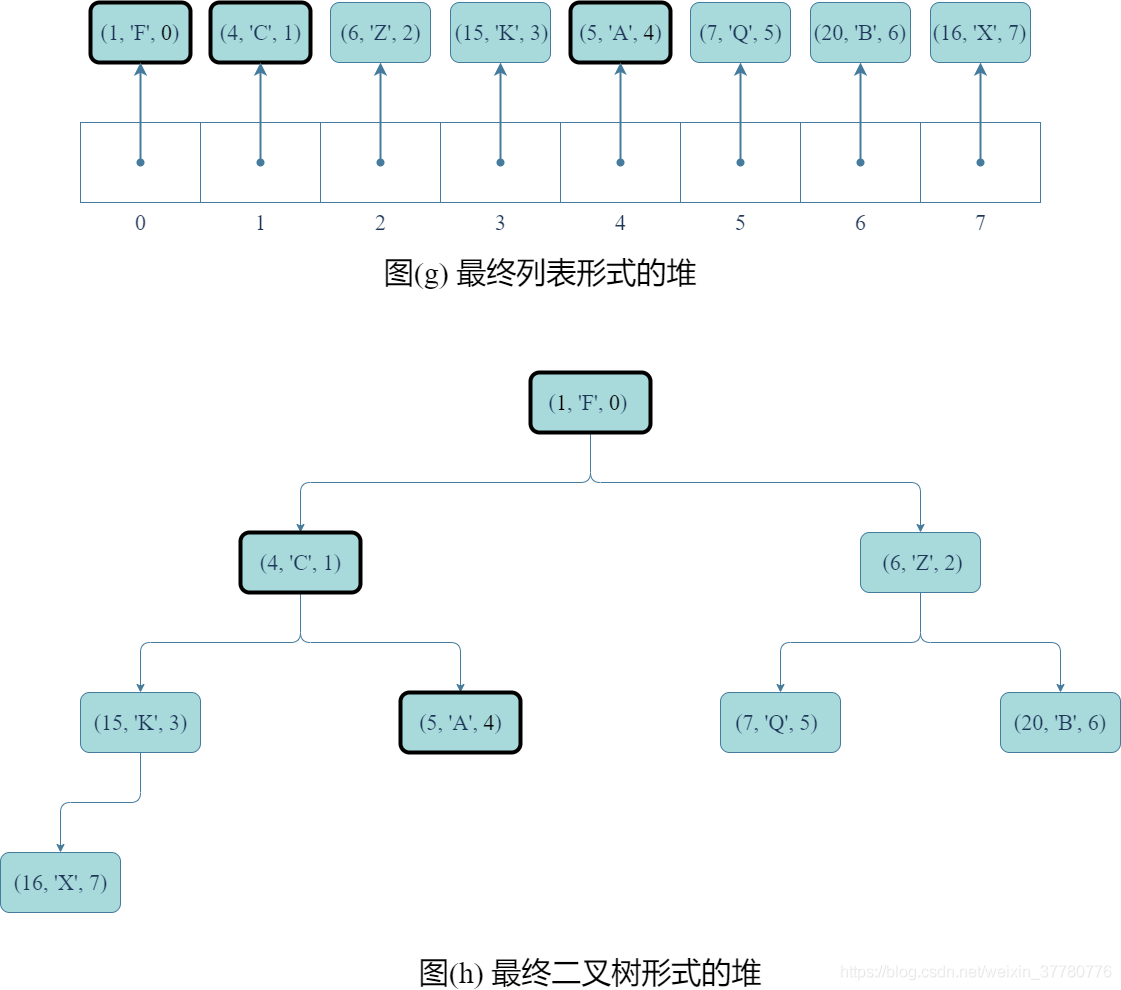
- 首先,如圖(a)和(b)所示,將要刪除的記錄交換至列表尾部(即完全二元樹最底層最右側結點處);
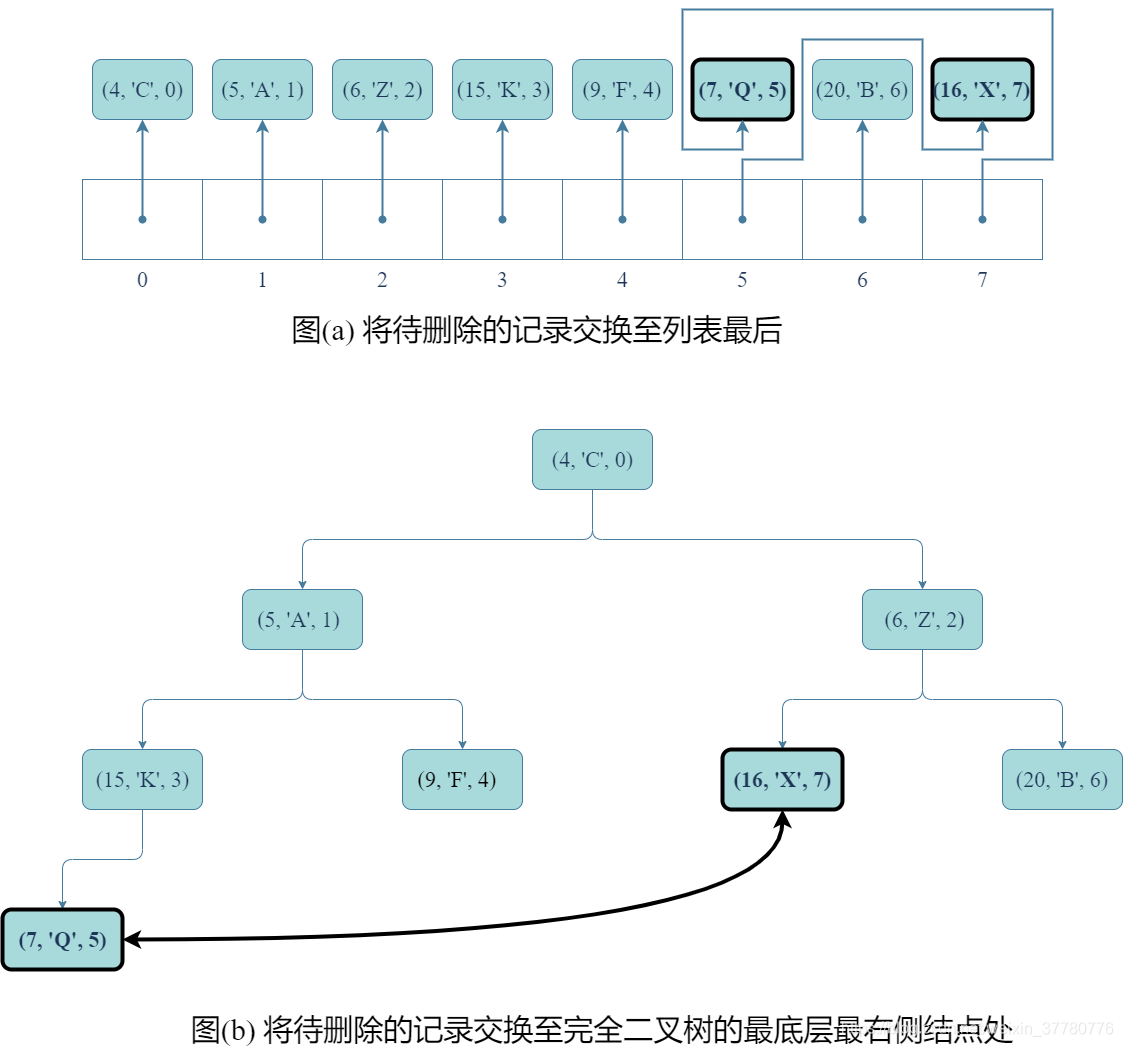
- 其次,如圖©和(d)所示,類似上述分析
update()方法,交換記錄後需要修改記錄的idx域;
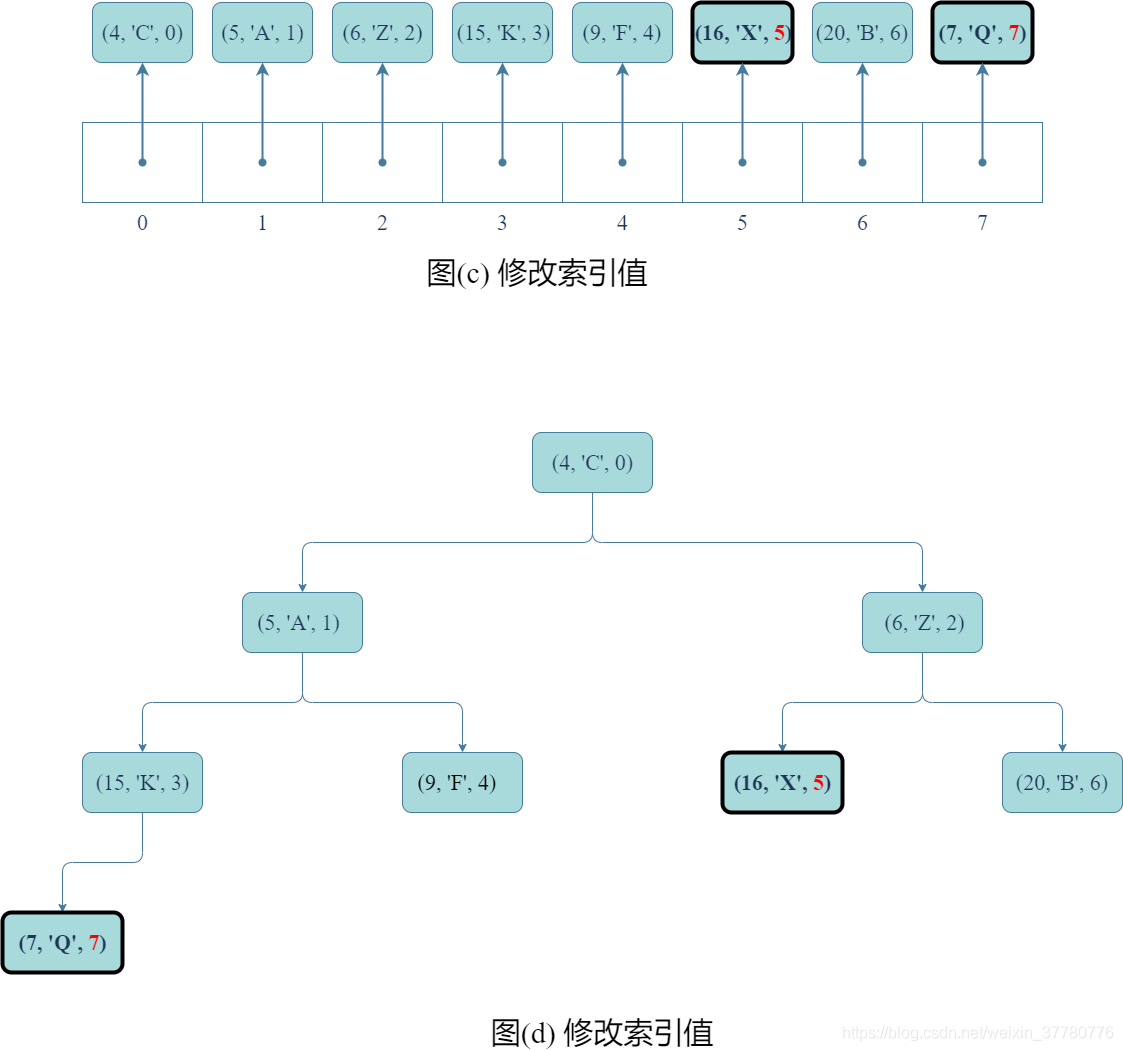
- 然後,如圖(e)和(f)所示,刪除列表尾部元素,實際上只要呼叫列表的
pop()方法即可;
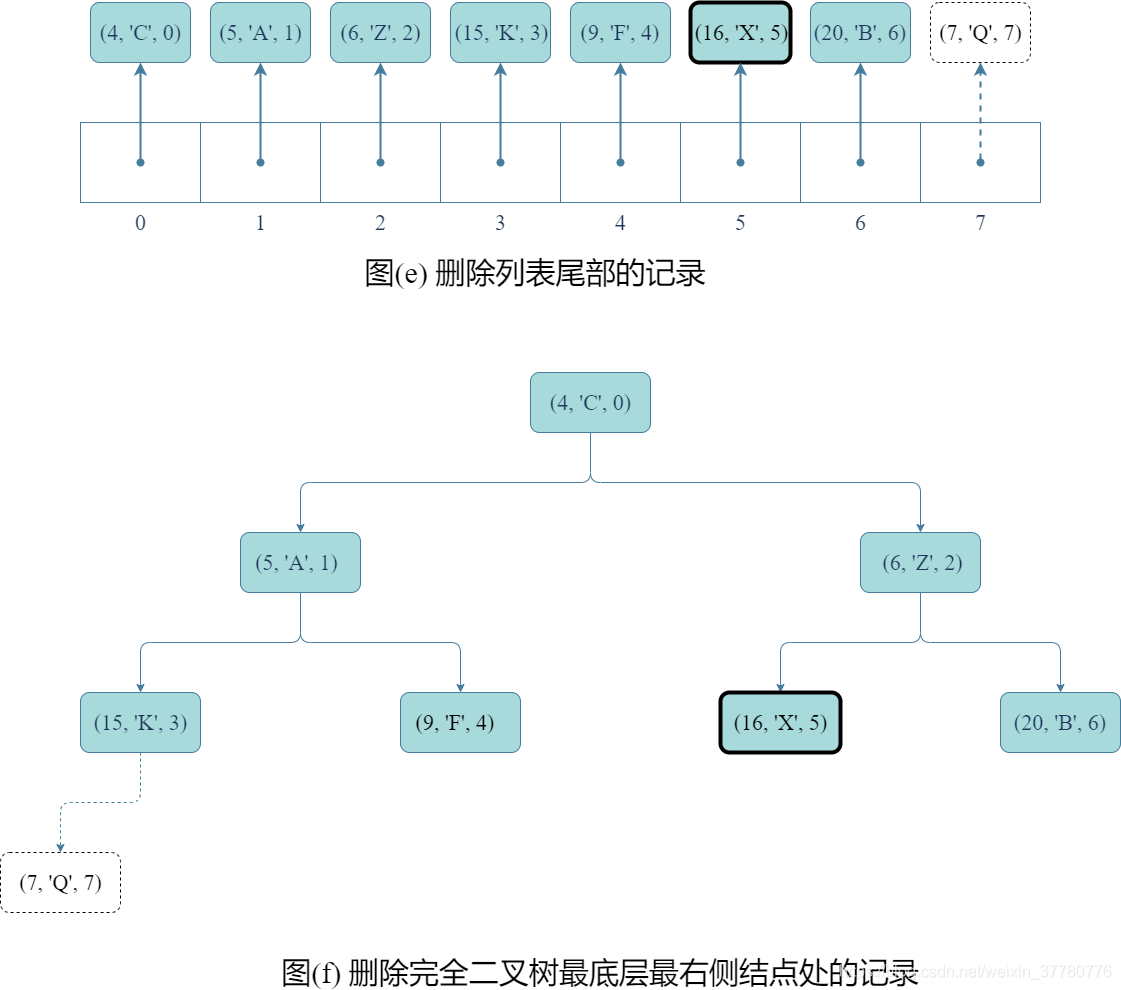
- 最後,得到如圖(g)和(h)所示的結果。實際上,如果上述(e)和(f)所示步驟結束後完全二元樹不滿足堆序性質,則還需像分析
update()方法時一樣,重複圖©、(d)、(e)、(f)的步驟。
二、支援插隊模型的優先順序佇列實現
基於上述分析,本節將通過繼承【資料結構Python描述】樹堆(heap)簡介和Python手工實現及使用樹堆實現優先順序佇列中實現的HeapPriorityQueue來實現支援插隊模型的優先順序佇列AdaptablePriorityQueue。
Item
首先,需要對描述優先順序佇列中每一條記錄的類_Item進行如下所示的升級
from heap_priority_queue import HeapPriorityQueue
class Item(HeapPriorityQueue._Item):
"""用於儲存優先順序佇列每一條記錄的鍵、值以及鍵值在列表中索引的類"""
def __init__(self, key, value, idx):
super().__init__(key, value)
self.idx= idx
也就是說,後續優先順序佇列底層的列表儲存的是一系列Item範例,每一個範例均儲存了key、value以及當前範例在列表中的索引idx,對於使用者向優先順序佇列中成功插入的每一對(key, value),都會得到一個Item範例的參照,如圖分析update()方法時提到中的cursor。
_swap(i, j)
在HeapPriorityQueue中實現過了該方法,此處需重寫該方法使得(key, value, idx)形式的記錄的idx域如實反應該記錄當前在列表中的位置:
def _swap(self, i, j):
"""重寫父類別方法"""
super()._swap(i, j)
self._data[i].idx = i
self._data[j].idx = j
_bubble(j)
由於呼叫update()方法之後,某結點處記錄按照鍵的大小既可能需要下沉也可能需要上浮,因此將繼承自HeapPriorityQueue的結點記錄上浮方法(_upheap())和下沉方法(_downheap())封裝進一個方法_bubble()中。
def _bubble(self, i):
"""
對優先順序佇列的記錄進行向上或向下冒泡,確保完全二元樹滿足堆序性質
:param i: 記錄在列表中的索引
:return: None
"""
if i > 0 and self._data[i] < self._data[self._parent(i)]:
self._upheap(i)
else:
self._downheap(i)
add(key, value)
該方法繼承自HeapPriorityQueue,此處僅重寫後返回新增記錄的參照,供傳入update()和remove()方法中使用:
def add(self, key, value):
"""
重寫父類別方法,在實現父類別方法功能的基礎上,返回新增記錄的參照
:param key: 鍵
:param value: 值
:return: 新增Item物件的參照
"""
cursor = self.Item(key, value, len(self._data)) # 封裝鍵值對物件
self._data.append(cursor)
self._upheap(len(self._data) - 1)
return cursor
update(item, key, value)
該方法需要最終呼叫上述_bubble()方法以確保最終的完全二元樹仍然是一個堆:
def update(self, item, key, value):
"""
更新item的key和/或value
:param item: Item類一個範例物件的參照
:param key: 鍵
:param value: 值
:return: None
"""
i = item.idx
if not (0 <= i < len(self) and self._data[i] is item):
raise ValueError('給定的Item範例無效!')
item.key = key
item.value = value
self._bubble(i)
remove(item)
實現如下:
def remove(self, item):
"""
刪除item參照的物件,並返回(key, value)
:param item: Item類一個範例物件的參照
:return: (key, value)
"""
i = item.idx
if not (0 <= i < len(self) and self._data[i] is item):
raise ValueError('給定的Item範例無效!')
if i == len(self) - 1: # 直接刪除即可
self._data.pop()
else:
self._swap(i, len(self) - 1)
self._data.pop()
self._bubble(i)
return item.key, item.value
三、支援插隊模型的優先順序佇列複雜度分析
針對上述實現的AdaptableHeapPriorityQueue,其各方法的最壞時間複雜度如下表所示:
| ADT方法 | 時間複雜度 |
|---|---|
__len__(q)、q.is_empty()、q.min() | O ( 1 ) O(1) O(1) |
p.add(key, value) | O ( l o g ( n ) ) O(log(n)) O(log(n))1 |
q.update(item, key, value) | O ( l o g ( n ) ) O(log(n)) O(log(n)) |
q.remove(item) | ( l o g ( n ) ) (log(n)) (log(n))1 |
q.remove_min() | O ( l o g ( n ) ) O(log(n)) O(log(n))1 |
四、支援插隊模型的優先順序佇列程式碼測試
下面是使用上述實現的AdaptableHeapPriorityQueue模擬「銀行VIP客戶插隊辦理業務」及「被插隊客戶憤而離去」的完整程式碼:
# adaptable_heap_priority_quue.py
from heap_priority_queue import HeapPriorityQueue
class AdaptableHeapPriorityQueue(HeapPriorityQueue):
"""使用二元堆積實現的可進行Item範例刪除和更新操作的優先順序佇列"""
class Item(HeapPriorityQueue._Item):
"""用於儲存優先順序佇列每一條記錄的鍵、值以及鍵值在列表中索引的類"""
def __init__(self, key, value, index):
super().__init__(key, value)
self.idx = index
def _swap(self, i, j):
"""重寫父類別方法"""
super()._swap(i, j)
self._data[i].idx = i
self._data[j].idx = j
def _bubble(self, i):
"""
對優先順序佇列的記錄進行向上或向下冒泡,確保完全二元樹滿足堆序性質
:param i: 記錄在列表中的索引
:return: None
"""
if i > 0 and self._data[i] < self._data[self._parent(i)]:
self._upheap(i)
else:
self._downheap(i)
def add(self, key, value):
"""
重寫父類別方法,在實現父類別方法功能的基礎上,返回新增記錄的參照
:param key: 鍵
:param value: 值
:return: 新增Item物件的參照
"""
cursor = self.Item(key, value, len(self._data)) # 封裝鍵值對物件
self._data.append(cursor)
self._upheap(len(self._data) - 1)
return cursor
def update(self, item, key, value):
"""
更新item的key和/或value
:param item: Item類一個範例物件的參照
:param key: 鍵
:param value: 值
:return: None
"""
i = item.idx
if not (0 <= i < len(self) and self._data[i] is item):
raise ValueError('給定的Item範例無效!')
item.key = key
item.value = value
self._bubble(i)
def remove(self, item):
"""
刪除item參照的物件,並返回(key, value)
:param item: Item類一個範例物件的參照
:return: (key, value)
"""
i = item.idx
if not (0 <= i < len(self) and self._data[i] is item):
raise ValueError('給定的Item範例無效!')
if i == len(self) - 1: # 直接刪除即可
self._data.pop()
else:
self._swap(i, len(self) - 1)
self._data.pop()
self._bubble(i)
return item.key, item.value
if __name__ == '__main__':
q = AdaptableHeapPriorityQueue()
cursor1 = q.add(4, '憤憤不平普通客戶')
cursor2 = q.add(5, '普通客戶1')
cursor3 = q.add(6, '普通客戶2')
cursor4 = q.add(15, '普通客戶3')
cursor5 = q.add(9, '暫不知自己是VIP的土豪客戶')
cursor6 = q.add(7, '普通客戶4')
cursor7 = q.add(20, '普通客戶5')
cursor8 = q.add(16, '普通客戶6')
print(q) # [(4, '憤憤不平普通客戶'), (5, '普通客戶1'), (6, '普通客戶2'), (15, '普通客戶3'), (9, '暫不知自己是VIP的土豪客戶'), (7, '普通客戶4'),
# (20, '普通客戶5'), (16, '普通客戶6')]
print('按上述順序,下一個辦理業務的應該是:', q.min()[1]) # 按上述順序,下一個辦理業務的應該是:憤憤不平普通客戶
q.update(cursor5, 1, '意識到自己是VIP的土豪客戶') # 修改cursor5參照的記錄的優先順序,即土豪插隊
print('VIP土豪插隊後下一個辦理業務的是:', q.min()[1]) # VIP土豪插隊後下一個辦理業務的是: 意識到自己是VIP的土豪客戶
q.remove(cursor1) # '憤憤不平普通客戶'要求刪除自己取的號
print(q) # [(1, '意識到自己是VIP的土豪客戶'), (5, '普通客戶1'), (6, '普通客戶2'), (15, '普通客戶3'), (16, '普通客戶6'), (7, '普通客戶4'), (20,
# '普通客戶5')]