python爬蟲程式碼更新
2020-10-11 15:00:14
昨天和室友看《Python 金融巨量資料挖掘與分析全流程詳解》第67,68頁的程式碼時,發現網頁已經更新了,程式碼執行錯誤。
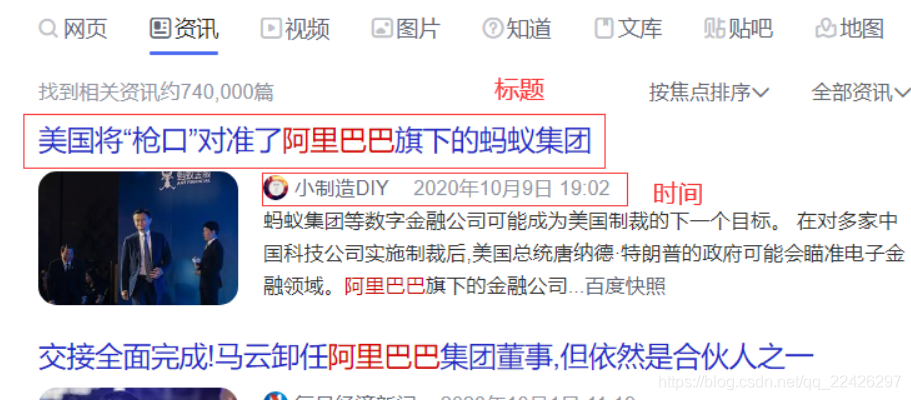
先看結果,

大致由三部分組成,標題,時間,和連結。
開啟爬蟲的網頁
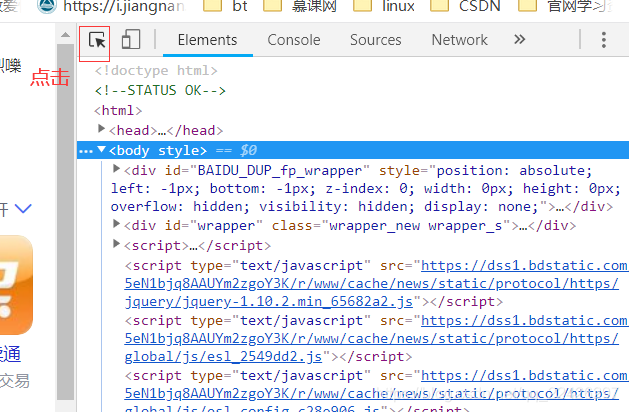
缺個連結,按f12,開啟開發者工具
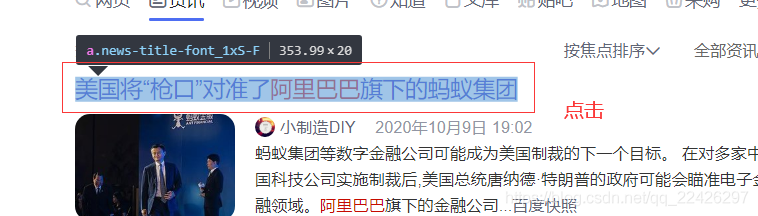
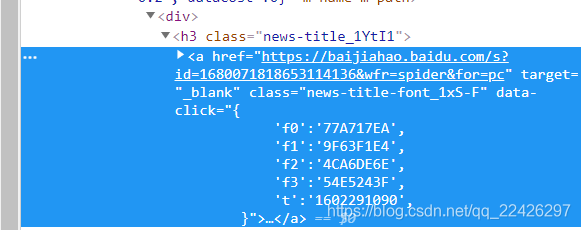
在開發者工具上面出現這個網頁程式碼,這個截圖結果可能在網頁右邊,也可能在下面
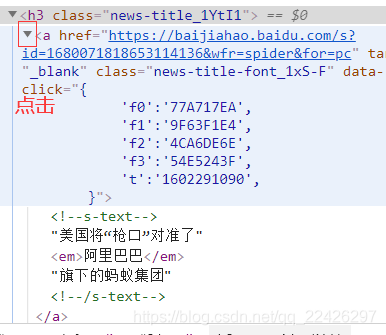
這樣大家都發現了,連結和標題都有了,可以寫正則
p_href = '<h3 class=".*?"><a href="(.*?)"' href = re.findall(p_href, res, re.S) p_title = '<h3 class=".*?">.*?>(.*?)</a>' title = re.findall(p_title, res, re.S)
還剩下時間和作者,繼續按照上面的方式查詢

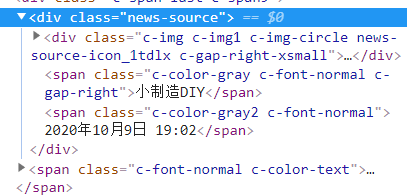
這樣一來,就發現了作者和時間繼續正則
p_info = '<span class="c-color-gray.*?">(.*?)</span>' info = re.findall(p_info, res, re.S)
最後再上完整程式碼,
import requests
import re
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)'
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'}
url = 'https://www.baidu.com/s?rtt=1&bsst=1&cl=2&tn=news&word=阿里巴巴&x_bfe_rqs=03E80&x_bfe_tjscore=0.596217&tngroupname=organic_news&newVideo=12&rsv_dl=news_b_pn&pn=20'
res = requests.get(url, headers=headers).text
# https://www.baidu.com/s?rtt=1&bsst=1&cl=2&tn=news&word=阿里巴巴&x_bfe_rqs=03E80&x_bfe_tjscore=0.596217&tngroupname=organic_news&newVideo=12&rsv_dl=news_b_pn&pn=20
p_info = '<span class="c-color-gray.*?">(.*?)</span>'
info = re.findall(p_info, res, re.S)
p_href = '<h3 class=".*?"><a href="(.*?)"'
href = re.findall(p_href, res, re.S)
p_title = '<h3 class=".*?">.*?>(.*?)</a>'
title = re.findall(p_title, res, re.S)
source = []
date = []
for i in range(len(title)):
title[i] = title[i].strip()
title[i] = re.sub('<.*?>', '', title[i])
info[i] = re.sub('<.*?>', '', info[i])
source.append(info[2*i])
date.append(info[2*i+1])
source[i] = source[i].strip()
date[i] = date[i].strip()
print(str(i + 1) + '.' + title[i] + '(' + date[i] + '-' + source[i] + ')')
print(href[i])
在最後,希望大家不要照搬書本,自己好好分析,打好基礎,加油。