合併排序演演算法——時間複雜度詳解和python程式碼實現
遞迴形式
遞迴形式是演演算法中常用到的一種構造思路。遞迴允許函數或過程對自身進行呼叫,是對演演算法中重複過程的高度概括,從本質層面進行刻畫,避免演演算法書寫中過多的巢狀迴圈和分支語法。因此,是對演演算法結構很大的簡化。
遞迴形式實際可以看做一個函數表示式:
f
(
n
)
=
G
(
f
(
g
(
n
)
)
)
f(n)=G(f(g(n)))
f(n)=G(f(g(n))),即
f
(
n
)
f(n)
f(n)可以通過一個
f
(
g
(
n
)
)
f(g(n))
f(g(n))的表示式間接推出。當然,如果遞迴式可解,則最後也能將
f
(
n
)
f(n)
f(n)直接用n表示出來。
如:
f
(
n
)
=
f
(
n
−
1
)
+
n
f(n)=f(n-1)+n
f(n)=f(n−1)+n (1)
f
(
n
)
=
f
(
n
2
)
+
n
f(n)=f(\frac{n}{2})+n
f(n)=f(2n)+n (2)
f
(
n
)
=
f
(
n
1
)
+
f
(
n
2
)
+
.
.
.
+
f
(
n
k
)
f(n)=f(n_1)+f(n_2)+...+f(n_k)
f(n)=f(n1)+f(n2)+...+f(nk) (3)
可以想到,如果執行時間可以用這樣的遞迴表示式,那麼求解
f
(
n
)
f(n)
f(n)可能會相對簡單。
遞迴形式分為線性遞迴、二分遞迴、多分支遞迴等。
在上面舉例中,(1)式即為線性遞迴(該遞迴關係實際上描述了求和過程);(2)式即為二分遞迴(後面會看到,該關係實際描述了合併排序過程)。(3)式即為多分支迴歸,即每次分成的子問題規模不一定相同。將這些遞迴形式應用於演演算法中,就形成了遍歷、減治、分治等演演算法策略。此處重點討論分治法,並且僅關注分治法應用於排序問題中的一種經典演演算法:合併排序。
合併排序
基本思想:分治法
分治法是把一個規模較大的問題分成若干個規模較小的問題,並遞迴的對這些問題進行求解,當問題規模足夠小時,可以直接求解。最終將這些規模小問題的求解結果遞迴的合併,建立原問題的解。
使用分治法的意義之一是,這樣容易求出演演算法的時間複雜度,有很多方法可以套用。可以達成這樣目標的一個前提是,1.執行時間可以用一個遞迴式表示;2.分解到最後,規模足夠小的子問題應當是常數時間就可以求解的,否則還是沒法簡化時間複雜度的計算。
在排序過程中,主要分成兩個步驟:首先,將n個數用二分遞迴分解,直到每個子問題規模為1。再將這些子問題遞迴的合併,合併就是一個排序的過程。
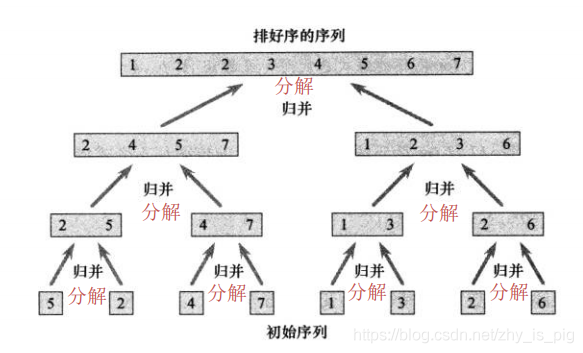
下面以一個排序問題舉例:對A=(3,2,4,6,1,5,7,8)用合併排序從小到大排列。
分解過程
這是一個規模為8的排序問題。首先將問題不斷二分直到8個規模為1的子問題。因為每步操作的結構類似,因此這幾步操作可以用一個遞迴函數merge-sort表示:merge-sort(A,p,r),其中p為每步分解操作中子序列頭的位置,r表示子序列尾的位置。如何保證若干次操作後子序列規模能降到1呢?這就需要對頭和尾數位的位置進行比較。其操作過程是:若p<r,則在兩數之間插入一個位置q,並呼叫merge-sort(A,p,q)與merge-sort(A,q+1,r),對兩邊子序列分別再進行上述頭尾元素位置的比較。這樣迴圈的結果是最終每個子序列的頭和尾元素位置相同,即問題規模降為1。單元素本身就是排好序的,也就是說,對單元素排序是一個可以用常數時間解決的問題。
回到上述例子,分解之後,A=({3},{2},{4},{6},{1},{5},{7},{8})
merge過程
當子問題變成單元素時,就開始呼叫merge過程,即兩個已經排好序的子序列合併,在合併的過程中就要排序。因此,在每一次merge前,都有左右兩個子序列已經排好序(這裡和插入排序中,當選擇新元素判斷插入序列位置時,已有序列已經排好序這一思想有共通之處)。
此時思路仍可以類比抓牌。現在有兩堆牌(A,B)。每堆都已經從小到大排列,小的放上面,大的放下面。先比較A和B堆中最上面的牌(A1,B1)。若A1>B1,則把B1拿出來放在第三堆(C)中,令為C1。接著,把留下的A1繼續跟B2比,若A1還大則重複上述操作,若A1小則把A1取出,令為C2,而換B2和A堆中剩下元素比較。最終,某一堆的數位可能被全部取出,而另一堆還沒取完,則此時直接把另一堆的數位追加到C堆後面即可。
可以看出,這樣操作就不是插入排序那樣的原地排序了,而是每層遞迴都要新生成一個空序列以存放每層排好序的元素。當然,為了節省空間複雜度,這個儲存空間需要儘快釋放。
總的來說,計算順序是先對原序列遞迴分解
→
\to
→直到子序列為單元素
→
\to
→對子序列遞迴合併+排序,直到序列總長度等於原問題規模。
將解這個問題的過程寫成merge-sort(n),問題規模為n。下面討論如何將這個問題的運算時間
T
(
n
)
T(n)
T(n)用遞迴式表示,這裡仍然是基於RAM模型的假設。解這個問題分為哪幾個步驟呢?
首先,需要找到這個問題的中間元素,分解為兩個子問題。而因為這一步只要計算中間的索引即可,其運算時間與問題規模無關,是常數
c
1
c_1
c1;其次,需要對分成的兩個子問題分別呼叫該過程merge-sort(n/2)。求解這兩個子問題的時間即為
T
(
n
2
)
T(\frac{n}{2})
T(2n)。最後,當子問題全部解完之後,需要對這兩個子問題合併,合併的merge(n)過程需要
c
2
n
c_2n
c2n執行時間。因為合併是將每個堆最上面的元素進行比較,若要合併成n個元素,則一共最多要比較n次(回想抓牌過程),每次比較只要常數時間
c
2
c_2
c2。由於
c
2
n
+
c
1
c_2n+c_1
c2n+c1仍然是n的一個線性函數,可以表示為
Θ
(
n
)
\Theta(n)
Θ(n),因此得到執行時間的遞迴表示式:
T
(
n
)
=
T
(
n
2
)
+
Θ
(
n
)
T(n)=T(\frac{n}{2})+\Theta(n)
T(n)=T(2n)+Θ(n)
虛擬碼
首先看merge-sort虛擬碼,即假設兩側序列都已經排好序,如何對這兩段序列合併排序。
有一個需要注意的構造技巧。排序總體應當分為兩個階段:1.所有堆中的元素均非空時,這樣只要一直比較兩堆中最上面的元素即可;2.當某堆中的元素被取完時,這樣直接把非空的那堆追加到排好序的序列後面即可。因此,在選取某堆最上面元素的時候,需要先判斷該堆元素是否為空。一種自然的想法是把這堆元素迴圈計數,看個數是否為0。但這樣的話,每輪合併都要把所有元素迴圈一遍很費時間。因此,簡化的操作是每輪合併後對每堆序列的最下層追加一個一定不屬於該序列的「哨兵」,因此只要某輪輪合併排序的時候發現了「哨兵」,說明該堆已空。
「哨兵」如何選擇?首先,需要排序的元素裡一定不存在
∞
\infty
∞,並且,利用
∞
\infty
∞比所有數大的性質也可以進一步簡化程式碼,直接與兩堆數位比較的過程融合,不需要單獨寫一行程式碼判斷下一個數是否是哨兵。
以下是merge過程虛擬碼:
MERGE(A, p, q, r)
1 n1 ← q - p + 1
2 n2 ← r - q
3 create arrays L[1 ‥ n1 + 1] and R[1 ‥ n2 + 1]
4 for i ← 1 to n1
5 do L[i] ← A[p + i - 1]
6 for j ← 1 to n2
7 do R[j] ← A[q + j] //將A分成兩堆,用這兩堆的比較更新A序列
8 L[n1 + 1] ← ∞ //新堆尾部插入哨兵
9 R[n2 + 1] ← ∞
10 i ← 1
11 j ← 1
12 for k ← p to r
13 do if L[i] ≤ R[j] //兩個新堆最上面的元素比較。這裡可以合併遇到∞的情況,是對程式碼很大的簡化
14 then A[k] ← L[i]
15 i ← i + 1
16 else A[k] ← R[j]
17 j ← j + 1
> 引自清華計算機系武永衛老師課件
以下是合併排序merge-sort整個過程的虛擬碼:
merge-sort(A,p,r)
if p<r:
q = (p+r)/2 //注意這裡q是下取整,因此最後總能迴圈到p>=q
merge-sort(A,p,q)
merge-sort(A,q+1,r)
MERGE(A,p,q,r)
python程式碼實現
以下是merge過程python程式碼的實現:
A = [1,4,6,2,4,5,7]
def MERGE(A, p, q, r): ##其中,r為原序列末位數的索引,p為原序列首位數的索引,q為中間某個數的索引(q左右兩側的數已經順序排列)
L = A[p:q+1]
R = A[q+1:r+1]
L.append(float("inf"))
R.append(float("inf"))
i = 0
j = 0
for k in range(p,r+1):
if L[i]<=R[j]:
A[k] = L[i]
i = i+1
else:
A[k] = R[j]
j = j+1
return A
MERGE(A, 0, 2, 6)
輸出結果是一個已經排好序的序列:
>>> [1, 2, 4, 4, 5, 6, 7]
以下是整個合併排序merge-sort過程的程式碼實現(需要呼叫前面定義的MERGE函數):
def merge_sort(A, p, r):
if p < r:
q = math.floor((p+r)/2)
merge_sort(A,p,q)
merge_sort(A,q+1,r)
MERGE(A, p, q, r)
return A
A = [1,6,4,2,5,4,7]
merge_sort(A, 0, 6)
>>> [1, 2, 4, 4, 5, 6, 7]
用遞迴樹猜測時間複雜度
如何確定合併排序演演算法的時間複雜度?雖然用主定理可以直接確定,但這裡還是從遞迴樹的角度給出猜測。因為對於一些無法用主定理直接確定的遞迴演演算法,還是需要將遞迴樹和代換法結合確定複雜度。用遞迴樹可以提出猜想,用代換法則可以給出該猜想結果的數學證明。
如圖所示,是一個遞迴樹的結構。問題總規模為n。這裡為了簡化問題,令
n
=
2
k
n = 2^k
n=2k。令從上到下為第1,2,…m層。用遞迴樹求解總的運算時間,需要每層都看。這也是和寫遞迴式的不同之處。遞迴式只要看其中任意一層即可。可以從上往下看。第1層的運算時間是從第1-2層的分解加第2-1層的合併,前面提到過,分解與合併時間之和是
c
1
+
c
2
n
c_1+c_2n
c1+c2n,因為低次項在算漸進界時不重要,可以直接簡化為
c
n
cn
cn。第2層每個問題規模n/2,分解與合併時間之和均為
c
n
2
\frac{cn}{2}
2cn,因此,第2層總時間也為
c
n
cn
cn。這樣遞推可得,所有m層每層執行時間均為
c
n
cn
cn。如何計算總層數?從
n
=
2
k
n = 2^k
n=2k個元素二分降到1個元素,需要降
k
=
l
g
n
k=lgn
k=lgn次,因此總層數為
m
=
l
g
n
+
1
m=lgn+1
m=lgn+1,故有總執行時間
T
(
n
)
=
c
n
l
g
n
+
c
n
T(n)=cnlgn+cn
T(n)=cnlgn+cn
我之前文章提到過,函數增長率只看高階,因此,猜測該演演算法執行時間的漸進確界為
n
l
g
n
nlgn
nlgn。
用代換法可以證明,這一結論成立。則其時間複雜度即為
Θ
(
n
l
g
n
)
\Theta(nlgn)
Θ(nlgn)。