Python爬取京東商城商品大圖詳解
Python爬取京東商城商品大圖詳解
做為一個爬蟲初學者,在做爬取網址圖片的練習中以京東網為例爬取商品大圖並儲存在相應的資料夾
1.匯入模組
import urllib.request
import re
2.商品名稱填寫區域
這裡「AJ」只是舉個例子,當然也可以輸入其他任意商品
keyname="AJ"#輸入商品名稱
key=urllib.request.quote(keyname)
3.新增報頭
新增報頭的目的是模擬瀏覽器去存取目標網頁,這裡我用的是火狐瀏覽器,當然谷歌也可以,但是需要改一下報頭資訊
headers=("User-Agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:80.0) Gecko/20100101 Firefox/80.0")
opener=urllib.request.build_opener()
opener.addheaders=[headers]
urllib.request.install_opener(opener)
4.分析商品網頁
在京東首頁先隨便搜一個商品,以「男外套「為例子吧:
這是「男外套」第一頁的URL:
'''https://search.jd.com/Search?keyword=%E7%94%B7%E5%A4%96%E5%A5%97&enc=utf-8&pvid=7fd9c2174f0b403da73119cfc5fe2f03'''
繼續點選第二頁、第三頁,把對應的URL複製下來進行分析
第二頁:
'''https://search.jd.com/Search?keyword=%E7%94%B7%E5%A4%96%E5%A5%97&page=3&s=51&click=0'''
第三頁
'''https://search.jd.com/Search?keyword=%E7%94%B7%E5%A4%96%E5%A5%97&page=5&s=101&click=0'''
然後進行分析,在keyword後面更換一下商品名稱複製到瀏覽器中開啟,會開啟京東商城搜尋更換的商品名稱的頁面。
例如把第三頁中的keyword後面的」%E7%94%B7%E5%A4%96%E5%A5%97「這一串字串換為「女外套」,我們發現商城頁面從「男外套」變成了「女外套」並已經進行了搜尋
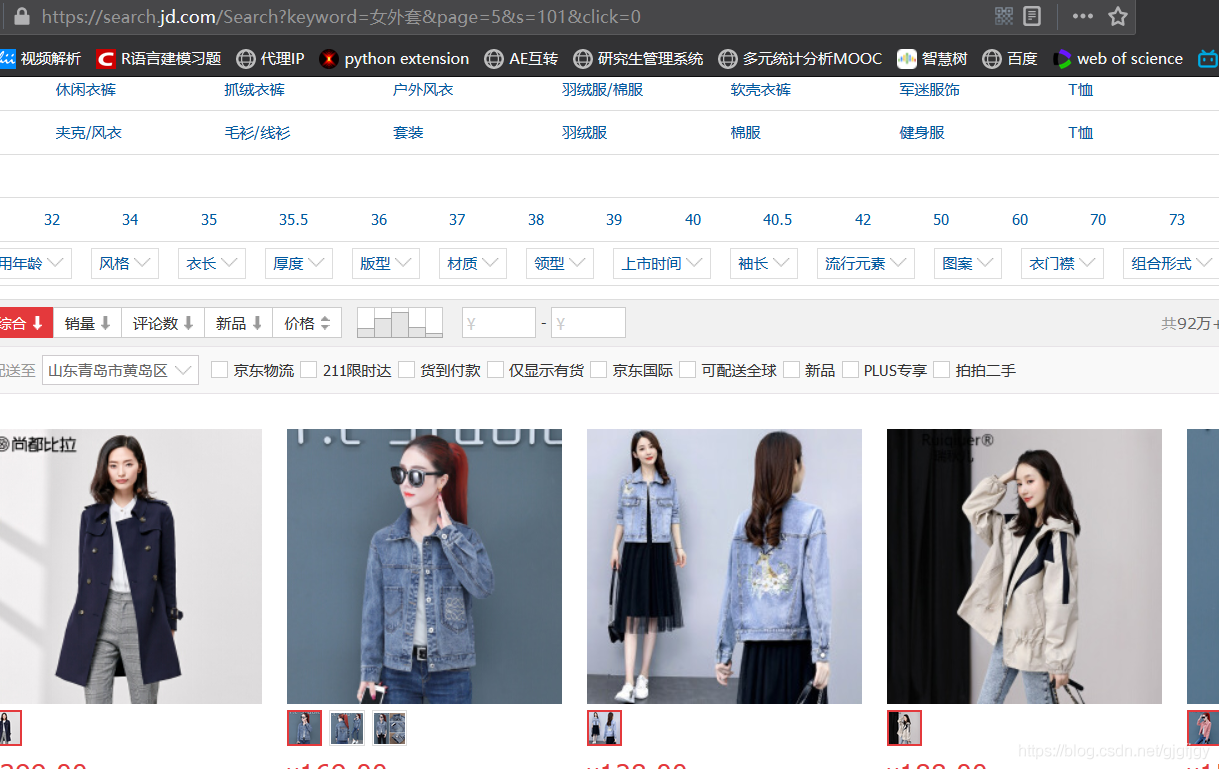 關鍵問題來了:當前頁面只是第一頁,怎麼使網址變成第二頁、第三頁、第N頁呢。繼續分析之前複製三個頁面的URL,發現URL中有一個單詞page,於是我試著去修改「page=」後面的數位,將3改為7,發現頁面跳到了第4頁
關鍵問題來了:當前頁面只是第一頁,怎麼使網址變成第二頁、第三頁、第N頁呢。繼續分析之前複製三個頁面的URL,發現URL中有一個單詞page,於是我試著去修改「page=」後面的數位,將3改為7,發現頁面跳到了第4頁
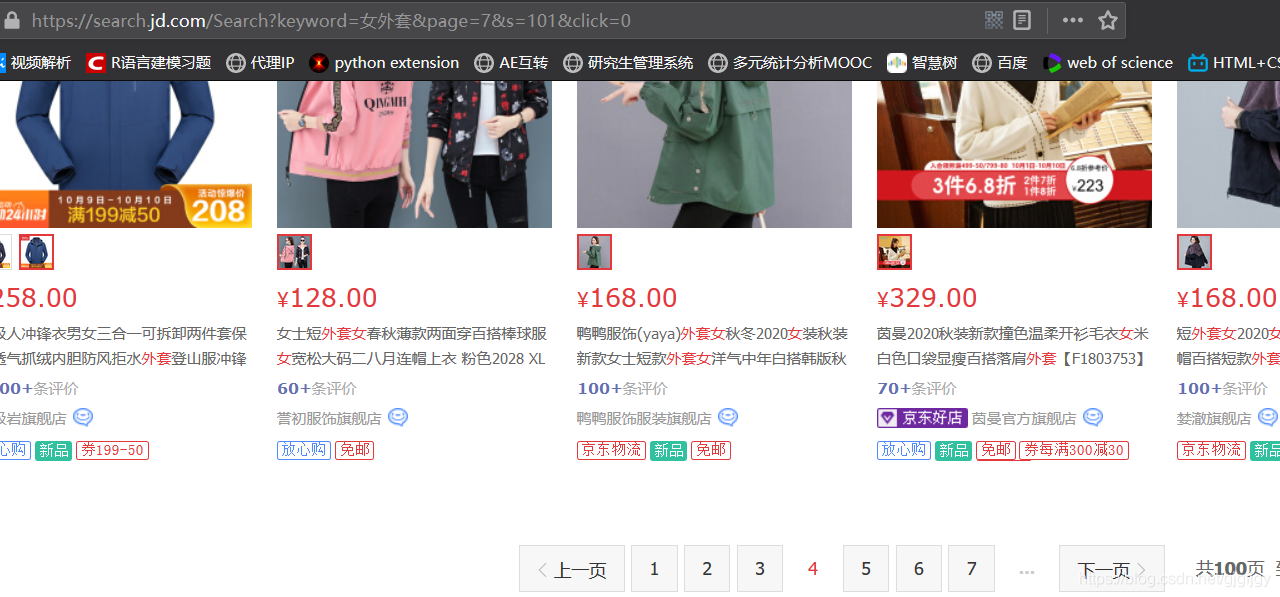 之前複製的第二個和第三個URL「page=」後面分別是3、5,由於搜尋商品的頁面預設是第一頁,複製下來的URL也跟第二頁、第三頁差別比較大,於是我試著將「page=」後面的數位改為1,發先頁面跳到了第一頁;於是我們的URL就可以確定了:
之前複製的第二個和第三個URL「page=」後面分別是3、5,由於搜尋商品的頁面預設是第一頁,複製下來的URL也跟第二頁、第三頁差別比較大,於是我試著將「page=」後面的數位改為1,發先頁面跳到了第一頁;於是我們的URL就可以確定了:
url="https://search.jd.com/Search?keyword="+key+"&wq="+key+"&page="+str(i*2-1);
然後對頁面進行存取並讀取編碼:
data=urllib.request.urlopen(url).read().decode("utf-8","ignore")
5.正規表示式的確定
檢視搜尋商品頁面的原始碼,在商品搜尋介面先隨便複製一張商品圖的影象地址,複製在文字中,然後選擇複製其中的一段(因為全部複製有可能找不到,實際圖片地址和頁面原始碼裡面的圖片地址的格式可能不太一樣),例如我複製任意一個商品的圖片地址中的一段在原始碼中進行搜尋
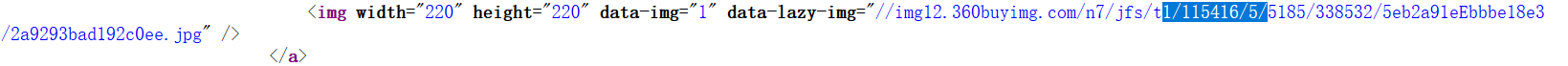 發現商品圖片地址前面的標籤是「data-lazy-img」然後再在原始碼頁面搜尋此標籤,發現"data-lazy-img"標籤後面都是商品圖片的圖片地址,於是可以設定正規表示式:
發現商品圖片地址前面的標籤是「data-lazy-img」然後再在原始碼頁面搜尋此標籤,發現"data-lazy-img"標籤後面都是商品圖片的圖片地址,於是可以設定正規表示式:
pat='data-lazy-img="(.*?)"'
然後再進行:
imagelist=re.compile(pat).findall(data)
6.大圖的爬取(之前的圖片地址是小圖)
先在搜尋頁面複製一張圖片的地址到文字,然後再點進商品,去檢視大圖,再複製商品圖片的地址到文字,進行分析,例如
小圖圖片地址'''https://img14.360buyimg.com/n7/jfs/t1/112463/24/19126/94054/5f7199a9E0a24e8f5/21931f19ee2f4874.jpg'''
大圖圖片地址'''https://img14.360buyimg.com/n0/jfs/t1/112463/24/19126/94054/5f7199a9E0a24e8f5/21931f19ee2f4874.jpg'''
從上圖片地址分析得到只有一處不一樣,那就是/n7和/n0,於是需要把爬取出來的字串中的「/n7」換為"/n0":
b1=imagelist[j].replace('/n7', '/n0')
注意:爬取的圖片地址直接是打不開的,需要在前面加個「http:」
newurl="http:"+b1
以下是此程式的完整程式碼:
import urllib.request
import re
keyname="AJ"#輸入商品名稱
key=urllib.request.quote(keyname)
headers=("User-Agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:80.0) Gecko/20100101 Firefox/80.0")
opener=urllib.request.build_opener()
opener.addheaders=[headers]
urllib.request.install_opener(opener)
for i in range(1,10):
url="https://search.jd.com/Search?keyword="+key+"&wq="+key+"&page="+str(i*2-1);
data=urllib.request.urlopen(url).read().decode("utf-8","ignore")
pat='data-lazy-img="(.*?)"'
imagelist=re.compile(pat).findall(data)
for j in range(0,len(imagelist)):
b1=imagelist[j].replace('/n7', '/n0')
print("第"+str(i)+"頁第"+str(j)+"張爬取成功")
newurl="http:"+b1
file="E:/新建資料夾/AJ/"+"第"+str(i)+"頁第"+str(j)+"張"+".jpg"#file指先在指定資料夾裡建立相關的資料夾才能爬取成功
urllib.request.urlretrieve(newurl, filename=file)
結語
作為爬蟲初學者,很樂意分享一些簡單的小程式,可能有很多描述得不夠專業,但是也比較詳細了(歡迎指正批評)!