15-python爬取百度貼吧-excel儲存
2020-10-11 15:00:13
讓我們爬取百度貼吧旅遊資訊,看看哪些地方是大家旅遊關注的熱點。
不要問我這個十一去哪兒旅遊了,我還在家沒日沒夜的碼程式碼。
這次我們用 urllib 爬取頁面,再用BeautifulSoup提取有用資訊,最後用 xlsxwriter 把獲取的資訊 寫入到excel表
一 、用到技術
python 基礎xlsxwriter用來寫入excel檔案的urllibpython內建爬蟲工具BeautifulSoup解析提取資料
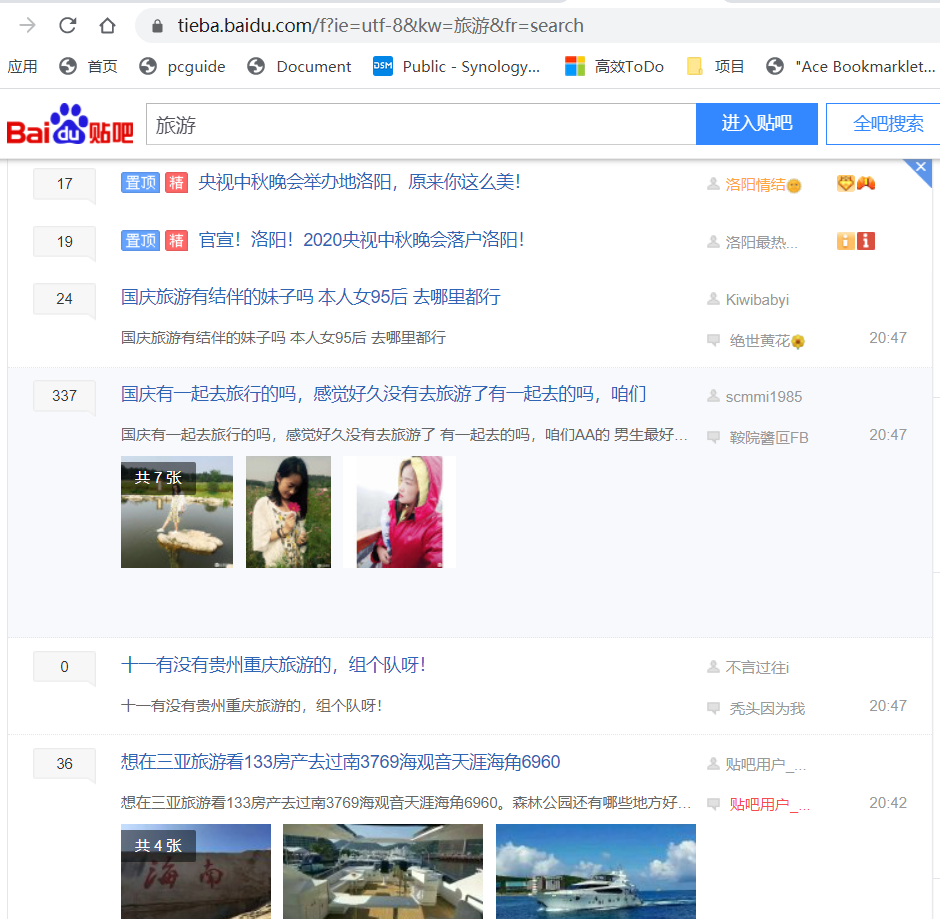
二、 目標頁面
https://tieba.baidu.com/f?kw=%E6%97%85%E6%B8%B8&ie=utf-8&pn=0
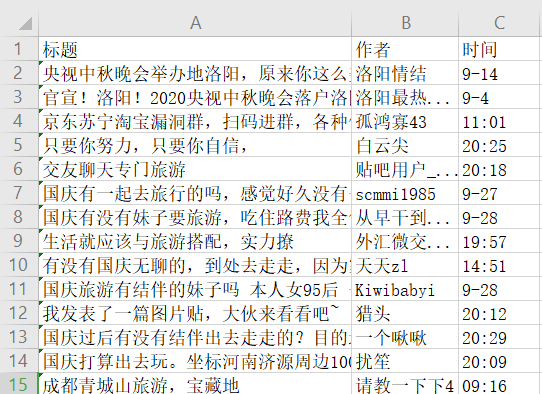
三、結果
四、安裝 必要的庫
- win+R 開啟執行
- 輸出cmd 進入控制檯
- 分別安裝
beautifulsoup4,lxml,xlsxwriter
pip install lxml
pip install beautifulsoup4
pip install xlsxwriter
五、分析頁面
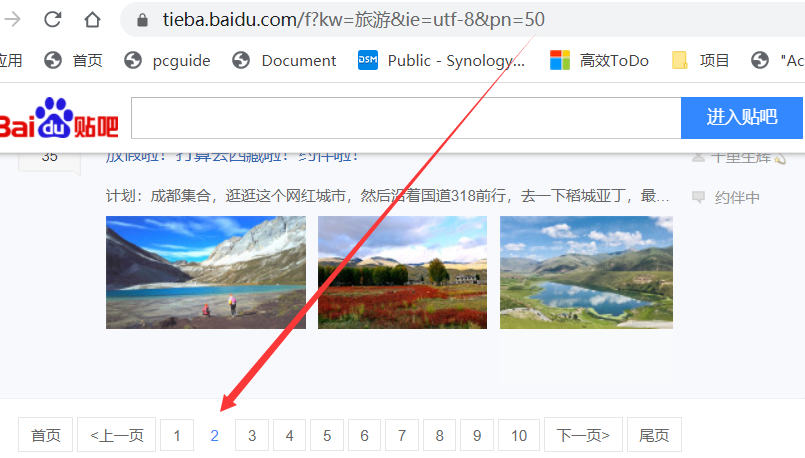
1. 頁面規律
我們單擊分頁按鈕,拿到頁面最後一個引數的規律
第二頁:https://tieba.baidu.com/f?kw=旅遊&ie=utf-8&pn= 50
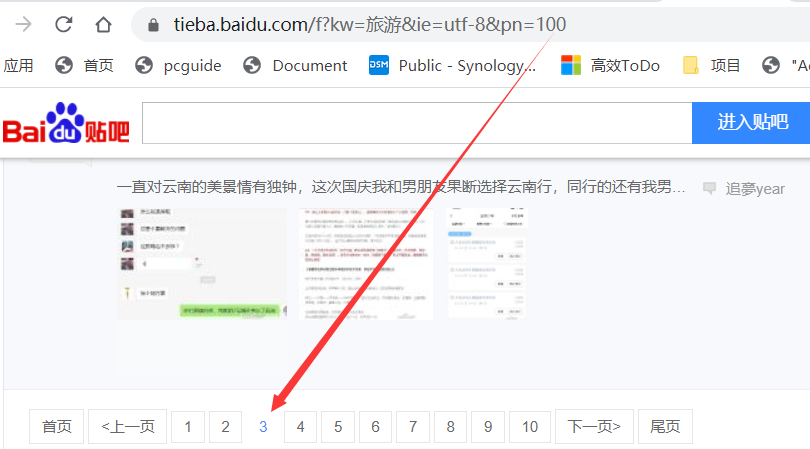
第三頁:https://tieba.baidu.com/f?kw=旅遊&ie=utf-8&pn= 100
第四頁:https://tieba.baidu.com/f?kw=旅遊&ie=utf-8&pn= 150
2. 頁面資訊
旅遊資訊列表
開啟網頁https://tieba.baidu.com/f?kw=旅遊&ie=utf-8&pn= 50
按鍵盤F12鍵或者 滑鼠右鍵"檢查元素"(我用的谷歌chrome瀏覽器)
發現所有旅遊列表都有個共同的class類名j_thread_list
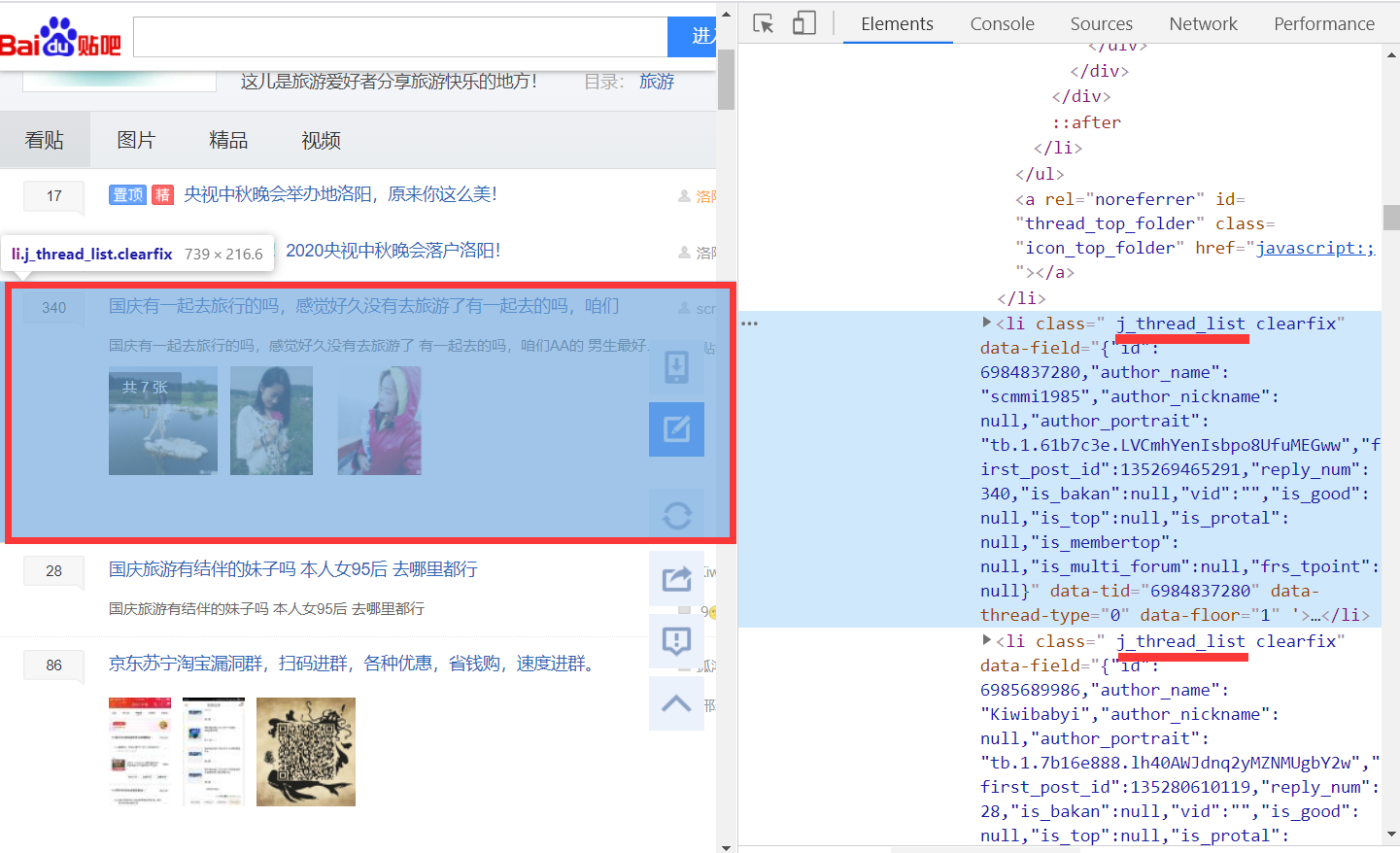
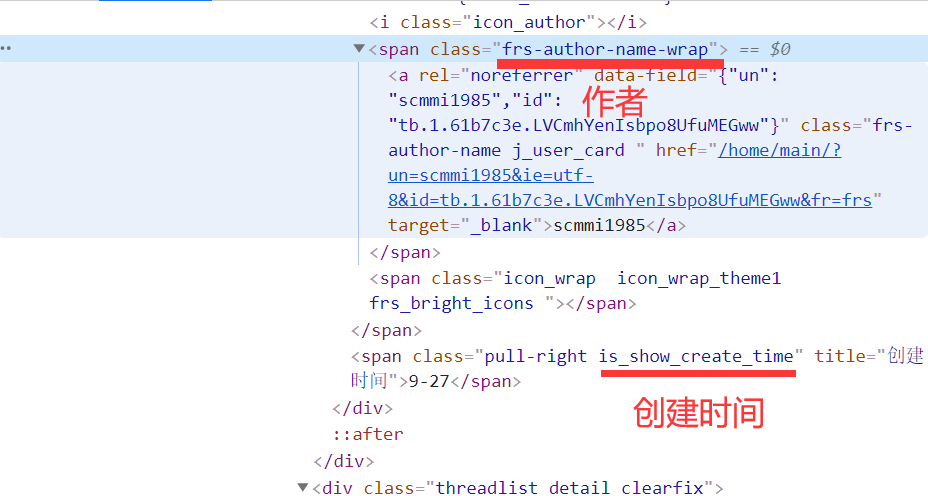
作者與建立時間
作者的class為frs-author-name,建立時間的class為is_show_create_time
標題
標題的class為j_th_tit

六、全部程式碼
import xlsxwriter
# 用來寫入excel檔案的
import urllib.parse
# URL編碼格式轉換的
import urllib.request
# 發起http請求的
from bs4 import BeautifulSoup
# css方法解析提取資訊
url='https://tieba.baidu.com/f?kw='+urllib.parse.quote('旅遊')+'&ie=utf-8&pn='
# 百度貼吧旅遊資訊
# parse.quote("旅遊") # 結果為%E6%97%85%E6%B8%B8
herders={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36', 'Referer':'https://tieba.baidu.com/','Connection':'keep-alive'}
# 請求頭資訊
data = []
# 所有爬蟲的資料都存放到 這個data列表裡面
"""
getList 獲取分頁中的列表資訊
url 分頁地址
"""
def getList(url):
req = urllib.request.Request(url,headers=herders)
# 設定請求頭
response=urllib.request.urlopen(req)
# 發起請求得到 響應結果response
htmlText = response.read().decode("utf-8").replace("<!--","").replace("-->","")
# htmlText = 響應結果read讀取.decode 轉換為utf文字.replace 替換掉html中的註釋
# 我們需要的結果在註釋中,所以要先替換掉註釋標籤 <!-- -->
html = BeautifulSoup(htmlText,"lxml")
# 建立beautifulSoup物件
thread_list=html.select(".j_thread_list")
# 獲取到所有的旅遊類別
# 遍歷旅遊列表
for thread in thread_list:
title = thread.select(".j_th_tit")[0].get_text()
author = thread.select(".frs-author-name")[0].get_text()
time= thread.select(".is_show_create_time")[0].get_text()
# 提取標題,作者,事件
print(title) # 列印標籤
data.append([title,author,time])
# 追加到總資料中
"""
獲取到所有的分頁地址,最大5頁
url 頁面地址
p=5 最多5頁
"""
def getPage(url,p=5):
for i in range(5):
link = url+str(i*50)
# 再一次拼接 第1頁0 第2頁50 第3頁100 第4頁150
getList(link)
# 執行獲取頁面函數getList
"""
寫入excel檔案
data 被寫入的資料
"""
def writeExecl(data):
lens = len(data)
# 獲取頁面的長度
workbook = xlsxwriter.Workbook('travel.xlsx')
# 建立一個excel檔案
sheet = workbook.add_worksheet()
# 新增一張工作表
sheet.write_row("A1",["標題","作者","時間"])
# 寫入一行標題
for i in range(2, lens + 2):
sheet.write_row("A"+str(i),data[i - 2])
# 遍歷data 寫入行資料到excel
workbook.close()
# 關閉excel檔案
print("xlsx格式表格寫入資料成功!")
"""
定義主函數
"""
def main():
getPage(url,5) #獲取分頁
writeExecl(data) #寫入資料到excel
# 如果到模組的名字是__main__ 執行main主函數
if __name__ == '__main__':
main()
七、單詞表
main 主要的
def (define) 定義
getPage 獲取頁面
writeExcel 寫入excel
workbook 工作簿
sheet 表
write_row 寫入行
add 新增
close 關閉
len length長度
data 資料
range 範圍
str (string)字串
append 追加
author 作者
select 選擇
Beautiful 美麗
Soup 糖
herders 頭資訊
response 響應
read 讀
decode 編碼
Request 請求
parse 解析
quote 參照
線上練習:https://www.520mg.com/it

IT 入門 感謝關注