Presto在滴滴的探索與實踐

桔妹導讀:Presto在滴滴內部發展三年,已經成為滴滴內部Ad-Hoc和Hive SQL加速的首選引擎。目前服務6K+使用者,每天讀取2PB ~ 3PB HDFS資料,處理30萬億~35萬億條記錄,為了承接業務及豐富使用場景,滴滴Presto需要解決穩定性、易用性、效能、成本等諸多問題。我們在3年多的時間裡,做了大量優化和二次開發,積攢了非常豐富的經驗。本文分享了滴滴對Presto引擎的改進和優化,同時也提供了大量穩定性建設經驗。
1. Presto簡介
▍1.1 簡介
Presto是Facebook開源的MPP(Massive Parallel Processing)SQL引擎,其理念來源於一個叫Volcano的並行資料庫,該資料庫提出了一個並行執行SQL的模型,它被設計為用來專門進行高速、實時的資料分析。Presto是一個SQL計算引擎,分離計算層和儲存層,其不儲存資料,通過Connector SPI實現對各種資料來源(Storage)的存取。
▍1.2 架構
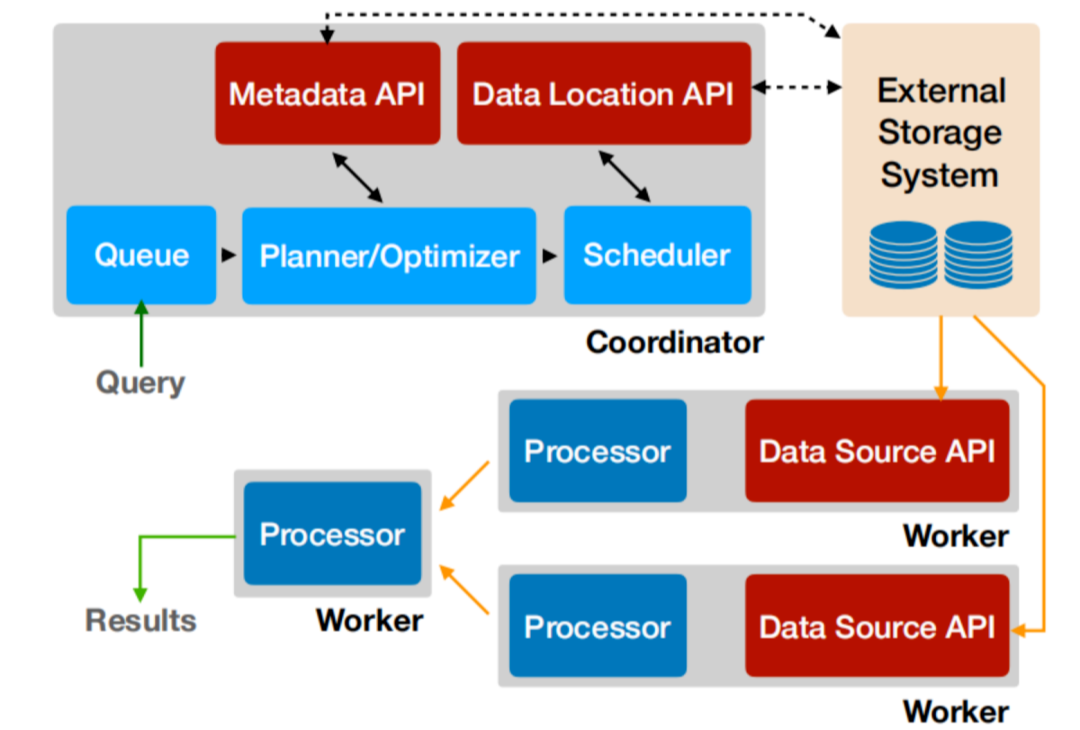
Presto沿用了通用的Master-Slave架構,一個Coordinator,多個Worker。Coordinator負責解析SQL語句,生成執行計劃,分發執行任務給Worker節點執行;Worker節點負責實際執行查詢任務。Presto提供了一套Connector介面,用於讀取元資訊和原始資料,Presto 內建有多種資料來源,如 Hive、MySQL、Kudu、Kafka 等。同時,Presto 的擴充套件機制允許自定義 Connector,從而實現對客製化資料來源的查詢。假如設定了Hive Connector,需要設定一個Hive MetaStore服務為Presto提供Hive元資訊,Worker節點通過Hive Connector與HDFS互動,讀取原始資料。
▍1.3 實現低延時原理
Presto是一個互動式查詢引擎,我們最關心的是Presto實現低延時查詢的原理,以下幾點是其效能脫穎而出的主要原因:
-
完全基於記憶體的平行計算
-
流水線
-
在地化計算
-
動態編譯執行計劃
-
小心使用記憶體和資料結構
-
GC控制
-
無容錯
2. Presto在滴滴的應用
▍2.1 業務場景
-
Hive SQL查詢加速
-
資料平臺Ad-Hoc查詢
-
報表(BI報表、自定義報表)
-
活動行銷
-
資料品質檢測
-
資產管理
-
固定資料產品
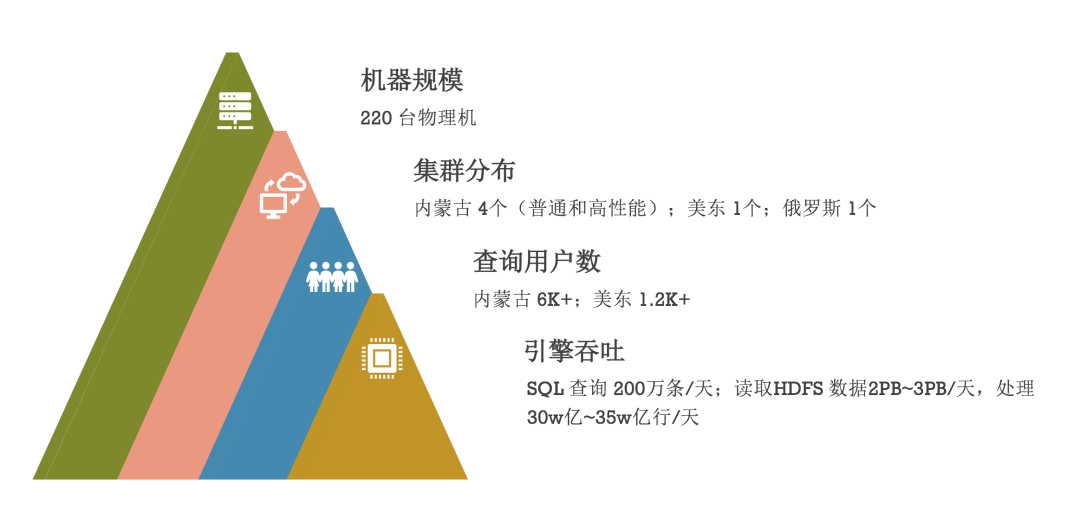
▍2.2 業務規模
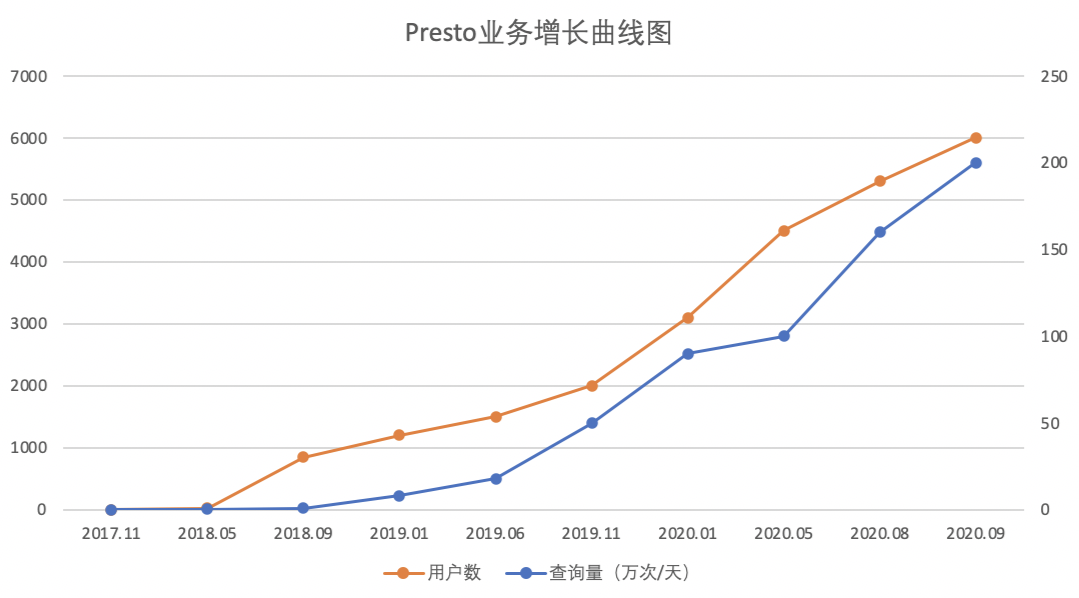
▍2.3 業務增長
▍2.4 叢集部署
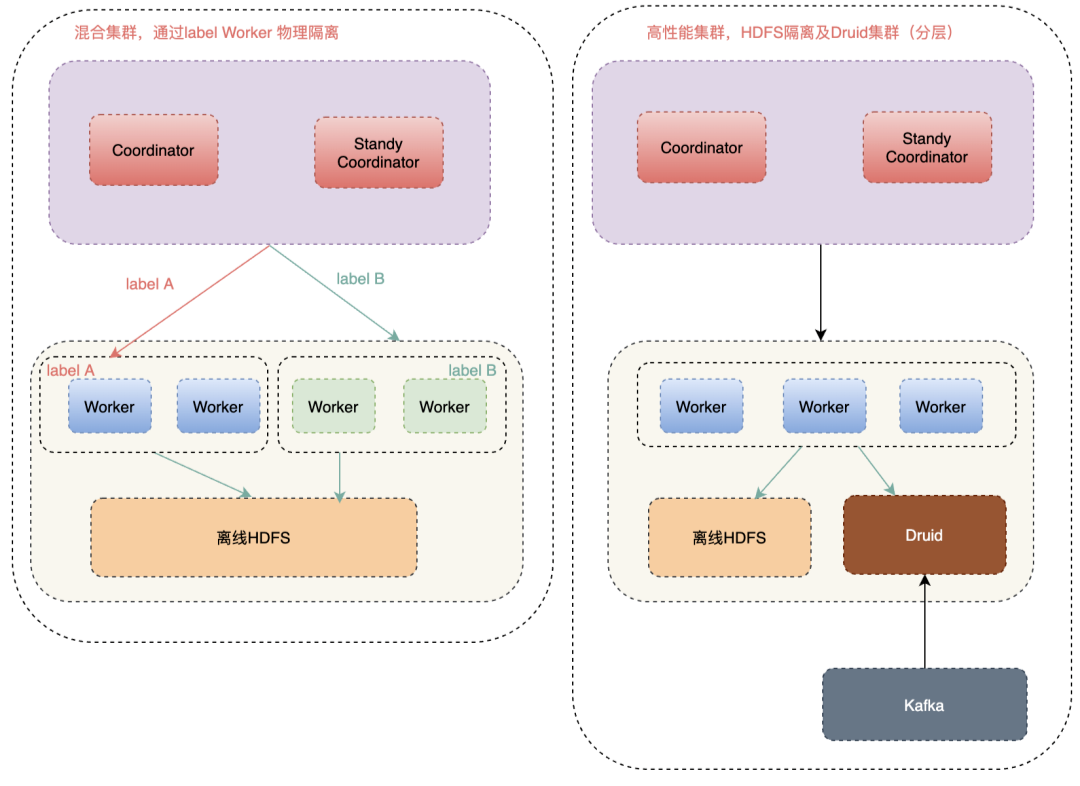
目前Presto分為混合叢集和高效能叢集,如上圖所示,混合叢集共用HDFS叢集,與離線Hadoop大叢集混合部署,為了防止叢集內大查詢影響小查詢, 而單獨搭建叢集會導致叢集太多,維護成本太高,我們通過指定Label來做到物理叢集隔離(詳細後文會講到)。而高效能叢集,HDFS是單獨部署的,且可以存取Druid, 使Presto 具備查詢實時資料和離線資料能力。
▍2.5 接入方式
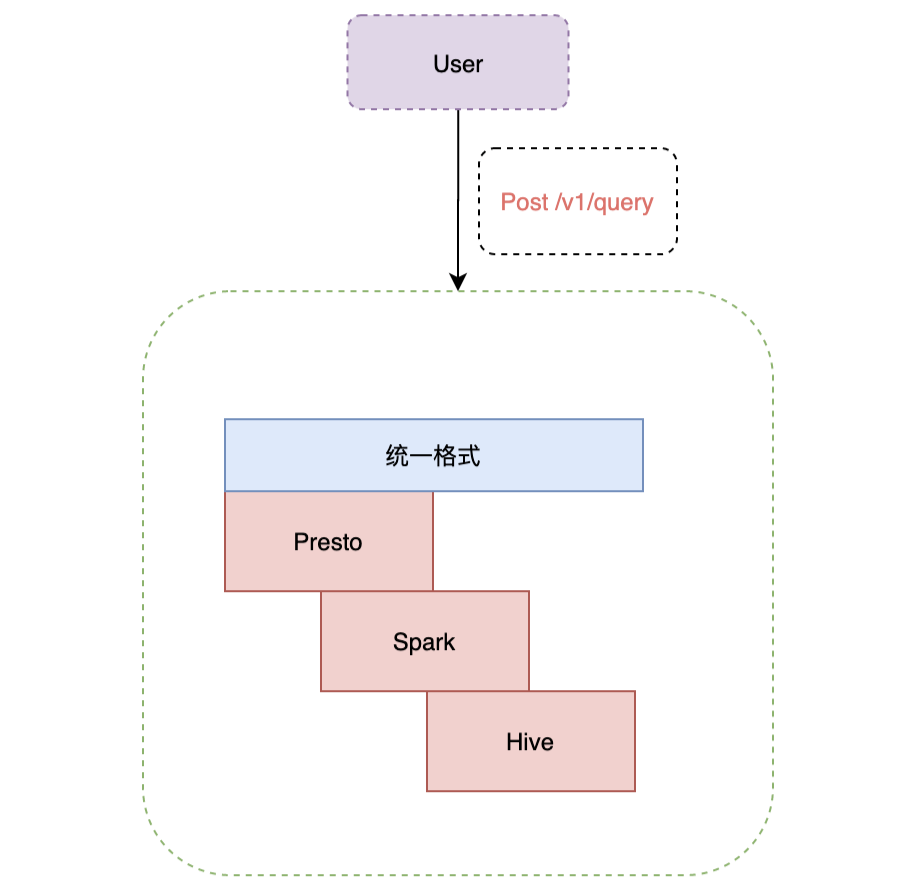
二次開發了JDBC、Go、Python、Cli、R、NodeJs 、HTTP等多種接入方式,打通了公司內部許可權體系,讓業務方方便快捷的接入 Presto 的,滿足了業務方多種技術棧的接入需求。
Presto 接入了查詢路由 Gateway,Gateway會智慧選擇合適的引擎,使用者查詢優先請求Presto,如果查詢失敗,會使用Spark查詢,如果依然失敗,最後會請求Hive。在Gateway層,我們做了一些優化來區分大查詢、中查詢及小查詢,對於查詢時間小於3分鐘的,我們即認為適合Presto查詢,比如通過HBO(基於歷史的統計資訊)及JOIN數量來區分查詢大小,架構圖見:
3. 引擎迭代
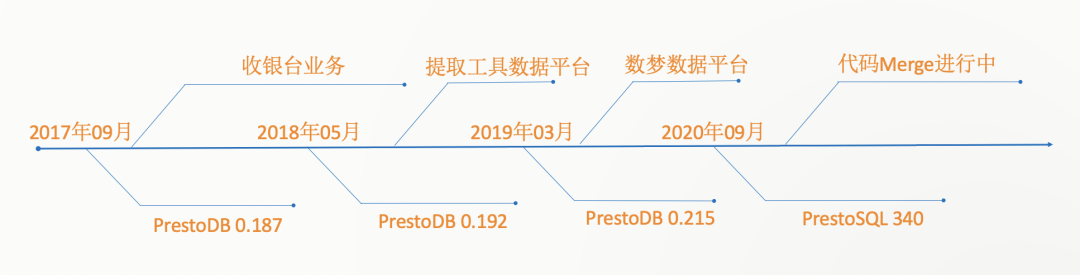
我們從2017年09月份開始調研Presto,經歷過0.192、0.215,共釋出56次版本。而在19年初(0.215版本是社群分家版本),Presto社群分家,分為兩個專案,叫PrestoDB和PrestoSQL,兩者都成立了自己的基金會。我們決定升級到PrestoSQL 最新版本(340版本)原因是:
-
PrestoSQL社群活躍度更高,PR和使用者問題能夠及時回覆
-
PrestoDB主要主力還是Facebook維護,以其內部需求為主
-
PrestoDB未來方向主要是ETL相關的,我們有Spark兜底,ETL功能依賴Spark、Hive
4. 引擎改進
在滴滴內部,Presto主要用於Ad-Hoc查詢及Hive SQL查詢加速,為了方便使用者能儘快將SQL遷移到Presto引擎上,且提高Presto引擎查詢效能,我們對Presto做了大量二次開發。同時,因為使用Gateway,即使SQL查詢出錯,SQL也會轉發到Spark及Hive上,所以我們沒有使用Presto的Spill to Disk功能。這樣一個純記憶體SQL引擎在使用過程中會遇到很多穩定問題,我們在解決這些問題時,也積累了很多經驗,下面將一一介紹:
▍4.1 Hive SQL相容
18年上半年,Presto剛起步,滴滴內部很多使用者不願意遷移業務,主要是因為Presto是ANSI SQL,與HiveQL差距較大,且查詢結果也會出現結果不一致問題,遷移成本比較高,為了方便Hive使用者能順利遷移業務,我們對Presto做了Hive SQL相容。而在技術選型時,我們沒有在Presto上層,即沒有在Gateway這層做SQL相容,主要是因為開發量較大,且UDF相關的開發和轉換成本太高,另外就是需要多做一次SQL解析,查詢效能會受到影響,同時增加了Hive Metastore的請求次數,當時Hive Metastore的壓力比較大,考慮到成本和穩定性,我們最後選擇在Presto引擎層上相容。
主要工作:
-
隱式型別轉換
-
語意相容
-
語法相容
-
支援Hive檢視
-
Parquet HDFS檔案讀取支援
-
大量UDF支援
-
其他
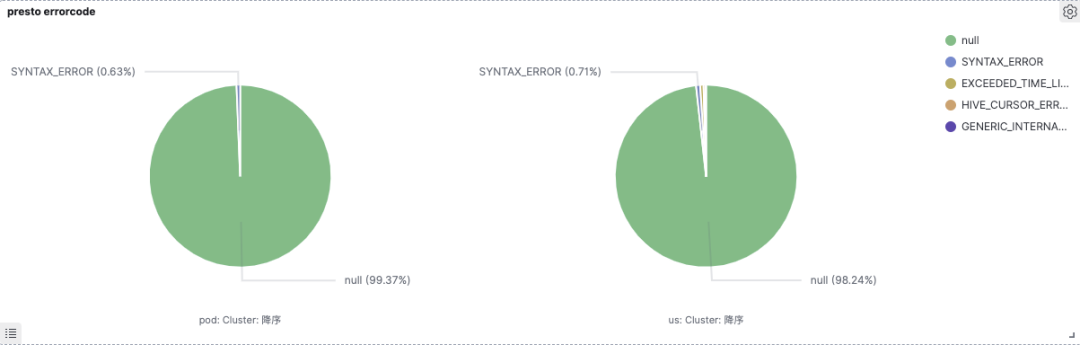
Hive SQL相容,我們迭代了三個大版本,目前線上SQL通過率97~99%。而業務從Spark/Hive遷移到Presto後,查詢效能平均提升30%~50%,甚至一些場景提升10倍,Ad-Hoc場景共節省80%機器資源。下圖是線上Presto叢集的SQL查詢通過率及失敗原因佔比,'null' 表示查詢成功的SQL,其他表示錯誤原因:
▍4.2 物理資源隔離
上文說到,對效能要求高的業務與大查詢業務方混合跑,查詢效能容易受到影響,只有單獨搭建叢集。而單獨搭建叢集導致Presto叢集太多,維護成本太高。因為目前我們Presto Coordinator還沒有遇到瓶頸,大查詢主要影響Worker效能,比如一條大SQL導致Worker CPU打滿,導致其他業務方SQL查詢變慢。所以我們修改排程模組,讓Presto支援可以動態打Label,動態排程指定的 Label 機器。如下圖所示:
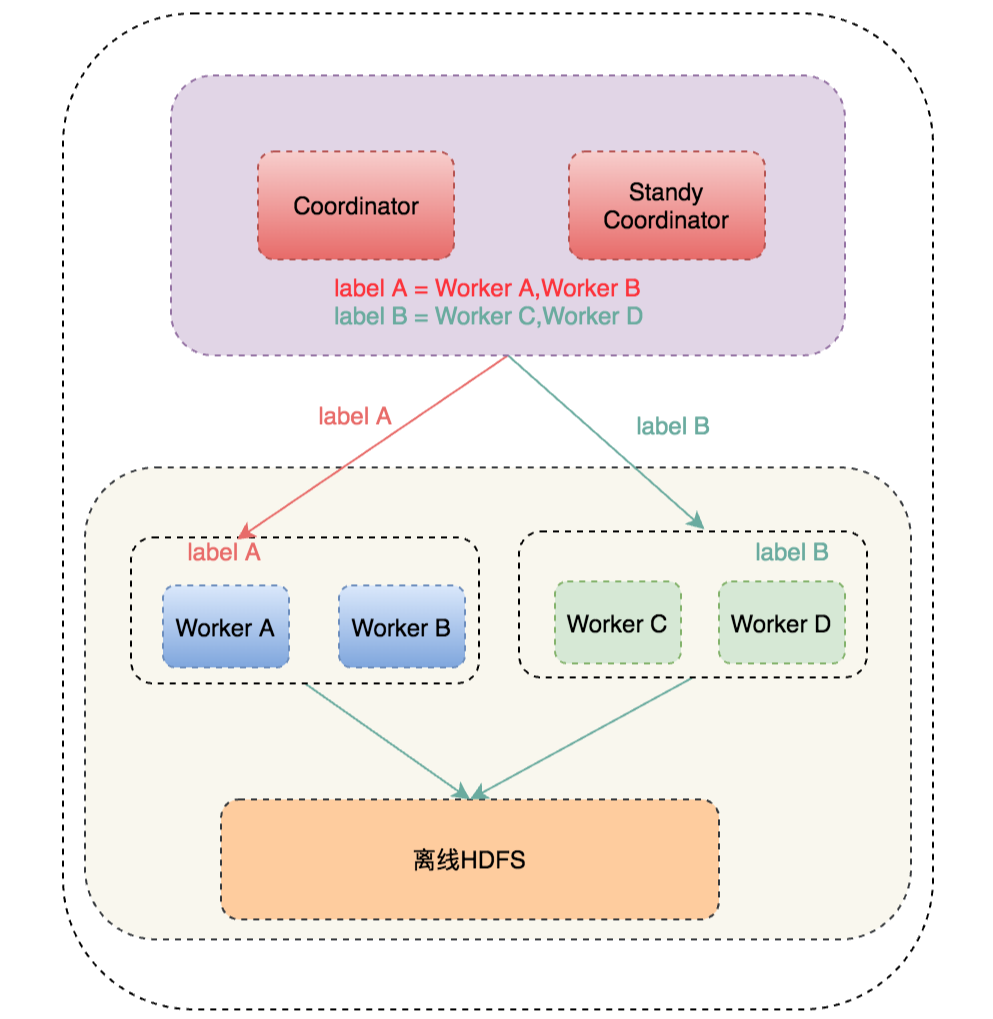
根據不同的業務劃分不同的label,通過組態檔設定業務方指定的label和其對應的機器列表,Coordinator會載入設定,在記憶體裡維護叢集label資訊,同時如果組態檔裡label資訊變動,Coordinator會定時更新label資訊,這樣排程時根據SQL指定的label資訊來獲取對應的Worker機器,如指定label A時,那排程機器裡只選擇Worker A 和 Worker B 即可。這樣就可以做到讓機器物理隔離了,對效能要求高的業務查詢既有保障了。
▍4.3 Druid Connector
使用 Presto + HDFS 有一些痛點:
-
latency高,QPS較低
-
不能查實時資料,如果有實時資料需求,需要再構建一條實時資料鏈路,增加了系統的複雜性
-
要想獲得極限效能,必須與HDFS DataNode 混部,且DataNode使用高階硬體,有自建HDFS的需求,增加了運維的負擔
所以我們在0.215版本實現了Presto on Druid Connector,此外掛有如下優點:
-
結合 Druid 的預聚合、計算能力(過濾聚合)、Cache能力,提升Presto效能(RT與QPS)
-
讓 Presto 具備查詢 Druid 實時資料能力
-
為Druid提供全面的SQL能力支援,擴充套件Druid資料的應用場景
-
通過Druid Broker獲取Druid後設資料資訊
-
從Druid Historical直接獲取資料
-
實現了Limit下推、Filter下推、Project下推及Agg下推
在PrestoSQL 340版本,社群也實現了Presto on Druid Connector,但是此Connector是通過JDBC實現的,缺點比較明顯:
-
無法劃分多個Split,查詢效能差
-
請求查詢Broker,之後再查詢Historical,多一次網路通訊
-
對於一些場景,如大量Scan場景,會導致Broker OOM
-
Project及Agg下推支援不完善
詳細架構圖見:
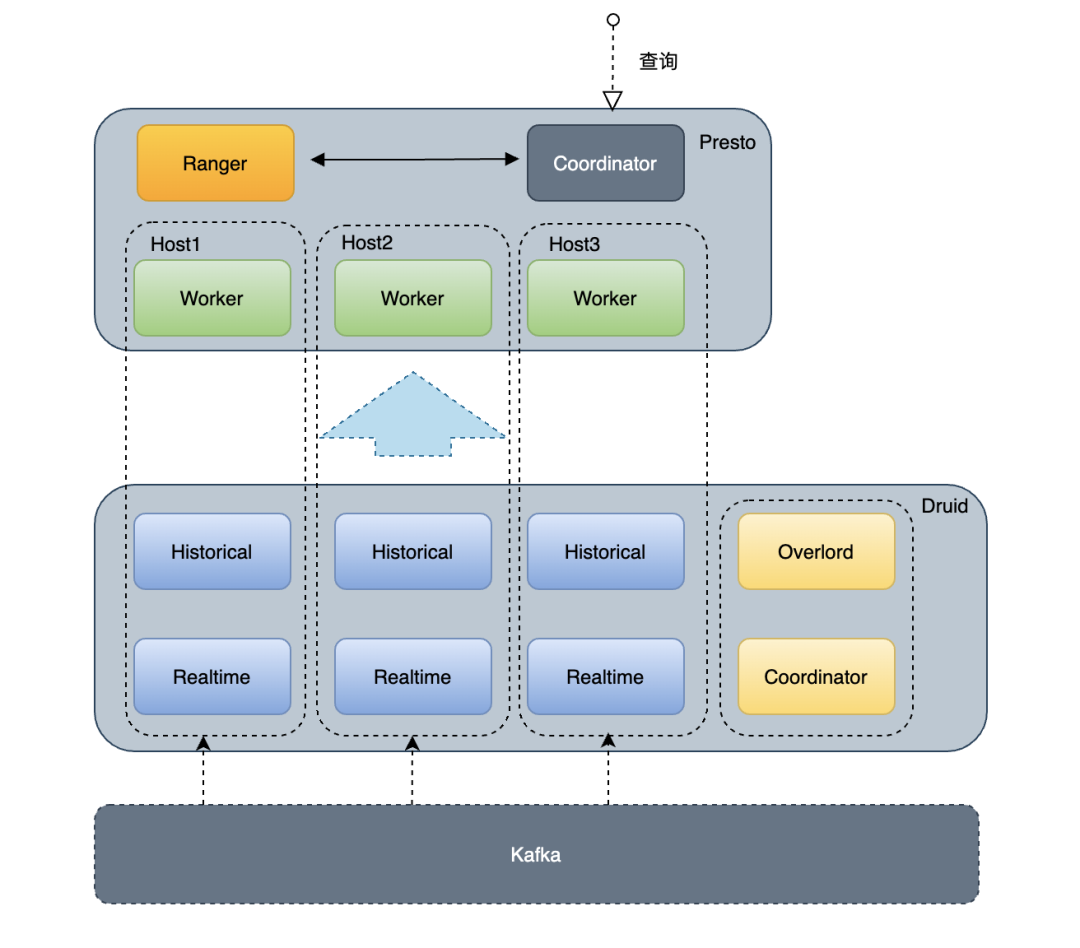
使用了Presto on Druid後,一些場景,效能提升4~5倍。
▍4.4 易用性建設
為了支援公司的幾個核心資料平臺,包括:數夢、提取工具、數易及特徵加速及各種散戶,我們對Presto做了很多二次開發,包括許可權管理、語法支援等,保證了業務的快速接入。主要工作:
-
租戶與許可權
-
與內部Hadoop打通,使用HDFS SIMPLE協定做認證
-
使用Ranger做鑑權,解析SQL使Presto擁有將列資訊傳遞給下游的能力,提供使用者名稱+資料庫名/表名/列名,四元組的鑑權能力,同時提供多表同時鑑權的能力
-
使用者指定使用者名稱做鑑權和認證,大賬號用於讀寫HDFS資料
-
支援檢視、表別名鑑權
-
-
語法拓展
-
支援add partition
-
支援數位開頭的表
-
支援數位開頭的欄位
-
-
特性增強
-
insert資料時,將插入資料的總行數寫入HMS,為業務方提供毫秒級的後設資料感知能力
-
支援查詢進度捲動更新,提升了使用者體驗
-
支援查詢可以指定優先順序,為使用者不同等級的業務提供了優先順序控制的能力
-
修改通訊協定,支援業務方可以傳達自定義資訊,滿足了使用者的紀錄檔審計需要等
-
支援DeprecatedLzoTextInputFormat格式
-
支援讀HDFS Parquet檔案路徑
-
▍4.5 穩定性建設
Presto在使用過程中會遇到很多穩定性問題,比如Coordinator OOM,Worker Full GC等,為了解決和方便定位這些問題,首先我們做了監控體系建設,主要包括:
-
通過Presto Plugin實現紀錄檔審計功能
-
通過JMX獲取引擎指標將監控資訊寫入Ganglia
-
將紀錄檔審計採集到HDFS和ES;統一接入運維監控體系,將所有指標發到 Kafka;
-
Presto UI改進:可以檢視Worker資訊,可以檢視Worker死活資訊
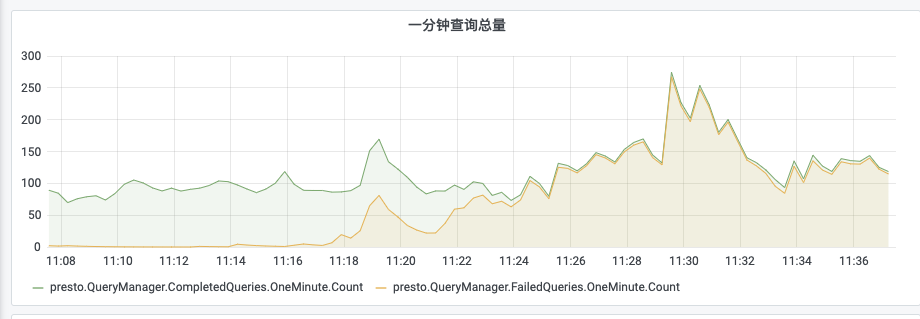
通過以上功能,在每次出現穩定性問題時,方便我們及時定位問題,包括指標檢視及SQL回放等,如下圖所示,可以檢視某叢集的成功及失敗SQL數,我們可以通過定義查詢失敗率來觸發報警:
在Presto交流社群,Presto的穩定性問題困擾了很多Presto使用者,包括Coordinator和Worker掛掉,叢集執行一段時間後查詢效能變慢等。我們在解決這些問題時積累了很多經驗,這裡說下解決思路和方法。
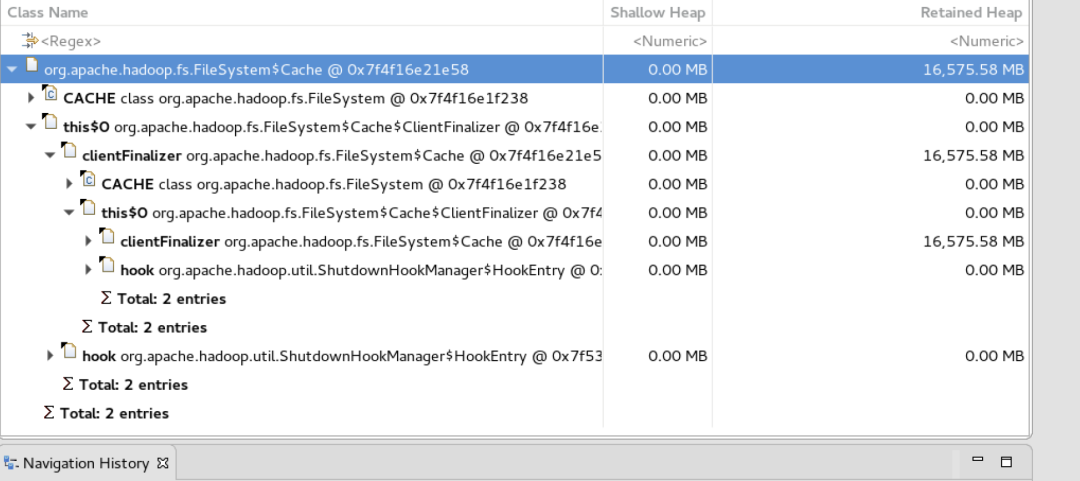
根據職責劃分,Presto分為Coordinator和Worker模組,Coordinator主要負責SQL解析、生成查詢計劃、Split排程及查詢狀態管理等,所以當Coordinator遇到OOM或者Coredump時,獲取元資訊及生成Splits是重點懷疑的地方。而記憶體問題,推薦使用MAT分析具體原因。如下圖是通過MAT分析,得出開啟了FileSystem Cache,記憶體漏失導致OOM。
這裡我們總結了Coordinator常見的問題和解決方法:
-
使用HDFS FileSystem Cache導致記憶體漏失,解決方法禁止FileSystem Cache,後續Presto自己維護了FileSystem Cache
-
Jetty導致堆外記憶體漏失,原因是Gzip導致了堆外記憶體漏失,升級Jetty版本解決
-
Splits太多,無可用埠,TIME_WAIT太高,修改TCP引數解決
-
JVM Coredump,顯示"unable to create new native thread",通過修改pid_max及max_map_count解決
-
Presto核心Bug,查詢失敗的SQL太多,導致Coordinator記憶體漏失,社群已修復
而Presto Worker主要用於計算,效能瓶頸點主要是記憶體和CPU。記憶體方面通過三種方法來保障和查詢問題:
-
通過Resource Group控制業務並行,防止嚴重超賣
-
通過JVM調優,解決一些常見記憶體問題,如Young GC Exhausted
-
善用MAT工具,發現記憶體瓶頸
而Presto Worker常會遇到查詢變慢問題,兩方面原因,一是確定是否開啟了Swap記憶體,當Free記憶體不足時,使用Swap會嚴重影響查詢效能。第二是CPU問題,解決此類問題,要善用Perf工具,多做Perf來分析CPU為什麼不在幹活,看CPU主要在做什麼,是GC問題還是JVM Bug。如下圖所示,為線上Presto叢集觸發了JVM Bug,導致執行一段時間後查詢變慢,重新啟動後恢復,Perf後找到原因,分析JVM程式碼,可通過JVM調優或升級JVM版本解決:

這裡我們也總結了Worker常見的問題和解決方法:
-
Sys load過高,導致業務查詢效能影響很大,研究jvm原理,通過引數(-XX:PerMethodRecompilationCutoff=10000 及 -XX:PerBytecodeRecompilationCutoff=10000)解決,也可升級最新JVM解決
-
Worker查詢hang住問題,原因HDFS使用者端存在bug,當Presto與HDFS混部署,資料和使用者端在同一臺機器上時,短路讀時一直wait鎖,導致查詢Hang住超時,Hadoop社群已解決
-
超賣導致Worker Young GC Exhausted,優化GC引數,如設定-XX:G1ReservePercent=25 及 -XX:InitiatingHeapOccupancyPercent=15
-
ORC太大,導致Presto讀取ORC Stripe Statistics出現OOM,解決方法是限制ProtoBuf報文大小,同時協助業務方合理資料治理
-
修改Presto記憶體管理邏輯,優化Kill策略,保障當記憶體不夠時,Presto Worker不會OOM,只需要將大查詢Kill掉,後續熔斷機制會改為基於JVM,類似ES的熔斷器,比如95% JVM 記憶體時,Kill掉最大SQL
▍4.6 引擎優化及調研
作為一個Ad-Hoc引擎,Presto查詢效能越快,使用者體驗越好,為了提高Presto的查詢效能,在Presto on Hive場景,我們做了很多引擎優化工作,主要工作:
-
某業務叢集進行了JVM調優,將Ref Proc由單執行緒改為並行執行,普通查詢由30S~1分鐘降低為3-4S,效能提升10倍+
-
ORC資料優化,將指定string欄位新增了布隆過濾器,查詢效能提升20-30%,針對一些業務做了調優
-
資料治理和小檔案合併,某業務方查詢效能由20S降低為10S,效能提升一倍,且查詢效能穩定
-
ORC格式效能優化,查詢耗時減少5%
-
分割區裁剪優化,解決指定分割區但獲取所有分割區元資訊問題,減少了HMS的壓力
-
下推優化,實現了Limit、Filter、Project、Agg下推到儲存層
18年我們為了提高Presto查詢效能,也調研了一些技術方案,包括Presto on Alluxio和Presto on Carbondata,但是這2種方案最後都被捨棄了,原因是:
-
Presto on Alluxio查詢效能提升35%,但是記憶體佔用和效能提升不成正比,所以我們放棄了Presto on Alluxio,後續可能會對一些效能要求敏感的業務使用
-
Presto on Carbondata是在18年8月份測試的,當時的版本,Carbondata穩定性較差,效能沒有明顯優勢,一些場景ORC更快,所以我們沒有再繼續跟蹤調研Presto on Carbondata。因為滴滴有專門維護Druid的團隊,所以我們對接了Presto on Druid,一些場景效能提升4~5倍,後續我們會更多關注Presto on Clickhouse及Presto on Elasticsearch
5. 總結
通過以上工作,滴滴Presto逐漸接入公司各巨量資料平臺,併成為了公司首選Ad-Hoc查詢引擎及Hive SQL加速引擎,下圖可以看到某產品接入後的效能提升:
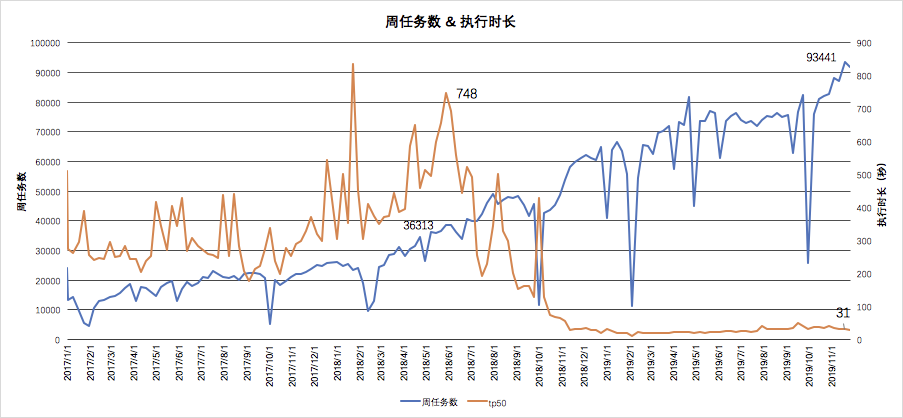
上圖可以看到大約2018年10月該平臺開始接入Presto,查詢耗時TP50效能提升了10+倍,由400S降低到31S。且在任務數逐漸增長的情況下,查詢耗時保證穩定不變。
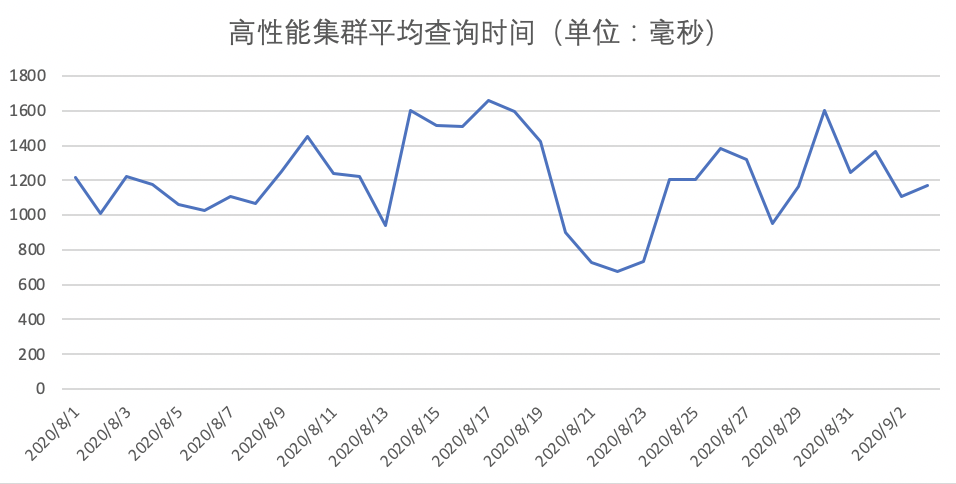
而高效能叢集,我們做了很多穩定性和效能優化工作,保證了平均查詢時間小於2S。如下圖所示:
6. 展望
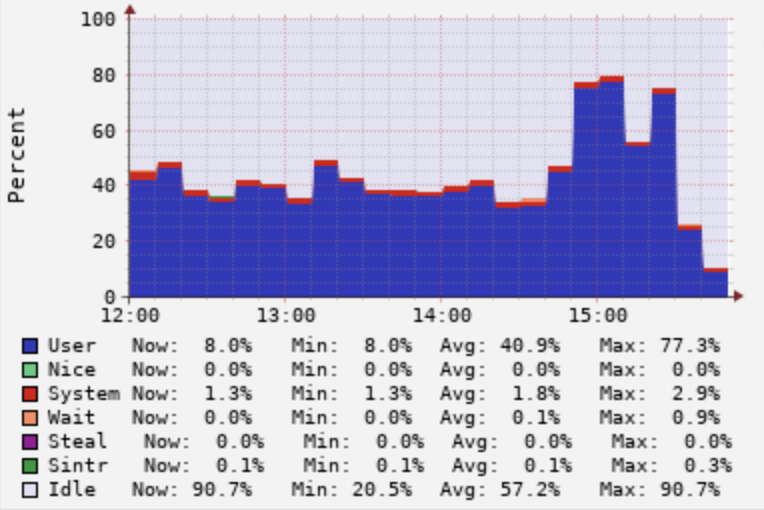
Presto主要應用場景是Ad-Hoc查詢,所以其高峰期主要在白天,如下圖所示,是網約車業務下午12-16點的查詢,可以看到平均CPU使用率在40%以上。
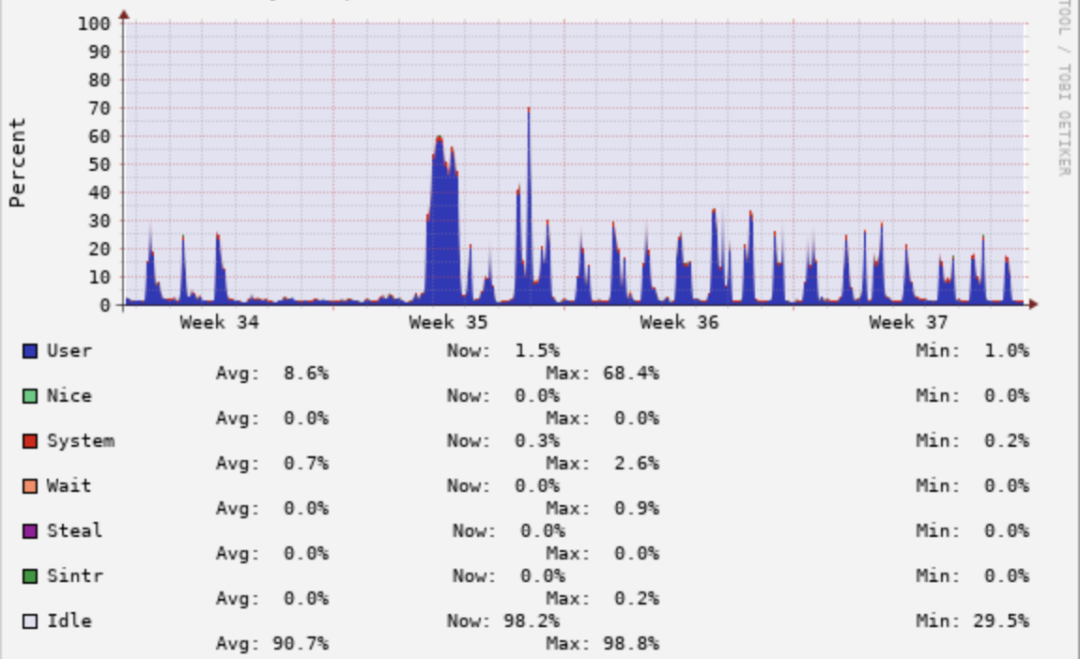
但是如果看最近一個月的CPU使用率會發現,平均CPU使用率比較低,且波峰在白天10~18點,晚上基本上沒有查詢,CPU使用率不到5%。如下圖所示:
所以,解決晚上資源浪費問題是我們今後需要解決的難題。
同時,為了不與開源社群脫節,我們打算升級PrestoDB 0.215到PrestoSQL 340版本,屆時會把我們的Presto on Druid程式碼開源出來,回饋社群。
本文作者
▬

滴滴Presto引擎負責人,負責帶領引擎團隊深入Presto核心,解決在海量資料規模下Presto遇到的穩定性、效能、成本方面的問題。搜尋引擎及OLAP引擎愛好者,公眾號:FFCompute
關於團隊
▬
滴滴巨量資料架構部 OLAP & 檢索平臺組負責以 Elasticsearch、Clickhouse、Presto 及 Druid 為代表的 OLAP 引擎的核心級極致優化,為滴滴各個產品線提供穩定可靠的 PB 級海量資料的實時資料分析、紀錄檔檢索、監控及即席查詢服務。
博聞強識,招賢納士,滴滴用廣闊的舞臺,在這裡,等待你!
內容編輯 | Charlotte
聯絡我們 | DiDiTech@didiglobal.com