嵌入式C語言深入篇之 —— 變數
新建一個物聯網行業交流學習QQ群,感興趣可加:928840648
=====CUT=====
變數
當一個C/C++原碼檔案被編譯鏈(比如gcc/g++)編譯及連結成為可執行程式後,由4個段組成,分別是:程式碼段,資料段,棧,堆。
程式碼段(.text)包含程式碼邏輯(函數),以及宏定義(#define)常數。
資料段包含3部分:.bss,.rodata,.data。
.bss: Block Started by Symbol,存放程式中未初始化的全域性變數。
.rodata:read only data,用於存放不可變修改的常數資料。
.data:靜態變數和已初始化的全域性變數儲存區。
棧(.stack)主要用來存放區域性變數, 傳遞的引數, 存放函數的返回地址;程式執行過程中動態生成及回收,不需要使用者回收儲存空間。
堆(.heap)由malloc等API動態分配的記憶體區域,其生命週期由free決定;程式執行過程中動態生成,需要由使用者自行回收。
瞭解程式的組成儲存區有利於開發過程中對程式的精簡,比如我們可以選擇變數內容及大小是直接編譯進可執行程式(ROM)中,還是程式執行過程中才被範例化(RAM);如果程式碼量10W+行基本能很明顯的出現差異,同樣功能有的程式碼編譯出來佔用空間非常大,有的很精簡,其中一個原因就是對底層儲存分割區的理解不同。
在我們Ubuntu Server目錄:~/workspace/basics/c/3_2_variables,存放著本章節我們會用到的原始碼檔案;其中main_1.c的內容是針對變數/函數的分割區儲存結構做了描述:
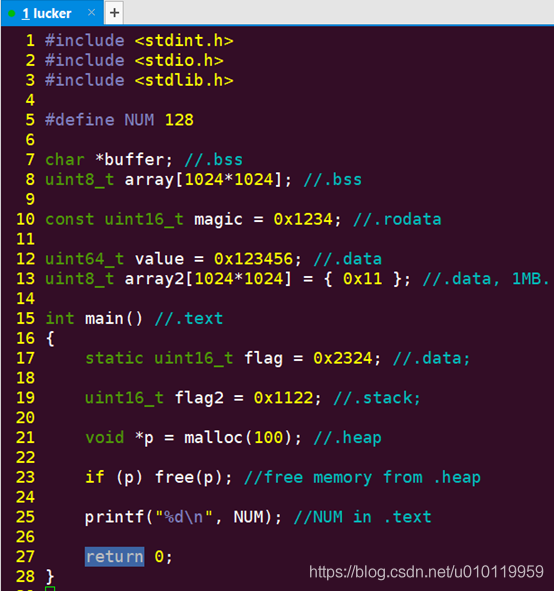
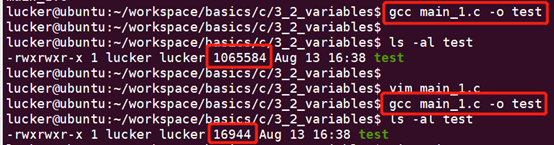
我們嘗試保留及註釋掉.data裡面的一個儲存空間,對比兩者編譯後程式的大小。
![]()
差別巨大:
本節內容原始碼在:~/workspace/basics/c/3_2_variables/main_2.c中,主要講解C語言中的動態型別變數定義的方法,需要使用到的關鍵字是:typeof(),該關鍵字是GNU C提供的一種特性,可以用來取得變數/函數的型別,或者表示式的型別。常用的方式如下:
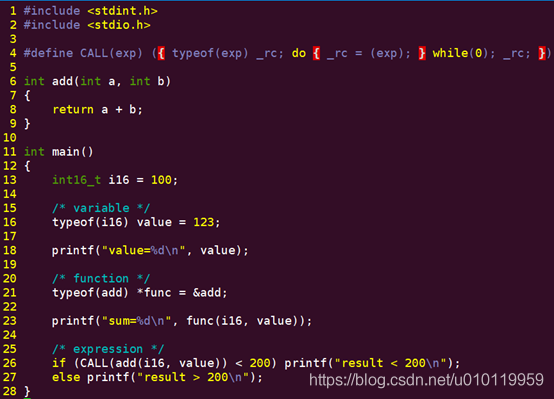
取得變數型別。
定義一個變數,可以是普通變數也可以是指標變數,然後typeof取得該變數型別並用於定義另外同型別的變數;比如圖中所示的value。
取得函數型別做函數指標。
主要用來取得函數的型別,並定義函數指標使用,圖中所示的指標func就是取著函數add型別定義的。
取得表示式型別做處理。
取得表示式相對較為複雜,圖中所示,我們將函數add的運算結果匯出來用於判斷;該技巧同樣可以用於函數呼叫失敗後的多次重試。
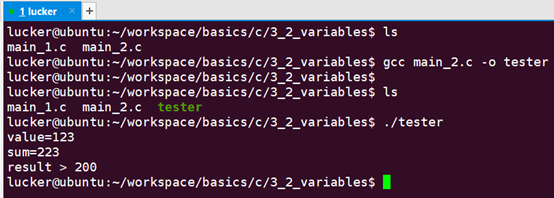
編譯執行如下:
型別轉換
在C語言中,進行型別之間的轉換有兩種轉換方式:隱式型別轉換 和 強制型別轉換。其中強制型別轉換是由開發人員完成的,比如float val = (float)u8;
一般不會出現問題,所以我們重點關心隱式型別轉換。
隱式型別轉換是由編譯器主動完成的,如果由低型別到高型別的隱式型別轉換是安全的,不會發生截斷;相反由高型別到低型別的隱式型別轉換是不安全的,會發生截斷產生不正確的結果:

四種情況下會發生隱式型別轉換:賦值,算術運算,函數傳參,函數返回值。
在原始碼檔案:main_3.c中,我們列出了四種情況的例子:
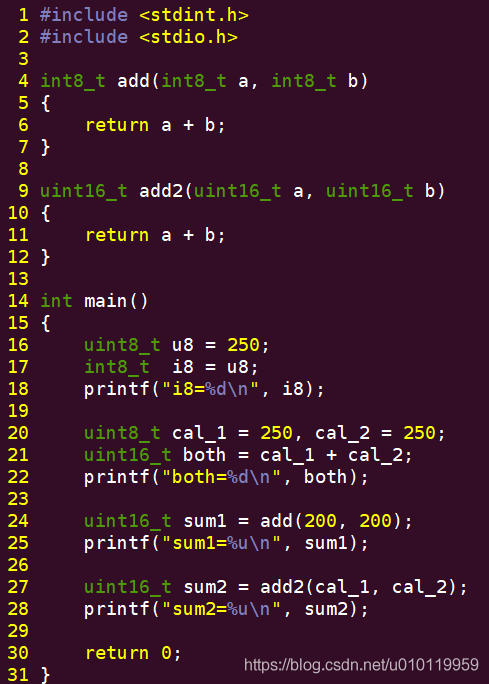
賦值。
圖中我們定義的型別uint8_t u8,並賦值為250;同時定義int8_t i8,然後把u8賦值給i8,顯然這個過程出現型別不匹配的轉換,由於250已經超過i8的最大範圍,因此i8不在是數值250了。
算術運算。
兩個uint8_t型別相加,賦值給uint16_t,實際上編譯器在執行該條指令時,會把兩個uint8_t先轉換為uint16_t,所以圖中:
uint16_t both = cal_1 + cal_2; 等價於:
uint16_t both = (uint16_t)cal_1 + (uint16_t)cal_2;
隱式型別轉換後資料正確。
函數傳參。
函數add的引數型別都是int8_t,而我們傳入的200已經超過最大範圍,因此傳入的資料發生大型別到小型別的轉換;同時函數返回值是int8_t,兩個超過範圍的int8_t相加得不到200+200=400的數值,如果相加也出現溢位,那麼返回值更加不可測了。
函數返回值。
函數add2的引數和返回值都是uint16_t,我們傳入的兩個uint8_t被轉換為uint16_t,運算結果數值也是uint16_t,因此返回數值正確。
編譯執行:
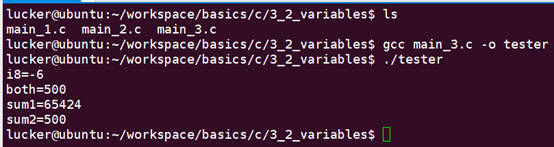
在編寫程式的過程中,我們需要留意可能存在隱式型別轉換的地方,避免由於資料型別轉換導致的結果不可預測。