孿生網路:使用雙頭神經網路進行元學習
深度神經網路有一個大問題-他們一直渴望資料。 當資料太少時(無法到達演演算法可以接受的數量)深度神經網路很難推廣。 這種現象突出了人類和機器認知之間的差距。 人們可以通過很少的訓練範例來學習複雜的模式(儘管速度較慢)。

需要像我們這樣思考的機器
自我監督學習的研究正在發展,以開發完全不需要標籤的結構(在訓練資料本身中巧妙地找到標籤),但其用例卻受到限制。
半監督學習是另一個快速發展的領域,它利用通過無監督培訓學到的潛在變數來提高監督學習的效能。這是一個重要的概念,但其範圍僅限於無監督與受監督資料比率相對較大且無標記資料與標記資料相容的用例。
也許一個主意囊括了所有主意-開發能夠充分利用有限的標記資料的方法和體系結構;使機器更像人類那樣思考。正式名稱是元學習,通常稱為「學習如何學習」。
元學習和自然語言處理中常用的術語是「少次學習」或「零次學習」。這些指的是能夠用很少或沒有(分別)預先訓練模型的資料來識別新概念。零次學習的一個例子是在接受英語到法語和法語到德語翻譯任務的培訓後將英語翻譯成德語。
孿生網路(Siamese network)
讓我們看一下一項需要少量學習的機器學習任務,以及孿生網路的獨特架構是如何實現的。 我們的訓練資料包含十個形狀,屬於四種形狀型別之一。 每個類別的資料量很少,但我們希望能夠歸納和識別新形狀。
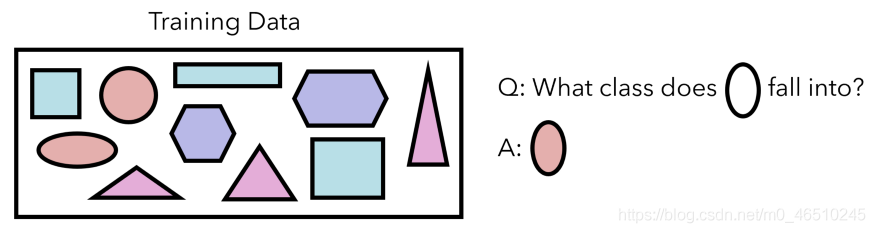
我們的資料集有10個形狀。
孿生神經網路測量兩個輸入屬於同一類別的概率。 從這個意義上講,它不會直接輸出任何輸入的類; 相反,它基於對一個輸入的理解與另一個輸入的顯式關係。 將產生以下資料來訓練模型:
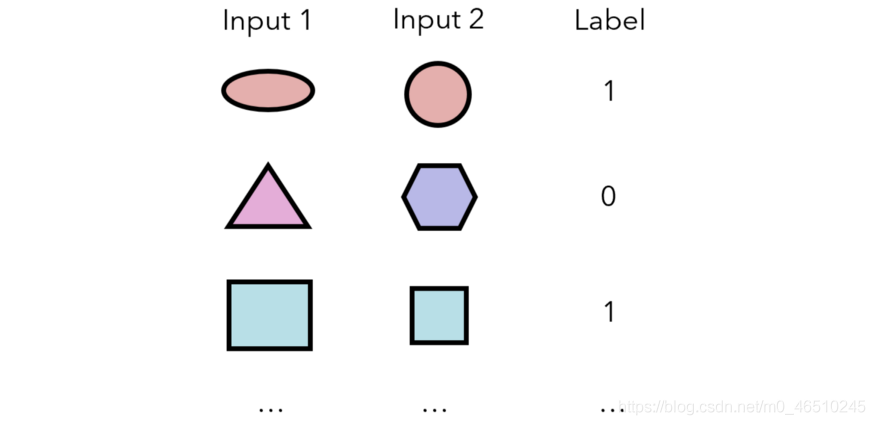
因此,對於資料集中的n個樣本,可以在(n²-n)/ 2個唯一的輸入對(每個輸入之間有n²個可能的配對,兩個相同樣本之間的n個配對,/ 2以考慮a&b和n)上訓練孿生網路。 b&a被視為單獨的組合)。
然後,在預測某些輸入a的過程中,孿生網路對(a,x)進行資料集中每個樣本x的預測。 a的類別是產生最大網路輸出的資料點x的類別。
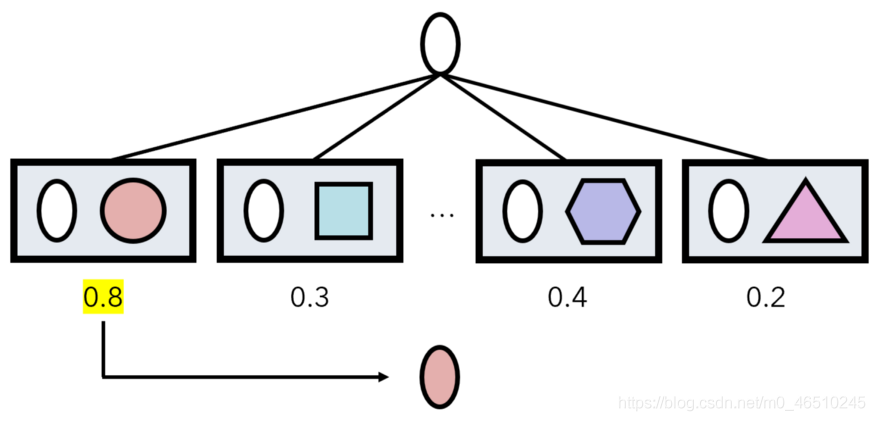
方框代表通過演演算法的預測,數位代表輸出。
孿生網路採用兩個輸入,然後通過嵌入函數將它們(分別)編碼為特徵向量,該函數由幾個折積層組成。 兩個特徵向量通過「距離層」合併,該距離層僅計算L1距離| f1-f2 |。 或者,也可以通過L2,餘弦等計算距離。輸出是距離向量的S型壓縮線性組合。
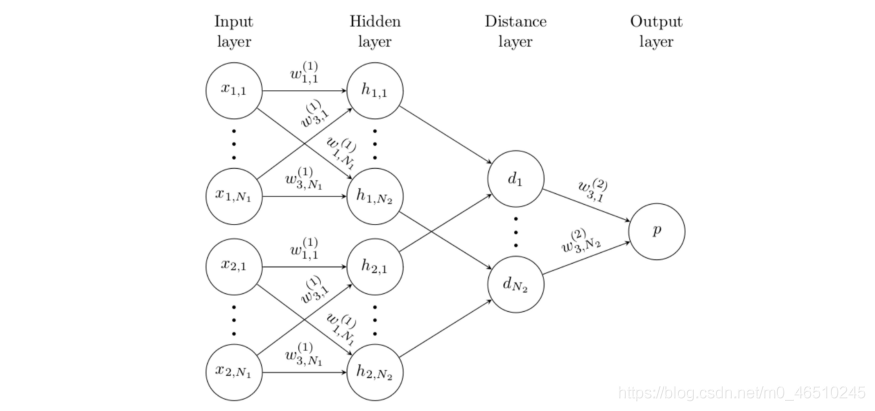
值得一提的是,在這種情況下,「嵌入」實際上只是原始輸入層與折積神經網路的傳統元素(如折積層和池化層)的編碼表示。嵌入的原因是,嵌入點之間的距離被獲取並處理以形成輸出
*注:嵌入定義為一個空間,在該空間中對映點之間的距離意味著某些東西;例如,在NLP嵌入中,單詞「 man」和「 boy」在空間中的物理距離應比「 man」和「 purple」的關係小,例如,它們之間的關係很小。
孿生網路的名稱來自於連體雙胞胎,或雙胞胎在出生時相連的雙胞胎,看起來好像有兩個頭。考慮到孿生網路的出現,這是有道理的。
孿生網路的一個關鍵部分是,雖然有兩個編碼兩個輸入的「頭部」,但它們具有相同的權重。這很有道理; f(a,b)應具有與f(b,a)相同的內部構成。無論輸入的順序如何,編碼過程都必須相同。
可以說孿生網路在影象識別過程中增加了更多的結構。折積神經網路更不用擔心:「這是一個龐大的架構,您可以用它來做您想做的事」;連體網路將影象對映到嵌入(確定影象中的關鍵特徵),通過該嵌入計算距離(直接比較兩者)並進行解釋以得出結果。
孿生網路背後的思想
從根本上講,孿生網路代表了我們對影象識別的看法的轉變。 當機器對彼此相關的概念進行理解時(與傳統的影象識別一樣,從零開始構建表示形式則相反),他們可以學習的資料更少。
這很好地解釋了為什麼人們能夠通過很少的訓練範例就能識別和學習概念。 我們通過複雜的層次結構和相互糾纏的關係來儲存資訊:橙色類似於蘋果,但與汽車有很大不同。 當與現有概念相關地描述一個新概念時,學習會更有效。
作為另一個類推,請考慮以下數位系列:2101、2102、2099、2101、2097、2100、2095。繼續-嘗試記住它,然後再向下捲動。 它很難!
幸運的是,有一種更有效的方式來記憶該集合:表達與前一個數位相關的每個數位。 如果我們記得第一個數位是2101,我們只需要記住1,-3、2,-4、3,-5。 與其處理複雜的大型概念(相對於數量級而言),不如將它們相對於其他物件建立起來,會更加有效。
實際應用與討論
孿生網路可用於一次性學習-通過資料增強僅學習一個訓練範例即可學習概念。 例如,可以對影象進行較小的旋轉,移動和縮放。 由於資料集的大小以n²的速度增長,因此可以提供大量資訊。

此外,它們還可以用於驗證問題(識別同一個人的兩個面孔,兩個指紋,兩個手勢等)—實際上,許多最新的實時面部識別系統都採用了孿生神經網路。 這些網路在執行此任務方面優於標準影象識別體系結構,後者在處理大量分類時遇到了巨大困難(我們正在與成千上萬的人交談)。
通常,孿生網路可以很好地處理類不平衡問題。這使其吸引了諸如影象識別之類的任務。部分原因可以歸因於嵌入的結構性;另一方面,在龐大的折積網路的廣闊區域中,微小的的特徵往往被過濾掉了。
通常,答案是簡單地使折積神經網路變大,但是網路的持續超大型化已成為現實的極限。
重要的是要意識到,儘管預測過程可能很長(遍歷資料中的每個樣本),但實際上孿生網路是在小型資料集上進行訓練的,而孿生網路通常需要較小的體系結構,同時還要加深理解。另外,實際上,項的嵌入通常是預先計算和快取的,因為它們的值經常使用。
它們還可以用於排名問題,在該問題中,網路輸出的不是兩個輸入是否屬於同一類,而是輸出第一個輸入是否排名高於第二個輸入,以及相似性問題(例如測量兩個摘錄的內容) 。
此外,孿生網路可以適用於任何資料型別,包括影象之外的那些文字和結構化資料。
還需要注意的是,孿生網路會產生非常非常好的嵌入。與其他成熟的流形學習方法(例如t-SNE和IsoMap)相比,它們的生產成本更高,但是是很好的輔助結果。這可能是其獨特架構的結果。

總結
- 當前的深度學習解決方案需要太多資料。 像自我監督和半監督學習這樣的努力可以充當輔助,但是更深層的問題是機器的思維方式不像人類。 元學習旨在讓AI學習學習。
- 孿生網路採用兩個輸入,使用與嵌入相同的權重對其進行編碼,解釋嵌入的差異,並輸出兩個輸入屬於同一類的概率。
- 孿生網路能夠更有效地學習,因為它們在先前的學習中立足於新概念,而不是盲目地從頭開始學習每一個新概念。 這就是為什麼常規大小的神經網路無法執行具有大量類的任務的原因。
- 孿生網路的一些優勢包括良好的泛化能力,每個類別只有一個資料點,以及對類別不平衡的強大魯棒性。
孿生網路論文:http://www.cs.toronto.edu/~rsalakhu/papers/oneshot1.pdf
作者:Andre Ye
deephub翻譯組