智算之道——人工智慧應用挑戰賽(初賽)-baseline 0.844
2020-10-09 13:00:14
智算之道——人工智慧應用挑戰賽(初賽)-baseline
比賽型別:資料探勘
比賽資料:表格題(csv)
學習方式:有監督
比賽連結
比賽任務:疾病的預測往往能夠從病人的病歷歷史資料探勘當中判斷,而許多有價值的發現也往往是在對於結構化資料的建模與分析之中得出。本賽題希望通過結構化的資料預測與分析,判斷一名病人的是否患有肝炎。
提交結果

注:本baseline僅供大家快速上手和提交
目錄
1 專案建立和使用

從上圖的平臺入口進入平臺——工作臺——新建專案(填寫專案名稱和專案描述即可),之後在專案建立notebook便可進入環境
2 資料讀取
2.1 匯入相關庫
import os
import pandas as pd
import warnings
from itertools import combinations
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.preprocessing import LabelEncoder, MinMaxScaler
from sklearn.model_selection import StratifiedKFold
from tqdm import tqdm
from xgboost import XGBClassifier
from lightgbm import LGBMClassifier
from catboost import CatBoostClassifier
%matplotlib inline
warnings.filterwarnings('ignore')
pd.set_option('display.max_rows',None)
pd.set_option('display.max_columns',None)
2.2 讀取資料
資料集路徑在 ‘/home/kesci/data/competition_A/’ 下
path = '/home/kesci/data/competition_A/'
train_df = pd.read_csv(path+'train_set.csv')
test_df = pd.read_csv(path+'test_set.csv')
submission = pd.read_csv(path+'submission_example.csv')
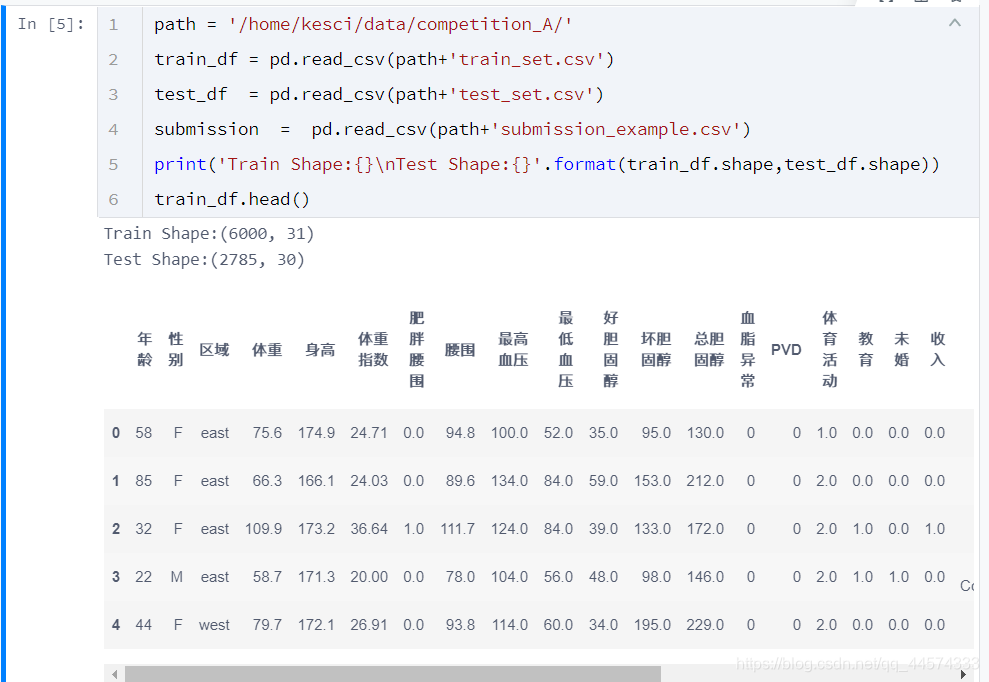
print('Train Shape:{}\nTest Shape:{}'.format(train_df.shape,test_df.shape))
train_df.head()
2.3 資料EDA
findfont: Font family [‘sans-serif’] not found. Falling back to DejaVu Sans.
對不起,環境中沒有SimHei字型,sns的中文暫時沒法顯示
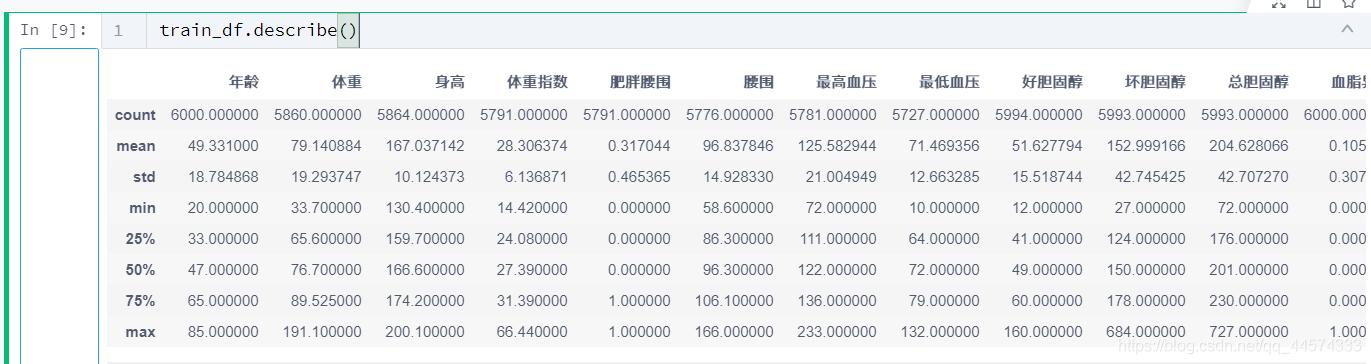
根據訓練集的列可以得到大致如下三種特徵:數位列、二值列(0或1)、字元列
num_columns = ['年齡','體重','身高','體重指數', '腰圍', '最高血壓', '最低血壓',
'好膽固醇', '壞膽固醇', '總膽固醇','收入']
zero_to_one_columns = ['肥胖腰圍','血脂異常','PVD']
str_columns = ['性別','區域','體育活動','教育','未婚','護理來源','視力不佳','飲酒','高血壓',
'家庭高血壓', '糖尿病', '家族糖尿病','家族肝炎', '慢性疲勞','ALF']
肝炎與年齡
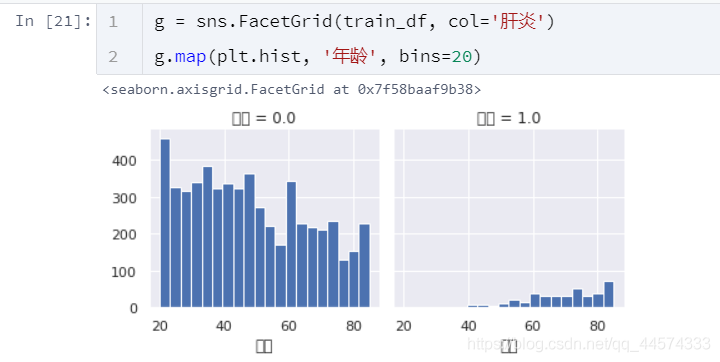
從上圖中可以看出在訓練集中患肝炎的年齡都是比較大的,也就是說年齡將會是一個很重要的區分是否患肝炎特徵
暫時先不畫了,如果解決了中文字型,會持續更新
2.4 特徵工程
字元編碼,將如[‘A’,‘B’,‘C’,‘D’]編碼成[0,1,2,3]
# 字元編碼
for i in tqdm(str_columns):
lbl = LabelEncoder()
train_df[i] = lbl.fit_transform(train_df[i].astype(str))
test_df[i] = lbl.fit_transform(test_df[i].astype(str))
資料歸一化
# 數值歸一化
train_df[num_columns] = MinMaxScaler().fit_transform(train_df[num_columns])
test_df[num_columns] = MinMaxScaler().fit_transform(test_df[num_columns])
空值填充
train_df.fillna(0,inplace=True)
test_df.fillna(0,inplace=True)
3 模型
3.1 準備資料集
all_columns = [i for i in train_df.columns if i not in ['肝炎','ID']]
train_x,train_y = train_df[all_columns].values,train_df['肝炎'].values
test_x = test_df[all_columns].values
submission['hepatitis'] =0
3.2 訓練模型
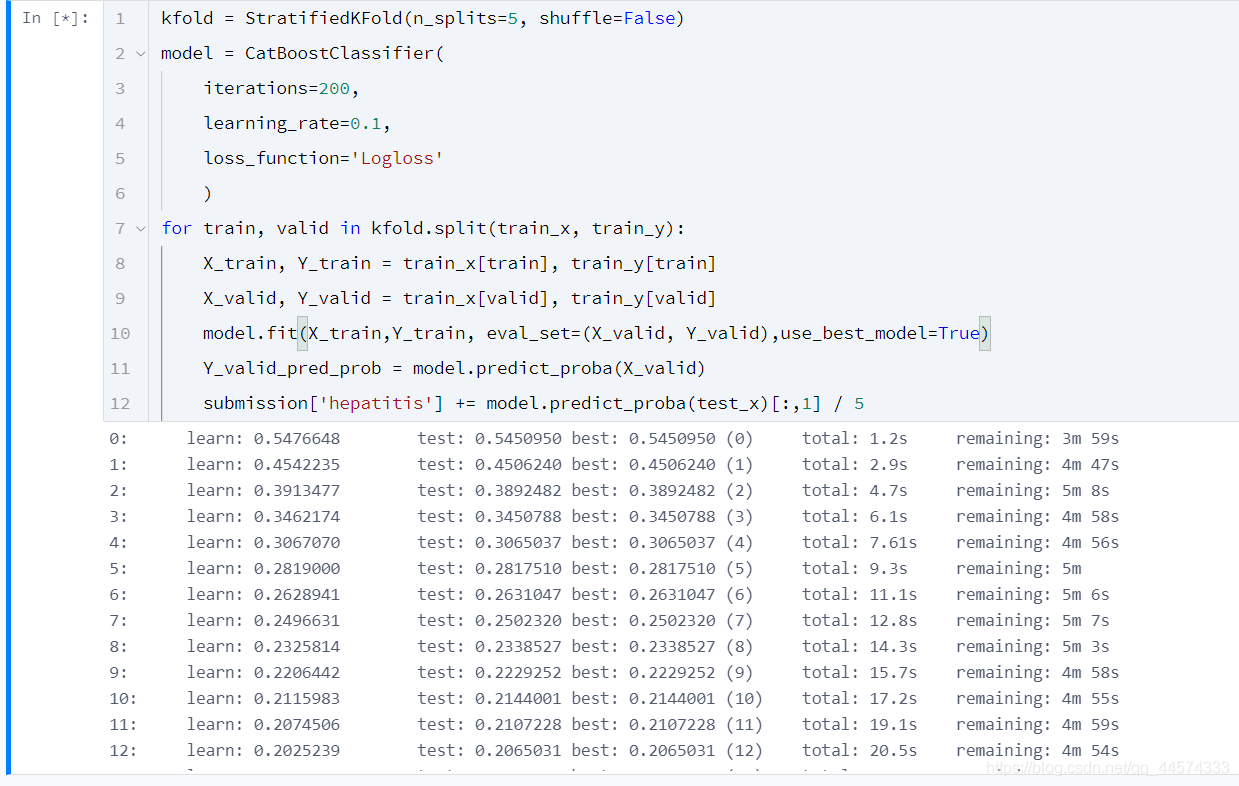
kfold = StratifiedKFold(n_splits=5, shuffle=False)
model = CatBoostClassifier(
iterations=200,
learning_rate=0.1,
loss_function='Logloss'
)
for train, valid in kfold.split(train_x, train_y):
X_train, Y_train = train_x[train], train_y[train]
X_valid, Y_valid = train_x[valid], train_y[valid]
model.fit(X_train,Y_train, eval_set=(X_valid, Y_valid),use_best_model=True)
Y_valid_pred_prob = model.predict_proba(X_valid)
submission['hepatitis'] += model.predict_proba(test_x)[:,1] / 5
3.3 提交
下述程式碼只需注意修改token即可
!wget -nv -O kesci_submit https://cdn.kesci.com/submit_tool/v4/kesci_submit&&chmod +x kesci_submit
submission.to_csv('submission.csv',index=False)
!./kesci_submit -token '你的隊伍Token' -file '/home/kesci/work/submission.csv'
完整ipynb檔案可見Github