【資料結構與演演算法】高階排序(希爾排序、歸併排序、快速排序)完整思路,並用程式碼封裝排序函數
本系列文章【資料結構與演演算法】所有完整程式碼已上傳 github,想要完整程式碼的小夥伴可以直接去那獲取,可以的話歡迎點個Star哦~下面放上跳轉連結
本篇文章來講解一下更高階的排序演演算法,顧名思義,它們的排序思想一定更復雜,效率也一定比簡單排序更高。為了更方便地理解高階排序演演算法,還是建議大家先把簡單排序瞭解清楚,因為高階排序也多少借鑑了簡單排序的思想,下面放上文章連結
【資料結構與演演算法】簡單排序(氣泡排序、選擇排序、插入排序)完整思路,並用程式碼封裝排序函數
那麼就讓我們來了解一下三種高階排序演演算法吧
一、希爾排序
希爾排序是插入排序的改進版本,彌補了插入排序在某些情況下的缺點。
例如,當長度為100的陣列,前面有序區域的陣列長度為80,此時我們用第81個數去跟前面有序區域的所有元素比較大小,但恰巧第81個數又是這100個數裡最小的,它本應該在索引為1的位置,如圖所示
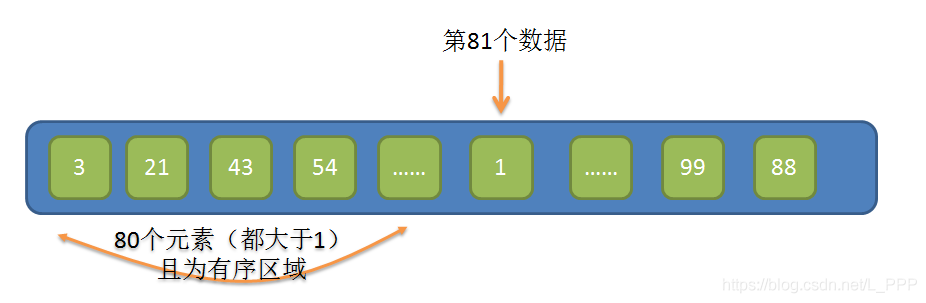
本例中第81個資料的值為1,那麼前面有序區域裡的80個元素都要往後移動一個位置,這種情況就非常影響排序效能。
因此,我們就要想辦法儘可能早點讓小的值靠前,讓大的值靠後,這樣就能避免上述情況了,這就是希爾排序要解決的問題。
希爾排序也叫做縮小增量排序,它通過先設定一個增量n,大小為陣列長度的一半,將間隔為n的元素視作一個組,然後對每個組內部的元素進行從小到大進行插入排序;然後再將增量n縮小一半,再次進行分組插入排序,直到增量n為1,因為增量為1的時候,所有的元素都為同一個組了
為了方便大家理解,我用一個例子來展示一個完整的希爾排序過程,首先資料的初始狀態如圖所示,這裡為了更好地體現希爾排序的優點,我特地把值較大的元素放到了靠左的位置,把值較小的元素放到了靠右的位置

該陣列長度為8,因此我們設定初始的增量為 8 / 2 = 4,那麼該陣列的分組情況如下圖所示:

圖中顏色相同的元素為一組,每組內的各個元素間隔都為4,現在對每個組內進行從小到大排序,排序結果如下圖所示:

此時我們將增量縮小一半,即 4 / 2 = 2,同樣的,現在將所有元素重新組合,把所有間隔為2的元素視作一組,分組結果如下圖所示:

圖中顏色相同的元素為一組,每組內的各個元素間隔都為2,現在對每個組內進行從小到大排序,排序結果如下圖所示:

我們繼續將增量縮小一半,即 2 / 2 = 1,同樣的,現在將所有元素重新組合,把所有間隔為1的元素視作一組,此時所有的元素都為同一組了,就相當於對所有的資料進行普通的插入排序,我們可以看到,對比最開始的資料,總得來說,小的值都比較靠左了,大的值也都比較靠右了,這樣排序起來效率就很高了。結果如下圖所示:

接下來用一個動圖,演示一下完整的希爾排序全過程
瞭解完了希爾排序的實現過程,我們現在用程式碼來封裝一下
function shellSort(arr) {
// 1. 獲取陣列長度
let length = arr.length
// 2.獲取初始的間隔長度
let interval = Math.floor(length / 2)
// 3. 不斷地縮小間隔的大小,進行分組插入排序
while(interval >= 1) {
// 4. 從 arr[interval] 開始往後遍歷,將遍歷到的資料與其小組進行插入排序
for(let i = interval; i < length; i++) {
let temp = arr[i]
let j = i
while(arr[j - interval] > temp && j - interval >= 0) {
arr[j] = arr[j - interval]
j -= interval
}
arr[j] = temp
}
// 5. 縮小間隔
interval = Math.floor(interval / 2)
}
return arr
}
來用剛才舉得例子來驗證一下我們封裝的希爾排序是否正確
let arr = [63, 76, 13, 44, 91, 8, 82, 3]
let res = shellSort(arr)
console.log(res)
/* 列印結果
[3, 8, 13, 44, 63, 76, 82, 91]
*/
上述情況中,希爾排序最壞情況下的時間複雜度為O(n²)。其實希爾排序的時間複雜度跟增量也有關係,我們上面是通過陣列長度一直取一半獲取的增量,其實還有一些別的增量規則,可以使得希爾排序的效率更高,例如Hibbard增量序列、Sedgewick增量序列,本文就不對這兩種增量做過多的講解了,大家可以去網上搜尋一下。
二、歸併排序
歸併排序的實現是使用了一種分而治之的思想,即將一個陣列不斷地通過兩兩分組的方式進行比較大小,最後直到所有元素都被分到一組裡,那自然就是整體有序的了。
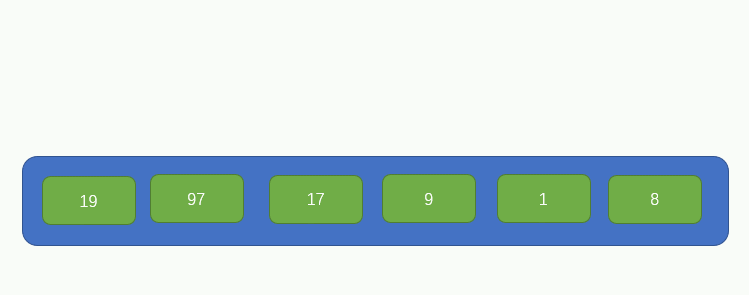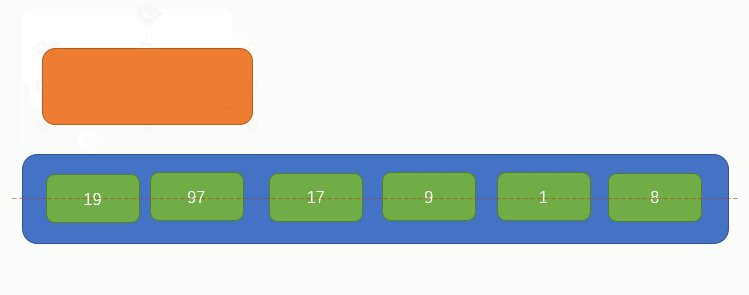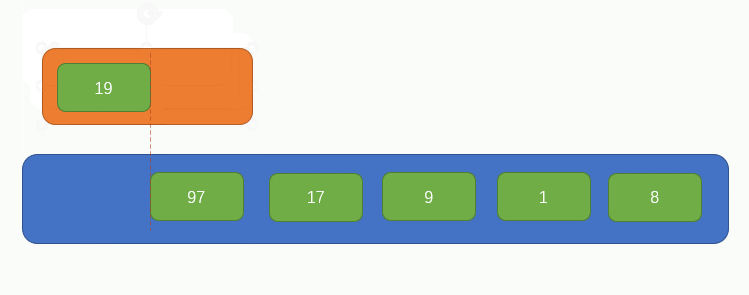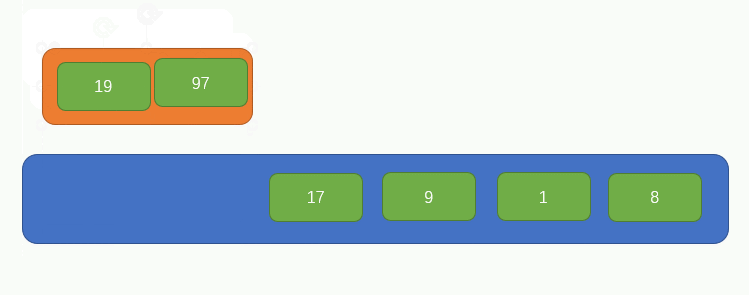
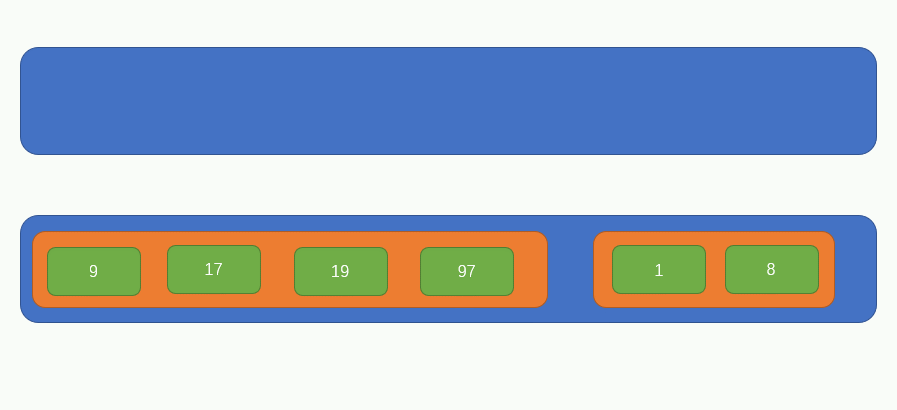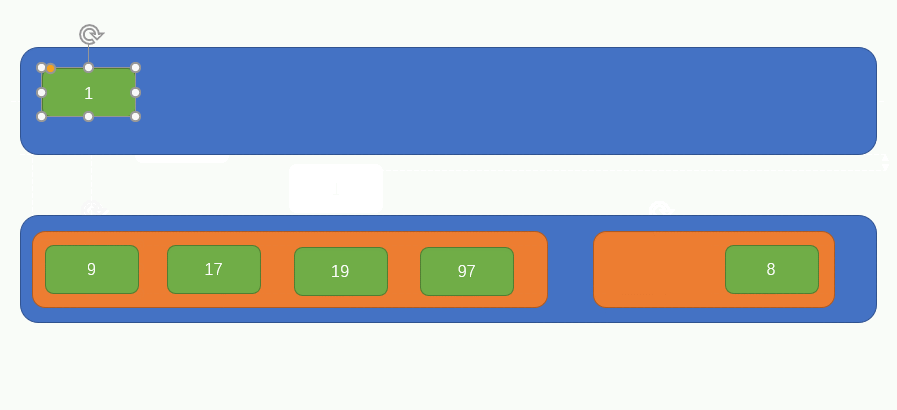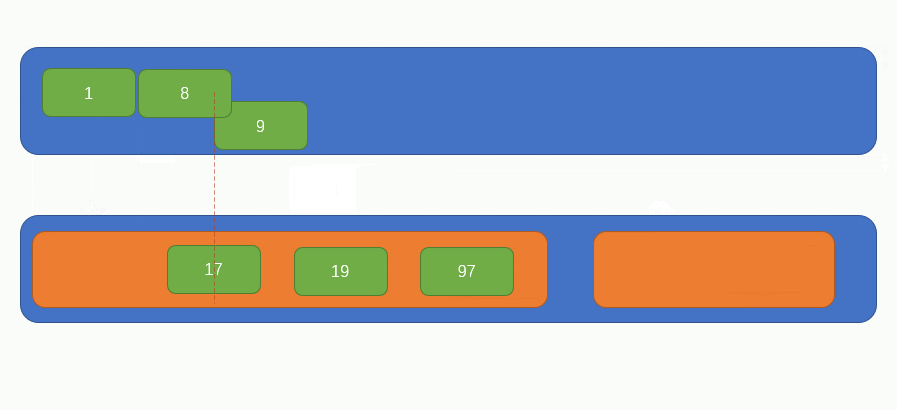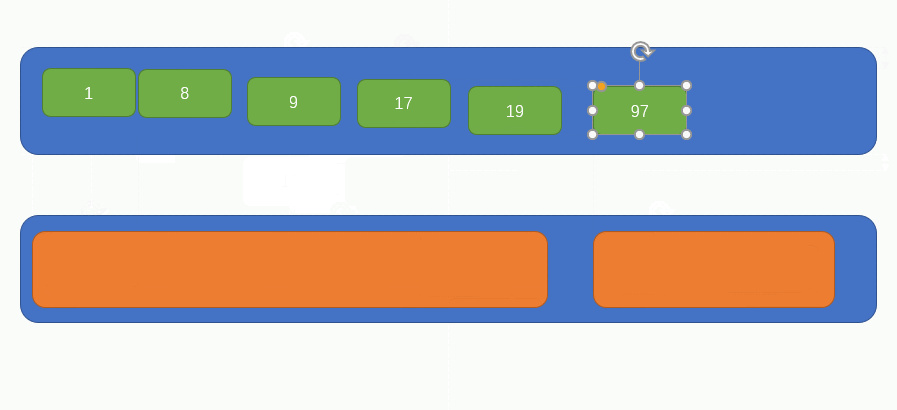
我們來看一下歸併排序的主要思路,首先有如下圖所示排列的一組資料:
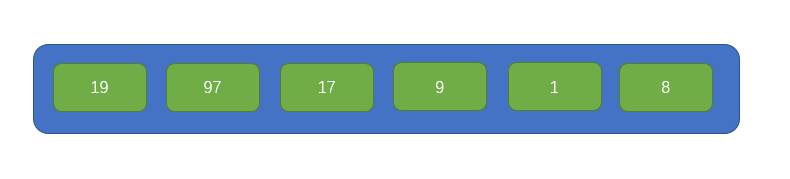
首先從左往右,每兩個元素視為一組,組合前要分別判斷一下這兩個元素的大小,小的在左,大的右,如圖所示
繼續再取兩個元素組成一組並比較大小,如圖所示:
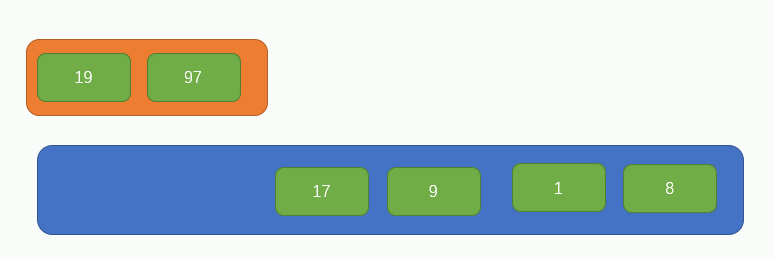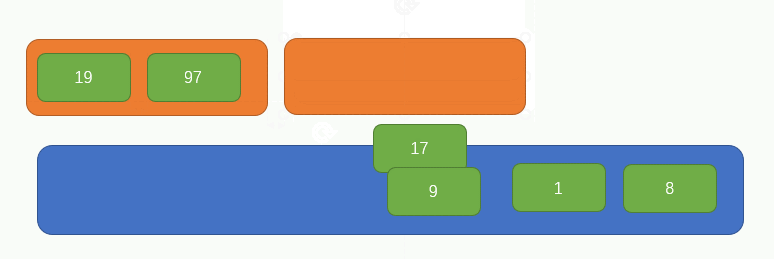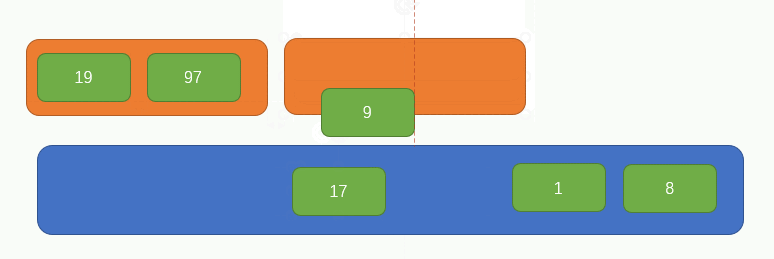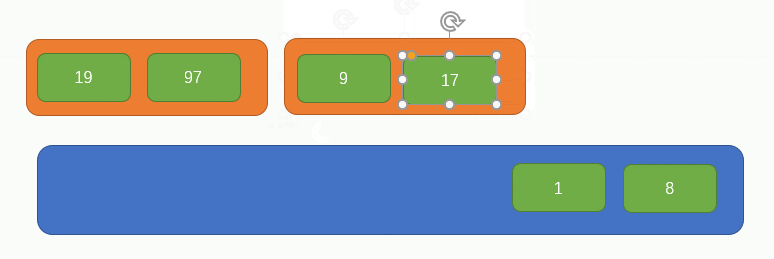
繼續上一個步驟,如圖所示:
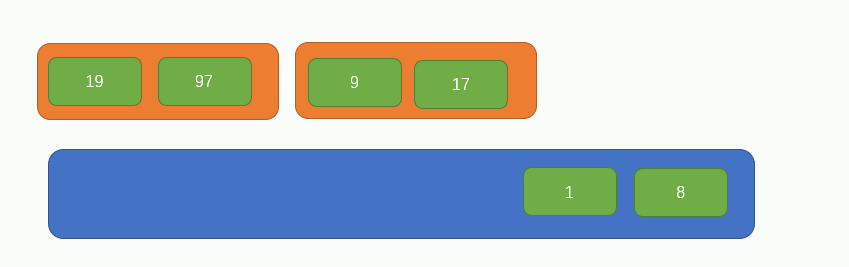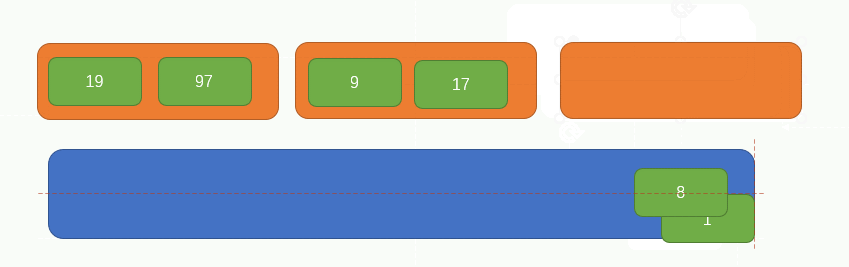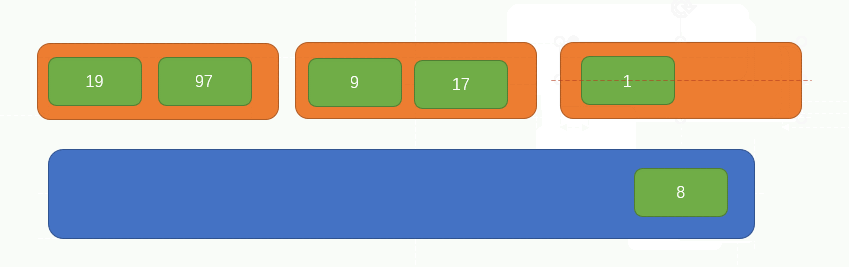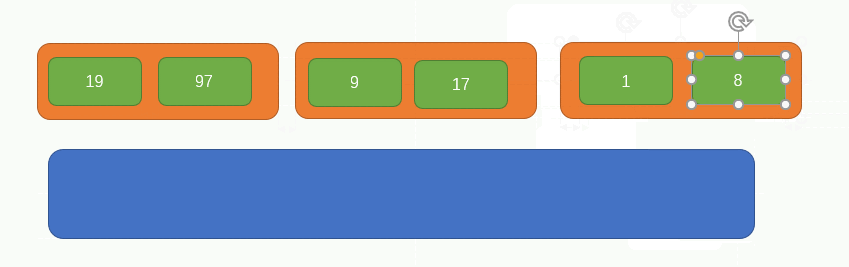
此時,原陣列的所有元素都被兩兩分組完畢了,現在整個陣列的長度變成了3,如下圖所示:

此時,我們要重新從左向右,每次取兩個元素組成一組,同時分別比較兩個元素內的所有子元素的大小,因為此時的兩個元素內部是有序的,所以我們比較兩者大小的話,只需要每次比較陣列的第一個元素即可,過程如下圖所示:
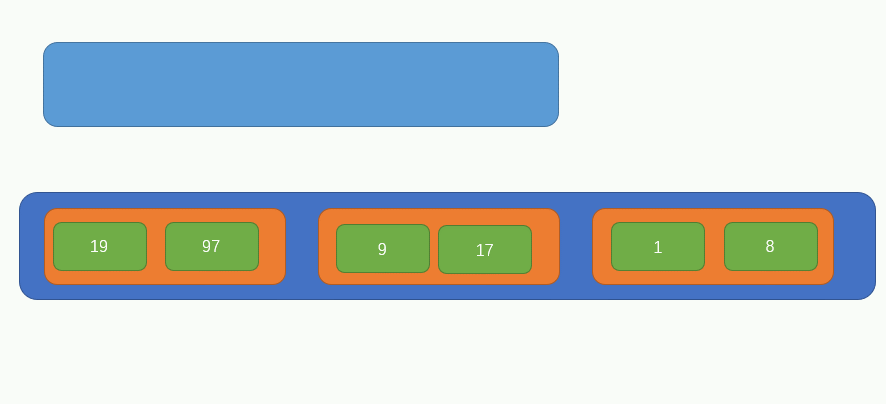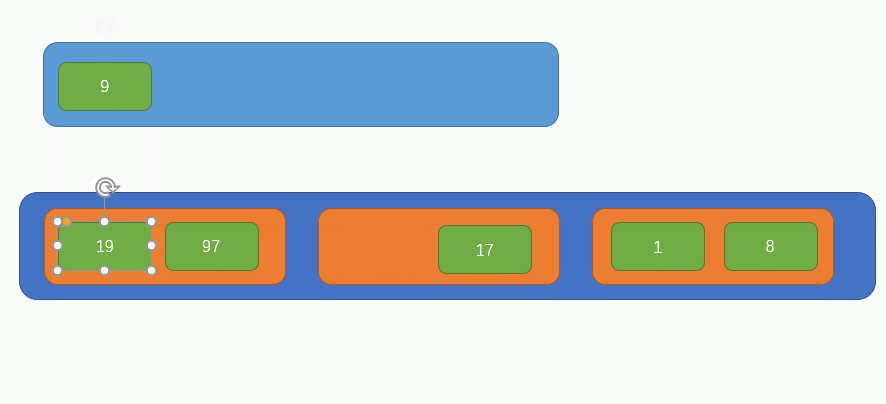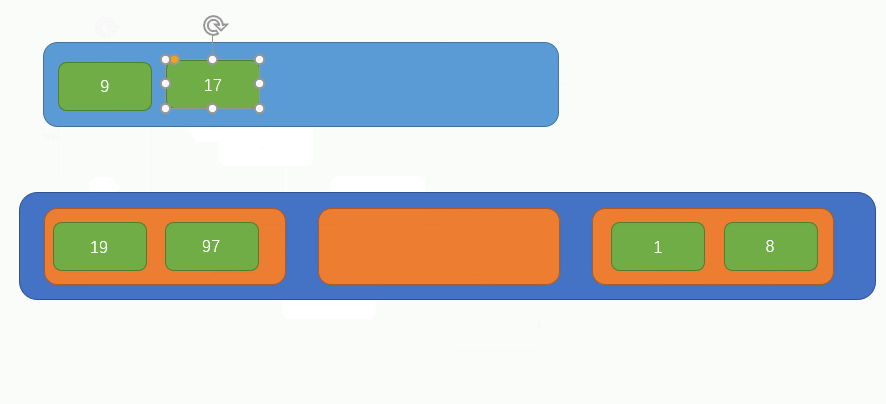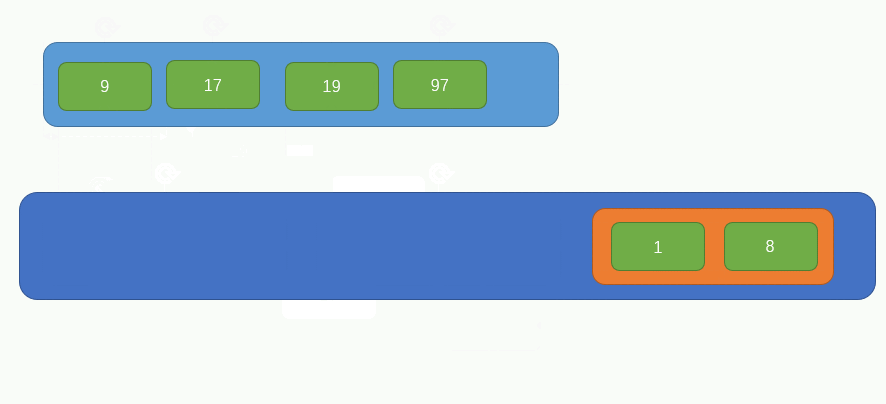
此時原陣列中只剩下一個元素了,所以就不對其做任何組合處理了,此時的陣列是這樣的:
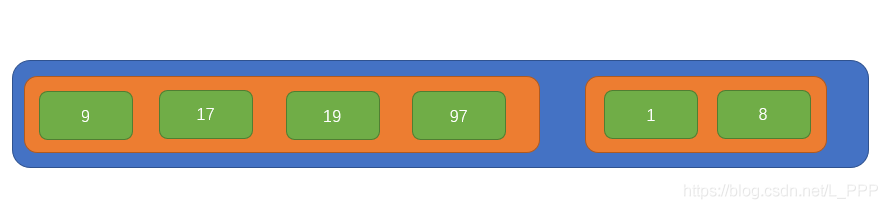
此時的陣列內只有兩個元素了,所以我們只需要不斷比較兩個元素內部的子元素大小,即可獲得完整的有序陣列了,過程如下圖所示:
這就是一個完整的歸併排序的過程,接下來我們用程式碼來實現一下吧
function mergeSort(arr) {
// 將所有元素不斷地兩兩組合,直到所有元素都被組合成一個組
while(arr.length > 1){
// 獲取一下遍歷前的陣列長度,方便下面判斷需要組合幾次
let length = arr.length
// 建立空的新陣列,用於存放所有組合後的元素
let next_arr = []
// 取兩個元素進行組合,一共取 length / 2 次
for(let i = 0; i < Math.floor(length / 2); i++){
// 取出第一個元素
let left = [].concat(arr.shift())
// 取出第二個元素
let right = [].concat(arr.shift())
// 建立另一個新的空陣列,用於存放組合後的所有元素
let new_arr = []
// 取兩個陣列中頭部最小的值放到新陣列中,直到一個陣列為空
while(left.length > 0 && right.length > 0){
let min = left[0] > right[0]? right.shift() : left.shift()
new_arr.push(min)
}
// 將合併好的陣列新增到新的陣列中
next_arr.push(new_arr.concat(left.length == 0? right : left))
}
// 判斷是否有一個未成組的陣列
if(arr.length == 1) next_arr.push(arr[0]);
// 將所有組合後的元素構成的新陣列作為下一次遍歷的物件
arr = next_arr
}
// 返回完整有序陣列
return arr[0]
}
我們來使用一下該方法,看看是否正確,為了方便大家理解,我在歸併排序的函數里加了一條列印的程式碼,可以看到每次遍歷後的陣列情況,結果如下
let arr = [19, 97, 9, 17, 1, 8]
mergeSort(arr)
/* 列印結果:
第一次組合後:[ [ 19, 97 ], [ 9, 17 ], [ 1, 8 ] ]
第二次組合後:[ [ 9, 17, 19, 97 ], [ 1, 8 ] ]
第三次組合後:[ [ 1, 8, 9, 17, 19, 97 ] ]
*/
檢視程式碼我們不難發現,歸併排序執行起來非常得佔記憶體,因為在組合的過程中,我們不斷得在建立新的陣列,然後又進行合併。但其比較次數卻非常得少,只在每次合併元素時進行比較,因此歸併排序的效率還是非常得高的。
三、快速排序
快速排序相信大家一定不陌生,就算沒用過也一定聽過,擁有這麼大的名聲,那麼它的排序效率一定很高。而且快速排序也是面試中經常會被問到的,可能會讓你當場手寫哦~所以大家一定要掌握它的核心思想
快速排序也用到了分而治之的思想,它的實現思路非常得有意思:
- 先選一個元素作為基點pivot
- 將其餘元素中所有比pivot小的值放到pivot的左邊;將所有比pivot大的值放到pivot的右邊
- 然後分別對pivot左邊的所有元素、pivot右邊的所有元素從步驟1開始排序依次,直到所有元素完整有序
思路看著很簡單,那麼我們來用一個例子具體看一下快速排序的全過程吧
首先有這樣一組資料,如下圖所示:
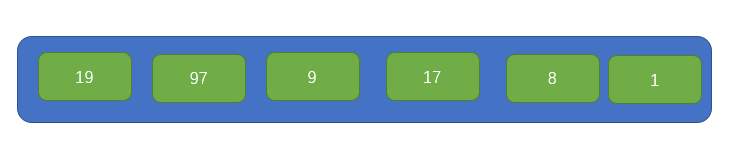
首先我們要選取一個元素作為基點pivot,最後排序完後,pivot左邊的所有元素都是小於pivot的,右邊的所有元素都是大於pivot的,因此我們希望的是儘量是兩邊平均一下,所以這裡將採用一種方式尋找到一個大概的中點,即取陣列兩頭的索引,分別為left 、right,再取一箇中點 center,結果如下圖:
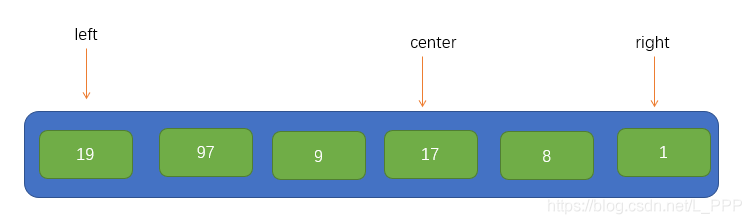
然後在這三個元素中找到一箇中等大小的值,並將其放到陣列的開頭位置,如下圖所示:
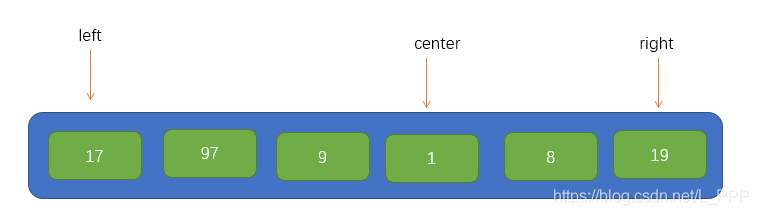
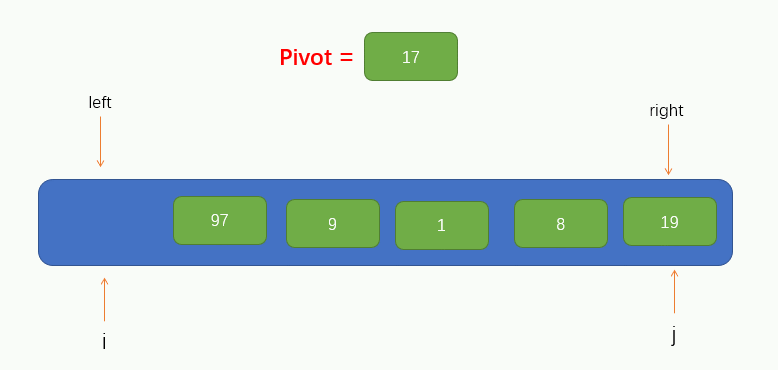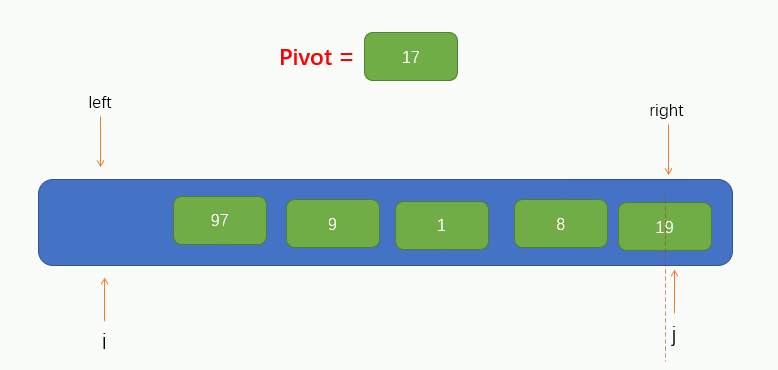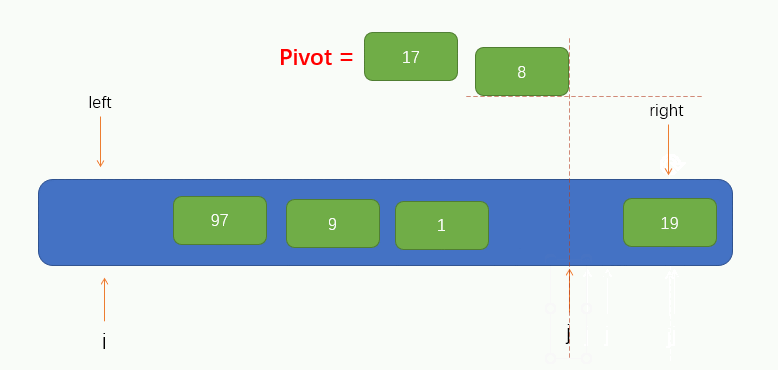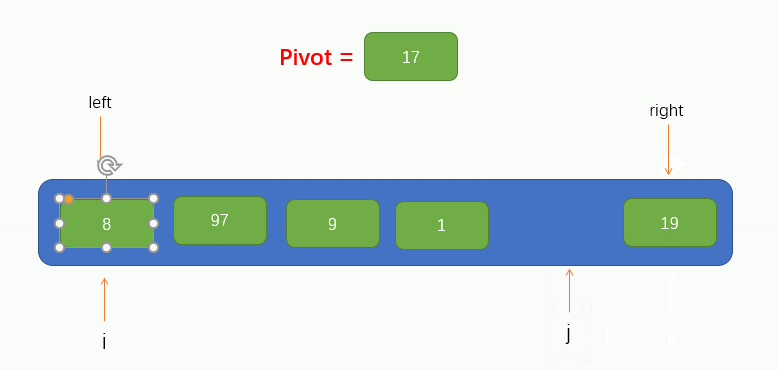
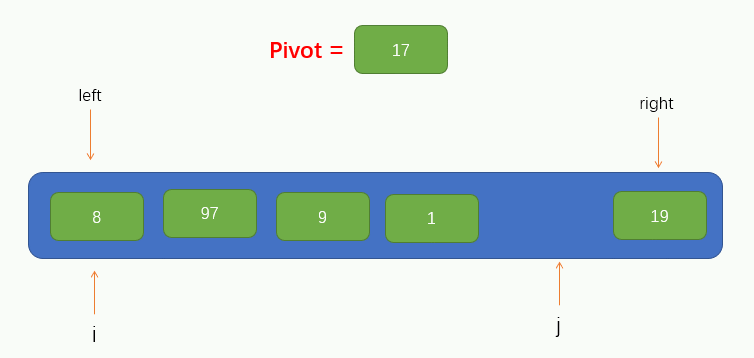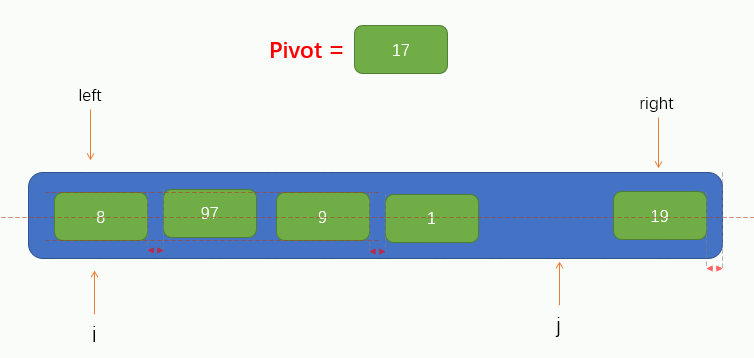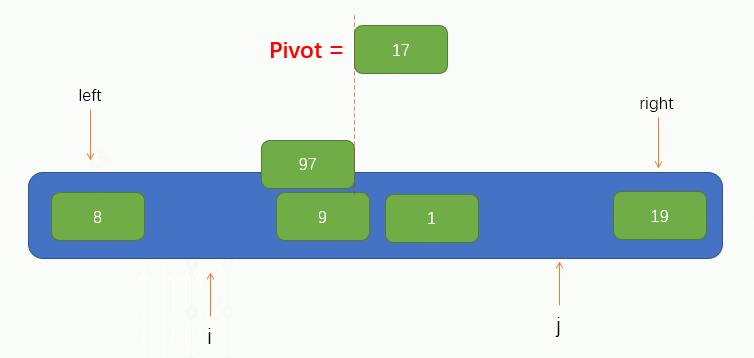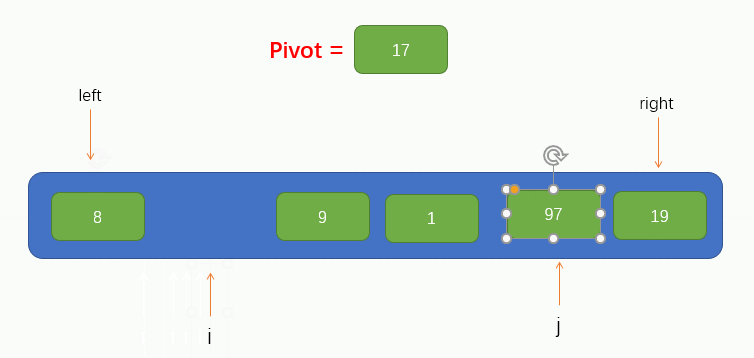
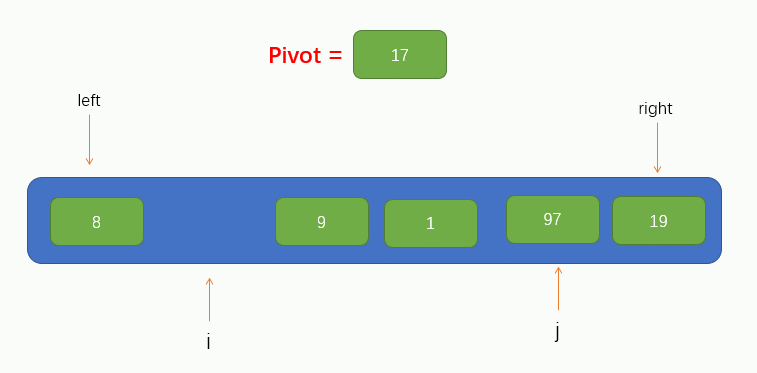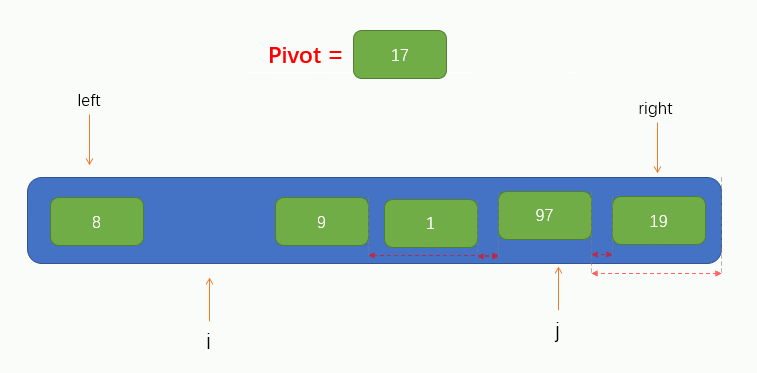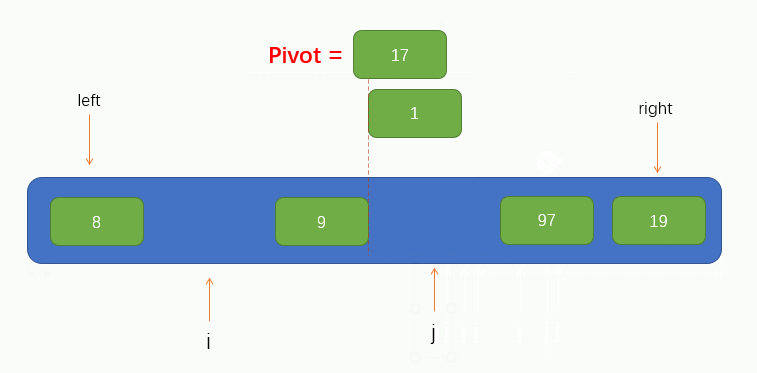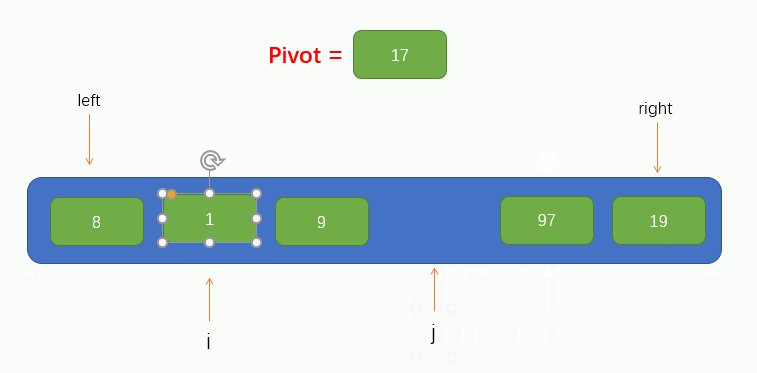
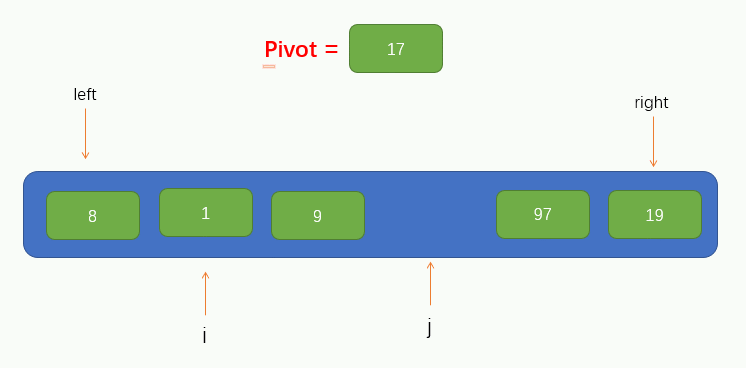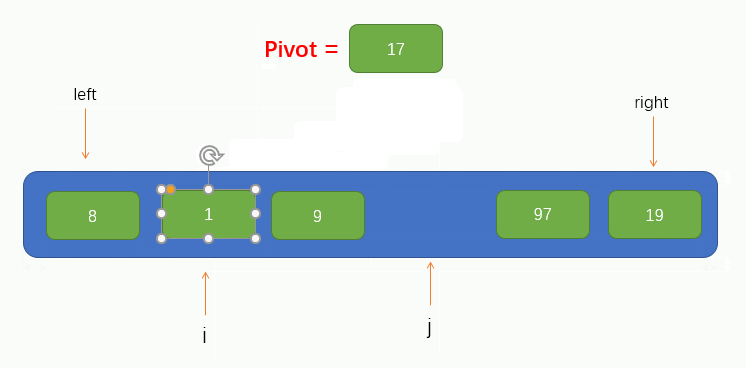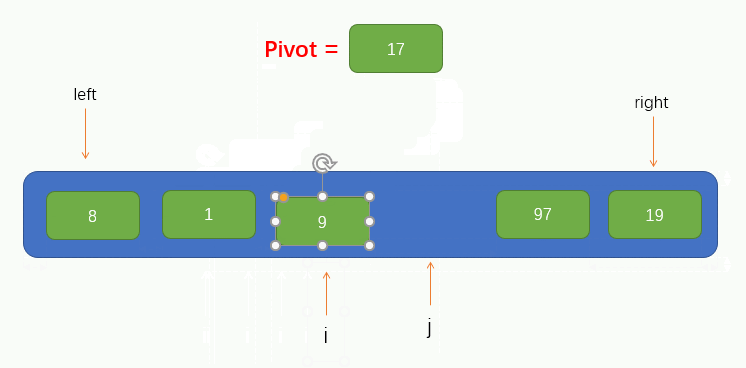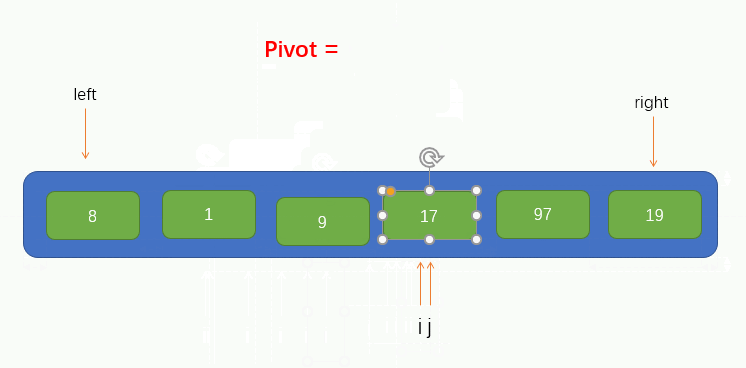
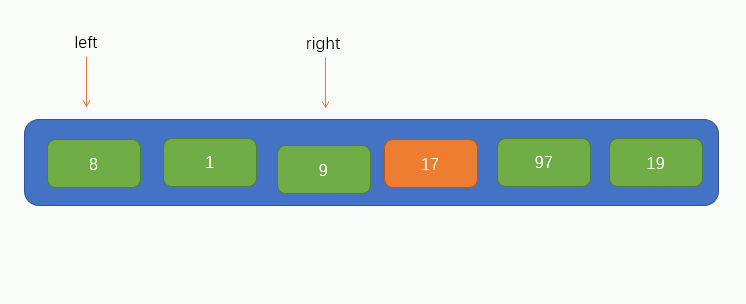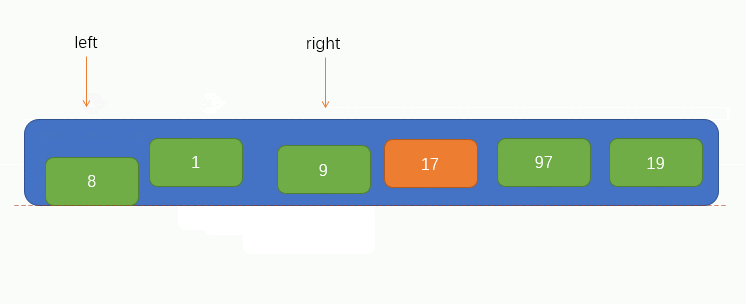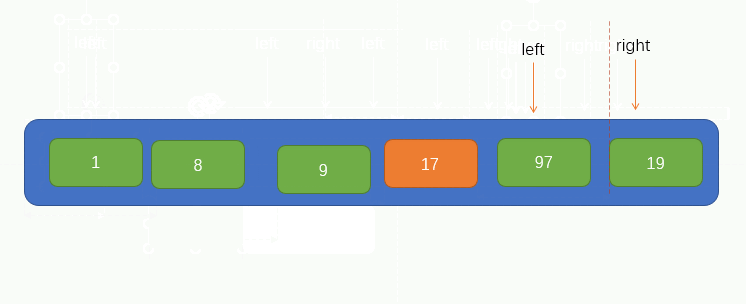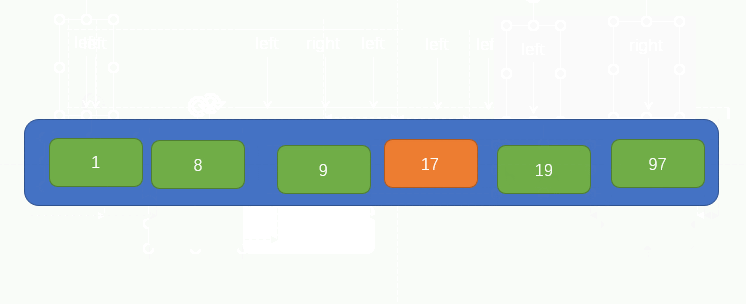
到此,我們就可以將該陣列的第一個元素作為此次遍歷的基點pivot了,同時,我們將引入兩個指標,即 i 和 j,分別指向 left 和 right,如圖所示
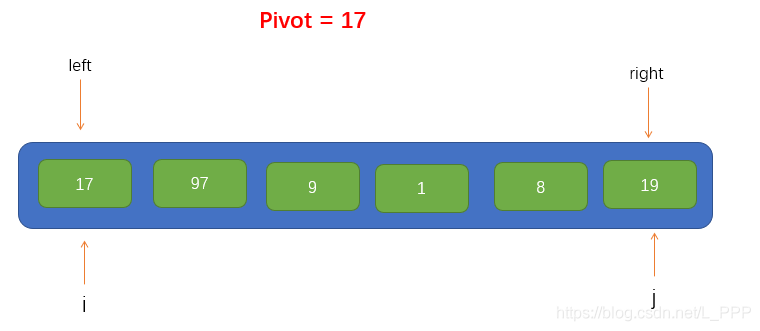
接下來就可以進行遍歷了,這裡我們把遍歷過程稱為填坑法,因為現在我們取到了陣列的第一個值為pivot,所以可以假設這個位置上沒有元素了,留了一個坑,需要我們將別的元素填進來。所以我們要從指標 j 開始往右尋找到一個比pivot小的值,若找到了,則將找到的值填到坑裡,但要注意的是,指標 j 不能找到 指標 i 的左邊去,即當指標 j 與 指標 i 重合時就停止移動。
過程如下圖所示:
此時我們可以看到,指標 j 找到了一個小於pivot的值 8,並將找到的值填到了坑裡,那麼此時指標 j 所指向的位置就留下了一個坑,又需要別的元素來填坑,所以此時我們就要讓指標 i 向右找一個大於pivot的值,並將值填到坑裡,同樣的,指標 i 也不能找到指標 j 的右邊,即當指標 i 與 指標 j 重合時就停止移動。
過程如下圖所示:
指標 i 找到了一個大於pivot的值 97 並將其填到了坑裡,此時指標 i 所在的位置就留下了一個坑,因此我們又要讓指標 j 往左找小於pivot的值並填到坑裡,過程如圖所示:
緊接著,指標 i 又要向右找大於pivot的值,但是移動了兩個位置都沒有找到,並且此時指標 i 指標 j 重合了,此時我們只需要將pivot填入到坑裡就實現了pivot左邊的所有元素小於它,右邊所有的元素都大於它了,如圖所示:
接下來的操作,就是我們要單獨對此時pivot的左邊所有元素和右邊的所有元素進行上述的一系列操作,就可以實現快速排序了。本例中的左右兩邊區域的元素個數都是小於等於3個的,因此直接將這幾個值互相進行比較大小比較方便,過程如下圖:
瞭解了快速排序的實現思路,我們來用程式碼來實現一下
function quickSort(arr) {
// 兩個資料進行交換
function exchange(v1, v2) {
let temp = arr[v1]
arr[v1] = arr[v2]
arr[v2] = temp
}
// 找到相對合適的元素放到陣列索引為0的位置作為基點pivot
function init(left, right) {
let center = Math.floor((left + right) / 2)
// 比較索引為left、center、right三個值的大小,從小到大排列
if(arr[left] > arr[right]) exchange(left, right)
if(arr[center] > arr[right]) exchange(center, right)
if(arr[left] > arr[center]) exchange(left, center)
// 判斷陣列長度是否大於3,若小於3,則陣列已經排序好了,不需要做任何處理
if(right - left > 2) exchange(left, center)
}
function quick(left, right) {
init(left, right)
// 若陣列長度小於等於2,則不需要做任何操作了,因為init函數已經排序好了
if(right - left <= 2) return;
// 建立指標i和j,分別指向left和right
let i = left
let j = right
// 將該陣列區域的第一個元素作為基點pivot
let pivot = arr[i]
// 不斷讓指標i和j尋找合適的值填坑,直到兩個指標重合
while(i < j) {
// 指標j不斷向左找小於pivot的值,但指標j不能找到指標i的左邊
while(arr[j] > pivot && j > i) {
j --
}
// 將找到的小於pivot的值填到指標i所指向的坑中
arr[i] = arr[j]
// 指標i不斷向右找大於pivot的值,但指標i不能找到指標j的右邊
while(arr[i] < pivot && i < j) {
i ++
}
// 將找到的大於pivot的值填到指標j所指向的坑中
arr[j] = arr[i]
}
// 將pivot填到指標i和指標j共同指向的坑中
arr[i] = pivot
// 對此時pivot的左邊所有元素進行快排
quick(left, i - 1)
// 對此時pivot的右邊所有元素進行快排
quick(i + 1, right)
}
quick(0, arr.length - 1)
return arr
}
我們可以簡單來驗證一下快速排序的正確性
let arr = [19, 97, 9, 17, 8, 1]
console.log(quickSort(arr))
/* 列印結果為:
[1, 8, 9, 17, 19, 97]
*/
四、結束語
排序演演算法中的高階排序(希爾排序、歸併排序、快速排序)就已經講完啦,下一篇文章為動態規劃
大家可以關注我,之後我還會一直更新別的資料結構與演演算法的文章來供大家學習,並且我會把這些文章放到【資料結構與演演算法】這個專欄裡,供大家學習使用。
然後大家可以關注一下我的微信公眾號:Lpyexplore的程式設計小屋,等這個專欄的文章完結以後,我會把每種資料結構和演演算法的筆記放到公眾號上,大家可以去那獲取。
或者也可以去我的github上獲取完整程式碼,歡迎大家點個Star
我是Lpyexplore,一個因Python爬蟲而進入前端的探索者。創作不易,喜歡的加個關注,點個收藏,給個贊~