多標籤分類(八):Attention-Driven Dynamic Graph Convolutional Network for Multi-Label Image Recognition
注意力驅動的動態圖形折積網路用於多標籤影象識別
摘要
近年來,為了提高多標籤影象的識別精度,研究中經常使用圖折積網路(GCN)來建模標籤依賴關係。但是,通過計算訓練資料的標籤共現可能性來構造圖可能會降低模型的通用性,特別是當測試影象中存在偶然的共現物件時。我們的目標是消除這種偏差並增強學習特徵的魯棒性。 為此,我們提出了一種注意力驅動動態圖折積網路(ADD-GCN),可以為每個影象動態生成特定圖。ADD-GCN採用動態圖折積網路(D-GCN)對語意注意模組(SAM)生成的內容感知類別表示的關係進行建模。
介紹
自然場景通常包含多個物件。在計算機視覺領域,多標籤影象識別是一項基本的計算機視覺任務,在人類屬性識、醫學影象識別和推薦系統等廣泛應用中發揮著關鍵作用,與單標籤分類不同,多標籤影象識別需要將多個標籤分配給單個影象。 因此,有必要考慮不同標籤之間的關係以提高識別效能。
近年來,圖折積網路(GCN)在圖頂點之間的關係建模方面取得了很大的成功。目前最先進的方法利用目標資料集的標籤共現先驗頻率建立一個完整的圖來建模每兩類之間的標籤相關性,取得了顯著的效果。然而,為整個資料集構建這樣的全域性圖可能會導致大多數常見資料集出現頻率偏差問題。儘管建立者盡了最大的努力,但大多數傑出的視覺資料集還是遭受了同時發生的頻率偏差的困擾。 讓我們考慮一個共同的類別「汽車」,它總是與諸如「卡車」,「摩托車」和「公共汽車」之類的不同型別的車輛一起出現。這可能會無意中導致這些資料集的頻率偏差,從而引導模型學習它們之間的更高的關係。具體來說,如圖1(a)所示,每個影象共用一個靜態圖,該靜態圖是通過計算目標資料集中類別的共現頻率而構建的。在每個影象中,靜態圖給出的「汽車」和「卡車」之間的關係值較高,而「汽車」和「廁所」之間的關係值較低。這可能會導致以下幾個問題:1)在不同的情況下(例如在沒有「卡車」的情況下)無法識別「汽車」,2)即使在只有「汽車」的場景中也會產生「卡車」的幻覺和 3)當「汽車」與「廁所」同時出現時,忽略「廁所」。
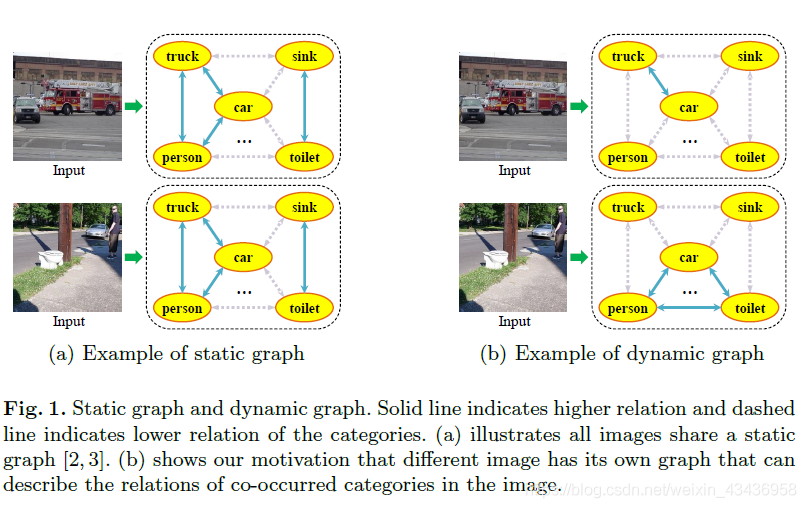
圖1表示靜態圖和動態圖。實線表示類別之間的關係較高,虛線表示類別之間的關係較低。(a)說明所有影象共用一個靜態圖。(b)顯示了我們的動機,不同的影象有自己的圖,可以描述影象中共發生的範疇之間的關係。 可以看到,在靜態圖當中,哪怕圖片中只存在小汽車,也很可能將卡車也預測出來,所以基於全域性的靜態圖很可能每一次都將關係較高的標籤預測出來
考慮到這些問題,我們的目標是構建一個動態圖,以捕捉每個影象的可感知內容的類別關係。具體來說,如圖1(b)所示,我們構造了影象特定的動態圖,其中「汽車」和「廁所」與「汽車」和「廁所」一起出現的影象具有很強的聯絡。 反之亦然。為此,我們提出了一種用於多標籤影象識別的注意力驅動動態圖折積網路(ADD-GCN),它利用內容感知的類別表示來構造動態圖表示,與以前的基於圖的方法不同,ADD-GCN通過估計影象特定的動態圖為每個輸入影象建模語意關係。具體來說,我們首先通過語意注意模組(SAM)將折積特徵圖分解為多個內容感知的類別表示形式,然後將這些表示形式輸入到動態GCN (D-GCN)模組中,該模組通過靜態圖和動態圖兩種聯合圖進行特徵傳播。最終,由D-GCN生成用於多標記分類的區分性載體。 靜態圖主要捕獲訓練資料集上的粗標籤依賴關係,並學習如圖1(a)所示的語意關係。動態圖的相關矩陣是應用於每個影象的內容感知類別表示的輕量級網路的輸出特徵圖,並用於捕獲這些內容感知類別表示的細微依賴關係,如圖1(b)所示。
我們的主要貢獻可以總結如下:
∙
\bullet
∙ 本文的主要貢獻在於,我們介紹了一種基於內容感知類別表示構造的新穎動態圖,用於多標籤影象識別。 動態圖能夠以自適應方式捕獲特定影象的類別關係,從而進一步增強了其代表性和判別能力。
∙
\bullet
∙ 我們精心設計了一個端到端注意力驅動動態圖折積網路(ADD-GCN),該網路由兩個聯合模組組成。 i)語意注意模組(SAM),用於定位語意區域併為每個影象生成內容感知的類別表示;以及ii)動態圖折積網路(D-GCN),用於對內容感知的類別表示的關係進行建模以進行最終分類。
3.方法
本節介紹了用於多標籤影象識別的注意力驅動動態圖折積網路(ADD-GCN)。 我們首先簡要介紹ADD-GCN,然後詳細描述其關鍵模組(語意注意模組和動態GCN模組)。
3.1 ADD-GCN概述
影象中的目標總是同時出現在影象中,如何有效地捕捉它們之間的關係是多標記識別的一個重要問題。基於圖的表示方法為標籤相關性建模提供了一種實用的方法。我們可以用節點
V
=
[
v
1
,
v
2
,
.
.
.
v
C
]
V = [v_1,v_2,...v_C]
V=[v1,v2,...vC]表示標籤,相關矩陣
A
A
A表示標籤關係(邊).最近的研究利用圖折積網路(GCN)來提高多標籤影象識別的效能。但是,它們以靜態方式構造相關矩陣A,該矩陣主要考慮訓練資料集中的標籤共現,並針對每個輸入影象進行固定。 結果,他們無法明確利用每個特定輸入影象的內容
為了解決這個問題,本文提出了具有兩個精心設計的模組的ADD-GCN:我們首先引入語意注意模組(SAM),以從提取的特徵圖中估計每個類
c
c
c的內容感知類別表示
v
c
v_c
vc,並將表示輸入到另一個動態GCN模組,用於最終分類。 我們將在下一部分中詳細介紹它們。
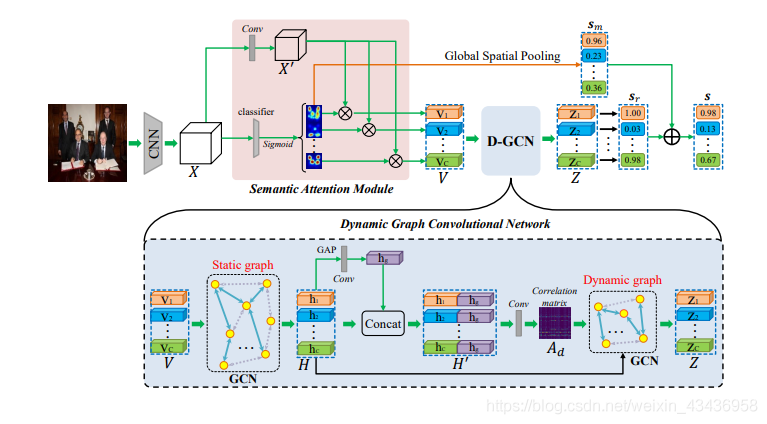
圖2表示了我們方法的總體框架。給定一個影象,ADD-GCN首先使用一個CNN骨幹提取折積特徵圖
X
X
X,然後SAM將
X
X
X解耦為可感知內容的類別表示
V
V
V,
D
−
G
C
N
D-GCN
D−GCN對
V
V
V之間的全域性和區域性關係建模,以生成最終的健壯表示
Z
Z
Z,該
Z
Z
Z包含與其他類別的豐富關係資訊
3.2 語意注意模組
語意注意模組(SAM)的目的是獲得一組內容感知的類別表示,每個類別表示都會從輸入特徵圖
X
∈
R
H
×
W
×
D
X∈\mathbb{R}^{H×W×D}
X∈RH×W×D中描述與特定標籤有關的內容。如圖2所示,SAM首先計算特定類別的啟用對映
M
=
[
m
1
,
m
2
,
.
.
.
,
m
C
]
∈
R
H
×
W
×
C
M=[m_1,m_2,...,m_C]∈\mathbb{R}^{H×W×C}
M=[m1,m2,...,mC]∈RH×W×C,然後使用它們將轉換後的特徵對映
X
′
∈
R
H
×
W
×
D
′
X'∈\mathbb{R}^{H×W×D'}
X′∈RH×W×D′轉換為可感知內容的類別表示
V
=
[
v
1
,
v
2
,
.
.
.
,
v
C
]
∈
R
C
×
D
V=[v_1,v_2,...,v_C]∈\mathbb{R}^{C×D}
V=[v1,v2,...,vC]∈RC×D.具體來說,每個類的表示
v
c
v_c
vc被表述為對
X
′
X'
X′的加權和(如下所示),這樣產生的
v
c
v_c
vc可以有選擇地聚合與其特定類別
c
c
c相關的特徵:
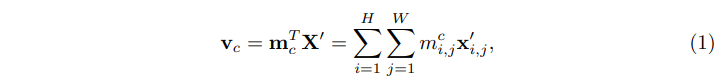
其中
m
i
,
j
c
m_{i,j}^c
mi,jc和
x
i
,
j
′
∈
R
D
′
x'_{i,j}∈\mathbb{R}^{D'}
xi,j′∈RD′分別表示為第
c
c
c個啟用對映的權值,在特徵圖
(
i
,
j
)
(i, j)
(i,j)處的特徵向量。然後問題就變成了如何計算特定類別的啟用對映
M
M
M,難點在於我們沒有明確的監督,比如對影象的邊框或者分類分割
啟用圖生成:我們基於類啟用對映(CAM)生成特定類別的啟用對映M,該類啟用對映是一種不需要邊框和分割就能將隱含注意力暴露在影象上的技術.具體來說,我們可以在特徵圖
X
X
X上執行全域性平均池化(GAP)或全域性最大池化(GMP),並使用FC分類器對這些池化的特徵進行分類,然後,通過將FC分類器的權重與特徵圖
X
X
X進行折積,將這些分類器用於識別類別特定的啟用圖。與CAM不同的是,我們使用折積層作為分類器,並在全域性空間池前使用
S
i
g
m
o
i
d
(
⋅
)
Sigmoid(·)
Sigmoid(⋅)對
M
M
M進行規整,在實驗中具有更好的效能。
3.3 動態GCN
利用上節得到的內容感知類別表示
V
V
V,引入動態GCN (D-GCN)自適應地變換它們的相干相關性,用於多標籤識別.最近圖折積網路(GCN)已被廣泛證明可在多種計算機視覺任務中有效,並且已被應用於靜態圖識別多標籤影象的模型標籤依賴關係.與這些研究不同的是,我們提出了一個新的D-GCN來充分利用內容感知的類別表示之間的關係來生成判別向量來最終分類.具體來說,我們的D-GCN由兩個圖形表示形式組成,即靜態圖和動態圖,如圖2所示。我們首先回顧傳統的GCN,然後詳細介紹D-GCN
傳統 GCN:給定一組特徵
V
∈
R
C
×
D
V∈\mathbb{R}^{C×D}
V∈RC×D作為輸入節點,GCN的目標是利用相關矩陣
A
∈
R
C
×
C
A∈\mathbb{R}^{C×C}
A∈RC×C和狀態更新權矩陣
W
∈
R
D
×
D
u
W∈\mathbb{R}^{D×D_u}
W∈RD×Du來更新
V
V
V的值.在形式上,更新後的節點
V
u
∈
R
C
×
D
u
V_u∈\mathbb{R}^{C×D_u}
Vu∈RC×Du可以用單層GCN表示為:
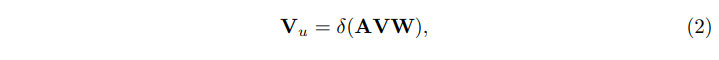
其中
A
A
A通常是預定義的,
W
W
W是在訓練中學習的。
δ
(
⋅
)
δ(·)
δ(⋅)表示啟用函數,如
R
e
L
U
(
⋅
)
ReLU(·)
ReLU(⋅)或
S
i
g
m
o
i
d
(
⋅
)
Sigmoid(·)
Sigmoid(⋅),使整個操作非線性,相關矩陣
A
A
A反映了各節點特徵之間的關係.在推理過程中,關聯矩陣
A
A
A首先將相關資訊擴散到所有節點,然後每個節點接收到所有必要的資訊,並通過線性變換
W
W
W更新其狀態.
D-GCN:如圖2底部所示,D-GCN將可感知內容的類別表示
V
V
V作為輸入節點特徵,並按順序將它們提供給靜態GCN和動態GCN.具體來說,單層靜態GCN簡單定義為
H
=
L
R
e
L
U
(
A
s
V
W
s
)
H = LReLU(A_sVW_s)
H=LReLU(AsVWs),其中
H
=
[
h
1
,
h
2
,
.
.
.
,
h
C
]
∈
R
C
×
D
1
H = [h_1,h_2,...,h_C]∈\mathbb{R}^{C×D_1}
H=[h1,h2,...,hC]∈RC×D1,啟用函數
L
R
e
L
U
(
⋅
)
LReLU(·)
LReLU(⋅)為
L
e
a
k
y
R
e
L
U
LeakyReLU
LeakyReLU,在訓練過程中,通過梯度下降法隨機初始化相關矩陣
A
s
A_s
As和狀態更新權值
W
W
W,由於
A
s
A_s
As對所有影象都是共用的,所以期望
A
s
A_s
As能夠捕獲全域性粗分類依賴關係.
然後引入動態GCN對
H
H
H進行變換,並根據輸入特徵
H
H
H自適應估計其相關矩陣
A
d
A_d
Ad,注意,這與靜態GCN不同,靜態GCN的相關矩陣是固定的,經過訓練後對所有輸入樣本都是共用的,而我們的
A
d
A_d
Ad是根據輸入特徵動態構造的.由於每個樣本具有不同的
A
d
A_d
Ad,使得模型提高了其代表效能力,降低了靜態圖帶來的過擬合風險.在形式上,動態GCN的輸出
Z
∈
R
C
×
D
2
Z∈\mathbb{R}^{C×D_2}
Z∈RC×D2可以定義為:

其中,
f
(
⋅
)
f(·)
f(⋅)是LeakyReLU啟用函數,而
δ
(
⋅
)
δ(·)
δ(⋅)是Sigmoid啟用函數,
W
d
∈
R
D
1
×
D
2
W_d∈\mathbb{R}^{D_1×D_2}
Wd∈RD1×D2為狀態更新權值,
W
A
∈
R
C
×
2
D
1
W_A∈\mathbb{R}^{C×2D_1}
WA∈RC×2D1是構造動態關聯矩陣
A
d
A_d
Ad的conv折積層的權值。
H
′
∈
R
2
D
1
×
C
H'∈\mathbb{R}^{2D_1×C}
H′∈R2D1×C由
H
H
H及其全域性表示
h
g
∈
R
D
1
h_g ∈R^{D_1}
hg∈RD1串聯得到,
h
g
∈
R
D
1
h_g ∈R^{D_1}
hg∈RD1由全域性平均池和一層conv層串聯得到,形式上,
H
′
H'
H′定義為:
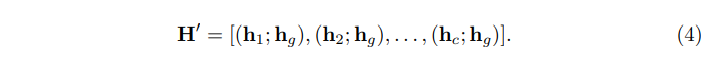
值得一提的是,動態圖
A
d
A_d
Ad是特定於每個影象的,可能會捕獲與內容相關的類別依賴關係。總的來說,我們的DGCN通過特定於資料的圖和特定於影象的圖增強了從
V
V
V到
Z
Z
Z的可感知內容的類別表示
3.4 最終分類和損失
最終的分類:如圖2所示,最終類別表示
Z
=
[
z
1
,
z
2
,
…
,
z
C
]
Z = [z_1, z_2,…, z_C]
Z=[z1,z2,…,zC]用於最終分類,由於每個向量
z
i
z_i
zi都是與其特定類對齊的,並且包含了與其他向量豐富的關係資訊,我們只需將每個類別向量放入一個二值分類器中就可以預測其類別得分,特別地,我們將每個類別的分數連線起來,以生成最終的分數向量
s
r
=
[
s
r
1
,
s
r
2
,
.
.
.
,
s
r
C
]
s_r=[s^1_r,s^2_r,...,s^C_r]
sr=[sr1,sr2,...,srC],此外,我們還可以通過SAM在3.2節中估計的類別特定的啟用圖
M
M
M上的全域性空間合併來獲得另一個可信度分數
s
m
=
[
s
m
1
,
s
m
2
,
.
.
.
,
s
m
C
]
s_m=[s^1_m,s^2_m,...,s^C_m]
sm=[sm1,sm2,...,smC],因此,我們可以將這兩個得分向量組合起來,預測更可靠的結果。這裡,我們只是簡單地將它們平均,從而得到最終分數
s
=
[
s
1
,
s
2
,
.
.
.
,
s
C
]
s = [s^1, s^2,...,s^C]
s=[s1,s2,...,sC]。
訓練損失:我們對最終分數
s
s
s進行監督,並採用傳統的多標籤失分方法對整個ADD-GCN進行如下訓練
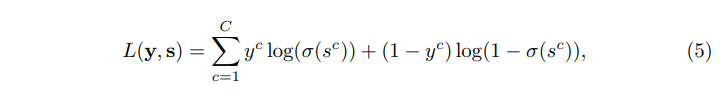
4.實驗
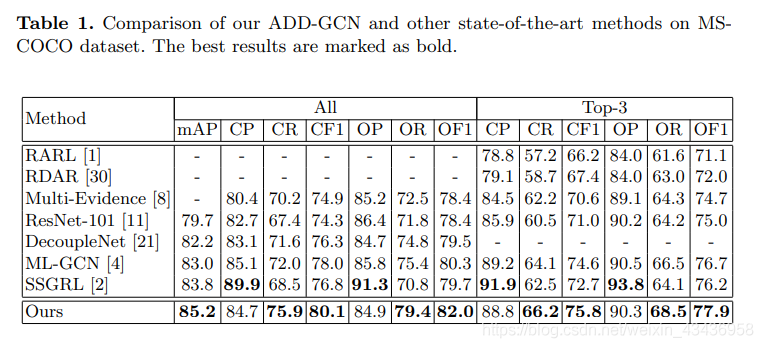
4.1實驗細節
對於整個ADD-GCN框架,我們使用ResNet-101作為骨幹。我們的SAM和D-GCN採用了斜率為負0.2的非線性啟用函數LeakyReLU,在訓練時,我們採用了資料增強來避免過擬合:對輸入影象進行隨機裁剪,調整大小為448×448,隨機水平翻轉來進行資料增強。我們選擇SGD作為優化器,其動量為0.9,重量衰減為
1
0
−
4
10^{-4}
10−4,每個GPU的批次處理大小為18。SAM/D-GCN初始學習率設定為0.5,骨幹CNN設定為0.05,我們總共訓練了50個epoch,在30和40個epoch時,學習率分別降低了0.1倍,在測試期間,我們簡單地將輸入影象的大小調整為512×512以進行評估。所有實驗都是基於PyTorch實現的.
4.4 消融實驗
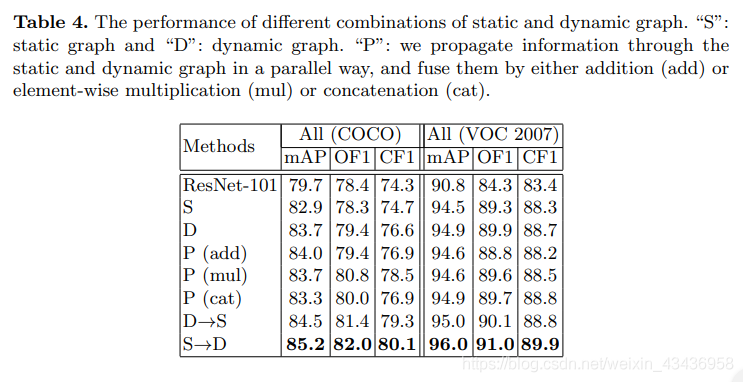
靜態圖形vs動態圖形:研究了靜態圖和動態圖在D-GCN中的作用。結果如表4所示.首先,我們研究了只有一個圖的情況。靜態圖和動態圖的效能都優於基線ResNet-101,動態圖在MS-COCO和VOC 2007上的效能都優於基線ResNet-101,結果表明,在整個資料集上,建模區域性(即影象級)分類感知依賴比粗糙標籤依賴更有效。為了進一步探究靜態圖與動態圖是否互補,我們嘗試以不同的方式組合它們,如表4所示.S表示靜態圖,D表示動態圖,P表示通過靜態圖和動態圖並行傳播資訊,通過加法(add)或元素乘(mul)或連線(cat)將其融合。結果表明,在所有設定中,
S
→
D
S→D
S→D的效能最好
4.5視覺化
在本節中,我們分別以類別特異性啟用圖和動態關聯矩陣
A
d
A_d
Ad的例子來說明SAM是否能夠定位語意目標,以及動態圖學到了什麼關係
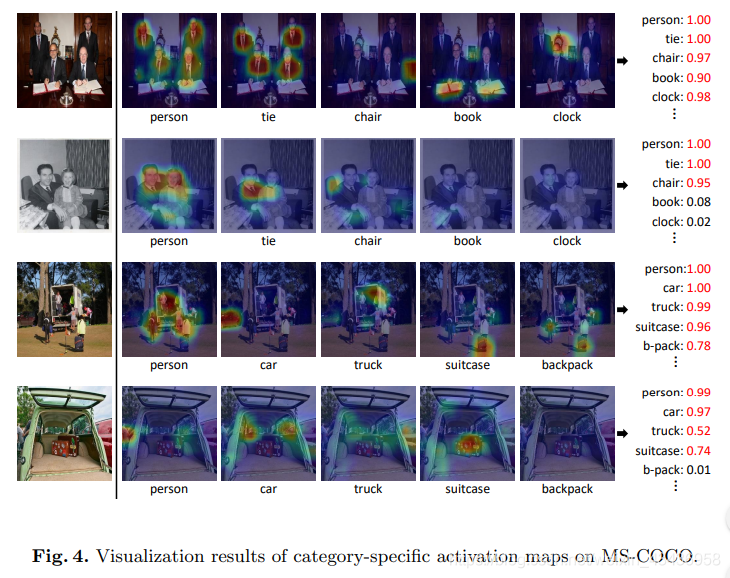
特定類別啟用對映的視覺化:我們使用相應的特定類別啟用對映來視覺化原始影象,以說明使用SAM模組捕獲影象中出現的每個類別的語意區域的能力.一些例子如圖4所示,每一行都是原始影象,對應的特定類別的啟用對映以及每個類別的最終得分.對於影象中出現的類別,我們觀察到我們的模型能夠準確地定位它們的語意區域。相比之下,啟用對映對影象不包含的類別的啟用率較低.例如,第二行有person、tie和chair的標籤,我們的ADD-GCN可以準確地突出顯示這三個類的相關語意區域。最後的結果表明,分類意識表徵具有足夠的可識別性,能夠被準確地識別:
動態圖視覺化:如圖5所示,我們將原始影象與其對應的動態相關矩陣
A
d
A_d
Ad進行視覺化,以說明D-GCN學到了什麼關係。對於圖5(a)中的輸入影象,其ground truth為「car」、「dog」和「person」。圖5(b)為輸入影象
A
d
A_d
Ad的視覺化圖,我們可以發現,
A
d
c
a
r
;
d
o
g
A^{car;dog}_d
Adcar;dog和
A
d
c
a
r
,
p
e
r
s
o
n
A^{car, person}_d
Adcar,person在「car」一列中排名最靠前(大約前10%)。這意味著「狗」和「人」與影象中的「車」更相關。類似的結果也可以在「狗」和「人」這兩行中找到。從動態圖的視覺化觀察,我們可以相信D-GCN能夠捕捉到特定輸入影象的這種語意關係。
