如何在圖資料庫中訓練圖折積網路模型
在圖資料庫中訓練GCN模型,可以利用圖資料庫的分散式計算框架現實應用中大型圖的可延伸解決方案
什麼是圖折積網路?
典型的前饋神經網路將每個資料點的特徵作為輸入並輸出預測。利用訓練資料集中每個資料點的特徵和標籤來訓練神經網路。這種框架已被證明在多種應用中非常有效,例如面部識別,手寫識別,物件檢測,在這些應用中資料點之間不存在明確的關係。但是,在某些使用情況下,當v(i)與v(i)之間的關係不僅僅可以由資料點v(i)的特徵確定,還可以由其他資料點v(j)的特徵確定。 j)給出。例如,期刊論文的主題(例如電腦科學,物理學或生物學)可以根據論文中出現的單詞的頻率來推斷。另一方面,在預測論文主題時,論文中的參考文獻也可以提供參考。在此範例中,我們不僅知道每個單獨資料點的特徵(詞頻),而且還知道資料點之間的關係(引文關係)。那麼,如何將它們結合起來以提高預測的準確性呢?
通過應用圖折積網路(GCN),單個資料點及其連線的資料點的特徵將被組合並饋入神經網路。 讓我們再次以論文分類問題為例。 在引文圖中(圖1),每論文都用引文圖中的頂點表示。 頂點之間的邊緣代表參照關係。 為了簡單起見,將邊緣視為未定向。 每篇論文及其特徵向量分別表示為v_i和x_i。 遵循Kipf和Welling [1]的GCN模型,我們可以使用具有一個隱藏層的神經網路通過以下步驟來預測論文的主題:

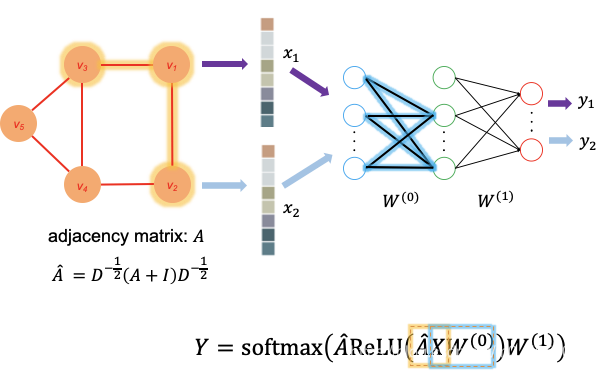
圖1.圖折積網路的體系結構。每個頂點vi在參照圖中代表一個論文。xi是vi的特徵向量。W(0)和W(1)是3層神經網路的權重矩陣。 ,D和I分別是細分矩陣,out度矩陣和恆等矩陣。水平和垂直傳播分別以橙色和藍色突出顯示。
在上述工作流程中,步驟1和步驟4執行水平傳播,其中每個頂點的資訊都傳播到它的鄰居。 第2步和第5步執行垂直傳播,其中每一層的資訊都傳播到下一層。 (見圖1)對於具有多個隱藏層的GCN,水平和垂直傳播將進行多次迭代。 值得注意的是,每次執行水平傳播時,頂點資訊都會在圖中進一步單跳傳播。 在此範例中,水平傳播執行了兩次(步驟2和4),因此每個頂點的預測不僅取決於其自身的特徵,而且還取決於距其2跳距離內的所有頂點的特徵。 另外,由於權重矩陣W(0)和W(1)由所有頂點共用,因此神經網路的大小不必隨圖的大小而增加,這使此方法可伸縮。
為什麼需要GCN的圖形資料庫
通過合併每個頂點的圖形特徵,GCN可以以低標籤率實現高精度。在Kipf和Welling的工作中[1],使用圖形中5%的標記頂點(實體)可以獲得80%的精度。考慮到整個圖在傳播過程中需要參與計算,訓練GCN模型的空間複雜度為O(E + V * N + M),其中E和V是圖中的邊和頂點數量N是每個頂點的特徵數量,M是神經網路的大小。
對於工業應用,圖可以具有數億個頂點和數十億條邊,這意味著在模型訓練期間,鄰接矩陣A,特徵矩陣X和其他中間變數(圖1)都可能消耗數TB的記憶體。可以通過在圖資料庫(GDB)中訓練GCN來解決這種挑戰,在該資料庫中,圖可以分佈在多節點群集中並部分儲存在磁碟上。此外,首先將圖結構的使用者資料(例如社交圖,消費圖和移動圖)儲存在資料庫管理系統中。資料庫內模型訓練還避免了將圖形資料從DBMS匯出到其他機器學習平臺,從而更好地支援了不斷髮展的訓練資料的連續模型更新。
如何在圖形資料庫中訓練GCN模型
在本節中,我們將在TigerGraph雲上(免費試用)提供一個圖資料庫,載入一個參照圖,並在資料庫中訓練GCN模型。按照以下步驟操作,您將在15分鐘內得到一個論文分類模型。
我們使用GraphStudio作為入門的工具,我們使用CORA資料集(https://relational.fit.cvut.cz/dataset/CORA)
Cora資料集包含三個檔案:
cite.csv具有三列,paperA_id,paperB_id和weight。 前兩列用於在論文之間建立CITE邊緣。 查詢將在以下步驟中更新CITE邊緣上的權重,因此不需要載入最後一列。 應該注意的是,該入門工具包中的檔案在每篇論文中都新增了自連結,以簡化查詢的實現。 這與Kipf和Welling [1]的方法是一致的。
paper_tag.csv具有兩列,paper_id和class_label。 該檔案中的每一行都將用於建立一個PAPER頂點,其中包含從檔案填充的論文ID和論文類別。
content.csv具有三列,paper_id,word_id和weight。 前兩列用於在論文和文字之間建立HAS邊緣。 HAS邊緣將用於儲存稀疏詞袋特徵向量。 查詢將在以下步驟中更新HAS邊緣上的權重,因此不需要載入最後一列。
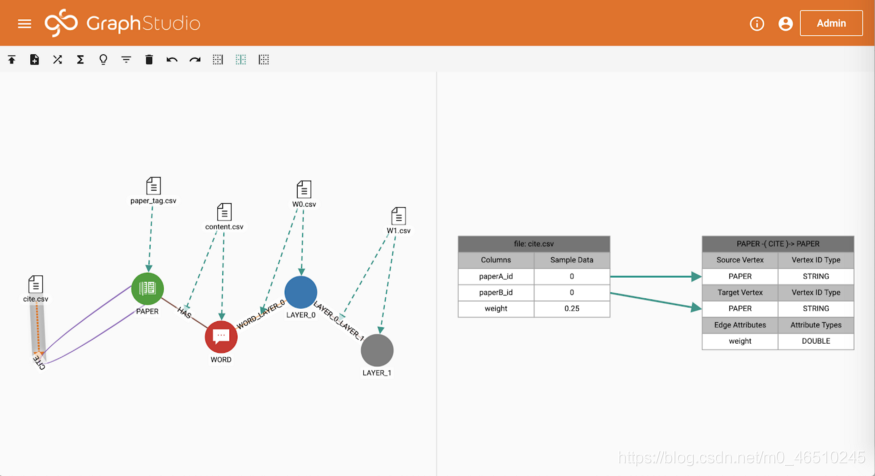
轉到「載入資料」頁面,然後單擊「開始/繼續載入」。 載入完成後,您可以在右側看到圖形統計資訊。 Cora資料集包含2708篇論文,1433個不同的單詞(特徵向量的維數)和7986個參照關係。 每篇論文都用7種不同類別中的1種標記。
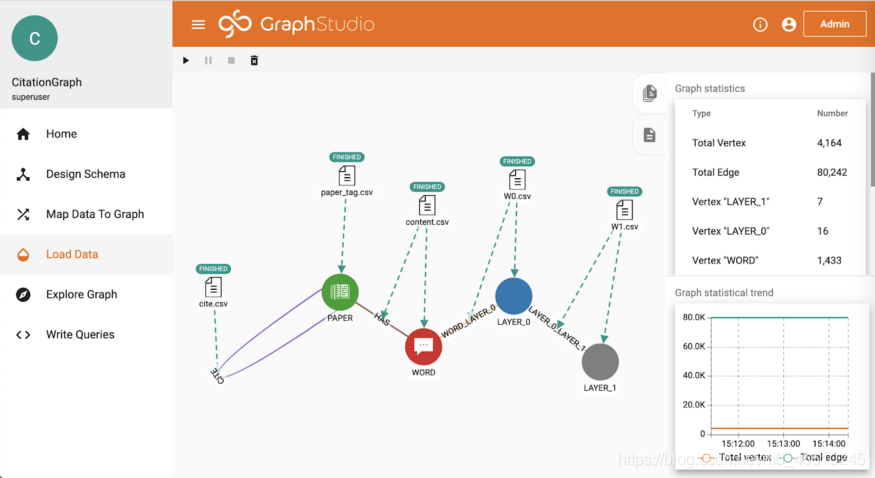
在「瀏覽圖」頁面中,您可以看到我們剛剛在參照圖的頂部建立了一個神經網路。 參照圖中的每篇論文都連線到多個單詞。 因此,HAS邊緣上的權重形成一個稀疏特徵向量。 1433個不同的詞連線到隱藏層中的16個神經元,而隱藏層連線到輸出層中的7個神經元(代表7個不同的類)。
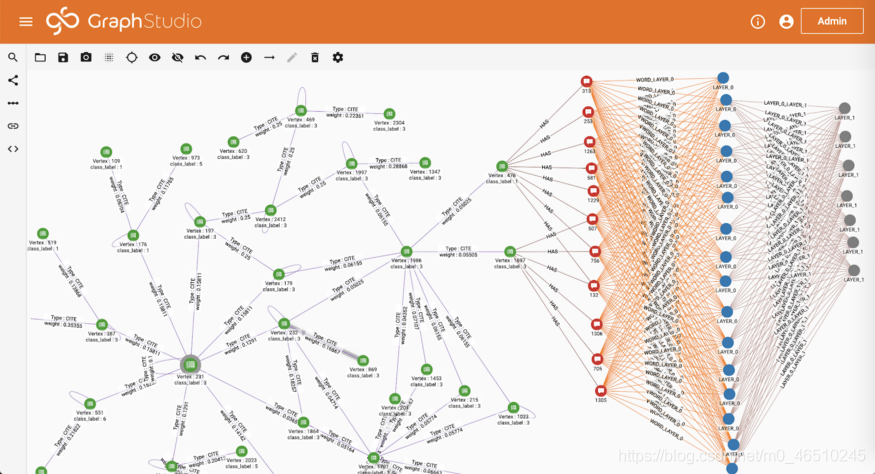
在「寫查詢」頁面中,您將找到GCN所需的查詢已新增到資料庫中。 查詢使用TigerGraph的查詢語言GSQL編寫。 單擊「安裝所有查詢」以將所有GSQL查詢編譯為C ++程式碼。 您也可以在此頁面上看到自述查詢。 請按照以下步驟訓練GCN。
執行初始化查詢
此查詢首先通過將論文i和j之間的權重分配為e_ij = 1 /(d_i * d_j)來歸一化CITE邊緣上的權重,其中d_i,d_j是論文i和論文j的CITE輸出度。 其次,通過將論文p和單詞w之間的權重分配為e_pw = 1 / dp來歸一化HAS邊緣上的權重,其中dp是論文w的HAS出度。 第三,它對140、500和1000個論文頂點進行取樣,以進行測試,驗證和訓練。
執行weight_initialization查詢
該查詢使用Glorot和Bengio [2]的方法初始化神經網路的權重。該神經網路在輸入層中有1433個神經元對應於詞彙的大小,在隱藏層中有16個神經元,在輸出層中有7個神經元,對應於論文的7類。
執行訓練查詢
該查詢使用與Kipf和Welling [1]中使用的相同的超引數訓練圖折積神經網路。具體而言,使用第一層的交叉熵損失,dropout和L2正則化(5e-4)評估模型。 Adam優化器已在此查詢中實現,並且批次梯度下降用於訓練。查詢結束後,將顯示在訓練和驗證資料上評估的損失以及在測試資料上評估的預測準確性。如訓練查詢的輸出所示,經過5個訓練輪次後,準確性達到53.2%。可以將輪次數設定為查詢輸入,以提高準確性。

執行預測查詢
該查詢將訓練完成的GCN應用於圖表中的所有論文,並視覺化結果。
GSQL查詢概述
在上一節中,我們將深入探討這些查詢,以瞭解TigerGraph的大規模並行處理框架如何支援訓練GCN。 簡而言之,TigerGraph將每個頂點視為可以儲存,傳送和處理資訊的計算單元。 我們將在查詢中選擇一些語句,以說明如何執行GSQL語句。
SELECT語句:
我們先來看一下查詢初始化。 第一行將初始化包含圖形中所有PAPER頂點的頂點集Papers。 在下一個SELECT語句中,我們將從頂點集Papers開始,並遍歷所有CITE邊。 對於每個邊緣(由e表示),其邊緣權重是根據其源頂點(由s表示)和目標頂點(由t表示)的平行度來計算的。

ACCUM和POST-ACCUM
現在,讓我們看一下查詢訓練。 正如我們在上一節中討論的那樣,水平傳播是我們從每個頂點向相鄰頂點傳送資訊的地方,這是通過ACCUM之後的行完成的。 它將每個目標頂點的特徵向量(稱為t。@ z_0)計算為其源頂點的特徵向量(稱為s.zeta_0)並按e.weight加權。 下一個POST-ACCUM塊進行垂直傳播。 它首先將ReLU啟用函數和輟學正則化應用於每個頂點上的特徵向量。 然後,它將隱藏層要素(稱為s.z_z_0)傳播到輸出層。 同樣,TigerGraph將針對邊和頂點並行化ACCUM和POST-ACCUM塊中的計算。

使用者定義的功能
啟用函數用C ++實現,並匯入到TigerGraph使用者定義的函數庫中。 下面是ReLU函數(ReLU_ArrayAccum)的實現

結論
在圖資料庫中訓練GCN模型利用了圖資料庫的分散式計算框架。 它是現實應用中大型圖的可延伸解決方案。 在本文中,我們將說明GCN如何將每個節點的特徵與圖特徵結合起來以提高圖中的節點分類的準確性。 我們還展示了使用TigerGraph雲服務在引文圖上訓練GCN模型的分步範例。
參照
[1] Thomas. N. Kipf and Max Welling, ICLR (2017)
[2] Glorot and Bengio, AISTATS (2010)
作者:Changran Liu
deephub翻譯組