百面機器學習02-模型評估
1:評估指標的侷限性
場景描述:
在模型評估過程中,分類問題、排序問題、迴歸問題往往需要使用不同的指標進行評估 。在諸多的評估指標中,大部分指標只能片面地反映模型的一部分效能 。 如果不能合理地運用評估指標 ,不僅不能發現模型本身的闖題,而且會得出錯誤的結論。下面以 Hulu 的業務為背景 ,假想幾個模型評估場景 3 看看大家能否觸類旁通,發現模型評估指標的侷限性。
知識點:準確率( Accuracy ),精確率( Precision ),召回率( Recall ),均萬根誤差(Root Mean Square Error, RMSE)
問題1:準確率的侷限性
分析與解答:Hulu 的奢侈品廣告主們希望把廣告走向投放給奢侈昂使用者 。 Hulu 通過第三萬的資料管理平臺( Data Management Platform , DI.在P )拿到了一部分奢侈晶使用者的資料 , 並以此為訓練、集和測出集,訓練和測試奢侈昂使用者的分類模型。該模型的分類準確率超過了95% , 但在實際廣告投放過程中,該模型還是把大部分廣告投給了非奢侈昂使用者 3 這可能是什麼原因造成的?
在解答該問題之前,我們先回顧一下臺類準確率的定義 。 準確率是
指分類正確的樣本佔總牛羊本個數的比例,即:
A
ccurac
y
=
n
correct
n
total
A \operatorname{ccurac} y=\frac{n_{\text {correct }}}{n_{\text {total }}}
Accuracy=ntotal ncorrect
其中 n correct n_{\text {correct }} ncorrect 為被正確分類的樣本個數, n total n_{\text {total }} ntotal 為總樣本的個數。準確率是分類問題中最簡單也是最直觀的評價指標,但存在明顯的缺陷。比如,當負樣本佔 99% 時,分類器把所有樣本都預測為負樣本也可以獲得 99%的準確率。所以, 當不同類別的樣本比例非常不均衡時 ,佔比大的類別往往成為影響準確率的最主要因素。
明確了這一點,這個問題也就迎刃而解了。顯然,奢侶品使用者只佔Hulu 全體使用者的一小部分,雖然模型的整體分類準確率高,但是不代表對奢侶品使用者的分類準確率也很高。線上上投放過程中,我們只會對模型劑「奢侶品使用者」判定的準確率不夠高的問題就被放大了。為了解決這個問題,可以使用更為有效的平均準確率(每個類別下的樣本準確率的算術平均)作為模型評估的指標。
事實上,這是一道比較開放的問題,面試者可以根據遇到的問題一步步地排查原因。標準答案其實也不限於指標的選擇,即使評估指標選擇對了,仍會存在模型過擬合或欠擬合、測試集和訓練集劃分不合理、線下評估與線上測試的樣本分佈存在差異等一系列問題,但評估指標的選擇是最容易被發現,也是最可能影響評估結果的因素。
問題2:精確率與召回率的權衡
Hulu 提供視訊的模糊搜尋功能,搜尋排序模型返回的 Top 5 的精確率非常高,但在實際使用過程中,使用者還是經常找不到想要的視訊,特別是一些比較冷門的劇集,這可能是哪個環節出了問題呢?
分析與解答:要回答這個問題,首先要明確兩個概念,精確率和召回率。精確率是指分類正確的正樣本個數佔分類器判定為正樣本的樣本個數的比例。召回率是指分類正確的正樣本個數佔真正的正樣本個數的比例。在排序問題中,通常沒有一個確定的間值把得到的結果直接判定為正樣本或負樣本,而是採用 Top N 返回結果的 Precision 值和 Recall值來衡量排序模型的效能,即認為模型返回的 Top N 的結果就是模型判定的正樣本,然後計算前 N 個位置上的準確率 Precision@N 和前 N N N個位置上的召回率 Recall@N。
Precision 值和 Recall 值是既矛盾又統一的兩個指標,為了提高Precision 值,分類器需要儘量在「更有把握" 時才把樣本預測為正樣本,但此時往往會因為過於保守而漏掉很多「沒有把握」的正樣本,導致 Recall 值降低。回到問題中來,模型返回的 Precision@5 的結果非常好,也就是說排序模型 Top 5 的返回值的品質是很高的。但在實際應用過程中,使用者為了找一些冷門的視訊,往往會尋找排在較靠後位置的結果,甚至翻頁去查詢目標視訊。但根據題目描述,使用者經常找不到想要的視訊,這說明模型沒有把相關的視訊都找出來呈現給使用者。顯然,問題出在召回率上。如果相關結果有100 個,即使 Precision@5 達到了 100%,Recall@5 也僅僅是5%。在模型評估時,我們是否應該同時關注 Precision 值和 Recall 值?進一步而言,是否應該選取不同的 Top N 的結果進行觀察呢?是否應該選取更高階的評估指標來更全面地反映模型在 Precision 值和 Recall 值兩方面的表現?
答案都是肯定的,為了綜合評估一個排序模型的好壞,不僅要看模型在不同 Top N 下的 Precision@N 和 Recall@N,而且最好繪製出模型的P-R(Precision-Recall ) 曲線。這裡簡單介紹一下 P-R 曲線的繪製方法。P-R 曲線的橫軸是召回率,縱軸是精確率。對於一個排序模型來說,其 P-R 曲線上的一個點代表著,在某一閩值下,模型將大於該閩值的結果判定為正樣本,小於該間值的結果判定為負樣本,此時返回結果對應的召回率和精確率。整條 P-R 曲線是通過將間值從高到低移動而生成的。圖 2.1 是 P-R 曲線樣例圖,其中實線代表模型 A A A 的 P-R 曲線,虛線代表模型 B 的 P-R 曲線。原點附近代表當間值最大時模型的精確率和召回率。
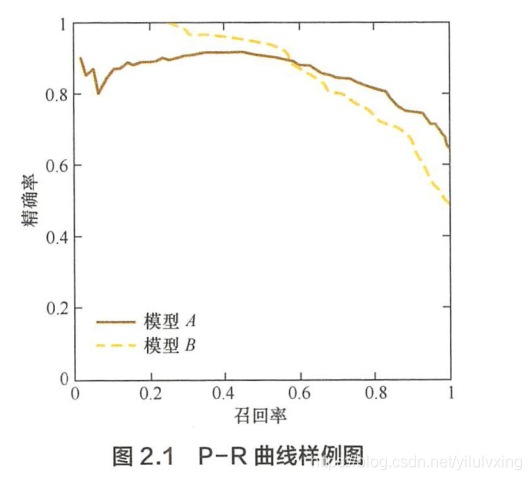
由圖可見,當召回率接近於 0 時,模型
A
A
A 的精確率為 0.9,模型 B的精確率是 1,這說明模型
B
B
B 得分前幾位的樣本全部是真正的正樣本,而模型
A
A
A 即使得分最高的幾個樣本也存在預測錯誤的情況。並且,隨著召回率的增加,精確率整體呈下降趨勢。但是,當召回率為 1 時,模型A 的精確率反而超過了模型 B。這充分說明,只用某個點對應的精確率和召回率是不能全面地衡量模型的效能, 只有通過 P-R 曲線的整體表現,才能夠對模型進行更為全面的評估。
除此之外,F1 score 和 ROC 曲線也能綜合地反映一個排序模型的效能。F1 score 是精準率和召回率的調和平均值,它定義為
F
1
=
2
×
precision
×
recall
precision
+
recall
\mathrm{F} 1=\frac{2 \times \text { precision} \times \text { recall }}{\text { precision }+\text { recall }}
F1= precision + recall 2× precision× recall
ROC 曲線會在後面的小節中單獨討論,這裡不再敘述。
問題3:平方根誤差的「意外」
分析與解答:Hutu 作為 一家串流媒體公司,擁有眾多的美劇資源,預測每部美劇的流量趨勢對於廣告投版、使用者增長都非常重要 。我們希望構建 個迴歸模型來預測某部美劇的流量趨勢 , 但無論採用哪種迴歸模型 3 得到的RMSE 指標都非常高。然而事實是模型在 95%的時間區間內的預測誤差都小於 1% , 取得了相當不錨的預測結果 。那麼 ,造成 RMSE 指標居高不下的最可能的原因是什麼?
RMSE 經常被用來衡量回歸模型的好壞,但按照題目的敘述,RMSE 這個指標卻失效了。先看一下 RMSE 的計算公式為
R
M
S
E
=
∑
i
=
1
n
(
y
i
−
y
^
i
)
2
n
R M S E=\sqrt{\frac{\sum_{i=1}^{n}\left(y_{i}-\hat{y}_{i}\right)^{2}}{n}}
RMSE=n∑i=1n(yi−y^i)2
其中,
y
i
y_{i}
yi 是第
i
i
i 個樣本點的真實值,
y
^
i
\hat{y}_{i}
y^i 是第
i
i
i 個樣本點的預測值,
n
n
n 是樣本點的個數。
一般情況下,RMSE 能夠很好地反映迴歸模型預測值與真實值的偏離程度。但在實際問題中,如果存在個別偏離程度非常大的離群點Outlier )時,即使離群點數量非常少,也會讓 RMSE 指標變得很差。
回到問題中來,模型在 95% 的時間區間內的預測誤差都小於 1% ,這說明,在大部分時間區間內,模型的預測效果都是非常優秀的。然而,RMSE 卻一直很差,這很可能是由於在其他的 5% 時間區間記憶體在非常嚴重的離群點。事實上,在流量預估這個問題中,噪聲點確實是很容易產生的,比如流量特別小的美劇、剛上映的美劇或者剛獲獎的美劇,甚至一些相關社交媒體突發事件帶來的流量,都可能會造成離群點。
針對這個問題,有什麼解決方案呢?可以從三個角度來思考。第一,如果我們認定這些離群點是「噪聲點」的話,就需要在資料預處理的階段把這些噪聲點過濾掉。第二,如果不認為這些離群點是「噪聲點」的話,就需要進一步提高模型的預測能力,將離群點產生的機制建模進去這是一個宏大的話題,這裡就不展開討論了)。第三,可以找一個更合適的指標來評估該模型。關於評估指標,其實是存在比 RMSE 的魯棒性更好的指標,比如平均絕對百分比誤差(Mean Absolute Percent Error,MAPE ),Error,MAPE),它定義為
M
A
P
E
=
∑
i
=
1
n
∣
y
i
−
y
^
i
y
i
∣
×
100
n
M A P E=\sum_{i=1}^{n}\left|\frac{y_{i}-\hat{y}_{i}}{y_{i}}\right| \times \frac{100}{n}
MAPE=i=1∑n∣∣∣∣yiyi−y^i∣∣∣∣×n100
相比 RMSE,MAPE 相當於把每個點的誤差進行了歸一化,降低了個別離群點帶來的絕對誤差的影響。
1:ROC 曲線
場景描述:
二值分類器(Binary Classifier )是機器學習領域中最常見也是應用最廣泛的分類器。評價二值分類器的指標很多,比如 precision、recall、F1 score、P-R 曲線等。上一小節已對這些指標做了一定的介紹,但也發現這些指標或多或少只能反映模型在某一方面的效能。相比而言,ROC 曲線則有很多優點,經常作為評估二值分類器最重要的指標之一。下面我們來詳細瞭解一下 ROC 曲線的繪製方法和特點。
知識點:ROC 曲線,曲線下的面積( Aera Under Curve, AUC) , P - R 曲線
問題1 :什麼是 ROC 曲線?
ROC 曲線是 Receiver Operating Characteristic Curve 的簡稱中文名為「受試者工作特徵曲線」。ROC 曲線源於軍事領域,而後在醫學領域應用甚廣,「受試者工作特徵曲線」這一名稱也正是來自於醫學領域。
ROC 曲線的橫座標為假陽性率(False Positive Rate,FPR ) ; 縱座標為真陽性率(True Positive Rate, TPR )。FPR 和 TPR 的計算方法分別為
F
P
R
=
F
P
N
T
P
R
=
T
P
P
\begin{aligned} F P R &=\frac{F P}{N} \\ T P R &=\frac{T P}{P} \end{aligned}
FPRTPR=NFP=PTP
上式中, P 是真實的正樣本的數量 , N是真實的負樣本的數量 , TP 是P 個正樣本中被分類器預測為E樣本的個數, FP 是 N 個負樣本中被分類器預測為正樣本的個數。只看定義確實高點繞 , 為了更重觀地說明這個問題,我們舉一個醫院診斷病人的例子 。 假設高 l 。但疑似癌症患者,真中高 3 位很不幸確實患了癌症( P=3 ),另外 7 位不是癌症患者( N=7 ) 。醫 院對這10 位疑似意者做了診斷,診斷出 3 位癌症患者,真中南 2 位確實是真正的患者( TP=2 ) 。 那麼真陽性率 TPR=TP/P=2/3 , 對於 7 位非癌症患者來說 3 有一位很不幸被誤診為癌症患者( FP= l ),那麼假陽性率FPR=FP/N 1/7 。 對於「該醫院」這個分類器來說,這組分類結果就對應 ROC 曲線上的-個點( 1/7, 2/3 )。
問題2 :如何繪製 ROC 曲線?
事實上, ROC 曲線是通過不斷移動分類器的「截斷點」來生成曲線上的一組關鍵點的,通過下面的例子進一步來解揮「截斷點」的概念。
在二值分類問題中,模型的輸出一般都是預測樣本為正例的概率 。假設測試集中有 20 個樣本,表 2.1 是模型的輸出結果 。 樣本按照預測概率從高到低排序。在輸出最終的正例、負例之前 3 我們需要指定一個
閾值3 預測概率大於該閾值的樣本會被判為正例,小於該與之的樣本則會被判為負例 。 比如,指定閾值為 0.9 ,那麼只有第一個樣本會被預測為正例 1 其他全部都是負例 。 上面所說的 「截斷點」指的就是區分正負預測結果的閾值 。
通過動態地調整截斷點 , 從最高的得分開始(實際上是從正無窮開始,對應著 ROC 曲線的零點) , 逐漸調整到最低得分 , 每一個截斷點都會對應一個 FPR 和 TPR ,在 ROC 圖上繪製出每個截斷點對應的位置,再連線所有點就得到最終的 ROC 曲線。
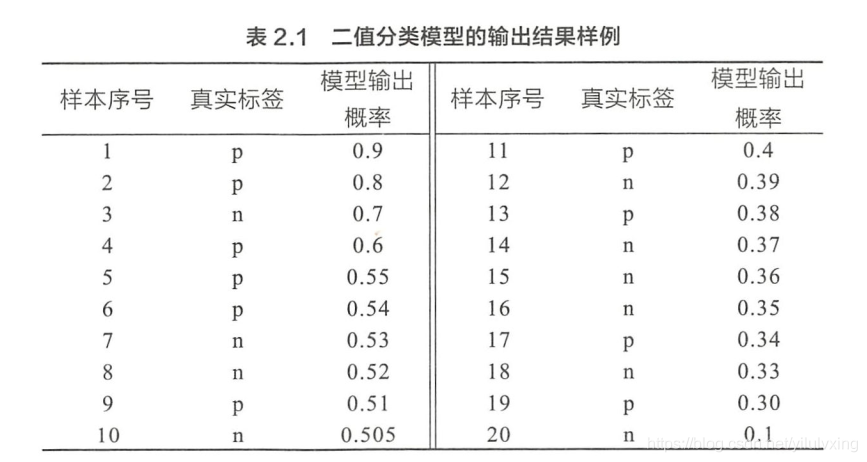
就本例來說,當截斷點選擇為正無窮時,模型把全部樣本預測為負例,那麼 FP 和 TP 必然都為 0, FPR 和 TPR 也都為 0 ,因此曲線的第一個點的座標就是( 0 , 0 ) 。 當把截斷點調整為 0.9 時 ,模型預測 1號樣本為正樣本,並且該樣本確實是正樣本,因此, TP=1, 20 個樣本中 ,所有正例數量為 P=10 ,故 TPR=TP/P= 1/10;這裡沒有預測錯的正樣本,即 FP=O ,負樣本總數 N=10 ,故 FPR=FP/N=0/10=0 ,對應 ROC 曲線上的點( 0,0.1 )。依次調整截斷點,直到畫出全部的關鍵點 2 再連線關鍵點即得到最終的 ROC 如曲線如圖 2 . 2 所示 。
其實 , 還有一種更直觀地繪製 ROC 曲線的方法 。 首先,根據樣本標籤統計出正負樣本的數量 ,假設正樣本數量為 P , 負樣本數量為 N; 接下來,把橫軸的刻度間隔設定為 1 /N , 縱軸的刻度間隔設定為 1 /P; 再根據模型輸出的預測概率對樣本進行排序(從高到低) ;依次遍歷樣本,同時從零點開始繪製ROC 曲線,每遇到一個正樣本就沿縱軸方向繪製一個刻度間隔的曲線,每遇到一個負樣本就沿橫軸方向繪製一個刻度間隔的曲線 3 直到遍歷完所高樣本,由線最終停在( 1,1 )這個點,整個 ROC 曲線繪製完成 。
問題3 :如何計算 AUC?
顧名思義, AUC 指的是 ROC 曲線下的面積大小, 該值能夠量化地反映基於 ROC 由線衡量出的模型效能 。 計算 AUC 值只需要沿著ROC 橫軸做積分就可以了 。 由於 ROC 曲線一般都處於 y=x 這條直線的上萬(如果不是的話,只要把模型預測的概率反轉成 1-p 就可以得到一個更好的分類器),所以 AUC 的取值一般在 0.5 ~ 1 之間 。 AUC越大 , 說明分類器越可能把真正的正樣本排在前面 , 分類效能越好 。
問題4 :ROC 曲線比 P-R 曲線有什麼特點?
本章第一小節曾介紹過同樣被經常用來評估分類和排序模型的 P -R曲線。相比 P -R 曲線, ROC 曲線奇一個特點,當正負樣本的分佈發生變化時, ROC 曲線的形狀能夠基本保持不變,而 P -R 曲線的形狀一般會發生較劇烈的變化。
舉例來說 3 圖 2.3 是 ROC 曲線和 P -R 曲線的對比圖 , 其中圖 2.3 ( a)和圖 2.3 ( c )是 ROC 曲線,圖 2.3 ( b )和圖 2.3 ( d )是 P-R 由線,圖 2.3( c )和圖2.3 ( d )則是將測試集中的負樣本數量增加 10 信後的曲線圖。
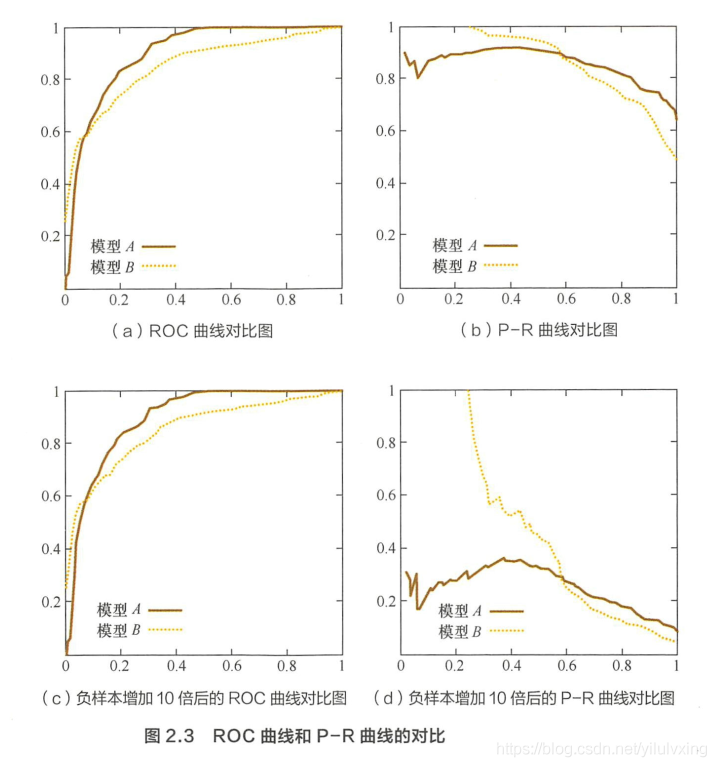
可以看出, P-R 曲線發生了明顯的變化,而 ROC 曲線形狀基本不變 。 這個特點讓 ROC 曲線能夠儘量降低不同測試集帶來的干擾,更加客觀地衡量模型本身的效能 。 這高什麼實際意義呢?在很多實際問題中 , 正負樣本數量往往很不均衡 。 比如,計算廣告領域經常涉及轉化率模型,正樣本的數量往往是負樣本數量的 1/1000 甚至 1/10000 。 若選擇不同的測試集, P -R 曲線的變化就會非常大,而 ROC 由線則能夠更加穩定地反映模型本身的好壞。所以, ROC 曲線的適用場景更多,被廣泛用於排序、推薦 、 廣告等領域。 但需要注意的是,選擇 P-R 曲線還是 ROC 曲線是因實際問題而異的,如果研究者希望更多地看到模型
在特定資料集上的表現, P-R 曲線則能夠更直觀地反映其效能。
3:餘弦距離的應用
場景描述
本章的主題是模型評估 ,但真實在模型訓練過程中,我們也在不斷地評估著樣本間的距離,如何評估樣本距離也是定義優化目標和訓練方法的基礎 。在機器學習問題中,通常將特徵表示為向量的形式,所以在分析兩個特徵向量之間的相似性時 ,常使用餘弦相似度來表示 。餘弦相似度的取值範圍是[-1,1 ],相同的兩個向量之間的相似度為 1 。 如果希望得到類似於距離的表示,將 1 減去餘弦相似度即為餘弦距離 。因此餘弦距離的取值範圍為[ 0,2],相同的兩個向量餘弦距離為 0。
涉及到的知識點:餘弦相似度,餘弦距離,歐氏距離,距離的定義
問題1:為什麼在一些場景中要使用餘弦相似度而不是歐式距離?
對於兩個向量 A A A 和 B , B, B, 其餘弦相似度定義為cos ( A , B ) = A ⋅ B ∥ A ∥ 2 ∥ B ∥ 2 (A, B)=\frac{A \cdot B}{\|A\|_{2}\|B\|_{2}} (A,B)=∥A∥2∥B∥2A⋅B即兩個向量夾角的餘弦,關注的是向量之間的角度關係,並不關心它們的絕對大小,其取值範圍是 [-1,1]。當一對文字相似度的長度差距很大、但內容相近時,如果使用詞頻或詞向量作為特徵,它們在特徵空間中的的歐氏距離通常很大; 而如果使用餘弦相似度的話,它們之間的夾角可能很小,因而相似度高。此外,在文字、影象、視訊等領域,研究的物件的特徵維度往往很高,餘弦相似度在高維情況下依然保持「相同時為1,正交時為 0,相反時為 -1」的性質,而歐氏距離的數值則受維度的影響,範圍不固定,並且含義也比較模糊。
在一些場景,例如 Word2Vec 中,其向量的模長是經過歸一化的,
此時歐氏距離與餘弦距離有著單調的關係,即
∥
A
−
B
∥
2
=
2
(
1
−
cos
(
A
,
B
)
)
\|A-B\|_{2}=\sqrt{2(1-\cos (A, B))}
∥A−B∥2=2(1−cos(A,B))
其中
∥
A
−
B
∥
2
\|A-B\|_{2}
∥A−B∥2 表示歐氏距離,
cos
(
A
,
B
)
\cos (A, B)
cos(A,B) 表示餘弦相似度,
(
1
−
cos
(
A
,
B
)
)
(1-\cos (A, B))
(1−cos(A,B)) 表示餘弦距離。在此場景下,如果選擇距離最小(相似度最大)的近鄰,那麼使用餘弦相似度和歐氏距離的結果是相同的。總體來說,歐氏距離體現數值上的絕對差異,而餘弦距離體現方向上的相對差異。例如,統計兩部劇的使用者觀看行為,使用者 A 的觀看向量為(0,1),使用者 B 為 (1,0); 此時二者的餘弦距離很大,而歐氏距離很小; 我們分析兩個使用者對於不同視訊的偏好,更關注相對差異,顯然應當使用餘弦距離。而當我們分析使用者活躍度,以登陸次數 ( 單位: 次 ) 和平均觀看時長(單位: 分鐘) 作為特徵時,餘弦距離會認為 (1,10)、(10,100) 兩個使用者距離很近; 但顯然這兩個使用者活躍度是有著極大差異的,此時我們更關注數值絕對差異,應當使用歐氏距離。特定的度量方法適用於什麼樣的問題,需要在學習和研究中多總結和思考,這樣不僅僅對面試有幫助,在遇到新的問題時也可以活學活用。
問題2:餘弦距離是否一個嚴格定義的距離
該題主要考察面試者對距離的定義的理解,以及簡單的反證和推導。首先看距離的定義:在一個集合中,如果每一對元素均可唯一確定一個實數,使得三條距離公理(正定性,對稱性,三角不等式)成立,則該實數可稱為這對元素之間的距離。餘弦距離滿足正定性和對稱性,但是不滿足三角不等式,因此它並不是嚴格定義的距離。具體來說,對於向量 A A A 和 B , B, B, 三條距離公理的證明過程如下。
- 正定性
根據餘丟辛離的定義,有
dist ( A , B ) = 1 − cos θ = ∥ A ∥ 2 ∥ B ∥ 2 − A B ∥ A ∥ 2 ∥ B ∥ 2 \operatorname{dist}(A, B)=1-\cos \theta=\frac{\|A\|_{2}\|B\|_{2}-A B}{\|A\|_{2}\|B\|_{2}} dist(A,B)=1−cosθ=∥A∥2∥B∥2∥A∥2∥B∥2−AB
孝慮到|| A ∥ 2 ∥ B ∥ 2 − A B ⩾ 0 , A\left\|_{2}\right\| B \|_{2}-A B \geqslant 0, A∥2∥B∥2−AB⩾0, 因此有 dist ( A , B ) ⩾ 0 \operatorname{dist}(A, B) \geqslant 0 dist(A,B)⩾0 坦成立。特別地,有
dist ( A , B ) = 0 ⇔ ∥ A ∥ 2 ∥ B ∥ 2 = A B ⇔ A = B \operatorname{dist}(A, B)=0 \Leftrightarrow\|A\|_{2}\|B\|_{2}=A B \Leftrightarrow A=B dist(A,B)=0⇔∥A∥2∥B∥2=AB⇔A=B
因此餘弦距離滿足正定性。 - 對稱性
根據餘弦距離的定義,有
dist ( A , B ) = ∥ A ∥ 2 ∥ B ∥ 2 − A B ∥ A ∥ 2 ∥ B ∥ 2 = ∥ B ∥ 2 ∥ A ∥ 2 − A B ∥ B ∥ 2 ∥ A ∥ 2 = dist ( B , A ) \begin{aligned} \operatorname{dist}(A, B) &=\frac{\|A\|_{2}\|B\|_{2}-A B}{\|A\|_{2}\|B\|_{2}}=\frac{\|B\|_{2}\|A\|_{2}-A B}{\|B\|_{2}\|A\|_{2}} \\ &=\operatorname{dist}(B, A) \end{aligned} dist(A,B)=∥A∥2∥B∥2∥A∥2∥B∥2−AB=∥B∥2∥A∥2∥B∥2∥A∥2−AB=dist(B,A)
因此餘弦距離肅足對稱性。 - 三角不等式
該性順並不成立,下面給出一個反例。給定 A = ( 1 , 0 ) , B = ( 1 , 1 ) , A=(1,0), B=(1,1), A=(1,0),B=(1,1),
C = ( 0 , 1 ) , C=(0,1), C=(0,1), 則有
dist ( A , B ) = 1 − 2 2 dist ( B , C ) = 1 − 2 2 dist ( A , C ) = 1 \begin{array}{r} \operatorname{dist}(A, B)=1-\frac{\sqrt{2}}{2} \\ \operatorname{dist}(B, C)=1-\frac{\sqrt{2}}{2} \\ \operatorname{dist}(A, C)=1 \end{array} dist(A,B)=1−22dist(B,C)=1−22dist(A,C)=1
因此有
dist ( A , B ) + dist ( B , C ) = 2 − 2 < 1 = dist ( A , C ) . \operatorname{dist}(A, B)+\operatorname{dist}(B, C)=2-\sqrt{2}<1=\operatorname{dist}(A, C) . dist(A,B)+dist(B,C)=2−2<1=dist(A,C).
假如面試時候跟張,一時想不到反例,該氣麼辦呢?此時可以思考
餘弦距離和歐氏距離的關歌。從問題 1 中,我們知道單位圓上歐氏距離和餘弦距離滿足
∥ A − B ∥ = 2 ( 1 − cos ( A , B ) ) = 2 dist ( A , B ) \|A-B\|=\sqrt{2(1-\cos (A, B))}=\sqrt{2 \operatorname{dist}(A, B)} ∥A−B∥=2(1−cos(A,B))=2dist(A,B)
即有如下關係
dist ( A , B ) = 1 2 ∥ A − B ∥ 2 \operatorname{dist}(A, B)=\frac{1}{2}\|A-B\|^{2} dist(A,B)=21∥A−B∥2
顯然在單位圓上 , 餘弦距離和 歐式氏距離的範圍都是[0 , 2 ]。我們已知歐式距離是一個合法的距離,而餘弦是離與歐氏距離有二次關係,自然不滿足三角不等式。具體來說,可以假設 A A A 與 B 、 B B 、 B B、B 與 C C C 非常近,其歐氏距離為極小量 u ; u ; u; 此時 A , B , C A, B, C A,B,C 雖然在圓尹上,但近似在一條直線上,所以 A 與 C 的因氏距離接近於 2u。因此,A 與 B 、 B B 、 B B、B 與 C 的餘弦距離為 u 2 / 2 ; A u^{2} / 2 ; A u2/2;A 與 C C C 的餘弦距離接近於 2 u 2 , 2 u^{2}, 2u2, 大於 A A A 與 B 、 B B_{、} B B、B 與 C C C 的餘弦距離之和。面試者在碰到這類基礎證明類的問題時,佳往會遇到一些困難。比如對面試官考察的重點「距離" 的定義就不一定清晰地記得。這個時快,就需要跟面試官多溝通,在距離的定義上達成一玫(要知道,面試考察的不僅是知識的掌握程度,還有面試者溝通和分析問題的能力)。要想給出一個完美的解答,就需要清晰的邀輯、嚴謹的思維。比如在正定性應該給出一些推導。最後,三角不等式的證明 / 證偽中,不應表述為「我覺得滿足 / 不滿足」,而是應該積極分針給定三個點時的三角關係,或者推導其和歐氏距離的關係,這樣照怕一時找不到反例而誤認為其是合法距離,也比「覺得不塗足" 這樣蒙對正確菩案要好。過去訓練模型時,首次注意到餘弦距離不符合三角不等式是在研究電視劇的標籤時,發現在通過影視語樣庫訓練出的詞向量中,comedy 和 funny、funny 和 happy 的餘弦距離都很近,小於 0.3,然而 comedy 和 happy的餘弦距離卻高達 0.7。這一現象明顯不符合社離的定義,引起了我們的注意和討論,經過思考和推導,得出了上述結論。在機單學習領域,被俗稱為距離,卻不滿足三祭距離公理的不僅僅有餘弦距離,還有 KL 距離(Kullback-Leibler Divergence),也叫作相對病,它常用於計算兩個分佈之間的差異,但不滿足對稱性和三角不等式。
4:A/B 測試的陷阱
場景描述
在網際網路公司中, A/B 測試是驗證新模組、新功能、新產晶是否高效,新演演算法、新模型的效果是否育提升,新設計是否受到使用者歡迎,新更改是否影響使用者體驗的主要測試方法。在機器學習領域中, A/B 測試是驗證模型最終效果的主要手段 。
知識點:A/B 測試, 實驗組 , 對照組
問題:在對模型進行過充分的離線評估之後,為什麼還要在行線上A/B 測試?
需要進行在結 A/B 測試的原因如下 。
- 離結評估無法完全消除模型過擬臺的影響,因此 3 得出的離線評估結果無法完全替代線上評估結果。
- 離線評估無法完全還原線上的工程環境。 一般來講,離結評估往往不會考慮線上環境的延遲 、資料丟失、標籤資料缺失等情況 。 因此,離線評估的結果是理想工程環境下的結果 。
- 線上系統的某些商業指標在離結評估中無法計算。離結評估一般是針對模型本身進行評估,而與模型相關的其他指標,特別是商業指標,往往無法直接獲得 。 比如,線了新的推薦演演算法, 離線評估往往關注的是 ROC 由線、 P -R 曲線等的改進, 而線上評估可以全面瞭解該推薦演演算法帶來的使用者點選率、留存時長、PV 存取量等的變化 。 這些都要由 A/B 測試來進行全面的評估。
問題:如何進行線上A/B測試
進行 A/B 測試的主要手段是進行使用者分桶,即將使用者分成實驗組和對照組,對實驗組的使用者施以新模型 ,對對照組的使用者施以舊模型 。在分桶的過程中, 要注意樣本的獨立性和取樣方式的無偏性,確保同一個使用者每次只能臺到同一個桶中,在分桶過程中所選取的 user_id 需要是一個亂數, 這樣才能保證桶中的樣本是無偏的 。
問題:如何劃分實驗組相對照組?
H 公司的演演算法工程師最近針對系統中的「美國使用者」研發了一套全新的視訊推薦模型 A ,而目前正在使用的針對全體使用者的推薦模型是B 。 在正式上線之前,工程師們希望通過 A/B 測試來驗證新推薦模型的效果 。 下面有三種實驗組相對照組的劃分方法, 請指出哪種劃分方法是正確的?
- 根據 user_id ( user_id 完全隨機生成)個位數的奇偶性將使用者劃分為實驗組和對照組 ,對實驗組施以推薦模型 A , 對照組施以模型 B
- 將 user_id 個位數為奇數且為美國使用者的作為實驗組 ,其餘使用者為對照組;
- 將 user_id 個位數為奇數且為美國使用者的作為實驗組, user_id 個位數為偶數的使用者作為對照組
上述 3 種 A/B 測試的劃分方法都不正確。我們用包含關係圖來說明三種劃分方法,如圖 2.4 所示。方法 1(見圖 2.4(a))沒有區分是否為美國使用者,實驗組和對照組的實驗結果均有稀釋; 方法 2(見圖2.4(b))的實驗組選取無誤,並將其餘所有使用者劃分為對照組,導致對照組的結果被稀釋; 方法 3(見圖 2.4(c )) 的對照組存在偏差。正確的做法是將所有美國使用者恨據 user_id 個位數劃分為試驗組合對照組(見圖 2.4(d)),分別施以模型 A A A 和 B , B, B, 才能夠驗證模型 A A A 的效果。
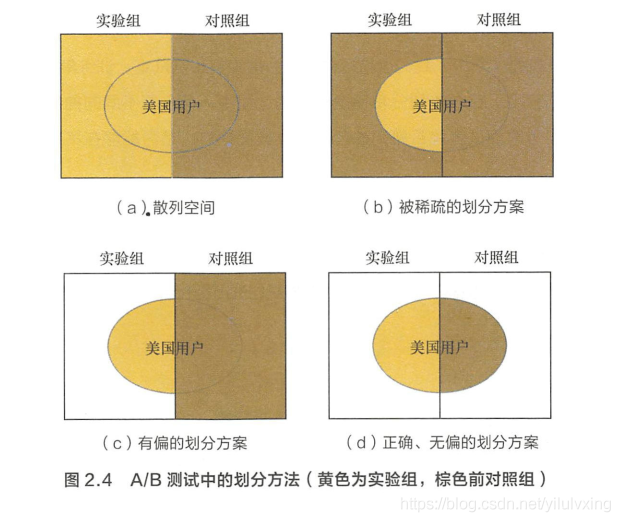
5:模型評估的方法
場景描述
在機器學習中,我們通常把樣本分為訓練集和測試集,訓練集用於訓練模型,測試集用於評估模型。在樣本劃分和模型驗證的過程中 ,存在著不同的抽樣方法和驗證方法 。 本小節主要考察面試者是否熟知這些方法及真優缺點、是否能夠在不同問題中挑選合適的評估方法。
知識點:Holdout 檢驗,交叉驗證,自由法( Bootstrap ),微積分
-
交叉檢驗
k-fold 交叉驗證: 首先條全部樣本劃分成 k個大小相等的樣本子集;依次遍歷這 k 個子集,每次把當前子集作為驗證貿,其餘所有子集作為訓刊集,進行模型的訓練和評估:最後把 k 次評估指標的平均值作為最終的評估指標。在實際實驗中,k經常取 10。樣本總數為 n,依次對 n 個樣本進行追歷,進行 n 次驗證,再將評估指標求平均值得型最終的評估指標。在樣本總數較多的情況下,留一然證法的
時間開銷極大。事實上,留一驗證是留 p p p 驗證的特例。留 p p p 驗證是每次留下 p p p 個樣本作為驗證集,而從 n n n 個元素中選擇 p p p 個元素有 C n p C_{n}^{p} Cnp種可能,因此它的時間開銷更是遠遠高於留一驗證,故而很少在實際工程中被應用。 -
自助法
不管是 Holdout 檢驗還是交叉檢侖,都是基於劃分訓練集和測試集的方法進行模型評估的。然而,當樣本規模比較小時,將樣本集進行也分會讓訓練集進一步減小,這可能會影響模型訓練效果。有沒有能維持訓練樣本規模的驗證方法呢?自助法可以比較好地解決這個問題。自助法是基於自助取樣法的檢驗方法。對於總數為 n n n 的樣本集合,有的樣本會被重複取樣,有的樣本沒有被抽出過,將這些沒有被抽出的樣本作為驗證集,進行模型驗證,這就是自助法的驗證過程。
在自助法的取樣過程中,對 n個樣本避行 n 次自助抽樣,當 n趨於無窮大肘,最終有多少資料從來未被選擇過?
一個樣本在一次抽樣過程中未被抽中的概率為
(
1
−
1
n
)
,
n
\left(1-\frac{1}{n}\right), n
(1−n1),n 次抽樣均未抽中的概率為
(
1
−
1
n
)
n
\left(1-\frac{1}{n}\right)^{n}
(1−n1)n 。當
n
n
n 趨於無窮大時,概率為
lim
n
→
∞
(
1
−
1
n
)
n
\lim _{n \rightarrow \infty}\left(1-\frac{1}{n}\right)^{n}
limn→∞(1−n1)n根據重要極限,
lim
n
→
∞
(
1
+
1
n
)
n
=
e
,
\lim _{n \rightarrow \infty}\left(1+\frac{1}{n}\right)^{n}=\mathrm{e},
limn→∞(1+n1)n=e, 所以有
lim
n
→
∞
(
1
−
1
n
)
n
=
lim
n
→
∞
1
(
1
+
1
n
−
1
)
n
=
1
lim
n
→
∞
(
1
+
1
n
−
1
)
n
−
1
⋅
1
lim
n
→
∞
(
1
+
1
n
−
1
)
=
1
e
≈
0.368
\begin{aligned} \lim _{n \rightarrow \infty}\left(1-\frac{1}{n}\right)^{n} &=\lim _{n \rightarrow \infty} \frac{1}{\left(1+\frac{1}{n-1}\right)^{n}} \\ &=\frac{1}{\lim _{n \rightarrow \infty}\left(1+\frac{1}{n-1}\right)^{n-1} \cdot \frac{1}{\lim _{n \rightarrow \infty}\left(1+\frac{1}{n-1}\right)}} \\ &=\frac{1}{\mathrm{e}} \approx 0.368 \end{aligned}
n→∞lim(1−n1)n=n→∞lim(1+n−11)n1=limn→∞(1+n−11)n−1⋅limn→∞(1+n−11)11=e1≈0.368
因此,當樣本數很大時,大約有 36.8% 的樣本從未被選擇過,可作為
驗證集。
6:超引數調優
場景描述
對於很多演演算法工程師來說,超引數調優是件非常頭度的事。除了根據經驗設定所謂的「合理值" 之外,一般很難找到合理的方法去尋擾超引數的最代取值。而與此同時,超引數對於模型效果的影響又至關重要要。有沒有一些可行的辦法去進行超引數的調優呢?
問題:超引數有哪些調優方法?
為了進行超引數調優,我們一般會慄用網格搜尋,隨機機搜尋、貝葉斯代化等演演算法。在具體介紹演演算法之前,需要明確超引數搜尋演演算法一般包括第幾個要素。一是目標函數, 即演演算法需要最大化/最小化的目標 二是搜素範圍,一般通過上限和下限來確定; 三是演演算法的其他引數,如搜尋步長。
-
網格搜尋
網格搜尋可能是最簡單、應用最廣泛的超引數搜尋演演算法,它通過查詢搜尋範圍內的所有的點來確定最優值。如果採用較大的搜尋範圍以及較小的步長,網格搜尋有很大概率找到全域性最優值。然而,這種搜尋方案十分消耗計算資源和時間,特別是需要調優的超引數比較多的時候。因此,在實際應用中,網格搜尋法一般會先使用較廣的搜尋範圍和較大的步長,來尋找全域性最優值可能的位置:然後會逐漸縮小搜素範圍和步長,來尋找更精確的最優值。這種揚作方案可以降低所需的時間和計算量,但由於目標函數一般是非凸的,所以很可能會錯過全域性最優值。 -
隨機搜尋
隨機搜尋的思想與網格搜尋比較相似,只是不再測試上界和下界之間的所有值,而是在搜尋範圍中隨機選取樣本點。它的理論依據是,如果樣本點集足夠大,那麼通過隨機取樣也能大概率地找到全域性最優值,或其近似值。隨機搜尋一般會比網格搜尋要快一些,但是和網格提索的快速版一樣,它的結果也是沒法保證的。 -
貝葉斯優化演演算法
貝葉斯優化演演算法在尋找最優最值引數時,採用了與網格搜尋、隨機搜尋完全不同的方法。網格搜尋和隨機搜尋在測試一個新點時,會忽略前一個點的資訊; 而貝葉斯優化演演算法則充分利用了之前的資訊。貝葉斯優化演演算法通過對目標函數形狀進行學習,找到使目標函數向全域性最優值提升的引數。具體來說,它學習目標函數形狀的方法是,首先根據先驗分佈,假設一個蒐集函數,然後每一次使用心得取樣點來測試目標函數時,利用這個資訊來更新目標函數的先驗分佈; 最後,演演算法通試由後驗分佈給出的全域性最值最可能出現位置的點,一旦找到了一個區域性最優值,它會在該區域不斷取樣,所以很容易陷入區域性最優值。為了彌補這個缺陷,貝葉斯優化演演算法會在探索和利用之間找到一個平貨點,「探索" 就是在還未取樣的區域獲取取樣點; 而「利用」則是棍據後驗分佈在最可能出現全域性最值的區域進行取樣。
07:過擬臺與欠擬臺
場景描述
在模型評估與調整的過程中 ,我們往往會遇到「過擬合」或「欠擬合」的情況 。 如何
有效地識別 「過擬臺」和「欠擬合"現象 ,並有針對性地進行模型調整 ,是不斷改進機器學習模型的關鍵 。 特別是在實際專案中,採用多種方法、從多個角度降低「過擬臺」和「欠擬臺」的風險是演演算法工程師應當真備的領域知識 。
知識點:過擬臺 , 欠擬合
問題:在模型評估過程中,過擬合欠擬合真體是指什麼現象?
過擬合是指模型對於訓練資料擬合呈過當的情況,反映到評估揭標上 ,就是模型在訓練集上的表現很好,但在測試集和新資料上的表現較差 。 欠擬合指的是模型在訓練和預測時表現都不好的情況 。 圖2.5 形象地描述了過擬臺和欠擬臺的區別 。
可以看出,圖
2.5
(
2.5(
2.5( a
)
)
) 是欠擬合的情況,擬合的黃線沒有很好地捕捉到資料的特徵, 不能很好地擬合資料。圖
2.5
(
c
)
2.5(\mathrm{c})
2.5(c) 則是過擬合的情況,導致模型泛化能力下降,在後期應用過程中很容易輸出錯誤的預測結果。
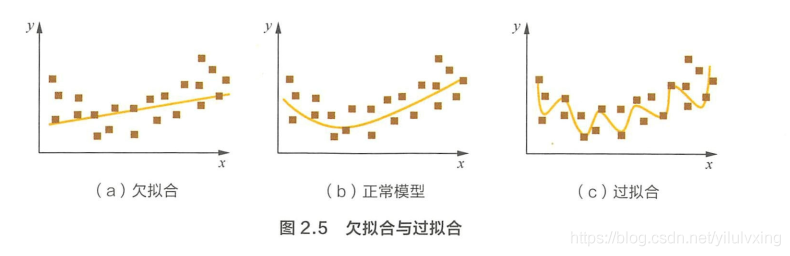
問題:能否說出幾種降低過擬臺和欠擬合風險的方法?
- 降低「過擬合」風險的方法
(1)從資料入手,獲得更多的訓練資料。使用更多的訓練資料是解決過擬合問題最有效的手段,因為更多的樣本能夠讓模型學習到更多更有效的特徵,減小噪聲的影響。當然,直接增加實驗資料一般是很困難的,但是可以通過一定的規則來擴充訓練資料。比如在影象分類的問題上,可以通過影象的平移、旋轉、縮放等方式擴充資料:更進一步地,可以使用生成式對抗網路來合成大量的新訓練資料。
(2)降低模型複雜度。在資料較少時,模型過於複雜是產生過擬合的主要因素, 適當降低模型複雜度可以避免模型擬合過多的取樣噪聲。例如,在神經網路模型中減少網路層數、神經元個數等;在決策樹模型中降低樹的深度、進行剪枝等
。
(3)正則化方法。給模型的引數加上一定的正則約束,比如將權值的大小加入到損失函數中。以 L2 正則化為例:
C = C 0 + λ 2 n ⋅ ∑ i w i 2 C=C_{0}+\frac{\lambda}{2 n} \cdot \sum_{i} w_{i}^{2} C=C0+2nλ⋅i∑wi2
這樣,在優化原來的目標函數 C 0 C_{0} C0, 的同時,也能避免權值過大帶來的過擬合風險。
(4)整合學習方法。整合學習是把多個模型整合在一起,來降低單一模型的過擬合風險,如 Bagging 方法。