行人檢測特徵提取_HOG和adaboost檢測行人檢測
一 特徵提取
1.1 矩特徵
矩特徵主要表徵了影象區域的幾何特徵,又稱為幾何矩, 由於其具有旋轉、平移、尺度等特性的不變特徵,所以又稱其為不變矩。在影象處理中,幾何不變矩可以作為一個重要的特徵來表示物體,可以據此特徵來對影象進行分類等操作。
矩特徵是目前特徵提取過程中效果比較理想的方法 矩實際上是影象灰度相對於影象質心的統計情況反映, Hu在1961 年首先提出了矩不變數的概念,並闡述了 7 個不變矩的公式, Li利用 Fourier-Mellin 變換的不變性推匯出一種構造任意階矩不變數的方法 並指出 Hu 矩就是它的一個特例,Zernike 在 Hu 的 7 個不變矩的基礎上做了進一步改進 提出了一組完備正交多項式{Vnm (x, y)},影象的 Zemike 矩實際上是影象在該正交多項式上的投影; D Shen 和 H H S 利用小波變換構造了具有旋轉不變性的目標影象特徵小波矩,小波矩結合了小波和矩的特性,其不僅可以得到影象的全域性特徵,也可以得到影象的區域性特徵,因而在識別相似形狀的物體時有更高的識別率[1]。下面主要敘述HU矩和Zernike矩。
與手工計算一個特徵集不同的是,多層感知器提供一種合適的特徵提取方法通過它的隱藏層,以便於特徵在訓練過程中調整到資料集。Fukushima提出了用LRF特徵的前饋神經網路,後來被Wohler and Anlauf應用到行人分類器上,是一種特別吸引人的2維影象分類方法。與標準的多層感知器形成對比的是,在隱藏層的神經細胞僅僅與輸入影象的受限區域性區域,被稱為區域性接受域(見圖三)。隱層分為多個分支,一個分支的所有的神經元共用同樣的權重集。區域性連通和權重共用性有效地降低了訓練階段需要確定的權重數量,從而允許相對小型的訓練集得到高的尺寸。
We further investigate the concept of LRFs by extracting the output of the hidden layer of a (once trained) NN/LRF as features subject to classification by generic classification methods (other than neural networks). Preliminary experiments have shown receptive fields of size 5X5 to be optimal, shifted at a step size of 2 pixels over the input image of size 18 X36. The number of branches is varied within the values of {8; 16; 24; 32} during parameter optimization.
我們進一步研究通過提取一個NN/LRF的隱層輸出作為特徵LRFs提取輸出的隱層受通用分類分類方法(除了神經網路)限制的LRF的概念。初步實驗顯示出的接受域大小的5X5為最佳,每一步改變2個畫素在大小為的18 X36輸入影象。在引數優化過程中分支的數量在{8; 16; 24; 32}中變化[4]。
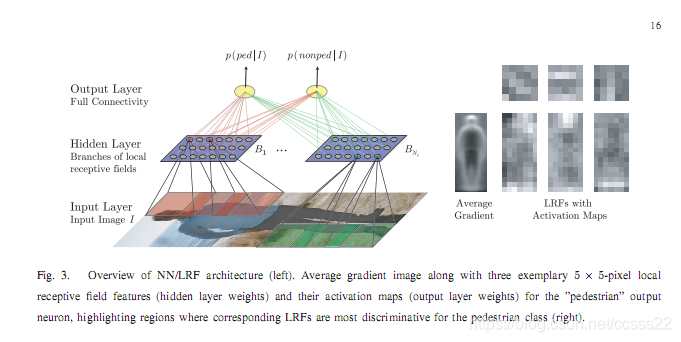
我下載參考文獻[4]中LRF的參考文獻,這些文獻中也有講到local receptive fields的,但是也只是描述NN/LRF的應用,並沒有敘述LRF的概念,如何得到的,其中有一些是講到了local features和spatio-temporal receptive fields的,LRF多是與NN結合起來用,與我們的框架不符,可以不考慮增加LRF特徵。
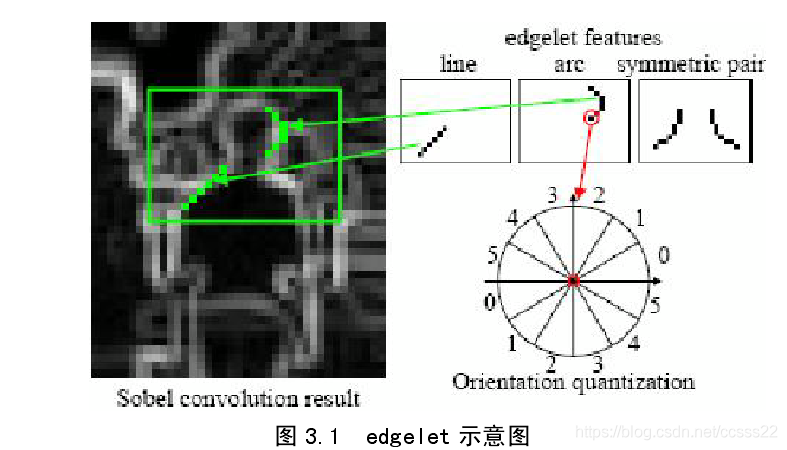
1.3 Edgelet特徵[5][6]
Edgelet特徵描述的是人體的輪廓特徵,但是它描述的是人體區域性輪廓的特徵,包括的形狀有直線、弧線等,它將人體分為幾個部分來訓練,比如:全身、頭肩部、腿部和軀幹部等,每個部分都使用adaboost演演算法訓練一個強分類器;在分類時,利用四個部分的聯合概率來判斷。由於該演演算法採用的是人體的區域性特徵,所以在出現遮擋的情況下仍然有很好的表現,缺點是特徵的計算比較複雜。
Wu Bo提取影象的edgelet特徵用於檢測靜態影象中的人體,對組成人體的各個部分分別建立模型,每一個edgelet描述人體的某個部位的輪廓,然後再用adaboost演演算法篩選出最有效的一組edgelet來描述人的整體。
如圖3.1所示,Wu Bo定義了三種edgelet,包括直線型、弧形和對稱型。每一個edgelet由一組邊緣點構成,是一條具有一定形狀和位置的線段。對於影象中任意的位置,根據該位置是否具有和某edgelet形狀相似的邊緣,就可以得到一個響應值。如果邊緣的形狀與edgelet越相似,那麼響應值就越高。
edgelet在某個位置(x,y)上的響應值可以這樣計算。
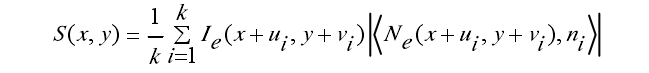
這種方法分別檢測視窗的區域性區域,然後再綜合這些區域的檢測結果來做最終的判決。這類方法的優點在於能更好地處理遮擋以及行人姿勢的多樣性。主要問題在於,如何定義區域性以及如何整合來自多個部位檢測器的資訊。
其中,K是點的數目。(ui ,vi)是該點在edgelet中的位置。Ie(x+ui,y+vi)是影象中對應該點的邊緣強度,Ne(x+ui,y+yi),ni表示影象中(x+ui,y+vi)點的梯度的法向量和edgelet中該點的法向量的內積。
綜上,可以得到edgelet相對於整體特徵有其自身的優點,這種方法以檢測區域性為基礎,在得到了各個區域性的檢測結果後,再分析各區域性之間的相互關係來得到最終的檢測結果。這種方法的優點在於能更好地處理遮擋以及行人姿勢的多樣性。這種方法的主要問題是,怎樣定義區域性和怎樣整合來自多個區域性位置的分類器的資訊。
1.4 Shapelet特徵[7]
2007年Sabzmeydani[20]提出了基於Shapelet特徵的目標檢測演演算法,其相較於Dalal提出的基於Hog特徵的演演算法將誤檢率進一步降低了整整10倍。該演演算法最核心的思想是利用機器學習的方法自動地生成自適應的區域性特徵。Shapelet特徵是一系列mid-level特徵的集合。這些特徵集中描述影象的區域性區域特徵,並通過Adaboost集中訓練low-level的梯度資訊組合構建而成。以往的物體檢測演演算法其主要的一個缺點就是在於使用固定的特徵描述模型,其弊端在於特徵的形成缺乏自適應性,很多情況下可能會丟失一些具有判別力的細節資訊,而機器學習往往只是利用來設定分類器的引數或者選擇特徵的;相對的,在基於Shapelet特徵的演演算法中,特徵本身就是通過機器學習,由很多low-level的梯度資訊組合而來的,是機器學習在目標檢測中更為徹底與深入的應用。
該演演算法的核心思想就是,兩次利用Adaboost演演算法:第一步,著眼於(靜態)影象區域性,對於影象區域性區域內所有的低階特徵(Low-Level,如最簡單的邊緣梯度特徵等)進行第一次的Adaboost訓練,訓練以後得到低階特徵的加權和,即為Shapelet特徵;然後,第二次使用Adaboost在所有求得的Shapelet特徵中進行訓練,選擇最優秀的弱分類器組合而得最終的強分類器。
基於Shapelet特徵的訓練過程包括以下三步:
第一步,輸入訓練樣本圖片,計算每幅影象在不同方向上的梯度值,Sabzmeydani使用了{0°,45°,90°,135°}四個方向,然後進行平滑濾波。每個low-level特徵包括位置、方向、以及強度大小三個資訊。這些low-level的梯度值用來構建Shapelet特徵。

第二步,求取Shapelet特徵。在每個子視窗內,通過Adaboost選擇部分割區分樣本類別能力優秀的部分low-level特徵來構建mid-level的Shapelet特徵。每個子視窗都可以以此得到一個Shapelet特徵,每一個Shapelet特徵都比直接的low-level特徵的區分能力要強,它是子視窗內不同方向不同位置的梯度的組合。
第三步,訓練最終的強分類器。單一的Shapelet特徵僅僅描述影象的一個區域性區域的輪廓資訊,因此它的分類能力是非常有限的。我們將之前所有求得的Shapelet特徵作為輸入,第二次利用Adaboost進行訓練來構造最終的強分類器。
Shapelet特徵通過先著眼於區域性的小特徵集,從底層特徵通過機器學習得出中層特徵(Mid-Level)的方法,嘗試獲得更多更有用的細節資訊,而無需同時考場所有的低層特徵。Shapelet特徵的特性:簡單、低維;由目標物體學習而來,對其他類別的物體具有排他性;具有比較強的判別能力;區域性同樣有效:可將整體分為各部分分別提取特徵[5]。
我們的行人檢測的主體框架和這些論文的行人檢測主體框架是一致的,差別在於兩個方面:一,特徵提取我們的是單一的矩形HOG特徵並沒有和其他特徵如shapelet特徵融合,沒有用到高斯權重和三線性插值,也沒有嘗試圓型HOG特徵,而有一些論文就做了一些相關工作;二,我們的分類器只是標準的adaboost級聯(GAB級聯),只是adaboost的弱分類器是用二元樹來實現的,而上述論文中有的adaboost分類器的弱分類器用SVM實現,有的分類器用adaboost和決策樹結合來實現,有一些是標準的adaboost級聯。