Hadoop原始碼分析【1-5】
寫在前面: 博主是一名巨量資料的初學者,暱稱來源於《愛麗絲夢遊仙境》中的Alice和自己的暱稱。作為一名網際網路小白,
寫部落格一方面是為了記錄自己的學習歷程,一方面是希望能夠幫助到很多和自己一樣處於起步階段的萌新。由於水平有限,部落格中難免會有一些錯誤,有紕漏之處懇請各位大佬不吝賜教!個人小站:http://alices.ibilibili.xyz/ , 部落格主頁:https://alice.blog.csdn.net/
儘管當前水平可能不及各位大佬,但我還是希望自己能夠做得更好,因為一天的生活就是一生的縮影。我希望在最美的年華,做最好的自己!

Hadoop原始碼分析(一)
Google 的核心競爭技術是它的計算平臺。Google 的大牛們用了下面 5 篇文章,介紹了它們的計算設施。
GoogleCluster: http://research.google.com/archive/googlecluster.html
Chubby:http://labs.google.com/papers/chubby.html
GFS:http://labs.google.com/papers/gfs.html
BigTable:http://labs.google.com/papers/bigtable.html
MapReduce:http://labs.google.com/papers/mapreduce.html
很快,Apache 上就出現了一個類似的解決方案,目前它們都屬於 Apache 的 Hadoop 專案,對應的分別是:
Chubby-->ZooKeeper
GFS-->HDFS
BigTable-->HBase
MapReduce-->Hadoop
目前,基於類似思想的 Open Source 專案還很多,如 Facebook 用於使用者分析的 Hive。
HDFS 作為一個分散式檔案系統,是所有這些專案的基礎。分析好 HDFS,有利於瞭解其他系統。由於 Hadoop 的 HDFS 和 MapReduce 是同一個專案,我們就把他們放在一塊,進行分析。
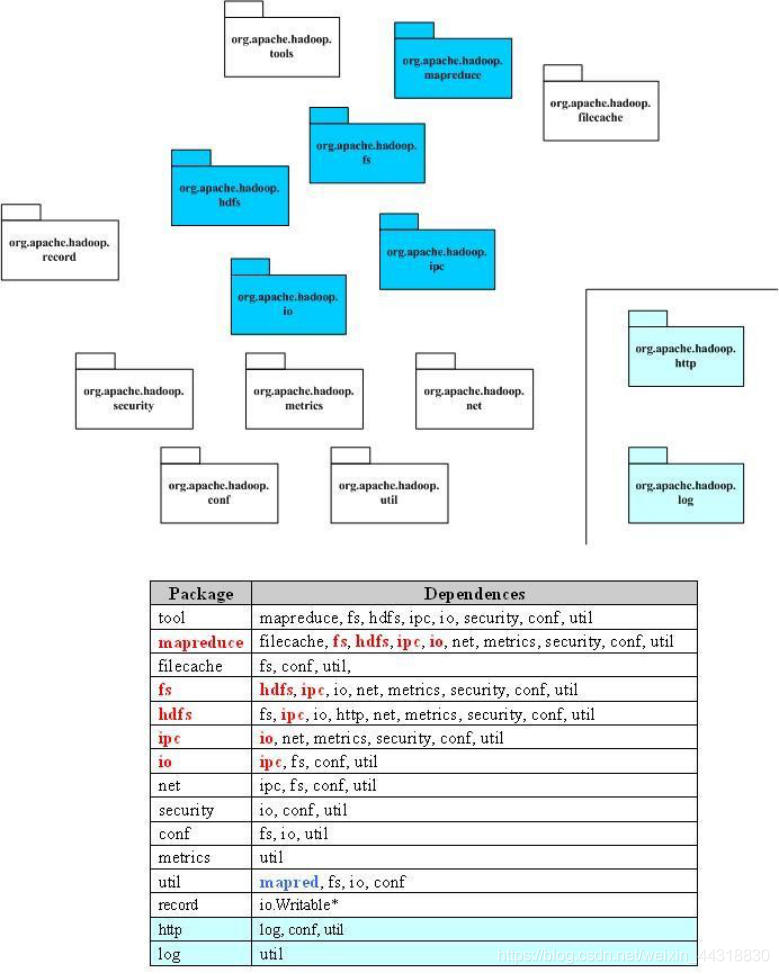
下圖是 MapReduce 整個專案的頂局包圖和他們的依賴關係。Hadoop 包之間的依賴關係比較複雜,原因是 HDFS 提供了一個分散式檔案系統,該系統提供 API,可以遮蔽本地檔案系統和分散式檔案系統,甚至象 Amazon S3 返樣的線上儲存系統。這就造成了分散式檔案系統的實現,或者是分散式檔案系統的底層的實現,依賴於某些貌似高層的功能。功能的相互參照,造成了蜘蛛網型的依賴關係。一個典型的例子就是包 conf,conf 用於讀取系統設定,它依賴於 fs,主要是讀取組態檔的時候,需要使用檔案系統,而部分的檔案系統的功能,在包 fs 中被抽象了。
Hadoop 的關鍵部分集中於圖中藍色部分,這也是我們考察的重點。
Hadoop原始碼分析(二)
下面給出了 Hadoop 的包的功能分析。
| Package | Dependences |
|---|---|
| tool | 提供一些命令列工具,如 DistCp,archive |
| mapreduce | Hadoop 的 Map/Reduce 實現 |
| filecache | 提供HDFS檔案的本地快取, 用於加快Map/Reduce 的資料存取速度 |
| fs | 檔案系統的抽象,可以理解為支援多種檔案系統實現的統一檔案存取介面 |
| hdfs | HDFS,Hadoop 的分散式檔案系統實現 |
| ipc | 一個簡單的 IPC 的實現,依賴於 io 提供的編解碼功能 |
| io | 表示層,將各種資料編碼/解碼,方便於在網路上傳輸 |
| net | 封裝部分網路功能,如 DNS,socket |
| security | 使用者和使用者組資訊 |
| conf | 系統的設定引數 |
| metrics | 系統統計資料的收集,屬於網管範疇 |
| util | 工具類 |
| record | 根據 DDL(資料描述語言)自動生成他們的編解碼函數,目前可以提供 C++ 和 Java |
| http | 基於 Jetty 的 HTTP Servlet,使用者通過瀏覽器可以觀察檔案系統的一些狀態資訊和紀錄檔 |
| log | 提供 HTTP 存取紀錄檔的 HTTP Servlet |
Hadoop原始碼分析(三)
由於 Hadoop 的 MapReduce 和 HDFS 都有通訊的需求,需要對通訊的物件進行序列化。Hadoop 並沒有採用 Java 的序列化,而是引入了它自己的系統。
org.apache.hadoop.io中定義了大量的可序列化物件,他們都實現了 Writable 介面。實現了 Writable 介面的一個典型例子如下:
public class MyWritable implements Writable {
// Some data
private int counter;
private long timestamp;
public void write(DataOutput out) throws IOException {
out.writeInt(counter);
out.writeLong(timestamp);
}
public void readFields(DataInput in) throws IOException {
counter = in.readInt();
timestamp = in.readLong();
}
public static MyWritable read(DataInput in) throws IOException {
MyWritable w = new MyWritable();
w.readFields(in);
return w;
}
}
其中的 write 和 readFields 分別實現了把物件序列化和反序列化的功能,是 Writable 介面定義的兩個方法。下圖給出了龐大的 org.apache.hadoop.io 中物件的關係。
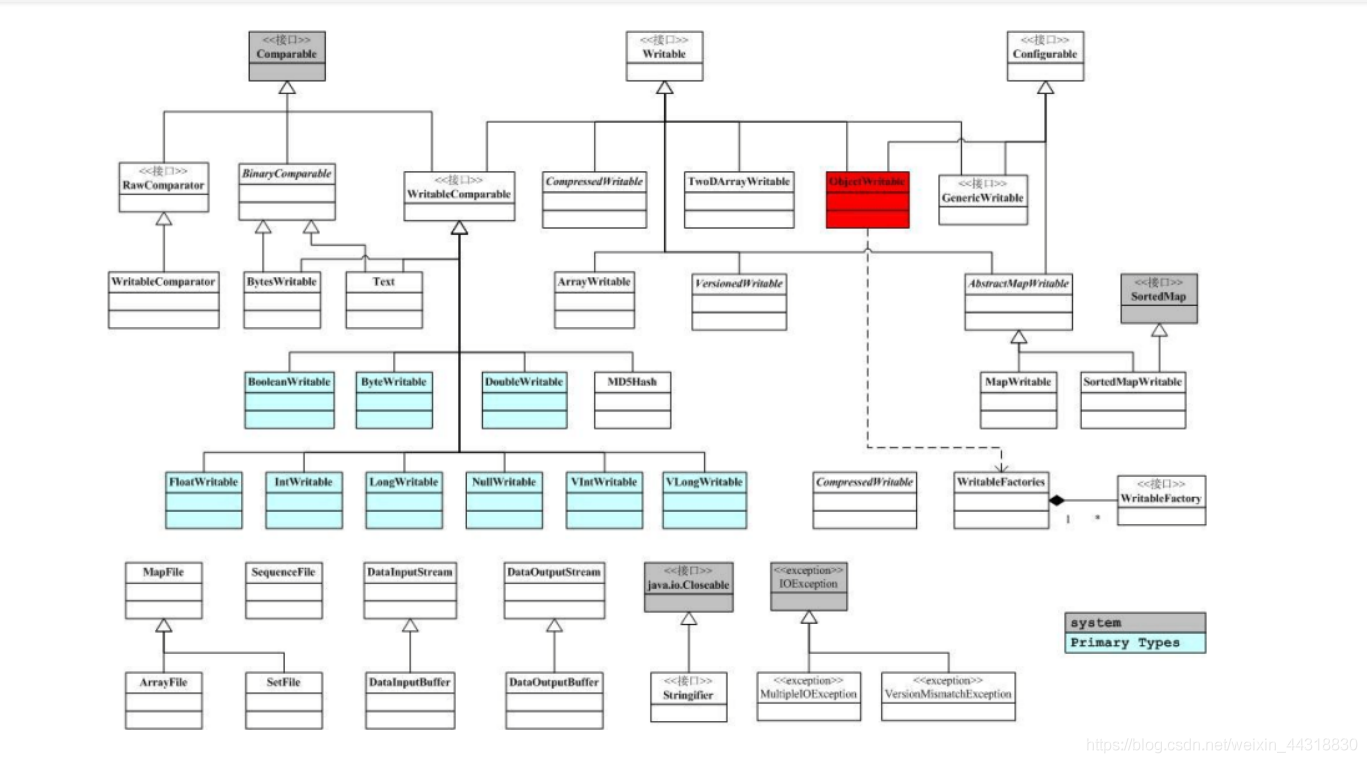
這裡,把 ObjectWritable 標為紅色,是因為相對於其他物件,它有不同的地位。當我們討論 Hadoop的 RPC時,我們會提到RPC上交換的資訊, 必須是 Java 的基本型別, String 和 Writable 介面的實現類, 以及元素為以上型別的陣列。
ObjectWritable物件儲存了一個可以在 RPC上傳輸的物件和物件的型別資訊。 這樣,我們就有了一個萬能的, 可以用於使用者端 / 伺服器間傳輸的
Writable 物件。例如,我們要把上面例子中的物件作為 RPC請求,需要根據 MyWritable 建立一個 ObjectWritable ,ObjectWritable 往流裡會寫如下資訊。
物件類名長度,物件類名,物件自己的序列化結果
這樣,到了對端, ObjectWritable 可以根據物件類名建立對應的物件,並解序列。應該注意到, ObjectWritable 依賴於 WritableFactories ,那裡儲存了 Writable 子類對應的工廠。我們需要把 MyWritable 的工廠,儲存在 WritableFactories 中(通過 WritableFactories. setFactory )。
Hadoop原始碼分析(四)
介紹完 org.apache.hadoop.io 以後,我們開始來分析 org.apache.hadoop.rpc 。RPC採用客戶機 / 伺服器模式。 請求程式就是一個客戶機,而服務提供程式就是一個伺服器。當我們討論 HDFS的,通訊可能發生在:
- Client-NameNode 之間,其中 NameNode 是伺服器
- Client-DataNode 之間,其中 DataNode 是伺服器
- DataNode-NameNode 之間,其中 NameNode 是伺服器
- DataNode-DateNode 之間,其中某一個 DateNode 是伺服器,另一個是使用者端
如果我們考慮 Hadoop的 Map/Reduce以後,這些系統間的通訊就更復雜了。為了解決這些客戶機 / 伺服器之間的通訊, Hadoop引入了一個 RPC框架。該 RPC框架利用的 Java 的反射能力,避免了某些 RPC解決方案中需要根據某種介面語言(如 CORBA的
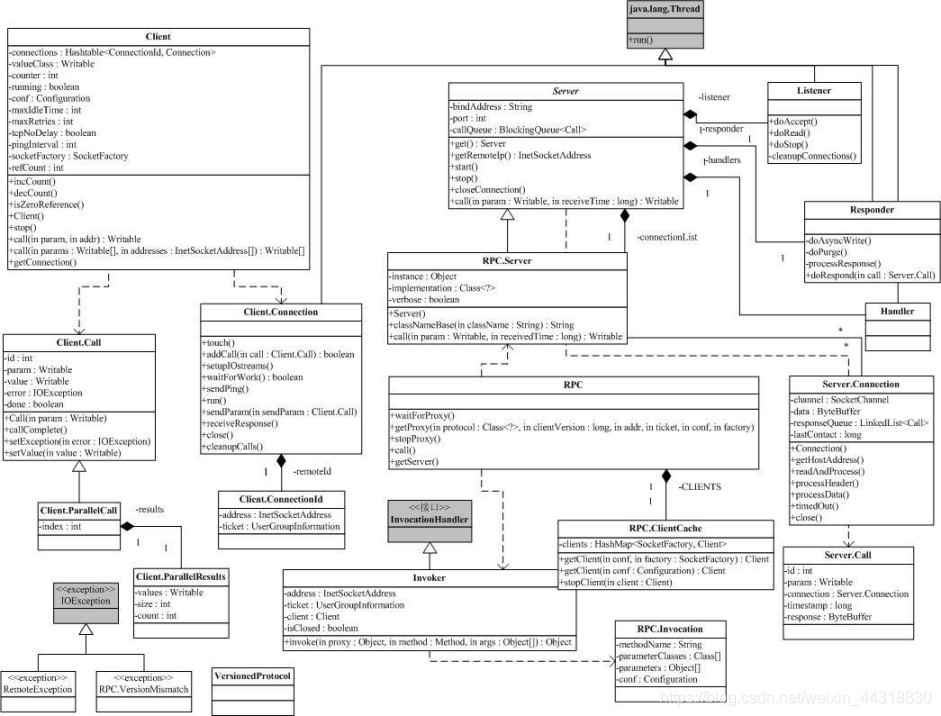
IDL)生成存根和框架的問題。但是,該 RPC框架要求呼叫的引數和返回結果必須是 Java 的基本型別, String 和 Writable 介面的實現類,以及元素為以上型別的陣列。同時,介面方法應該只丟擲 IOException 異常。
既然是 RPC,當然就有使用者端和伺服器,當然, org.apache.hadoop.rpc也就有了類 Client 和類 Server 。但是類 Server 是一個抽象類,類 RPC封裝了 Server ,利用反射,把某個物件的方法開放出來,變成 RPC中的伺服器。
下圖是 org.apache.hadoop.rpc 的類圖。
Hadoop原始碼分析(五)
既然是 RPC,自然就有使用者端和伺服器,當然, org.apache.hadoop.rpc 也就有了類 Client 和類 Server 。在這裡我們來仔細考察 org.apache.hadoop.rpc.Client 。下面的圖包含了 org.apache.hadoop.rpc.Client 中的關鍵類和關鍵方法。
由於 Client 可能和多個 Server 通訊,典型的一次 HDFS讀,需要和 NameNode打交道,也需要和某個 / 某些 DataNode通訊。這就意味著某一個 Client 需要維護多個連線。同時,為了減少不必要的連線,現在 Client 的做法是拿 ConnectionId (圖中最右側)來做為 Connection 的 ID。ConnectionId 包括一個 InetSocketAddress (IP 地址+埠號或主機名 +埠號)物件和一個使用者資訊物件。這就是說,同一個使用者到同一個 InetSocketAddress 的通訊將共用同一個連線。
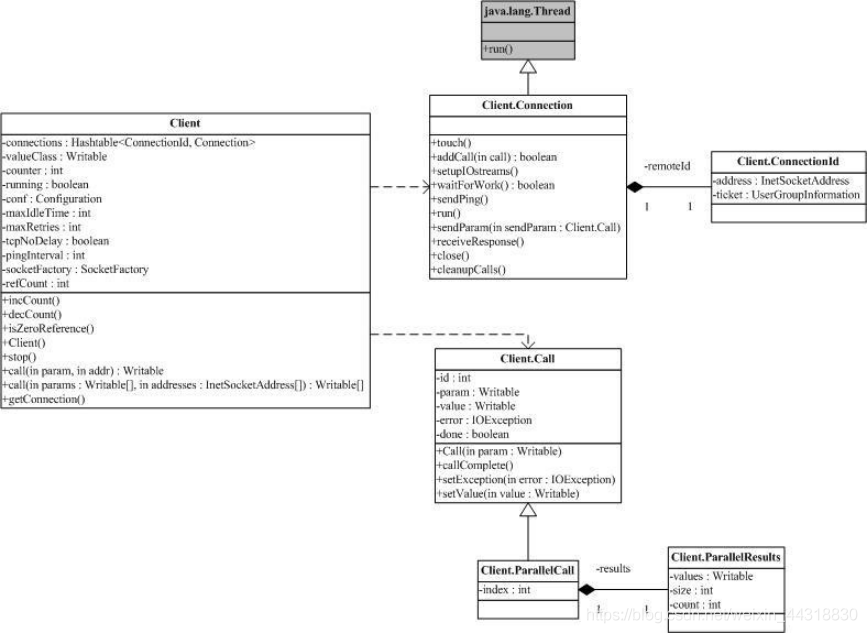
連線被封裝在類 Client.Connection 中,所有的 RPC呼叫,都是通過 Connection ,進行通訊。一個 RPC呼叫,自然有輸入引數,輸出引數和可能的異常,同時,為了區分在同一個 Connection 上的不同呼叫,每個呼叫都有唯一的 id 。呼叫是否結束也需要一個標記,所有的這些都體現在物件 Client.Call 中。Connection 物件通過一個 Hash表,維護在這個連線上的所有 Call :
private Hashtable<Integer ,Call>calls = new Hashtable<Integer,Call>();
一個 RPC呼叫通過 addCall ,把請求加到 Connection 裡。為了能夠在這個框架上傳輸 Java 的基本型別, String 和 Writable 介面的實現類,以及元素為以上型別的陣列,我們一般把 Call 需要的引數打包成為 ObjectWritable 物件。
Client.Connection 會通過 socket 連線伺服器,連線成功後回校驗使用者端 / 伺服器的版本號(Client.ConnectionwriteHeader()方法),校驗成功後就可以通過 Writable 物件來進行請求的傳送 / 應答了。注意,每個 Client.Connection 會起一個執行緒,不斷去讀取 socket ,並將收到的結果解包,找出對應的 Call ,設定 Call 並通知結果已經獲取。
Call 使用 Obejct 的 wait 和 notify ,把 RPC上的非同步訊息互動轉成同步呼叫。
還有一點需要注意,一個 Client 會有多個 Client.Connection ,這是一個很自然的結果。
小結
Hadoop原始碼分析【1-5】主要為大家科普了Hadoop下的各種包的功能分析,以及Hadoop下兩大核心HDFS和MapReduce如何基於RPC框架去實現通訊,資料傳輸。
本篇文章就到這裡,更多精彩文章及福利,敬請關注博主原創公眾號【猿人菌】!
