四萬字的 MySQL 詳細入門學習(附帶練習題)
寫在前面:本部落格是根據動力節點課程所寫的筆記,原視訊連結:https://www.bilibili.com/video/BV1fx411X7BD?p=1
關於這篇部落格,可能內容比較基礎,很多細節的東西沒講到,後面我還會繼續跟進這篇部落格,做好修改。
目錄
一、資料庫簡介
二、安裝MySQL
三、DB、DBMS、SQL的關係
四、表
五、SQL語句的分類
六、匯入初始化資料
七、檢視表結構以及表中的資料
八、MySQL的常用命令
九、查詢簡介及簡單查詢
十、條件查詢
十一、排序查詢
十二、分組查詢
十三、去重查詢
十四、連線查詢
十五、子查詢
十六、聯表查詢
十七、分頁查詢
十八、表的建立
十九、插入資料
二十、修改資料
二十一、刪除資料
二十二、修改表結構
二十三、約束
二十四、儲存引擎
二十五、事務
二十六、索引
二十七、檢視
二十八、資料庫的匯入匯出
二十九、設計三正規化
三十、作業題
一、資料庫簡介
在學習資料庫之前,我們回憶一下在IO流中所學習的一個序列化流和反序列化流,可以向檔案中存入物件,也可以從檔案中取出物件,這無疑是儲存和取出資料的一種形式。
我們學習資料庫,也是為了運算元據,其包括對資料的增加、刪除、修改、和查詢,那你就會問了,既然二者功能相同,那為什麼不能直接用序列化流呢?
那肯定是因為【資料庫管理系統】來運算元據更加簡單啊,只需要通過簡單的sql語句就能完成對資料的操作,不需要向序列化流那樣,需要建立物件啊,存入檔案啊,關閉流啊等等麻煩的操作。
什麼是資料庫?
本質上是一個資料夾,先有個概念,往下文看你就知道了。
什麼是資料庫管理系統(DBMS)呢?
顧名思義,管理資料庫的軟體,常見的有MySQL(免費,供初學者學習的),Oracle(付費,效能比MySQL好很多,一般是公司中使用的),SQL Server(大學課程中都用這個DBMS來教學)。
二、安裝MySQL
為了學習資料庫,接下來,我們安裝一個資料庫管理系統MySQL。安裝與設定,我都寫在一篇部落格里了,很詳細,還有百度網路硬碟連結,這裡就不花篇幅寫了
https://blog.csdn.net/weixin_43724203/article/details/108651956
三、DB、DBMS、SQL的關係
上文提到幾個概念DB、DBMS、SQL,來總結一下,看看他們之間的關係。
DB(DataBase):本質是資料夾,用來儲存資料
DBMS(DataBase Management System):資料庫管理系統,用來管理資料庫,也就是對資料庫中的資料進行管理
SQL(Structure Query Language):結構化查詢語言,DBMS使用SQL來管理DB。SQL是高階語言,計算機不能直接讀懂,因此SQL在執行前,內部會先編譯,這個編譯過程由DBMS完成。
四、表【table】
資料庫(資料夾)是不能直接存放資料的,需要有檔案來儲存,我們稱資料庫中的檔案為表。
什麼是表?看圖。在資料庫中,表和excel中設計的表基本一樣,是二維表格。【一個表對應一個檔案】
也就是說,表是資料庫的基本組成單元,其資料以表格形式組織起來,可讀性很強。
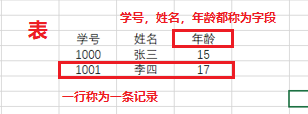
學習表,那麼我們就要學習欄位,以及對記錄的操作方法。
首先我們來看【欄位】。
每一個欄位包括哪些屬性呢?
欄位名、欄位型別、相關約束。
欄位名就不需要解釋了,根據我們的需要進行命名即可;
欄位型別的話,從上表可以看出,對於姓名,「張三」和「李四」可以看成是字串型別;對於年齡,「15」和「17」可以看成是整型。在資料庫中,字串型別用varchar表示(java中用String),整型用 int 表示(和java一樣)。
相關約束就是,給欄位加一些條件,該欄位對應的資料,必須滿足這些條件,資料才有效,否則會報錯。比如姓名的約束是 not null ,那麼當姓名為空的時候,就會報錯。
五、SQL語句的分類
在我們認識了DB、DBMS、表這三個概念之後,還有一個沒講,就是SQL。作為運算元據的語言,SQL自然是很重要的知識點。這裡,我們先看看它的分類。
對於其分類,先有個大概的認識。
DDL(Data Definition Language):資料庫定義語言。主要關鍵字:create drop alter,對錶的結構的增刪改
DML(Data Manipulation Language):資料庫操縱語言。主要關鍵字:insert delete update,對錶的資料的增刪改
DQL(Data Query Language)【最重點】:資料庫查詢語言。主要關鍵字:select,包含select的sql語句都是查詢語句。
DCL(Data Control Language):資料庫控制語言。主要關鍵字:grant授權、revoke復原許可權
TCL(Transaction Control Language):事務控制語言。主要關鍵字:commit提交事務,rollback回滾事務
這裡的關鍵字,先知道就行,後面學習就會了。不過,關於五個分類,DDL、DML、DQL、DCL、TCL以及它們的作用,還是要記憶一下先。
六、匯入初始化資料
學習完前面一些概念之後,我們先匯入一些資料,方便我們後面的練習。
匯入初始化資料,有以下幾個步驟:
1)開啟cmd視窗,登陸我們的MySQL
2)建立一個資料庫,來存放我們的練習資料(語句看不懂沒關係,先跟著敲)
create database if not exists bjpowernode;
使用資料庫
use bjpowernode;
3)匯入我們的資料:新建一個檔案,命名為 bjpowernode.sql ,開啟,將下面的程式碼複製貼上進去。然後回到我們的 cmd 視窗,輸入以下命令:source 路徑\bjpowernode.sql;(注意,這裡的「路徑」中不能有中文)。這樣,我們就把資料匯入bjpowernode這個資料庫中了。
【注意:下面的程式碼直接複製貼上就行,經過後面的學習,就能夠看懂了】
DROP TABLE IF EXISTS EMP;
DROP TABLE IF EXISTS DEPT;
DROP TABLE IF EXISTS SALGRADE;
CREATE TABLE DEPT
(DEPTNO INT(2) NOT NULL ,
DNAME VARCHAR(14) ,
LOC VARCHAR(13),
PRIMARY KEY (DEPTNO)
);
CREATE TABLE EMP
(EMPNO INT(4) NOT NULL ,
ENAME VARCHAR(10),
JOB VARCHAR(9),
MGR INT(4),
HIREDATE DATE DEFAULT NULL,
SAL DOUBLE(7,2),
COMM DOUBLE(7,2),
PRIMARY KEY (EMPNO),
DEPTNO INT(2)
)
;
CREATE TABLE SALGRADE
( GRADE INT,
LOSAL INT,
HISAL INT );
INSERT INTO DEPT ( DEPTNO, DNAME, LOC ) VALUES (
1, '財務部', '北京');
INSERT INTO DEPT ( DEPTNO, DNAME, LOC ) VALUES (
2, '研發部', '上海');
INSERT INTO DEPT ( DEPTNO, DNAME, LOC ) VALUES (
3, '銷售部', '深圳');
INSERT INTO DEPT ( DEPTNO, DNAME, LOC ) VALUES (
4, '管理層', '廣州');
COMMIT;
INSERT INTO EMP ( EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM,
DEPTNO ) VALUES (
1000, '張三', '文員', 1003, '1980-12-17'
, 800, NULL, 2);
INSERT INTO EMP ( EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM,
DEPTNO ) VALUES (
1001, '李四', '銷售員', 1005, '1981-02-20'
, 1600, 300, 3);
INSERT INTO EMP ( EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM,
DEPTNO ) VALUES (
1002, '王五', '銷售員', 1005, '1981-02-22'
, 1250, 500, 3);
INSERT INTO EMP ( EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM,
DEPTNO ) VALUES (
1003, '趙六', '經理', 1008, '1981-04-02'
, 2975, NULL, 2);
INSERT INTO EMP ( EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM,
DEPTNO ) VALUES (
1004, '劉備', '銷售員', 1005, '1981-09-28'
, 1250, 1400, 3);
INSERT INTO EMP ( EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM,
DEPTNO ) VALUES (
1005, '關羽', '經理', 1008, '1981-05-01'
, 2850, NULL, 3);
INSERT INTO EMP ( EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM,
DEPTNO ) VALUES (
1006, '張飛', '經理', 1008, '1981-06-09'
, 2450, NULL, 1);
INSERT INTO EMP ( EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM,
DEPTNO ) VALUES (
1007, '皮卡丘', '研發人員', 1003, '1987-04-19'
, 3000, NULL, 2);
INSERT INTO EMP ( EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM,
DEPTNO ) VALUES (
1008, '小火龍', '董事長', NULL, '1981-11-17'
, 5000, NULL, 4);
INSERT INTO EMP ( EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM,
DEPTNO ) VALUES (
1009, '妙蛙草', '銷售員', 1005, '1981-09-08'
, 1500, 0, 3);
INSERT INTO EMP ( EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM,
DEPTNO ) VALUES (
1010, '傑尼龜', '文員', 1006, '1987-05-23'
, 1100, NULL, 2);
INSERT INTO EMP ( EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM,
DEPTNO ) VALUES (
1011, '鋼鐵俠', '文員', 1005, '1981-12-03'
, 950, NULL, 3);
INSERT INTO EMP ( EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM,
DEPTNO ) VALUES (
1012, '蜘蛛俠', '研發人員', 1003, '1981-12-03'
, 3000, NULL, 2);
INSERT INTO EMP ( EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM,
DEPTNO ) VALUES (
1013, '永強', '文員', 1006, '1982-01-23'
, 1300, NULL, 1);
COMMIT;
INSERT INTO SALGRADE ( GRADE, LOSAL, HISAL ) VALUES (
1, 700, 1200);
INSERT INTO SALGRADE ( GRADE, LOSAL, HISAL ) VALUES (
2, 1201, 1400);
INSERT INTO SALGRADE ( GRADE, LOSAL, HISAL ) VALUES (
3, 1401, 2000);
INSERT INTO SALGRADE ( GRADE, LOSAL, HISAL ) VALUES (
4, 2001, 3000);
INSERT INTO SALGRADE ( GRADE, LOSAL, HISAL ) VALUES (
5, 3001, 9999);
COMMIT;
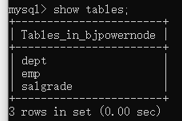
4)輸入 show tables; 發現我們的bjpowernode這個資料庫中多了幾個表
【關於bjpowernode.sql這個檔案】
在上面的操作中,我們已經向資料庫匯入了資料,且是通過bjpowernode.sql這個檔案進行匯入的。
那麼,什麼是sql指令碼呢?
(以sql結尾的檔案,我稱為「sql指令碼」。這種檔案中,編寫了大量的sql語句,通過source命令執行sql指令碼,就是將這個指令碼中的sql語句一一執行。)
七、檢視表結構以及表中的資料
在操作表中的資料之前,先查一下表的結構,是有必要的。
我們先看看,bjpowernode這個資料庫中,有哪些表
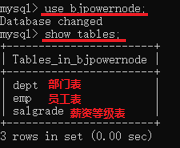
檢視dept表的表結構
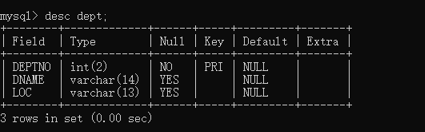
這裡我先介紹一下,讓大家能看懂上面的表
Field是欄位名稱,Type是欄位型別,Null、Key、Default、Extra這些是欄位約束。
欄位型別中,int(2)、varvhar(14),後面的數位,表示寬度,但是,int和varchar二者的寬度,含義還不一樣。
對於int(2),不是說你的數位大小隻能是0~99,而是說,當你給欄位deptno新增UNSIGNED ZEROFILL這個約束
時,如果你的值是1,那麼會自動幫你補齊為 01。
對於varchar(14),是說在你的字串中,無論是字母還是符號還是中文,都不能超過14和字元,一旦超過14個,
就會報錯。
欄位約束中,null空約束,yes時表示該欄位可以為空,no時反之;key是主鍵約束;default是預設約束,也就是
對於該欄位的預設值,這些約束在後面會細講。
這裡,我們把各個表的欄位都介紹一下,順便了解一下各個欄位的含義,方便後面的理解和練習
dept表(部門表):deptno(部門編號)、dname(部門名稱)、loc(部門位置)
emp表(員工表):empno(員工編號)、ename(員工姓名)、job(工作崗位)、mgr(上級領導編號)、hiredate(入職日期)、sal(月薪)、comm(津貼)、deptno(部門編號)
salgrade表(薪資等級表):grade(等級)、losal(最低薪資)、hisal(最高薪資)
接下來,查一下我們的表都有哪些資料,命令複製貼上就行,後面會學
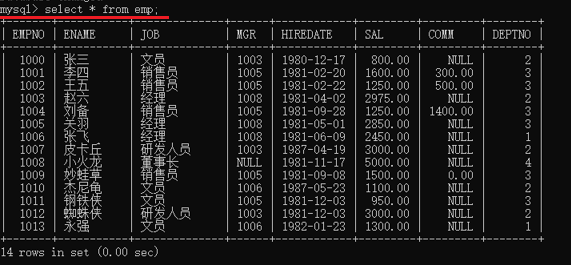
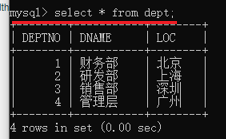
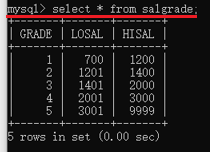
八、MySQL的常用命令
MySQL中有一些常用的命令,但是不難,一下子就記住了
select database(); -- 檢視當前正在使用的資料庫
select version(); -- 檢視當前MySQL的版本
show create table emp; -- 檢視emp這個表的建立語句
show create table emp; 這句執行之後,效果如下:
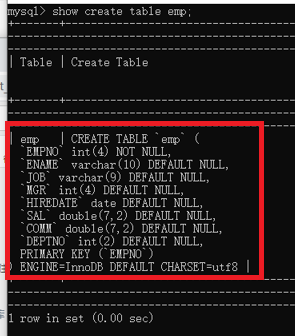
畫紅框的部分,就是我們建立emp這個表的時候,所需要的sql語句
九、查詢簡介及簡單查詢
在開始學習查詢之前,我們先了解查詢順序,你可以看不懂,但是在後面學習完它們的含義之後,這個執行順序你要記得住:
【from、join、on、where、group by、having、select、distinct、order by、limit】
【我的記憶方法】從加上哪組,有選重排限(英語直譯取第一個漢字)。十個字,沒什麼邏輯,但是記住之後,寫sql查詢語句相當簡單,你不用每一次都跑回來,看看這些執行順序,方法很蠢但有用!
在前面的sql分類中,我們學到過一種,叫做DQL,這就是查詢語句。其語法格式很簡單,如下:【這是最簡單的查詢方式,後面會越來越難,先記住這個格式】
select 欄位名1,欄位名2,欄位名3... from 表名
大家可以嘗試一下下面的程式碼,根據我的解釋和你實際看到的結果,就很容易理解
select * from emp; -- 查詢所有的員工記錄
select ename,sal from emp; -- 查詢員工姓名即對應的薪資
select ename,sal*2 from emp; -- 在第二句的基礎上,查出的結果是原薪資的兩倍
select ename 員工姓名,sal*2 薪資 from emp; -- 在第三局的基礎上,給欄位起別名
有幾個注意點,新手比較容易錯
1)sql語句是不區分大小寫的
2)語句要以 ; 結尾
3)字串是用單引號 ’ ’ 括起來的
十、條件查詢
什麼是條件查詢?
我們在簡單查詢之後,有一些資料是我們想要的,有些是我們不想要的,那麼我們就需要給查詢語句加一些條件進行篩選,這就是條件查詢。
條件查詢的語法格式如下:
select
欄位...
from
表
where
條件;
既然是條件,那麼我們當然需要一些運運算元,比如滿足 A=B 這個條件時,就把記錄查出來, ‘=’ 就是一個運運算元。常見的運運算元如下:
| 運運算元 | 說明 |
|---|---|
| = ,!=,>,<,>=,<= | 等於,不等於,大於,小於,大於或等於,小於或等於 |
| between…and… | 兩個值之間 |
| is null | 某個欄位對應的資料為空 |
| and | 並且 |
| or | 或者 |
| in | 包含,注意 num in (2,4) 表示的不是將 num 在 2 到 4 這個範圍內的記錄查出來,而是說 num=2 或者 num=4 時將記錄查出來 |
| not | 非,常和 is 、 in 連用,即 is not null(不為空)、not in(不在) |
| like | 有 like 的查詢語句稱為模糊查詢 |
這裡舉幾個例子,還是老規矩,大家執行sql語句,看看效果,很容易懂的
select * from emp;
select * from emp where empno = 1000; -- 這裡可以看到,只查詢了 empno = 1000 時這條記錄
select * from emp where sal > 1000;
select * from emp where sal between 1000 and 2000; -- 將薪資在1000到2000範圍內的記錄查出來
select * from emp where mgr is null; -- 結果是將董事長查出來了,因為懂事長已經是最高職位,沒有上司,為null
select * from emp where empno = 1000 and empno = 1001;
select * from emp where empno in (1000,1001,1002);
重點講一下模糊查詢,模糊查詢一般是根據字串來對記錄進行篩選。其支援兩個符號,下劃線 _ 和百分號 % 。下劃線表示必須是某個字元且不能為空,% 表示任意多個字元且能為空。
sql語句如下:
select * from emp where job like "%售%"; -- 顯然,可以將所有銷售員查詢出來
select * from emp where job like "_售_"; -- 查詢結果和上一句一樣,因為 % 雖然能表示任意多個字元,但是 銷售員 只有三個字,% 只指代了一個字元
select * from emp where ename like '%張%'; -- 查出兩條記錄,因為 % 能表示空
select * from emp where ename like '_張%'; -- 查出0條記錄,因為 _ 必須是具體的字元,不能為空
關於上面的幾個運運算元,還有一些注意點:
1)between…and…,是左閉右閉,及表示範圍的這兩個數也是包括在內的
2)null 不是一個值,要用 is null 或者 is not null 判斷,不能使用等號。比如 where mrg = null 來查詢董事長,是錯誤的。
3)and 的優先順序大於 or,所以當 and 和 or 同時出現時,最好加上括號區分優先順序
4)模糊查詢中_ 和 % 既然有特定的含義,那如果我確實需要 _ 這個符號來查詢呢?答案是在 _ 前面加一個 \,這一點和 java 中是一樣的。
十一、排序查詢
我們都知道,在我們每一次考完試之後,老師都會根據分數對班裡的人進行排序。因為不排序的話,對於雜亂無章的成績,很難看出誰是第一,誰是第二等等。
在 mysql 中,我們也可以將查詢到的結果進行排序,讓查詢結果更加清晰。
執行以下 sql 語句:
select ename,sal from emp order by sal asc; -- 根據薪資降序查詢
select ename,sal from emp order by sal desc; -- 根據薪資升序查詢
回到生活中,當老師發現小明和小紅的語文成績都是90,語數英三科總分也相等,那麼怎麼排序呢,老師一般會再次比較數學的成績,進行排序。
select ename,sal from emp order by sal asc,comm asc; -- 如果兩個人的薪資相等,那麼久根據津貼comm進行排序
【練習題】找出所有銷售員,並根據薪資降序排序
select * from emp where job = '銷售員' order by sal desc;
十二、分組查詢
在一個班級裡,我們不是所有人都擠在一起,老師一般都會為我們分組,考試後通過比較各組的平均分,來判斷哪一組成績比較差,才能更有針對性地對該組進行輔導。
同樣的,我們對於一個表,我們可以用 group by 將表分成多個組,然後比較各個組的平均值等。比如,在 emp 員工表中,我們可以根據不同的崗位,對員工進行分組,然後根據薪資的平均值,瞭解各個崗位的薪資情況。
在瞭解分組查詢之前,我們先了解一下分組函數。
分組函數:sum()、max()、min()、avg()、count()。分組函數又稱為多行處理常式,這是因為它是對多行資料進行操作。還有一種單行處理常式,都會進行介紹。
select sum(sal) from emp; -- 查出薪資的總值
select max(sal) from emp; -- 查出薪資的最大值
select min(sal) from emp; -- 查出薪資的最小值
select avg(sal) from emp; -- 查出薪資的平均值
select count(*) from emp; -- 查出總記錄數(14條)
SELECT COUNT(sal) FROM emp; -- 查出14條記錄
SELECT COUNT(comm) FROM emp; -- 查出4條記錄
對上述sql的總結:
1)對於上述五種分組函數,我們發現,查詢結果都是單行。這是因為,我們還沒有對錶 emp 進行分組。下面學習完分組,就有多行了。
2)對於 count() 這個分組函數,count() 是用來統計記錄條數的,* 表示所有的記錄條數,如果是欄位,則統計其非空的情況下的記錄條數。如 count(sal) 查出了14條記錄,但 count(comm) 查出的只有4條,這是因為,comm這個欄位只有4條記錄中有資料,其他的都為null。
學習完多行處理常式之後,我們再來看一下單行處理常式。較為常用的是:
我們來執行以下的sql:
-- 假設我們要查出員工表中,員工名以及他們的年薪((每月薪資+每月津貼)*12)
select ename,(sal+comm)*12 年薪 from emp; -- 查出來發現,年薪有的人變成了null。
這是因為,在單行中,有員工是沒有津貼的,及津貼是null,所以 sal+null 的結果還是null。【我們可以用單行處理常式 ifnull() 來解決。】sql語句如下:
select ename,(sal+ifnull(comm,0))*12 年薪 from emp;
單行處理常式 ifnull() 的格式是,ifnull(欄位,數值),ifnull(comm,0) 對應的意思就是,如果津貼是 null 的話,就把它轉換成數位 0 來和 sal 做相加運算。
好了,接下來學習一下分組排序吧。
【由於分組函數經常與group by(分組)連用,因此被稱為分組函數】
select job,avg(sal) from emp group by job; -- 根據職業進行分組,並查出各個職業的平均薪資。
就是這麼簡單,經過上面的sql語句,我們將表通過崗位進行了分組,並且通過分組函數求出了各個崗位對應的平均薪資。
此時,在查出各個崗位的平均薪資的時候,如果我們再加一個條件,需要查出平均薪資大於2999的崗位。顯然,大於2999,需要進行條件查詢,那麼我們試一下下面的sql語句
select job,avg(sal) from emp group by job where avg(sal) > 2999;
發現報錯了!這是什麼原因呢?回顧我們在開始學查詢時,我讓大家記住一個查詢順序。【from、join、on、where、group by、having、select、distinct、order、limit】,顯然,group by 是在where後面的,而分組函數 avg(sal) 又是在group by 後面執行的,也就是說,由於where是在分組函數之前執行,因此 where avg(sal) > 2999 是錯誤的,說白了,就是你 avg(sal) 都還不存在,那怎麼執行where。就是這個道理。
小總結:這裡很重要,分組函數不能寫在 where 後面,這是錯誤的!
為此,我們引入了【另一個關鍵字 having ,其作用和 where 相同】,都是條件查詢。不同點就是 where 在 group by 之前執行,而 having 在 group by 之後執行,也就是分組之後,通過 having 對資料進行再次過濾。
-- 查出平均薪資大於2999的崗位
select job,avg(sal) from emp group by job having avg(sal) > 2999;
【練習題】找出薪資高於平均薪資的所有員工
select ename,sal from emp where sal > avg(sal);
前面已經說到,由於各關鍵字的查詢順序,where 和 avg() 這些分組函數不能連用,那該怎麼解決這道練習題呢?我們用到【子查詢】。
【這裡先做個伏筆,子查詢後面會學習。這道題只是再次提醒你,where 和 分組函數不能連用】
-- 分兩步查詢
select avg(sal) from emp; -- 查出所有員工的平均薪資
select ename,sal from emp where sal > 2073.214286; -- 根據上條sql的查詢結果,找出薪資高於平均薪資的員工
-- 一步查詢
select ename,sal from emp where sal > (select avg(sal) from emp); -- 這個就是子查詢。後面會學。
關於分組查詢另外三個知識點:
1) 多欄位問題
我們來看看這個sql語句
select ename,job,avg(sal) from emp group by job;
這個sql語句執行錯誤,你想想,我們要的是根據崗位進行分組,並顯示崗位對應的平均工資,和單個員工ename有啥關係,你寫個ename在這裡,mysql究竟該顯示誰?顯然是不合理的。
有個規定:【當一條語句中有group by的話,select後面只能跟分組函數和參與分組的欄位】
2) 多次分組
在前面的學習中,我們知道 order by 可以在後面加兩個欄位,在第一個欄位相等時,再根據第二個欄位進行排序。
類似的,如果我們要求:找出每個部門不同工作崗位的最高薪資。顯然,我們需要線根據部門分組一次,再根據崗位再分組一次。
select deptno,job,max(sal) from emp group by deptno,job;
3) having和where的選擇
首先,在某些情況下,having 和 where 都是可以使用的。
【練習題】找出最高薪資大於2900的部門
select deptno,max(sal) from emp group by deptno having max(sal) > 2900;
select deptno,max(sal) from emp where sal > 2900 group by deptno;
以上兩種方式查出來的結果是一樣的。但是having的效率比where低,原因:第二個sql語句中,先將薪資小於2900的員工過濾掉,這樣參與分組的員工就少了,效率就高了。
十三、去重查詢
我們先執行一下下面的sql語句
select deptno from emp;
我們發現,資料冗餘的太多了,很多都是重複的。那麼我們該怎麼去掉這些重複的內容呢?很簡單
select distinct deptno from emp;
如上,只需要在欄位前面加上 distinct 即可。
我們這種情況只有一個欄位,那麼多個欄位時,會是怎樣呢?
select distinct deptno,job from emp;
和我們想的不一樣,它並不是只對 deptno 這個欄位起效果。而是對 deptno、job 這兩個欄位同時起效果,它要求 deptno 和 job 兩個欄位對應的值不能夠同時重複。
【練習題】統計崗位的數量
select count(distinct job) from emp;
十四、連線查詢【重點】
關於連線查詢,我已經寫過一篇很詳細的部落格了,快車直達:https://blog.csdn.net/weixin_43724203/article/details/108678299
【練習題】找出每一個員工的部門名稱以及工資等級
select
e.ename,d.dname,s.grade
from
emp e
join
dept d
on
e.deptno = d.deptno
join
salgrade s
on
e.sal between s.losal and s.hisal;
【練習題】找出每一個員工的部門名稱、工資等級、以及上級領導
SELECT
e1.ename '員工',d.dname,s.grade,e2.ename '領導'
FROM
emp e1
LEFT JOIN
emp e2
ON
e1.mgr = e2.empno
JOIN
dept d
ON
e1.deptno = d.deptno
JOIN
salgrade s
ON
e1.sal BETWEEN s.losal AND s.hisal;
十五、子查詢
首先我們要知道,什麼是子查詢?
select語句A中,可以巢狀另一個select語句B,則select語句B稱為子查詢。
子查詢可以出現在什麼地方?
select
...(select)
from
...(select)
where
...(select);
舉例
在where中使用子查詢:找出高於平均薪資的員工資訊
select * from emp where sal > (select avg(sal) from emp);
在from後面巢狀子查詢:找出每個部門平均薪資的薪資等級
SELECT deptno,AVG(sal) FROM emp GROUP BY deptno; -- 先查出每個部門的平均薪資,將結果作為一個表,和salgrade表連線
select
t.*,s.grade
from
(SELECT deptno,AVG(sal) as avgsal FROM emp GROUP BY deptno) t
join
salgrade s
on
t.avgsal between s.losal and s,hisal;
在select後面巢狀子查詢:找出每個員工所在的部門名稱,要求顯示員工名和部門名
select
e.ename,(select d.dname from dept d where e.deptno = d.deptno) as dname
from
emp e;
十六、聯表查詢
所謂聯表查詢,就是使用 union 關鍵字,將查詢結果集相加。這個過程中,會自動將重複的記錄刪除。
比如,我們要找出工作崗位是 銷售員 和 經理 的員工。
-- 方式一
select ename,job from emp where job in ('銷售員','經理');
--方式二
select ename,job from emp where job = '銷售員'
union
select ename,job from emp where job = '經理';
【注意】:
聯表查詢和連線查詢都是多表查詢,聯表查詢是縱向查詢,連線查詢是橫向查詢,如何理解呢?
縱向查詢,先查出崗位為銷售員的所有員工作為表 A ,再查出崗位為經理的所有員工作為表 B ,union 是將 B 從 A 的下方拼湊上去,合成更多條記錄,因此稱為縱向查詢。
橫向查詢,從上面的學習中我們知道,當我們所需要的欄位在不同的表上時,我們就要連線多個表,然後將各個欄位拼湊起來,當然,是左右關係的拼湊,因此稱為橫向查詢。
十七、分頁查詢
limit 分頁查詢(是非常重要的知識點,不難,但是很重要!)
在實際查詢中,我們查詢到的資料可能會很多很多,我們不可能一次性全部查出來,顯示在我們的瀏覽器上。比如,我們百度一下某個問題,假設沒有分頁的話,那我們要下拉時,不知道要拉多久才能到底。

limit 語法格式:limit startIndex,length。
startIndex是起始位置,從0開始,0是第一條記錄。
length表示查多少條記錄作為一頁。
再次回到我們的查詢順序,可以看到,limit是最後處理的一個關鍵字。
sql語句如下:
select * from emp limit 0,5;
select * from emp limit 5,5;
現在,我們來總結一下一個規律:
第一頁:0,3
第二頁:3,3
第三頁:6,3
第四頁:9,3
後面的 3 是不變的,不信你百度一下後,去數一數一頁有多少條記錄,都是固定的。前面的記錄下標就一直變化,規律是:【(頁碼-1)x 每頁條數 】
寫成java程式碼
int pageNo = 1; //頁碼
int pageSize = 10; //每頁多少條記錄
limit (pageNo-1)*pageSize,pageSize
十八、表的建立
在前面的學習中,我們一直使用的資料,是通過 sql 指令碼匯入的,我們發現,我們都會查詢語句了,但是我們自己還不會建立表。現在,就來學習學習吧。
建立表的格式如下:
create table 表名{
欄位1 資料型別 約束,
欄位2 資料型別 約束,
....
};
先看看資料型別吧:資料型別有整型、浮點型、日期型、字串型,常見的有如下
整型
| 型別 | 位元組 | 最小值 | 最大值 |
|---|---|---|---|
| tinyint | 1 | -128 | 127 |
| -128 | 127 | ||
| smallint | 2 | -32768 | 32767 |
| 0 | 65535 | ||
| mediumint | 3 | -8388608 | 8388607 |
| 0 | 16777215 | ||
| int | 4 | -2147483648 | 2147483647 |
| 0 | 4294967295 | ||
| bigint | 8 | -9223372036854775808 | 92233720368547758087 |
| 0 | 18446744073709551615 |
浮點型
| 型別 | 位元組 | 最小值 | 最大值 |
|---|---|---|---|
| float | 4 | 1.4x10^(-45) | 3.4x10^38 |
| double | 8 | 4.9x10^(-324) | 1.7x10^308 |
日期型
| 型別 | 說明 | 標準格式 | 位元組 |
|---|---|---|---|
| date | 日期 | YYYY-MM-DD | 3 |
| time | 時間 | HH:MM:SS | 3 |
| datetime | 日期時間 | YYYY-MM-DD HH:MM:SS | 8 |
| timestamp | 時間戳,從1970年1月1日0時起到現在的毫秒數 | 4 | |
| year | 年份 | YYYY | 1 |
字串型
| 型別 | 說明 | 範圍 |
|---|---|---|
| char | 定長度字串 | char(M),0<=M<=255,也就是最多255個字元。對於char(3),如果你儲存 ‘abcde’,就會報錯。 |
| varchar | 變長度字串 | varchar(M),0<=M<=65535(約2W-6W個字元,受字元集影響) |
| text | 文字串 | 約2W-6W個字元,受字元集影響 |
【思考】char和varchar怎麼選擇?
char分配的長度是固定長度,會直接分配空間,不需要和varchar一樣先判斷字串長度,因此char的效率比varchar高。在實際的開發中,一些不需要很多字元、且長度固定的欄位,就選用char,比如性別等;一些長度不固定的欄位,就選用varchar,比如簡介等。
現在,我們開始建表吧。
注意:表名以 t_ 或者 tbl_ 開頭。你就會問了,我們除了建立表,還能建立其他的嗎?為什麼要加 t_ 或 tbl_ 來區分?有的,後面還會學索引、檢視。
【練習題】建立一個 t_student表,要求如下
學生資訊包括:學號、姓名、性別、班級編號、生日
學號:bigint
姓名:varchar
性別:char
班級編號:int
生日:char
create table t_student(
no bigint,
name varchar(255),
sex char(1),
classno int,
birth char(10)
);
執行以上sql,我們的 t_student 表就建立好了
建立表之後,我們如果要刪除表,可執行以下sql
drop table if exists t_student;
【表的複製】:表的複製,是將一個查詢結果,作為一張新表,sql語句如下
create table emp1 as select ename from emp; -- 將emp的查詢結果作為新表emp1
select * from emp1; -- 檢查我們的emp1表是否建立成功
show create table emp1; -- 檢視emp1的建立過程,發現和手動建立的沒啥區別
十九、插入資料
在前面的學習中,我們發現,從九到十七,都是在將查詢語句,可見查詢的重要性。
現在,我們來學插入語句。
插入語句非常簡單,語法格式如下:
insert into 表名(欄位1,欄位2…) values(值1,值2…);
插入語句有兩種形式,一種是分開插入,一種是一次性插入多個記錄。
-- 方式一
insert into t_student(no,name,sex,classno,birth) values(1,'張三','男',1000,'7月1日');
insert into t_student(no,name,sex,classno,birth) values(2,'李四','男',1001,'7月20日');
-- 方式二
insert into t_student(no,name,sex,classno,birth) values(1,'張三','男',1000,'7月1日'),(2,'李四','男',1001,'7月20日');
【注意】:
1)前面的欄位必須和後面的值匹配得上。
如果有的欄位沒寫出來,則會自動視為null,如下
insert into t_student(name) values('王五');
2)前面的欄位可以不寫,但這就要求後面的值要寫全
insert into t_student values(4,'趙六','男',1003,'9月9日');
【插入批次記錄】:和表的複製類似,其實我們也可以將一個查詢結果,插入到表中,sql語句如下:
create table emp2 as select ename from emp where ename = '張三';
select * from emp2;
insert into emp2 select ename from emp where ename != '張三';
select * from emp2;
-- 當然,這要求查詢結果和原來表的列數是一樣的
二十、修改資料
學習完插入資料後,我們再來學修改資料,修改資料也很簡單。
語法格式:update 表名 set 欄位名1=值1,欄位名2=值2… where 條件;
注意:如果沒有條件的話,整張表的對應欄位都會更新
【練習題】將部門 1 的所在地址修改成蘭州,將部門名稱修改為人事部
UPDATE dept SET loc='蘭州',dname='人事部' WHERE deptno = 1;
二十一、刪除資料
刪除資料也一樣,很簡單
語法格式:delete from 表名 where 條件;
delete from dept where deptno = 1; -- 刪除編號為1的部門
如何刪除所有記錄?
delete from emp1; -- 刪除所有記錄
truncate table emp1; -- 刪除所有記錄,只剩下表頭
drop table if exists emp1; -- 整張表刪除
兩種刪除所有記錄有什麼不同?
delete效率很低,刪除所有記錄,沒有釋放其實體地址,其實體地址還在,也就是隻是在地址上將內容抹去。我們可以想象成,在一個用鉛筆在紙上填寫的表格中,用橡皮檫把內容擦去。這樣做的好處,是資料在刪除之後,後悔了,還能再回來。
truncate效率高,表被截斷,不可回滾,永久丟失。可以想象成紙上的表格,用剪刀將表頭以外的其他行都剪掉,我們就不能重新用鉛筆寫了。
二十二、修改表結構
修改表結構的sql語句其實有很多種,比如刪除欄位,修改欄位名,新增欄位等等。但是,我們不學!原因如下:
1)因為我們可以在 sqlyog、navicat等MySQL的視覺化工具中進行修改。
2)表一旦建立,就很少會出現修改表結構的情況(除非在前期設計表的時候),你想想看,假如一張表中已經有了幾千萬條記錄,此時你修改某個欄位,那這些記錄對應該欄位的值該怎麼辦,難道要全部修改嗎?
3)在java程式碼中,不會出現修改表結構的語句。出現在java程式碼中的,一般只有【CRUD】(Create增、Retrieve檢索、Update修改、Delete刪除,也就是我們在前面學的DML和DQL)操作。
二十三、約束
在前面剛剛接觸欄位的時候,我們就介紹了欄位的三個要素,欄位名,欄位型別,欄位約束。那麼,什麼是約束呢?
在建立表的時候,可以給表的欄位新增一些約束,新增約束的目的是為了保證資料的合法性、有效性等。
【常見約束】:
| 約束 | 說明 |
|---|---|
| not null | 非空約束。新增 not null 約束的欄位,其值不能是 null |
| unique | 唯一約束。新增 unique 約束的欄位,每條記錄對應該欄位的值不能重複 |
| primary key | 主鍵約束。是非空約束和唯一約束的結合,其值不能為 null 且不能重複。簡稱為 PK |
| foreign key | 外來鍵約束。和主鍵約束一樣,其值不能為 null 且不能重複,但是其還有另一種用處,後面會學。簡稱為FK |
| default | 預設值約束。可以設定欄位的預設值,如果在insert插入記錄時,其沒有設值,則使用預設值 |
現在,我們來單獨講講各個約束。
非空約束
create table t_temp(
name varchar(255) not null,
age int(11)
);
insert into t_temp(age) values(17); -- 報錯,因為name不能為 null ,而這個新增語句沒有給name賦值
drop table if exists t_temp;
唯一約束:注意,null 可以不唯一
create table t_temp(
name varchar(255) unique
);
insert into t_temp(name) values('張三'); -- 順利插入資料
insert into t_temp(name) values('張三'); -- 報錯,因為'張三'已經存在了,不滿足唯一性
drop table if exists t_temp;
-- 注意,如果是兩個寫在一起,則是聯合之後具有唯一性,如下
create table t_temp(
name varchar(255),
age int(11),
unique(name,age)
);
insert into t_temp(name,age) values('張三',15);
insert into t_temp(name,age) values('張三',16); -- 不會報錯
insert into t_temp(name,age) values('張三',15); -- 報錯
drop table if exists t_temp;
主鍵約束【重要】:
1)新增了主鍵約束的欄位稱為主鍵欄位,主鍵欄位其對應的主鍵值是這行記錄在整張表中的唯一標識,符合表的【設計三正規化】(後面講)。
2)主鍵約束和唯一約束一樣,也可採用複合形式,也就是多個欄位聯合起來作為主鍵。但是我們一般不這樣做,因為這樣做違背了【設計三正規化】。
3)一張表中,只能有一個欄位作為主鍵,且只能有一個主鍵。
先看看sql語句吧
create table t_temp(
id int,
name varchar(255),
primary key(id)
);
insert into t_temp(name) values('張三'); -- 報錯,因為 int 是主鍵,不能沒有值,不能為 null
insert into t_temp(id,name) values(1,'張三'); -- 不會報錯
insert into t_temp(id,name) values(1,'李四'); -- 報錯,因為主鍵具有唯一性
drop table if exists t_temp;
主鍵值的自增:我們的主鍵,為了滿足其非空和唯一兩個條件,我們一般會將其設定為自增。
create table t_temp(
id int primary key auto_increment, -- 從1開始,以1遞增
name varchar(255),
);
insert into t_temp(name) values('張三');
insert into t_temp(name) values('李四');
select * from t_temp; -- 發現 id 已經自動幫我們寫好了
drop table if exists t_temp;
【注意】:我們一般不會使用業務主鍵,而是採用自然主鍵。什麼意思呢?
我們的主鍵,必須要能代表一條記錄,且不能修改,且不能和其他的欄位有任何的關係,不要和業務掛鉤。假如我們用銀行卡號作為主鍵,當我們更換銀行卡時,我們讓銀行幫我們改卡號,完了,銀行說不能改,在底層銀行卡號是主鍵,主鍵不能修改,改了就可能和別人重複了。
所以我們採用自然主鍵,我們可以自定義一個欄位 id int,然後設 id 為主鍵。即主鍵最好是和業務無關的自然數。
外來鍵約束:
在學習外來鍵約束之前,讓我們先來看一下下面的sql語句和圖片:
【下面的程式碼直接複製就行了】
CREATE TABLE t_student(
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(255) NOT NULL,
classno INT NOT NULL,
classname VARCHAR(255) NOT NULL
);
INSERT INTO t_student(NAME,classno,classname) VALUES
('張三',100,'陽光小學北京路校區四年級(1)班'),
('李四',100,'陽光小學北京路校區四年級(1)班'),
('王五',100,'陽光小學北京路校區四年級(1)班'),
('趙六',101,'陽光小學北京路校區四年級(2)班'),
('孫七',101,'陽光小學北京路校區四年級(2)班');
SELECT * FROM t_student;
drop table if exists t_student;
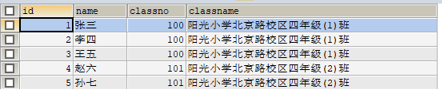
我們發現,在classname這個欄位中,重複的資料太多了。也許你不會覺得多,這是因為這裡只有幾個人,假設1班和2班,每一個同學的資訊就是一條記錄,那重複的,冗餘的就多了吧?如何解決呢?我們需要用到外來鍵約束。
我們將t_student這個表,分成兩個表,再用外來鍵將兩個表聯絡起來,就不會出現冗餘了。
【下面的程式碼直接複製就行了】
CREATE TABLE t_class(
cno INT,
cname VARCHAR(255),
PRIMARY KEY(cno)
);
CREATE TABLE t_student(
sno INT,
sname VARCHAR(255),
classno INT,
FOREIGN KEY(classno) REFERENCES t_class(cno) -- classno稱為外來鍵,關聯了t_class這個表的cno欄位
);
INSERT INTO t_class(cno,cname) VALUES
(100,'陽光小學北京路校區四年級(1)班'),(101,'陽光小學北京路校區四年級(2)班');
INSERT INTO t_student(sno,sname,classno) VALUES
(1,'張三',100),(2,'李四',100),(3,'王五',100),(4,'趙六',101),(5,'孫七',101);
SELECT * FROM t_class;
SELECT * FROM t_student;
INSERT INTO t_student(sno,sname,classno) VALUES(6,'周八',103); -- 報錯,因為classno是外來鍵,其值不能是t_class的cno欄位的值中所沒有的
【注意】:
1)外來鍵的值,可以是 null
2)外來鍵所關聯的表的欄位,其不一定需要時主鍵,但是要求其必須是唯一性。你想想,假設其不具有唯一性,那外來鍵關聯過去後,它就懵逼了,它不知道關聯哪個。
關於外來鍵約束,先學到這裡就好了。後面還會學。
在上面的sql語句中,在建立表時,我們發現,唯一約束和主鍵約束,有兩種寫法,一種是直接接在欄位後面,一種是在所有欄位都寫完之後,再寫約束。第一種其實稱為 列級約束,第二種稱為 表級約束。
二十四、儲存引擎(瞭解)
關於儲存引擎,這部分知識只是作為一個瞭解。如果想要深入瞭解的話,可以看看其他博主的部落格。不過我感覺,如果不是想成為DBA的話,其實也沒有必要去深入瞭解。
首先,我們要知道,什麼是儲存引擎?
就是表的儲存方式。比如一樣東西,我們把它放到箱子裡,我們可以橫著放,也可以豎著放,這就是儲存方式的不同。【注意儲存引擎是MySQL特有的,Oracle中也有類似的機制,但它只是叫做儲存方式,沒有和MySQL一樣,整一些花裡胡哨的名字。】
什麼時候使用儲存引擎?
其實是在建表的時候指定的。來看看我們之前對於dept表的建表sql語句
CREATE TABLE DEPT(
DEPTNO INT(2) NOT NULL ,
DNAME VARCHAR(14) ,
LOC VARCHAR(13),
PRIMARY KEY (DEPTNO)
);
其實我們這樣寫是,是不完整的,我們使用查詢建表語句來看一下,鍵入 show create table dept;
CREATE TABLE `dept` (
`DEPTNO` INT(2) NOT NULL,
`DNAME` VARCHAR(14) DEFAULT NULL,
`LOC` VARCHAR(13) DEFAULT NULL,
PRIMARY KEY (`DEPTNO`)
) ENGINE=INNODB DEFAULT CHARSET=utf8;
且不考慮欄位的約束問題,我們來對比一下,兩個建表語句有什麼不同:
1)首先是發現了 dept、deptno、dname 等識別符號,都加了飄號 ` ` ,可能在一些教學中,會要求我們給識別符號加上飄號,以和其他的關鍵字等進行區分,其實不加才更好。 因為這是MySQL特有的,放到Oracle中就崩了,假如你寫了上萬條sql語句,然後突然要求你使用Oracle這個DBMS,想想你要修改多久呀。
2)發現了後面一句 engine=innodb default charset=utf8; engine就是引擎的意思,charset是字元集的意思。我們建表的時候,沒有進行制定;但是在查建表語句的時候,卻給我們指定了innodb和utf8,說明innodb是預設的儲存引擎,utf8是預設的字元集。
MySQL中,儲存引擎有很多種,每一種都有自己的優缺點,需要根據需求進行選擇。
我們可以通過 SHOW ENGINES; 這個語句查詢MySQL所支援的儲存引擎。以下內容可以不看了,知道儲存引擎這個東西就行了。

【常見的儲存引擎:】(InnoDB和MyISAM這裡就不寫了,因為視訊講的真的垃圾,瞭解一個引擎,又牽扯出了一大堆新的概念,最好是有高品質的部落格幫助我們理解,所以你想深入瞭解儲存引擎,就去看其他的部落格吧)
MyISAM:
從上面的圖,Teacnsaction – NO 我們可以知道這個儲存引擎不支援事務(事務在下一部分學習)。
【糾錯】:在前面的學習中,我曾說表就是檔案,一張表就對應一個檔案,那是為了讓大家更容易理解。其實一張表,是可以對應多個檔案的。
當我們使用 MyISAM 儲存引擎建立表的時候,會生成3個檔案來對應該表。如下圖。
.frm(format)是格式檔案,儲存的是該表的表結構(欄位名、欄位型別、欄位約束這些)
.MYD(MyISAM data)是資料檔案,儲存表的資料(記錄)。
MYI(MyISAM Index)是索引檔案,儲存表的索引(索引相當於書本的目錄,有了目錄,我們可以很快找到我們想要看的內容。後面會學習。)。

二十五、事務【重要】
【事務是重中之重】
一、事務簡介
1)什麼是事務?
一個事務,就是一個完整的業務邏輯單元,不可再分。
說人話!比如我要在銀行進行轉賬,那我要經過哪些步驟呢?我把錢轉過去了,那我這邊的錢就變少了,到賬的使用者那邊的前就變多了,是不是就需要兩條update修改語句。
假如我不使用事務,我把錢轉過去,我這邊錢變少了,就在這變少的瞬間,系統崩了,那完了,到賬的那邊的錢還沒有增多,那我豈不是虧了很多錢?所以,我們需要使用事務,事務會將我們的多個sql語句繫結成為一個整體。只有確定了所有的sql語句都是正確的之後,才會提交給DBMS,讓它修改資料。如果一個sql語句出現了差錯,那麼這個事務不會被提交,所有的資料都不會發生變化。
2)事務有什麼用?
從(1)問中我們就能夠知道。事務是為了保證資料的完整性和安全性。
3)與事務相關的語句有哪些?
只有DML語句,即insert、delete、update這些會讓資料發生變化的語句。
4)關於事務這裡,我們要知道以下幾個單詞:
transaction:事務,commit:提交,rollback:回滾
舉個例子:假設一件事,需要經過insert、update、delete,然後才能完成。此時我們需要使用事務。
開啟事務。(開始)
執行insert。(不會修改資料庫的資料,會被記錄到快取中)
執行update。(不會修改資料庫的資料,會被記錄到快取中)
執行delete。(不會修改資料庫的資料,會被記錄到快取中)
提交事務或者回滾事務。(結束) 無論是提交事務還是回滾事務,都是事務結束的標誌。
提交事務:根據快取中的記錄,最終修改資料庫的資料,然後清空快取中的記錄。
回滾事務:不會修改資料庫的資料,直接清空快取中的記錄。
這是用中文表述的大概意思,接下來,我們來演示事務,用sql語句來演示,更加直觀。
二、演示事務
先建立好表
USE bjpowernode;
CREATE TABLE t_user(
id INT PRIMARY KEY AUTO_INCREMENT,
username VARCHAR(255)
);
insert into t_user(username) value('zhangsan');
在之前的學習中,當我們執行insert、delete、update這三種DML語句的時候,每執行一句,我們的表中資料就會改變一次。這是因為,MySQL它是預設自動提交事務的,也就是執行一句,就會直接修改資料庫的資料。
現在,我們來模擬一下事務的回滾,看下面的sql
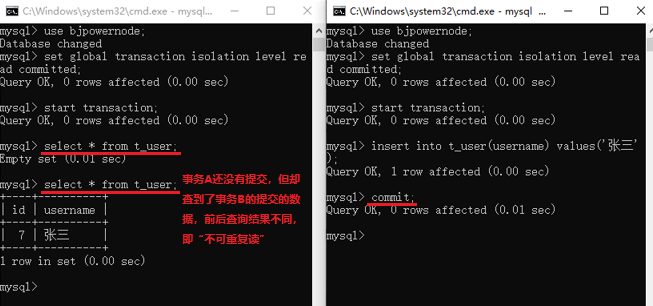
start transaction; -- 這裡開始,往下的所有sql,如果沒有出現回滾或者提交,都是事務的一部分
insert into t_user(username) value('lisi'); -- 插入一條記錄
update t_user set username = 'wangwu' where username = 'zhangsan';
select * from t_user; -- 查詢,發現lisi已經存在,且zhangsan被修改,我們看到的資料,現在只是存在快取
-- 中(或者說記憶體,我們關閉MySQL後重新開啟,是查不到這個資料的),事實上還沒有持久化(也就是存到硬碟中)。
rollback; -- 回滾
select * from t_user; -- 繼續查詢,記錄不見了。說明因為回滾,將記憶體中的執行記錄清空了。
然後我們模擬一下事務的提交,看下面的sql
start transaction;
insert into t_user(username) value('lisi');
update t_user set username = 'wangwu' where username = 'zhangsan';
select * from t_user;
commit; -- 回滾
select * from t_user; -- 繼續查詢,lisi存在,且zhangsan。說明資料已經存到硬碟中。即已經持久化。
總結:所以我們要使用事務,就是先start transaction,然後寫各種DML,最後commit或者rollback。
三、事務的四大特性 ACID
在對事務有一定的瞭解之後,我們來學習一下事務有哪些特性。
這四個,有時候會面試。
A:原子性:事務是最小的工作單元,不可再分。
C:一致性:事務必須保證多條DML語句同時成功或者同時失敗
I:隔離性:事務A和事務B之間有隔離,不能互相干擾
D:永續性:事務的最終資料必須持久化(儲存到硬碟)
四、事務的隔離性
事務的隔離性這個特性中,有一個概念,叫做隔離級別。我們會根據事務對安全性的要求,來選擇不同的隔離級別。就好像我們根據不同程度的颱風,政府部門會採取不同的應急措施一樣。
有的隔離級別中,存在一些不利於資料安全的現象,級別越低,現象越糟糕;但是,隔離級別越高,效率就會越低。所以對於隔離級別的選擇,只能到實際開發中去決定。【這個不要求初級java程式設計師會選擇】
隔離級別包含以下四種:讀未提交(第一級別),讀已提交(第二級別),可重複度(第三級別),序列化讀(第四級別)。每一種隔離級別都是為了解決上一級隔離級別中存在的不好現象。【注意:這四種隔離級別中的「讀」字,意思都是指查詢。】
在MySQL中,是第三級別起步;在Oracle中,是第二級別起步。也就是現在的DBMS中,基本上已經沒有第一級別起步的了。接下來,我們來詳細介紹一下這四個隔離級別。然後通過演示,來加深理解和印象。
讀未提交(read uncommited):這個隔離級別中,存在「髒讀」現象。「髒讀」就是事務A還沒有執行完,還沒有提交,其要存取或修改的資料就被事務B給讀到了,事務B讀到了「髒」的資料,所以稱為「髒讀」。
讀已提交(read commited):這個隔離級別中,解決了「髒讀」現象,存在「不可重複讀」現象。「不可重複讀」就是假設事務A還沒提交,事務B讀取資料 1 ,然後事務A提交,事務A的提交導致了資料 1 變成了 2,還沒完成提交的事務B再次讀取資料,發現兩次讀到的資料不一樣。第一次是 1,第二次是 2,也就是前後兩個資料不重複,所以稱為「不可重複讀」。
可重複讀(repeatable read):這個隔離級別中,解決了「不可重複讀」現象,存在「幻讀」現象。「幻讀」就是事務A還沒提交,事務B讀取初始資料 1,事務A提交後,修改了資料 1 使之變成了資料 2,此時事務B仍未提交,再次讀取資料,得到的結果是仍然是 1。硬碟中資料實際上已經被事務A修改成了 2,但是事務B讀到的仍然是 1,就像讀到了虛幻的資料一樣,所以稱為「幻讀」。
序列化讀(serializable):這個隔離級別中,解決了「幻讀」現象,存在效率低的現象。序列化讀就是讓事務A和事務B排隊執行,事務A沒有執行完,你事務B就不要執行。這就解決了前三個隔離級別的問題,但是由於事務排隊執行,因此效率極其低下。
以上就是四種隔離級別的介紹,怎樣,已經說的很通俗易懂了吧。現在,我們來演示一下各個隔離級別。
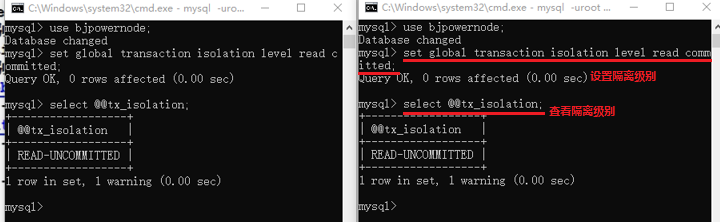
我們需要先開啟兩個DOS命令視窗,開啟MySQL,使用bjpowernode資料庫,修改隔離級別,然後檢視隔離級別確認一下,接著就可以開始我們的演示了。
修改隔離級別:set global transaction isolation level 隔離級別;
查詢隔離級別:select @@tx_isolation; 不同MySQL版本,有的是:select @@transaction_isolation;
具體如下圖:
讀未提交:

讀已提交:
可重複讀:
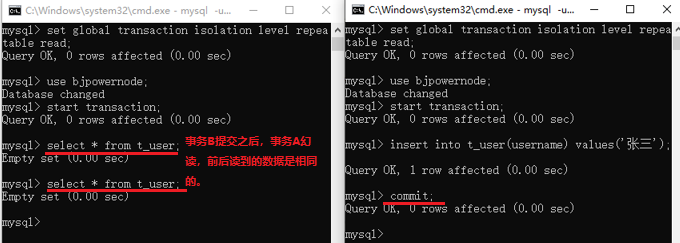
序列化讀:
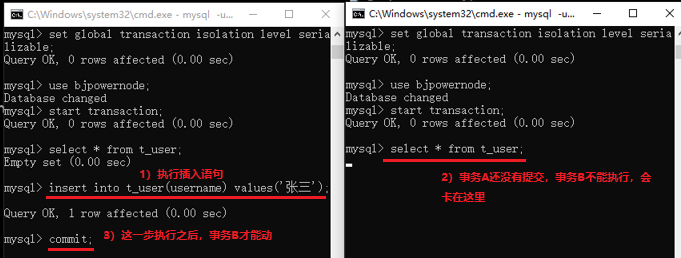
二十六、索引(瞭解)
在學習索引之前,我們通過幾個問題,自問自答,來了解索引
1)什麼是索引?
通俗地講,索引相當於書本的目錄,有了目錄我門就能很快定位到我們想要看的內容。如果沒有目錄,我們就只能從頭開始一頁一頁地翻書,知道找到我們想要的內容。
2)索引有什麼用?
超大地提高了檢索記錄(emmmm,檢索的意思自行百度)的效率。
3)為什麼有了索引檢索效率就會高?
因為索引縮小了掃描的範圍。我們想要查詢某條記錄,有兩種方式:1)全表掃描;2)根據索引在小範圍內掃描。
4)索引可以亂用嗎?
不可以,雖然加了索引之後檢索效率提高了,但是索引需要維護,成本高。就比如,《新華字典》改版之後,其中的漢字頁碼就會變,那前面目錄也要發生變化。同樣的,表中資料一旦修改,索引需要重新排序,進行維護。
5)什麼時候需要給欄位新增索引?
資料量大(一本書假如只有10頁,那還要什麼目錄);
該欄位很少有DML操作(也就是該欄位對應的資料不會經常發生改變)。
該欄位經常出現在where後面。(where後面是條件,經常出現在where後面說明是經常需要根據該欄位對應的值,來查詢到該值所在的記錄),看下面
新增索引是給某一個欄位,或者說某些欄位新增索引
select * from t_user where username = '張三';
當username欄位上沒有新增索引的時候,以上sql語句會進行全表掃描,掃描username欄位中所有的值。
當username欄位上新增索引的時候,以上sql語句會根據索引進行掃描,快速定位
【注意】:主鍵和unique約束自帶索引
6)瞭解了索引之後,我們該怎麼為我們的欄位建立索引呢?
建立索引:create index 索引名 on 表名(欄位名);
刪除索引:drop index 索引名 on 表名;
舉例:
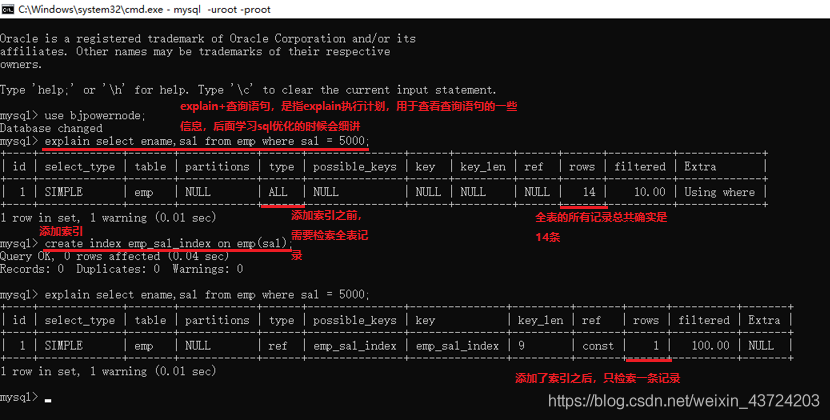
【索引的底層原理】:跳過吧,這個我也不會,如果有比較好的,能把底層原理講透,講通俗化的部落格,麻煩告知我一下,十分感謝。
二十七、檢視(瞭解)
檢視這一節的話,和前面索引的關係不大。索引是為了提高檢索效率,檢視則是為了資料的保密性。
1)什麼是檢視?
檢視就是將一個DQL語句的查詢結果作為一張「虛擬表」,可以通過這張虛擬表來 增刪改 原表的資料
2)怎麼建立檢視?怎麼刪除檢視?
建立檢視:create view 檢視名 as select 欄位名 from 表名;
刪除檢視:drop view 檢視名;
3)檢視有什麼作用?
你可能會疑惑,直接操作原表不可以嗎,為什麼還要建立一個檢視來修改?其實有些表的保密性是比較高的,假如一張表來儲存使用者資訊,其中包括了身份證、銀行卡號等重要資訊。當銀行需要某公司來接手維護他們的使用者管理系統時,為了這些使用者的隱私資訊不被洩漏,就建立檢視,把隱私資訊去除,留下一些不重要的資訊作為一張虛擬表就行。
4)演示檢視
-- 為了不修改emp表,我們先複製emp表
create table emp1 as select * from emp;
-- 根據emp1表來建立一個檢視
create view myview as select empno,ename,sal from emp1;
-- 通過檢視修改原表資料
delete from myview where empno = 1000;
二十八、資料庫的匯入匯出
在windows的dos命令視窗中執行:
將資料庫中的資料匯出:
mysqldump bjpowernode>E:\bjpowernode.sql -uroot -proot; -- 匯出整個資料庫
mysqldump bjpowernode emp>E:\bjpowernode.sql -uroot -proot; -- 匯出表
匯入資料:
source E:\bjpowernode.sql
mysqldump是匯出命令,bjpowernode是資料庫,> 表示匯出到哪個位置
二十九、設計三正規化
什麼是設計三正規化?
設計三正規化是一種規範,讓我們在設計表的時候,能夠避免資料的冗餘,減小空間開銷
第一規格化:任何一張表都應該有主鍵,並且每一個欄位原子性不可再分
第二正規化:在第一規格化基礎上,所有非主鍵的欄位完全依賴主鍵,不能產生部分依賴
第三正規化:在第二正規化基礎上,所有非主鍵欄位直接依賴主鍵,不能產生傳遞依賴
接下來,我們來了解各個正規化。
第一規格化:
我們來看下面這一張表,顯然不符合第一規格化.首先這張表沒有主鍵;其次,聯絡方式不具有原子性,因為還可以分為郵箱和手機號。

修改如下,即可滿足第一規格化

第二正規化:
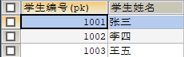
下面這張表,不滿足第二正規化。原因是主鍵是複合主鍵,即由學生編號和教師編號這兩個欄位構成一個主鍵,這就產生了部分依賴。
它們共同構成主鍵,但是學生姓名卻只依賴於學生編號,不依賴於教師編號;同樣的,教師姓名只依賴於教師編號,不依賴於學生編號。這就是部分依賴。

修改如下,即可滿足第二正規化。

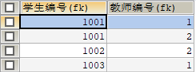
對於上面三個表,你可能會有點懵逼,你先記住一下口訣:
【多對多,三張表,關係表兩個外來鍵】:如何理解呢?為滿足第二正規化,我們將表拆成三個表,第三個表是關係表。多對多是指欄位的關係,多個學生對應多個老師,或者反過來說,多個老師對應多個學生也行。記住了這個口訣,我們以後在設計表的時候,就不需要多加思索。
第三正規化:
下面這張表,不滿足第三正規化。原因是存在傳遞依賴。班級名稱依賴於班級編號,而班級編號依賴於學生編號(因為班級編號屬於學生的一個資訊),這就是傳遞依賴。

修改如下,即可滿足第三正規化:
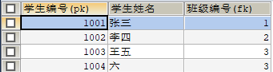

【一對多,兩張表,多的表加外來鍵】:同樣是一個口訣,一個班級對應多個學生,這就是一對多的關係,此時需要給多的表(學生表)加外來鍵,關聯到班級表。
以上就是三個正規化,很好理解,主要記住三正規化是為了減少資料冗餘。
另外,在實際開發中,我們不一定會使用三正規化來設計表,因為多表查詢存在笛卡爾積,查詢效率較慢,所以有時候
會通過犧牲空間(資料大量冗餘),來保證查詢效率高。
三十、作業題
在這些練習題中,每一道題都會有不同的解法。
(1)取得每個部門最高薪水的人
(2)哪些人的薪水在部門的平均薪水之上或等於平均薪水的
(3)取得部門中(所有人的)平均的薪水等級
(4)不準用分組函數(max),取得最高薪水
(5)取得平均薪水最高的部門的部門編號(兩種解決方案)
(6)取得平均薪水最高的部門的部門名稱
(7)求平均薪水的等級最低的部門的部門名稱
(8)取得比普通員工(員工程式碼沒有在mgr欄位上出現的)的最高薪水還要高領導人的姓名
(9)取得薪水最高的前五名員工
(10)取得薪水最高的第六到第十名員工
(11)取得最後入職的5名員工
(12)取得每個薪水等級有多少員工
(13)面試題
(14)列出所有員工及領導的姓名
(15)列出受僱日期早於其直接上級的所有員工的編號,姓名,部門名稱
(16)列出部門名稱和這些部門的員工資訊
(17)列出至少有 5 個員工的所有部門
(18)列出薪金比"張飛" 多的所有員工資訊
(19)列出所有 「銷售員」 的姓名及其部門名稱, 部門的人數
(20)列出最低薪金大於 1500 的各種工作及從事此工作的全部僱員人數
(21)列出在部門"銷售部"工作的員工的姓名, 假定不知道銷售部的部門編號
(22)列出薪金高於公司平均薪金的所有員工, 所在部門, 上級領導, 僱員的工資等級
(23)列出與"張三" 從事相同工作的所有員工及部門名稱
(24)列出薪金等於部門 30 中員工的薪金的其他員工的姓名和薪金
(25)列出薪金高於在部門 30 工作的所有員工的薪金的員工姓名和薪金. 部門名稱
(26)列出在每個部門工作的員工數量, 平均工資和平均服務期限
(27)列出所有員工的姓名、部門名稱和工資
(28)列出所有部門的詳細資訊和人數
(29)列出各種工作的最低工資及從事此工作的僱員姓名
(30)列出各個部門的領導的最低薪金
(31)列出所有員工的 年工資, 按 年薪從低到高排序
(32)求出員工領導的薪水超過3000的員工名稱與領導
(33)求出部門名稱中, 帶’財’字元的部門員工的工資合計、部門人數
(34)給任職日期超過 30 年的員工加薪 10%.
1)取得每個部門最高薪水的人
我們先查出部門及對應最高薪水,將其作為一張表,和emp表連線查詢
SELECT
e1.ename,t.*
FROM
emp e1
JOIN
(SELECT
d.dname,MAX(sal) maxsal
FROM
emp e2
JOIN
dept d
ON
e2.deptno = d.deptno
GROUP BY
e2.deptno) t
ON
e1.sal = t.maxsal;
2)哪些人的薪水在部門的平均薪水之上或等於平均薪水的
與題1類似,先將各部門的平均薪水查出來,作為一張表 t ,再和 emp 表連線
SELECT
e.ename,t.*,e.sal
FROM
emp e
JOIN
(SELECT
d.deptno,d.dname,AVG(e.sal) avgsal
FROM
emp e
JOIN
dept d
ON
e.deptno = d.deptno
GROUP BY
e.deptno) t
ON
e.sal >= t.avgsal AND e.deptno = t.deptno;
3)取得部門中(所有人的)平均的薪水等級
這道題如果你用了前兩道題類似的做法,先查出所有人的薪水等級,然後作為一張表,與dept表連線查詢的話,那你就中計了,和我一樣。我剛開始也是這麼寫的,如下:
SELECT
d.dname,AVG(t.grade) avggrade
FROM
dept d
JOIN
(SELECT
e.deptno,e.ename,s.grade
FROM
emp e
JOIN
salgrade s
ON
e.sal BETWEEN s.losal AND s.hisal) t
ON
d.deptno = t.deptno
GROUP BY
t.deptno;
這道題不需要這麼麻煩。
-- 大家先複製上面這一段,看看得到了什麼表
SELECT
e.deptno,AVG(s.grade)
FROM
emp e
JOIN
salgrade s
ON
e.sal BETWEEN s.losal AND s.hisal
GROUP BY
e.deptno;
-- 再連線dept就行
SELECT
d.dname,AVG(s.grade) avggrede
FROM
emp e
JOIN
salgrade s
ON
e.sal BETWEEN s.losal AND s.hisal
JOIN
dept d
ON
e.deptno = d.deptno
GROUP BY
e.deptno;
4)不準用分組函數(max),取得最高薪水
使用 limit 和 排序
select ename,sal 最高薪水 from emp order by sal desc limit 0,1;
5)取得平均薪水最高的部門的部門編號(兩種解決方案)
-- 方式一
SELECT deptno FROM emp GROUP BY deptno ORDER BY AVG(sal) DESC LIMIT 0,1;
-- 方式二
SELECT AVG(sal) avgsal FROM emp GROUP BY deptno; -- 第一步:查出各部門的平均工資
SELECT MAX(t.avgsal) FROM (SELECT AVG(sal) avgsal FROM emp GROUP BY deptno) t; -- 第二步:將第一步中的結果作為一張表,查出最大的那個平均值
SELECT deptno FROM emp GROUP BY deptno HAVING AVG(sal) = (SELECT MAX(t.avgsal) FROM
(SELECT AVG(sal) avgsal FROM emp GROUP BY deptno) t); -- 第三步:根據deptno分組查詢emp表,將工資
-- 平均值等於第二步中查出的最大平均值的那個部門編號查出來
6)取得平均薪水最高的部門的部門名稱
這道簡單,我們先 SELECT AVG(sal) FROM emp e GROUP BY e.deptno ORDER BY AVG(sal) DESC LIMIT 0,1; 得出最大的部門工資平均值,然後去連線 dept 表得到部門名稱,稍作修改即可。
注意這道題和第三題一樣,沒有必要將結果作為一張新表,直接連線dept表即可。
SELECT
d.dname
FROM
emp e
JOIN
dept d
ON
e.deptno = d.deptno
GROUP BY
e.deptno
ORDER BY
AVG(sal) DESC
LIMIT 0,1;
7)求平均薪水的等級最低的部門的部門名稱
這道太難,建議跳過
-- 先找出每個部門的平均薪水
select deptno,avg(sal) as avgsal from emp group by deptno;
-- 找出每個部門的平均薪水的等級 (1)
SELECT
t.*,s.grade
FROM
(SELECT e.deptno,AVG(sal) avgsal FROM emp e GROUP BY e.deptno) t
JOIN
salgrade s
ON
t.avgsal BETWEEN s.losal AND s.hisal;
-- 找出每個部門的平均薪水中的最低的等級 (2)
select grade from salgrade where (select avg(sal) as avgsal from emp group by deptno order by
avgsal asc limit 1) between losal and hisal;
-- (1) 和 (2) 聯立,再稍作修改
SELECT
t.dname,s.grade
FROM
(SELECT d.dname,e.deptno,AVG(sal) avgsal FROM emp e JOIN dept d ON e.deptno = d.deptno GROUP BY e.deptno) t
JOIN
salgrade s
ON
t.avgsal BETWEEN s.losal AND s.hisal
WHERE
grade = (SELECT grade FROM salgrade WHERE (SELECT AVG(sal) AS avgsal FROM emp GROUP BY deptno ORDER BY avgsal ASC LIMIT 1) BETWEEN losal AND hisal);
8)取得比普通員工(員工程式碼沒有在mgr欄位上出現的)的最高薪水還要高領導人的姓名
-- 第一步:找出不重複的mgr
select distinct mgr from emp;
-- 第二步:找出普通員工中的最高工資
-- 注意不重複的mgr多了個條件,is not null,這是因為如果 not in 後面的小括號中如果有null,
-- 那麼結果也會是null,大家可以去掉看看效果
SELECT MAX(sal) FROM emp WHERE empno NOT IN (SELECT DISTINCT mgr
FROM emp WHERE mgr IS NOT NULL);
-- 第三步:找出所有領導及對應工資
SELECT ename,sal FROM emp WHERE empno IN (SELECT DISTINCT mgr
FROM emp WHERE mgr IS NOT NULL);
-- 第四步:將第二步和第三步聯立
SELECT ename,sal FROM emp WHERE empno IN
(SELECT DISTINCT mgr FROM emp WHERE mgr IS NOT NULL)
HAVING sal > (SELECT MAX(sal) FROM emp WHERE empno NOT IN
(SELECT DISTINCT mgr FROM emp WHERE mgr IS NOT NULL));
9)取得薪水最高的前五名員工
這道,送分題
select ename,sal from emp order by sal desc limit 0,5;
10)取得薪水最高的第六到第十名員工
select enaem,sal from emp order by sal desc limit 5,5;
11)取得最後入職的5名員工
SELECT * FROM emp ORDER BY hiredate DESC LIMIT 0,5;
12)取得每個薪水等級有多少員工
-- 方法一
SELECT
t.grade,COUNT(t.grade)
FROM
(SELECT e.ename,s.grade FROM emp e JOIN salgrade s ON e.sal BETWEEN s.losal AND s.hisal) t
GROUP BY
t.grade;
-- 方法二
select
s.grade,count(*)
from
emp e
join
salgrade s
on
e.sal between s.losal and s.hisal
group by
s.grade;
13)面試題【這道題不做,等到jdbc中講】
有3個表s(學生表),c(課程表),sc(學生選課表)
s(sno,sname)代表(學號,姓名)
c(cno,cname,cteacher)代表(課號,課名,教師)
sc(sno,cno,scgrade)代表(學號,課號,成績)
問題:
1)找出沒選過「黎明」老師的所有學生姓名
2)列出2門以上(含2門)不及格學生姓名及平均成績
3)即學過1號課程又學過2號課程的所有學生的姓名
請用標準 SQL 語言寫出答案,方言也行(請說明是使用什麼方言)
14)列出所有員工及領導的姓名
這道題注意左連線就好了,因為懂事長是沒有領導的,需要左連線,否則會顯示不了董事長這條記錄。這一點在連線中都有講到。
SELECT
e1.ename AS 員工,e2.ename AS 領導
FROM
emp e1
LEFT JOIN
emp e2
ON
e1.mgr = e2.empno;
15)列出受僱日期早於其直接上級的所有員工的編號,姓名,部門名稱
SELECT
e1.ename 員工,e1.hiredate 員工入職日期,e2.ename 領導,e2.hiredate 領匯入職日期
FROM
emp e1
JOIN
dept d
ON
e1.deptno = d.deptno
LEFT JOIN
emp e2
ON
e1.mgr = e2.empno
WHERE
e1.hiredate < e2.hiredate;
16)列出部門名稱和這些部門的員工資訊
SELECT
d.dname,e.ename
FROM
dept d
JOIN
emp e
ON
d.deptno = e.deptno
ORDER BY
dname;
17)列出至少有 5 個員工的所有部門
SELECT
d.dname
FROM
dept d
JOIN
emp e
ON
d.deptno = e.deptno
GROUP BY
d.dname
HAVING
COUNT(*) >= 5;
18)列出薪金比"張飛" 多的所有員工資訊
SELECT
*
FROM
emp
WHERE
sal > (SELECT sal FROM emp WHERE ename = '張飛');
19)列出所有 「銷售員」 的姓名及其部門名稱, 部門的人數
由於我的資料和視訊有些不同,查詢結果不同。這道題如果以下的sql看不懂的話,建議看視訊:點我看視訊
SELECT
e.ename,e.job,d.dname,t.*
FROM
emp e
JOIN
dept d
ON
e.deptno = d.deptno
JOIN
(SELECT
COUNT(*) 銷售部人數
FROM
emp e
JOIN
dept d
ON
e.deptno = d.deptno
WHERE
d.dname = '銷售部') t
WHERE
e.job = '銷售員';
20)列出最低薪金大於 1500 的各種工作及從事此工作的全部僱員人數
SELECT
job,COUNT(*)
FROM
emp
GROUP BY
job
HAVING
MIN(sal) > 1500;
21)列出在部門"銷售部"工作的員工的姓名, 假定不知道銷售部的部門編號
SELECT ename FROM emp WHERE deptno = (SELECT deptno FROM dept WHERE dname = '銷售部');
22)列出薪金高於公司平均薪金的所有員工, 所在部門, 上級領導, 僱員的工資等級
這道題簡單,一步一步寫就好了。但是是一道好題,綜合性較強。
-- 公司平均薪金
SELECT AVG(sal) FROM emp
-- 高於平均薪金的所有員工
SELECT
e.ename
FROM
emp e
WHERE
e.sal > (SELECT AVG(sal) FROM emp);
--所在部門(內連線),上級領導(自連線+左連線),工資等級(內連線)。結果如下
SELECT
e1.ename,d.dname,e2.ename,s.grade
FROM
emp e1
JOIN
dept d
ON
e1.deptno = d.deptno
LEFT JOIN
emp e2
ON
e1.mgr = e2.empno
JOIN
salgrade s
ON
e1.sal BETWEEN s.losal AND s.hisal
WHERE
e1.sal > (SELECT AVG(sal) FROM emp);
23)列出與"張三" 從事相同工作的所有員工及部門名稱
SELECT
e.ename,d.dname
FROM
emp e
JOIN
dept d
ON
e.deptno = d.deptno
WHERE
job = (SELECT job FROM emp WHERE ename = '張三') and e.ename != '張三';
24)列出薪金等於部門 30 中員工的薪金的其他員工的姓名和薪金
這道題讀起來有點拗口,就是說。除部門3之外的員工,如果有薪金等於部門3中某個員工薪金的,就把他的姓名和薪金查出來。
SELECT
ename,sal
FROM
emp
WHERE
sal IN (SELECT DISTINCT sal FROM emp WHERE deptno = 3) AND deptno != 3;
25)列出薪金高於在部門 30 工作的所有員工的薪金的員工姓名和薪金. 部門名稱
SELECT
e.ename,e.sal
FROM
emp e
JOIN
dept d
ON
e.deptno = d.deptno
WHERE
sal > (SELECT MAX(sal) FROM emp WHERE deptno = 3);
26)列出在每個部門工作的員工數量, 平均工資和平均服務期限
這道題重點是掌握如何計算兩個日期的「年差」,差了多少年。
函數及格式:timestampdiff(間隔型別,前一個日期,後一個日期)
-- 前面這句不難,主要是掌握後面的平均服務期限。就是 當前日期-入職日期
SELECT
e.deptno,d.dname 部門,d.loc,COUNT(*) 員工數量,AVG(sal) 平均工資
FROM
emp e
JOIN
dept d
ON
e.deptno = d.deptno
GROUP BY
e.deptno;
-- 平均服務年限
select timestampdiff(year,hiredate,now()) 服務年限 from emp;
-- 接下來就簡單了
SELECT
e.deptno,d.dname 部門,d.loc,COUNT(*) 員工數量,AVG(sal) 平均工資,AVG(TIMESTAMPDIFF(YEAR,hiredate,NOW())) 平均服務年限
FROM
emp e
JOIN
dept d
ON
e.deptno = d.deptno
GROUP BY
e.deptno;
27)列出所有員工的姓名、部門名稱和工資
送分題
select
e.ename,d.dname,e.sal
from
emp e
join
dept d
on
e.deptno = d.deptno;
28)列出所有部門的詳細資訊和人數
SELECT
d.deptno,d.dname,d.loc,COUNT(e.ename)
FROM
dept d
JOIN
emp e
ON
d.deptno = e.deptno
GROUP BY
d.deptno;
29)列出各種工作的最低工資及從事此工作的僱員姓名
SELECT
e.ename,t.*
FROM
emp e
JOIN
(SELECT job,MIN(sal) minsal FROM emp GROUP BY job) t
ON
e.sal = t.minsal and e.job = t.job;
30)列出各個部門的領導的最低薪金
各個部門的領導。就把經理算進來就好了。理論上懂事長不屬於某個部門。
select
deptno,min(sal)
from
emp
where
job = '經理'
group by
deptno;
31)列出所有員工的 年工資, 按 年薪從低到高排序
年工資包括津貼,注意使用 ifnull() 函數
SELECT
ename,(sal+IFNULL(comm,0))*12 年薪
FROM
emp
ORDER BY
年薪 ASC;
32)求出員工領導的薪水超過3000的員工名稱與領導
SELECT
a.ename 員工,b.ename 領導
FROM
emp a
JOIN
emp b
ON
a.mgr = b.empno
WHERE
b.sal > 3000;
33)求出部門名稱中, 帶’財’字元的部門員工的工資合計、部門人數
模糊查詢 用like
SELECT
t.dname,SUM(sal),COUNT(*)
FROM
emp e
JOIN
(SELECT deptno,dname FROM dept WHERE dname LIKE '%財%') t
ON
e.deptno = t.deptno
GROUP BY
e.deptno;
34)給任職日期超過 30 年的員工加薪 10%.
UPDATE emp SET sal = sal*1.1 WHERE TIMESTAMPDIFF(YEAR,hiredate,NOW()) > 30;