Cache Line對資料讀寫效能的影響
對於一個程式來說,幾乎所有的計算任務都不可能僅通過CPU的計算就可以完成,它至少要和記憶體打交道:讀取運算資料、寫入運算結果。
現代CPU的算力已經十分強大,相比之下儲存裝置的IO讀寫速度卻發展的十分緩慢。通常情況下,記憶體每完成一次讀寫操作,CPU已經可以進行上百次的運算,為了填補兩者速度上的鴻溝,現代CPU不得不加入一層或多層讀寫速度接近於CPU處理速度的快取記憶體Cache。CPU會將計算需要的資料讀取到快取中,讓計算可以快速進行,當計算結束後,再將計算結果統一寫回到主記憶體中,這樣CPU就不需要緩慢的等待記憶體讀寫了。
多級快取-填補記憶體讀寫速度與CPU計算速度的鴻溝
筆者畫了一個簡圖,大概表示現代CPU的快取架構,如下:
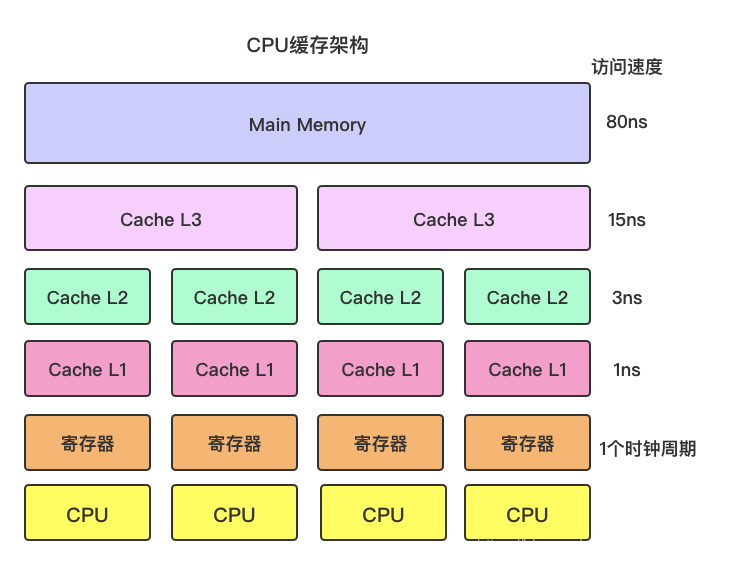
各級快取的讀寫速度如下:
| 快取 | 時鐘週期(大約) | 時間(大約) |
|---|---|---|
| 主記憶體 | - | 80ns |
| L3 | 40 | 15ns |
| L2 | 10 | 3ns |
| L1 | 3~4 | 1ns |
| 暫存器 | 1 | - |
越靠近CPU的快取讀寫速度越快,相應的 容量越小、且成本越高。
當CPU需要讀取資料時,首先從最近的快取開始找,找不到就逐層往上尋找,如果命中快取,就無需再從主記憶體中去讀取,直接拿來計算。反之從主記憶體中載入資料並依次寫入多級快取中,下次就可以直接從快取中讀資料了。
區域性性原理與Cache Line
CPU存取記憶體時,無論是存取指令還是存取資料,所存取的儲存單元都趨於聚集在一個較小的連續區域中。
- 當我們需要從記憶體中讀取一個int變數i的值時,CPU真的只會僅僅將這個4位元組的i載入到快取嗎?
答案是:NO!!!
當我們去讀取一個4位元組的int變數時,計算機認為程式接下來很大概率會存取相鄰的資料,於是會把相鄰的資料給一塊兒載入到快取中,下次再讀取時,就不用存取主記憶體了,直接從快取中讀取就可以了,減少了CPU存取主記憶體的次數,提高快取的命中率。
說白了,CPU讀取資料時,總是會一個塊一個塊的讀,哪怕你需要的僅僅是1個位元組的資料,這個【塊】就被稱為【Cache Line】。
不同的CPU,Cache Line大小是不一樣的,Intel的CPU大部分都是64位元組。
多級快取就是由若干個Cache Line組成的,CPU每次從主記憶體中拉取資料時,會把相鄰的資料也存入同一個Cache Line。
如下測試程式碼,各自讀取一千萬次資料,Cache Line失效的耗時11ms,能很好的利用Cache Line特性的只需要3ms。
public class CacheLine {
static int length = 8 * 10000000;
static long[] arr = new long[length];
public static void main(String[] args) {
long temp;// 無特殊含義,讀取出來的資料賦值
// 1.每次讀取都跳8個,下次讀取的資料一定不在上次讀取的Cache Line中,快取全部未命中
long start = System.currentTimeMillis();
for (int i = 0; i < length; i += 8) {
temp = arr[i];
}
long end = System.currentTimeMillis();
System.out.println(end - start);// 11ms
// 2.順序讀取,Cache Line生效,唯讀前8分之1的資料
start = System.currentTimeMillis();
for (int i = 0; i < length / 8; i++) {
temp = arr[i];
}
end = System.currentTimeMillis();
System.out.println(end - start);// 3ms
}
}
偽共用
當多個執行緒去同時讀寫共用變數時,由於快取一致性協定,只要Cache Line中任一資料失效,整個Cache Line就會被置為失效。這就會導致本來相互不影響的資料,由於被分配在同一個Cache Line中,雙方在寫資料時,導致對方的Cache Line不斷失效,無法利用Cache Line快取特性的現象就被稱為【偽共用】。
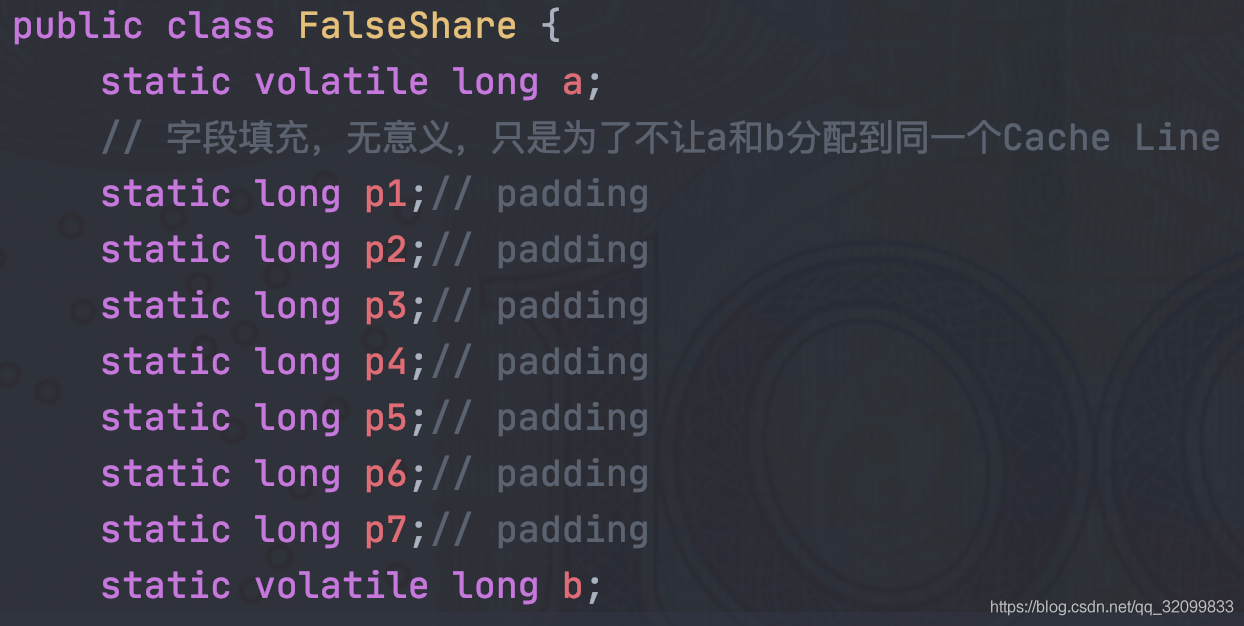
如下程式碼,啟動兩個執行緒,分別修改共用變數a和b,由於a個b一共佔用16位元組,可以被分配進同一個Cache Line中,本來互相不影響的兩個執行緒修改資料,但是由於a個b被分配到同一個Cache Line中,導致對方的Cache Line不斷失效,不斷的重新發起load指令重主記憶體中重新載入資料,降低程式的效能。
public class FalseShare {
static volatile long a;
static volatile long b;
public static void main(String[] args) throws InterruptedException {
CountDownLatch cdl = new CountDownLatch(2);
long t1 = System.currentTimeMillis();
new Thread(()->{
for (long i = 0; i < 1_0000_0000L; i++) {
// 執行緒只改a
FalseShare.a = i;
}
cdl.countDown();
}).start();
new Thread(()->{
for (long i = 0; i < 1_0000_0000L; i++) {
// 執行緒只改b
FalseShare.b = i;
}
cdl.countDown();
}).start();
cdl.await();
long t2 = System.currentTimeMillis();
System.err.println(t2 - t1);
}
}
程式執行結果:耗時2782ms。
對齊填充
要想解決上面的偽共用問題也很簡單,既然一個Cache Line存放64位元組的資料,只要在a和b變數之間填充7個無意義的Long變數,佔滿64位元組,這樣a和b就無法被分配進同一個Cache Line中,執行緒之間修改資料互不影響,就沒有上面的問題了。
解決方法如下:
程式執行結果:耗時752ms。
@Contended
Cache Line對齊其實是一種比較low的解決辦法,因為你無法判斷你寫的程式會被放到哪種CPU上執行,不同的CPU它的Cache Line大小是不一樣的,如果超過了64位元組,填充7個long變數就沒有效果了,還有沒有更好的解決辦法呢???
JDK8引入了一個新的註解@Contended,被它修飾的變數,會被存放到一個單獨的Cache Line中,不會和其他變數共用Cache Line。
修改後如下:

程式執行結果:耗時744ms,Cache Line是生效的。
備註
JDK8的老版本中@Contended預設是禁用的,需要手動開啟:
-XX:-RestrictContended。筆者的JDK版本為【1.8.0_191】,-XX:-RestrictContended引數已經沒有用了,預設都會開啟對@Contended註解的支援。
尾巴
理解硬體設計對編寫高效能程式是有必要的!!!