今日份的深入理解MySQL鎖型別和加鎖原理
相關免費學習推薦:
前言
- MySQL索引底層資料結構與演演算法
- MySQL效能優化原理-前篇
- MySQL效能優化-實踐篇1
- MySQL效能優化-實踐篇2
- MySQL鎖與事物隔離級別
前面我們講了MySQL資料庫底層的資料結構與演演算法、MySQL效能優化篇一些內容。以及上篇講了MySQL的行鎖與事務隔離級別。本篇再重點來講講鎖型別和加鎖原理。
首先對mysql鎖進行劃分:
- 按照鎖的粒度劃分:行鎖、表鎖、頁鎖
- 按照鎖的使用方式劃分:共用鎖、排它鎖(悲觀鎖的一種實現)
- 還有兩種思想上的鎖:悲觀鎖、樂觀鎖。
- InnoDB中有幾種行級鎖型別:Record Lock、Gap Lock、Next-key Lock
- Record Lock:在索引記錄上加鎖
- Gap Lock:間隙鎖
- Next-key Lock:Record Lock+Gap Lock
表鎖
表級鎖是 MySQL 鎖中粒度最大的一種鎖,表示當前的操作對整張表加鎖,資源開銷比行鎖少,不會出現死鎖的情況,但是發生鎖衝突的概率很大。被大部分的mysql引擎支援,MyISAM和InnoDB都支援表級鎖,但是InnoDB預設的是行級鎖。
表鎖由 MySQL Server 實現,一般在執行 DDL 語句時會對整個表進行加鎖,比如說 ALTER TABLE 等操作。在執行 SQL 語句時,也可以明確指定對某個表進行加鎖。
表鎖使用的是一次性鎖技術,也就是說,在對談開始的地方使用 lock 命令將後續需要用到的表都加上鎖,在表釋放前,只能存取這些加鎖的表,不能存取其他表,直到最後通過 unlock tables 釋放所有表鎖。
除了使用 unlock tables 顯示釋放鎖之外,對談持有其他表鎖時執行lock table 語句會釋放對談之前持有的鎖;對談持有其他表鎖時執行 start transaction 或者 begin 開啟事務時,也會釋放之前持有的鎖。
共用鎖用法:
LOCK TABLE table_name [ AS alias_name ] READ複製程式碼
排它鎖用法:
LOCK TABLE table_name [AS alias_name][ LOW_PRIORITY ] WRITE複製程式碼
解鎖用法:
unlock tables;複製程式碼
行鎖
行級鎖是Mysql中鎖定粒度最細的一種鎖,表示只針對當前操作的行進行加鎖。行級鎖能大大減少資料庫操作的衝突。其加鎖粒度最小,但加鎖的開銷也最大。有可能會出現死鎖的情況。 行級鎖按照使用方式分為共用鎖和排他鎖。
不同儲存引擎的行鎖實現不同,後續沒有特別說明,則行鎖特指 InnoDB 實現的行鎖。
在瞭解 InnoDB 的加鎖原理前,需要對其儲存結構有一定的瞭解。InnoDB 是聚簇索引,也就是 B+樹的葉節點既儲存了主鍵索引也儲存了資料行。而 InnoDB 的二級索引的葉節點儲存的則是主鍵值,所以通過二級索引查詢資料時,還需要拿對應的主鍵去聚簇索引中再次進行查詢。關於MySQL索引的詳細知識可以檢視《MySQL索引底層資料結構與演演算法》。
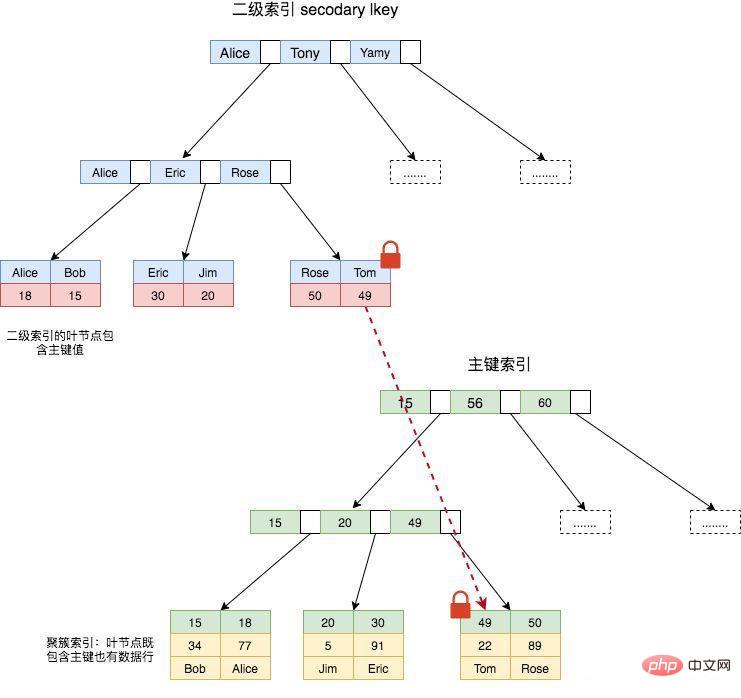
下面以兩條 SQL 的執行為例,講解一下 InnoDB 對於單行資料的加鎖原理。
update user set age = 10 where id = 49; update user set age = 10 where name = 'Tom';複製程式碼
第一條 SQL 使用主鍵索引來查詢,則只需要在 id = 49 這個主鍵索引上加上寫鎖;
第二條 SQL 則使用二級索引來查詢,則首先在 name = Tom 這個索引上加寫鎖,然後由於使用 InnoDB 二級索引還需再次根據主鍵索引查詢,所以還需要在 id = 49 這個主鍵索引上加寫鎖,如上圖所示。
也就是說使用主鍵索引需要加一把鎖,使用二級索引需要在二級索引和主鍵索引上各加一把鎖。
根據索引對單行資料進行更新的加鎖原理了解了,那如果更新操作涉及多個行呢,比如下面 SQL 的執行場景。
update user set age = 10 where id > 49;複製程式碼
這種場景下的鎖的釋放較為複雜,有多種的優化方式,我對這塊暫時還沒有了解,還請知道的小夥伴在下方留言解釋。
頁鎖
頁級鎖是MySQL中鎖定粒度介於行級鎖和表級鎖中間的一種鎖。表級鎖速度快,但衝突多,行級衝突少,但速度慢。所以取了折衷的頁級,一次鎖定相鄰的一組記錄。BDB支援頁級鎖。
共用鎖/排他鎖
共用鎖(Share Lock)
共用鎖又稱讀鎖,是讀取操作建立的鎖。其他使用者可以並行讀取資料,但任何事務都不能對資料進行修改(獲取資料上的排他鎖),直到已釋放所有共用鎖。
如果事務T對資料A加上共用鎖後,則其他事務只能對A再加共用鎖,不能加排他鎖。獲准共用鎖的事務只能讀資料,不能修改資料。
用法
SELECT ... LOCK IN SHARE MODE;
在查詢語句後面增加LOCK IN SHARE MODE,Mysql會對查詢結果中的每行都加共用鎖,當沒有其他執行緒對查詢結果集中的任何一行使用排他鎖時,可以成功申請共用鎖,否則會被阻塞。其他執行緒也可以讀取使用了共用鎖的表,而且這些執行緒讀取的是同一個版本的資料。
排他鎖(eXclusive Lock)
排他鎖又稱寫鎖,如果事務T對資料A加上排他鎖後,則其他事務不能再對A加任任何型別的封鎖。獲准排他鎖的事務既能讀資料,又能修改資料。
用法
SELECT ... FOR UPDATE;
在查詢語句後面增加FOR UPDATE,Mysql會對查詢結果中的每行都加排他鎖,當沒有其他執行緒對查詢結果集中的任何一行使用排他鎖時,可以成功申請排他鎖,否則會被阻塞。
樂觀鎖和悲觀鎖
在資料庫的鎖機制中介紹過,資料庫管理系統(DBMS)中的並行控制的任務是確保在多個事務同時存取資料庫中同一資料時不破壞事務的隔離性和統一性以及資料庫的統一性。
樂觀並行控制(樂觀鎖)和悲觀並行控制(悲觀鎖)是並行控制主要採用的技術手段。
無論是悲觀鎖還是樂觀鎖,都是人們定義出來的概念,可以認為是一種思想。其實不僅僅是關係型資料庫系統中有樂觀鎖和悲觀鎖的概念,像memcache、hibernate、tair等都有類似的概念。
針對於不同的業務場景,應該選用不同的並行控制方式。所以,不要把樂觀並行控制和悲觀並行控制狹義的理解為DBMS中的概念,更不要把他們和資料中提供的鎖機制(行鎖、表鎖、排他鎖、共用鎖)混為一談。其實,在DBMS中,悲觀鎖正是利用資料庫本身提供的鎖機制來實現的。
悲觀鎖
在關聯式資料庫管理系統裡,悲觀並行控制(又名「悲觀鎖」,Pessimistic Concurrency Control,縮寫「PCC」)是一種並行控制的方法。它可以阻止一個事務以影響其他使用者的方式來修改資料。如果一個事務執行的操作對某行資料應用了鎖,那只有當這個事務把鎖釋放,其他事務才能夠執行與該鎖衝突的操作。悲觀並行控制主要用於資料爭用激烈的環境,以及發生並行衝突時使用鎖保護資料的成本要低於回滾事務的成本的環境中。
悲觀鎖,正如其名,它指的是對資料被外界(包括本系統當前的其他事務,以及來自外部系統的事務處理)修改持保守態度(悲觀),因此,在整個資料處理過程中,將資料處於鎖定狀態。 悲觀鎖的實現,往往依靠資料庫提供的鎖機制 (也只有資料庫層提供的鎖機制才能真正保證資料存取的排他性,否則,即使在本系統中實現了加鎖機制,也無法保證外部系統不會修改資料)
悲觀鎖的具體流程
- 在對任意記錄進行修改前,先嚐試為該記錄加上排他鎖(exclusive locking);
- 如果加鎖失敗,說明該記錄正在被修改,那麼當前查詢可能要等待或者丟擲異常。 具體響應方式由開發者根據實際需要決定;
- 如果成功加鎖,那麼就可以對記錄做修改,事務完成後就會解鎖了。
- 其間如果有其他對該記錄做修改或加排他鎖的操作,都會等待我們解鎖或直接丟擲異常。
悲觀鎖的優點和不足
悲觀鎖實際上是採取了「先取鎖在存取」的策略,為資料的處理安全提供了保證,但是在效率方面,由於額外的加鎖機制產生了額外的開銷,並且增加了死鎖的機會。並且降低了並行性;當一個事物所以一行資料的時候,其他事物必須等待該事務提交之後,才能操作這行資料。
樂觀鎖
在關聯式資料庫管理系統裡,樂觀並行控制(又名「樂觀鎖」,Optimistic Concurrency Control,縮寫「OCC」)是一種並行控制的方法。它假設多使用者並行的事務在處理時不會彼此互相影響,各事務能夠在不產生鎖的情況下處理各自影響的那部分資料。在提交資料更新之前,每個事務會先檢查在該事務讀取資料後,有沒有其他事務又修改了該資料。如果其他事務有更新的話,正在提交的事務會進行回滾。
樂觀鎖( Optimistic Locking ) 相對悲觀鎖而言,樂觀鎖假設認為資料一般情況下不會造成衝突,所以在資料進行提交更新的時候,才會正式對資料的衝突與否進行檢測,如果發現衝突了,則讓返回使用者錯誤的資訊,讓使用者決定如何去做。
相對於悲觀鎖,在對資料庫進行處理的時候,樂觀鎖並不會使用資料庫提供的鎖機制。一般的實現樂觀鎖的方式就是記錄資料版本。
資料版本,為資料增加的一個版本標識。當讀取資料時,將版本標識的值一同讀出,資料每更新一次,同時對版本標識進行更新。當我們提交更新的時候,判斷資料庫表對應記錄的當前版本資訊與第一次取出來的版本標識進行比對,如果資料庫表當前版本號與第一次取出來的版本標識值相等,則予以更新,否則認為是過期資料。
樂觀鎖的優點和不足
樂觀並行控制相信事務之間的資料競爭(data race)的概率是比較小的,因此儘可能直接做下去,直到提交的時候才去鎖定,所以不會產生任何鎖和死鎖。但如果直接簡單這麼做,還是有可能會遇到不可預期的結果,例如兩個事務都讀取了資料庫的某一行,經過修改以後寫回資料庫,這時就遇到了問題。
意向共用鎖/意向排他鎖
由於表鎖和行鎖雖然鎖定範圍不同,但是會相互衝突。所以當你要加表鎖時,勢必要先遍歷該表的所有記錄,判斷是否加有排他鎖。這種遍歷檢查的方式顯然是一種低效的方式,MySQL 引入了意向鎖,來檢測表鎖和行鎖的衝突。
意向鎖也是表級鎖,也可分為讀意向鎖(IS 鎖)和寫意向鎖(IX 鎖)。當事務要在記錄上加上讀鎖或寫鎖時,要首先在表上加上意向鎖。這樣判斷表中是否有記錄加鎖就很簡單了,只要看下錶上是否有意向鎖就行了。
意向鎖之間是不會產生衝突的,也不和 AUTO_INC 表鎖衝突,它只會阻塞表級讀鎖或表級寫鎖,另外,意向鎖也不會和行鎖衝突,行鎖只會和行鎖衝突。
意向鎖是InnoDB自動加的,不需要使用者干預。
對於insert、update、delete,InnoDB會自動給涉及的資料加排他鎖(X);
對於一般的Select語句,InnoDB不會加任何鎖,事務可以通過以下語句給顯示加共用鎖或排他鎖。
意向共用鎖(Intention Shared Lock)
意向共用鎖(IS):表示事務準備給資料行加入共用鎖,也就是說一個資料行加共用鎖前必須先取得該表的IS鎖
意向排他鎖(Exclusive Lock)
意向排他鎖(IX):類似上面,表示事務準備給資料行加入排他鎖,說明事務在一個資料行加排他鎖前必須先取得該表的IX鎖。
記錄鎖(Record Lock)
記錄鎖是最簡單的行鎖,並沒有什麼好說的。上邊描述 InnoDB 加鎖原理中的鎖就是記錄鎖,只鎖住 id = 49 或者 name = 'Tom' 這一條記錄。
當 SQL 語句無法使用索引時,會進行全表掃描,這個時候 MySQL 會給整張表的所有資料行加記錄鎖,再由 MySQL Server 層進行過濾。但是,在 MySQL Server 層進行過濾的時候,如果發現不滿足 WHERE 條件,會釋放對應記錄的鎖。這樣做,保證了最後只會持有滿足條件記錄上的鎖,但是每條記錄的加鎖操作還是不能省略的。
所以更新操作必須要根據索引進行操作,沒有索引時,不僅會消耗大量的鎖資源,增加資料庫的開銷,還會極大的降低了資料庫的並行效能。
間隙鎖(Gap Lock)
當我們使用範圍條件而不是相等條件檢索資料,並請求共用或排他鎖時,InnoDB會給符合條件的已有資料記錄的索引項加鎖;對於鍵值在條件範圍內但並不存在的記錄,InnoDB 也會對這個「間隙」加鎖,這種鎖機制就是所謂的間隙鎖。
間隙鎖是鎖索引記錄中的間隔,或者第一條索引記錄之前的範圍,又或者最後一條索引記錄之後的範圍。
間隙鎖在 InnoDB 的唯一作用就是防止其它事務的插入操作,以此來達到防止幻讀的發生,所以間隙鎖不分什麼共用鎖與排他鎖。
要禁止間隙鎖,可以把隔離級別降為讀已提交,或者開啟引數 innodb_locks_unsafe_for_binlog
show variables like 'innodb_locks_unsafe_for_binlog';複製程式碼

innodb_locks_unsafe_for_binlog:預設
值為OFF,即啟用間隙鎖。因為此引數是唯讀模式,如果想要禁用間隙鎖,需要修改 my.cnf(windows是my.ini) 重新啟動才行。
# 在 my.cnf 裡面的[mysqld]新增 [mysqld] innodb_locks_unsafe_for_binlog = 1複製程式碼
案例1:唯一索引的間隙鎖
測試環境:
MySQL5.7,InnoDB,預設的隔離級別(RR)
範例表:
CREATE TABLE `my_gap` ( `id` int(1) NOT NULL AUTO_INCREMENT, `name` varchar(8) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;INSERT INTO `my_gap` VALUES ('1', '張三');INSERT INTO `my_gap` VALUES ('5', '李四');INSERT INTO `my_gap` VALUES ('7', '王五');INSERT INTO `my_gap` VALUES ('11', '趙六');複製程式碼在進行測試之前,我們先看看 my_gap 表中存在的隱藏間隙:
- (-infinity, 1]
- (1, 5]
- (5, 7]
- (7, 11]
- (11, +infinity]
只使用記錄鎖(行鎖),不會產生間隙鎖
/* 開啟事務1 */BEGIN;/* 查詢 id = 5 的資料並加記錄鎖 */SELECT * FROM `my_gap` WHERE `id` = 5 FOR UPDATE;/* 延遲30秒執行,防止鎖釋放 */SELECT SLEEP(30); # 注意:以下的語句不是放在一個事務中執行,而是分開多次執行,每次事務中只有一條新增語句/* 事務2插入一條 name = '杰倫' 的資料 */INSERT INTO `my_gap` (`id`, `name`) VALUES (4, '杰倫'); # 正常執行/* 事務3插入一條 name = '學友' 的資料 */INSERT INTO `my_gap` (`id`, `name`) VALUES (8, '學友'); # 正常執行/* 提交事務1,釋放事務1的鎖 */COMMIT;複製程式碼
上述案例,由於主鍵是唯一索引,而且只使用一個索引查詢,並且只鎖定了一條記錄,所以只會對 id = 5 的資料加上記錄鎖(行鎖),而不會產生間隙鎖。
產生間隙鎖
恢復初始化的4條記錄,繼續在 id 唯一索引列上做以下測試:

/* 開啟事務1 */BEGIN;/* 查詢 id 在 7 - 11 範圍的資料並加記錄鎖 */SELECT * FROM `my_gap` WHERE `id` BETWEEN 5 AND 7 FOR UPDATE;/* 延遲30秒執行,防止鎖釋放 */SELECT SLEEP(30); # 注意:以下的語句不是放在一個事務中執行,而是分開多次執行,每次事務中只有一條新增語句/* 事務2插入一條 id = 3,name = '思聰3' 的資料 */INSERT INTO `my_gap` (`id`, `name`) VALUES (3, '思聰3'); # 正常執行/* 事務3插入一條 id = 4,name = '思聰4' 的資料 */INSERT INTO `my_gap` (`id`, `name`) VALUES (4, '思聰4'); # 正常執行/* 事務4插入一條 id = 6,name = '思聰6' 的資料 */INSERT INTO `my_gap` (`id`, `name`) VALUES (6, '思聰6'); # 阻塞/* 事務5插入一條 id = 8, name = '思聰8' 的資料 */INSERT INTO `my_gap` (`id`, `name`) VALUES (8, '思聰8'); # 阻塞/* 事務6插入一條 id = 9, name = '思聰9' 的資料 */INSERT INTO `my_gap` (`id`, `name`) VALUES (9, '思聰9'); # 阻塞/* 事務7插入一條 id = 11, name = '思聰11' 的資料 */INSERT INTO `my_gap` (`id`, `name`) VALUES (11, '思聰11'); # 阻塞/* 事務8插入一條 id = 12, name = '思聰12' 的資料 */INSERT INTO `my_gap` (`id`, `name`) VALUES (12, '思聰12'); # 正常執行/* 提交事務1,釋放事務1的鎖 */COMMIT;複製程式碼
從上面可以看到,(5,7]、(7,11] 這兩個區間,都不可插入資料,其它區間,都可以正常插入資料。所以可以得出結論:當我們給(5,7] 這個區間加鎖的時候,會鎖住(5,7]、(7,11] 這兩個區間。
恢復初始化的4條記錄,我們再來測試如果鎖住不存在的資料時,會如何?
/* 開啟事務1 */BEGIN;/* 查詢 id = 3 這一條不存在的資料並加記錄鎖 */SELECT * FROM `my_gap` WHERE `id` = 3 FOR UPDATE;/* 延遲30秒執行,防止鎖釋放 */SELECT SLEEP(30); # 注意:以下的語句不是放在一個事務中執行,而是分開多次執行,每次事務中只有一條新增語句/* 事務2插入一條 id = 3,name = '小張' 的資料 */INSERT INTO `my_gap` (`id`, `name`) VALUES (2, '小張'); # 阻塞/* 事務3插入一條 id = 4,name = '小白' 的資料 */INSERT INTO `my_gap` (`id`, `name`) VALUES (4, '小白'); # 阻塞/* 事務4插入一條 id = 6,name = '小東' 的資料 */INSERT INTO `my_gap` (`id`, `name`) VALUES (6, '小東'); # 正常執行/* 事務5插入一條 id = 8, name = '大羅' 的資料 */INSERT INTO `my_gap` (`id`, `name`) VALUES (8, '大羅'); # 正常執行/* 提交事務1,釋放事務1的鎖 */COMMIT;複製程式碼
從上面可以看出,指定查詢某一條記錄時,如果這條記錄不存在,會產生間隙鎖。
結論
- 對於指定查詢某一條記錄的加鎖語句,如果該記錄不存在,會產生記錄鎖(行鎖)和間隙鎖,如果記錄存在,則只會產生記錄鎖(行鎖);
- 對於查詢某一範圍內的查詢語句,會產生間隙鎖。
案例2:普通索引的間隙鎖
範例表:id 是主鍵,在 number 上,建立了一個普通索引。
# 注意:number 不是唯一值CREATE TABLE `my_gap1` ( `id` int(1) NOT NULL AUTO_INCREMENT, `number` int(1) NOT NULL COMMENT '數位', PRIMARY KEY (`id`), KEY `number` (`number`) USING BTREE ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;INSERT INTO `my_gap1` VALUES (1, 1);INSERT INTO `my_gap1` VALUES (5, 3);INSERT INTO `my_gap1` VALUES (7, 8);INSERT INTO `my_gap1` VALUES (11, 12);複製程式碼
在進行測試之前,我們先來看看 my_gap1 表中 number 索引存在的隱藏間隙:
- (-infinity, 1]
- (1, 3]
- (3, 8]
- (8, 12]
- (12, +infinity]
測試1
我們執行以下的事務(事務1最後提交),分別執行下面的語句:
/* 開啟事務1 */BEGIN;/* 查詢 number = 3 的資料並加記錄鎖 */SELECT * FROM `my_gap1` WHERE `number` = 3 FOR UPDATE;/* 延遲30秒執行,防止鎖釋放 */SELECT SLEEP(30); # 注意:以下的語句不是放在一個事務中執行,而是分開多次執行,每次事務中只有一條新增語句/* 事務2插入一條 number = 0 的資料 */INSERT INTO `my_gap1` (`number`) VALUES (0); # 正常執行/* 事務3插入一條 number = 1 的資料 */INSERT INTO `my_gap1` (`number`) VALUES (1); # 被阻塞/* 事務4插入一條 number = 2 的資料 */INSERT INTO `my_gap1` (`number`) VALUES (2); # 被阻塞/* 事務5插入一條 number = 4 的資料 */INSERT INTO `my_gap1` (`number`) VALUES (4); # 被阻塞/* 事務6插入一條 number = 8 的資料 */INSERT INTO `my_gap1` (`number`) VALUES (8); # 正常執行/* 事務7插入一條 number = 9 的資料 */INSERT INTO `my_gap1` (`number`) VALUES (9); # 正常執行/* 事務8插入一條 number = 10 的資料 */INSERT INTO `my_gap1` (`number`) VALUES (10); # 正常執行/* 提交事務1 */COMMIT;複製程式碼
我們會發現有些語句可以正常執行,有些語句被阻塞來。檢視表中的資料:

這裡可以看到,number(1,8) 的間隙中,插入語句都被阻塞來,而不在這個範圍內的語句,正常執行,這就是因為有間隙鎖的原因。
測試2
我們再進行以下測試,這裡將資料還原成初始化那樣
/* 開啟事務1 */BEGIN;/* 查詢 number = 3 的資料並加記錄鎖 */SELECT * FROM `my_gap1` WHERE `number` = 3 FOR UPDATE;/* 延遲30秒執行,防止鎖釋放 */SELECT SLEEP(30);/* 事務1插入一條 id = 2, number = 1 的資料 */INSERT INTO `my_gap1` (`id`, `number`) VALUES (2, 1); # 阻塞/* 事務2插入一條 id = 3, number = 2 的資料 */INSERT INTO `my_gap1` (`id`, `number`) VALUES (3, 2); # 阻塞/* 事務3插入一條 id = 6, number = 8 的資料 */INSERT INTO `my_gap1` (`id`, `number`) VALUES (6, 8); # 阻塞/* 事務4插入一條 id = 8, number = 8 的資料 */INSERT INTO `my_gap1` (`id`, `number`) VALUES (8, 8); # 正常執行/* 事務5插入一條 id = 9, number = 9 的資料 */INSERT INTO `my_gap1` (`id`, `number`) VALUES (9, 9); # 正常執行/* 事務6插入一條 id = 10, number = 12 的資料 */INSERT INTO `my_gap1` (`id`, `number`) VALUES (10, 12); # 正常執行/* 事務7修改 id = 11, number = 12 的資料 */UPDATE `my_gap1` SET `number` = 5 WHERE `id` = 11 AND `number` = 12; # 阻塞/* 提交事務1 */COMMIT;複製程式碼
檢視表中的資料;

這裡有一個奇怪的現象:
- 事務3 新增 id = 6,number = 8 的資料,阻塞了;
- 事務4 新增 id = 8,number = 8 的資料,正常執行了;
- 事務7 將 id = 11,number = 12 的資料修改為 id = 11, number = 5 的操作,給阻塞了。
這是為什麼?我們來看看下面的圖:

從圖中庫看出,當 number 相同時,會根據主鍵 id 來排序
- 事務 3 新增的 id = 6,number = 8,這條資料是在 (3,8) 的區間裡邊,所以會阻塞;
- 事務 4 新增的 id = 8,number = 8,這條資料實在 (8,12) 區間裡邊,所以不會阻塞;
- 事務 7 的修改語句相當於 在 (3,8) 的區間裡邊插入一條資料,所以也被阻塞了。
結論
- 在普通索引列上,不管是何種查詢,只要加鎖,都會產生間隙鎖,這跟唯一索引不一樣;
- 在普通索引跟唯一索引中,資料間隙的分析,資料行是優先根據普通普通索引排序,再根據唯一索引排序。
臨鍵鎖(Next-key Locks)
臨鍵鎖,是記錄鎖(行鎖)與間隙鎖的組合,它的鎖範圍,即包含索引記錄,又包含索引區間。它指的是加在某條記錄以及這條記錄前面間隙上的鎖。假設一個索引包含 15、18、20 ,30,49,50 這幾個值,可能的 Next-key 鎖如下:
(-∞, 15],(15, 18],(18, 20],(20, 30],(30, 49],(49, 50],(50, +∞)複製程式碼
通常我們都用這種左開右閉區間來表示 Next-key 鎖,其中,圓括號表示不包含該記錄,方括號表示包含該記錄。前面四個都是 Next-key 鎖,最後一個為間隙鎖。和間隙鎖一樣,在 RC 隔離級別下沒有 Next-key 鎖,只有 RR 隔離級別才有。還是之前的例子,如果 id 不是主鍵,而是二級索引,且不是唯一索引,那麼這個 SQL 在 RR 隔離級別下就會加如下的 Next-key 鎖 (30, 49](49, 50)
此時如果插入一條 id = 31 的記錄將會阻塞住。之所以要把 id = 49 前後的間隙都鎖住,仍然是為了解決幻讀問題,因為 id 是非唯一索引,所以 id = 49 可能會有多條記錄,為了防止再插入一條 id = 49 的記錄。
注意:臨鍵鎖的主要目的,也是為了避免幻讀(Phantom Read)。如果把事務隔離級別降級為 RC,臨鍵鎖則也會失效。
插入意向鎖(Insert Intention Locks)
插入意向鎖是一種特殊的間隙鎖(簡稱II GAP)表示插入的意向,只有在 INSERT 的時候才會有這個鎖。注意,這個鎖雖然也叫意向鎖,但是和上面介紹的表級意向鎖是兩個完全不同的概念,不要搞混了。
插入意向鎖和插入意向鎖之間互不衝突,所以可以在同一個間隙中有多個事務同時插入不同索引的記錄。譬如在例子中,id = 30 和 id = 49 之間如果有兩個事務要同時分別插入 id = 32 和 id = 33 是沒問題的,雖然兩個事務都會在 id = 30 和 id = 50 之間加上插入意向鎖,但是不會衝突。
插入意向鎖只會和間隙鎖或 Next-key 鎖衝突,正如上面所說,間隙鎖唯一的作用就是防止其他事務插入記錄造成幻讀,正是由於在執行 INSERT 語句時需要加插入意向鎖,而插入意向鎖和間隙鎖衝突,從而阻止了插入操作的執行。
插入意向鎖的作用:
- 為來喚起等待。由於該間隙已經有鎖,插入時必須阻塞,插入意向鎖的作用具有阻塞功能;
- 插入意向鎖是一種特殊的間隙鎖,既然是一種間隙鎖,為什麼不直接使用間隙鎖?間隙鎖直接不相互排斥。不可以阻塞即喚起等待,會造成幻讀。
- 為什麼不實用記錄鎖(行鎖)或 臨鍵鎖?申請了記錄鎖或臨鍵鎖,臨鍵鎖之間可能相互排斥,即影響 insert 的並行性。
自增鎖(Auto-inc Locks)
AUTO_INC 鎖又叫自增鎖(一般簡寫成 AI 鎖),是一種表鎖,當表中有自增列(AUTO_INCREMENT)時出現。當插入表中有自增列時,資料庫需要自動生成自增值,它會先為該表加 AUTO_INC 表鎖,阻塞其他事務的插入操作,這樣保證生成的自增值肯定是唯一的。AUTO_INC 鎖具有如下特點:
- AUTO_INC 鎖互不相容,也就是說同一張表同時只允許有一個自增鎖;
- 自增值一旦分配了就會 +1,如果事務回滾,自增值也不會減回去,所以自增值可能會出現中斷的情況。
自增操作
使用AUTO_INCREMENT 函數實現自增操作,自增幅度通過 auto_increment_offset和auto_increment_increment這2個引數進行控制:
- auto_increment_offset 表示起始數位
- auto_increment_increment 表示調動幅度(即每次增加n個數位,2就代表每次+2)
通過使用last_insert_id()函數可以獲得最後一個插入的數位
select last_insert_id();複製程式碼
自增鎖
首先insert大致上可以分成三類:
- simple insert 如insert into t(name) values('test')
- bulk insert 如load data | insert into ... select .... from ....
- mixed insert 如insert into t(id,name) values(1,'a'),(null,'b'),(5,'c');
如果存在自增欄位,MySQL 會維護一個自增鎖,和自增鎖相關的一個引數為(5.1.22 版本後加入) innodb_autoinc_lock_mode ,可以設定 3 值:
- 0 :traditonal (每次都會產生表鎖)
- 1 :consecutive(會產生一個輕量鎖,simple insert 會獲得批次的鎖,保證連續插入)
- 2 :interleaved (不會鎖表,來一個處理一個,並行最高)
MyISam引擎均為 traditonal,每次均會進行表鎖。但是InnoDB引擎會視引數不同產生不同的鎖,預設為 1:consecutive。
show variables like 'innodb_autoinc_lock_mode';複製程式碼
traditonal
innodb_autoinc_lock_mode 為 0 時,也就是 traditional 級別。該自增鎖時表鎖級別,且必須等待當前 SQL 執行完畢後或者回滾才會釋放,在高並行的情況下可想而知自增鎖競爭時比較大的。
- 它提供來一個向後相容的能力
- 在這一模式下,所有的 insert 語句(「insert like」)都要在語句開始的時候得到一個表級的 auto_inc 鎖,在語句結束的時候才釋放這把鎖。注意,這裡說的是語句級而不是事務級的,一個事務可能包含有一個或多個語句;
- 它能保證值分配的可預見性、可連續性、可重複性,這個也就是保證了 insert 語句在複製到 slave 的時候還能生成和 master 那邊一樣的值(它保證了基於語句複製的安全);
- 由於在這種模式下 auto_inc 鎖一直要保持到語句的結束,所以這個就影響了並行的插入。
consecutive
innodb_autoinc_lock_mode 為 1 時,也就是 consecutive 級別。這是如果是單一的 insert SQL,可以立即獲得該鎖,並立即釋放,而不必等待當前SQL執行完成(除非在其它事務中已經有 session 獲取了自增鎖)。另外當SQL是一些批次 insert SQL 時,比如 insert into ... select ... , load data , replace ... select ... 時,這時還是表級鎖,可以理解為退化為必須等待當前 SQL 執行完才釋放。可以認為,該值為 1 時相對比較輕量級的鎖,也不會對複製產生影響,唯一的缺陷是產生自增值不一定是完全連續的。
- 這一模式下對 simple insert 做了優化,由於 simple insert 一次性插入的值的個數可以立馬得到確定,所以 MyQL 可以一次生成幾個連續的值,用於這個 insert 語句。總得來說這個對複製也是安全的(它保證了基於語句複製的安全);
- 這一模式也是MySQL的預設模式,這個模式的好處是 auto_inc 鎖不要一直保持到語句的結束,只要語句得到了相應的值就可以提前釋放鎖。
interleaved
innodb_autoinc_lock_mode 為 2 時,也就是 interleaved 級別。所有 insert 種類的 SQL 都可以立馬獲得鎖並釋放,這時的效率最高。但是會引入一個新的問題:當 binlog_format 為 statement 時,這是複製沒法保證安全,因為批次的 insert,比如 insert ... select ... 語句在這個情況下,也可以立馬獲取到一大批的自增 id 值,不必鎖整個表, slave 在回放這個 SQL 時必然會產生錯亂。
- 由於這個模式下已經沒有了 auto_inc 鎖,所以這個模式下的效能是最好的,但是也有一個問題,就是對於同一個語句來說它所得到的 auto_incremant 值可能不是連續的。
如果你的二進位制檔案格式是mixed | row 那麼這三個值中的任何一個對於你來說都是複製安全的。
由於現在mysql已經推薦把二進位制的格式設定成row,所以在binlog_format不是statement的情況下最好是innodb_autoinc_lock_mode=2 這樣可能知道更好的效能。
總結
InnoDB鎖的特性
- 在不通過索引條件查詢的時候,InnoDB使用的確實是表鎖!
- 由於 MySQL 的行鎖是針對索引加的鎖,不是針對記錄加的鎖,所以雖然是存取不同行 的記錄,但是如果是使用相同的索引鍵,是會出現鎖衝突的。
- 當表有多個索引的時候,不同的事務可以使用不同的索引鎖定不同的行,另外,不論 是使用主鍵索引、唯一索引或普通索引,InnoDB 都會使用行鎖來對資料加鎖。
- 即便在條件中使用了索引欄位,但是否使用索引來檢索資料是由 MySQL 通過判斷不同 執行計劃的代價來決定的,如果 MySQL 認為全表掃 效率更高,比如對一些很小的表,它 就不會使用索引,這種情況下 InnoDB 將使用表鎖,而不是行鎖。因此,在分析鎖衝突時, 別忘了檢查 SQL 的執行計劃(explain檢視),以確認是否真正使用了索引。
鎖模式
鎖的模式有:讀意向鎖,寫意向鎖,讀鎖,寫鎖和自增鎖(auto_inc)。
不同模式鎖的相容矩陣
| IS | IX | S | X | AI | |
|---|---|---|---|---|---|
| IS | 相容 | 相容 | 相容 | 相容 | |
| IX | 相容 | 相容 | 相容 | ||
| S | 相容 | 相容 | |||
| X | |||||
| AI | 相容 | 相容 |
總結起來有下面幾點:
- 意向鎖之間互不衝突;
- S 鎖只和 S/IS 鎖相容,和其他鎖都衝突;
- X 鎖和其他所有鎖都衝突;
- AI 鎖只和意向鎖相容;
鎖的型別
根據鎖的粒度可以把鎖細分為表鎖和行鎖,行鎖根據場景的不同又可以進一步細分,依次為 Next-Key Lock,Gap Lock 間隙鎖,Record Lock 記錄鎖和插入意向 GAP 鎖。
不同的鎖鎖定的位置是不同的,比如說記錄鎖只鎖住對應的記錄,而間隙鎖鎖住記錄和記錄之間的間隔,Next-Key Lock 則所屬記錄和記錄之前的間隙。不同型別鎖的鎖定範圍大致如下圖所示。
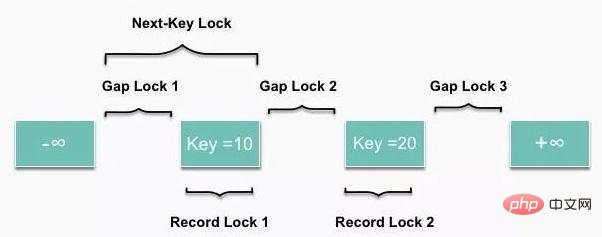
不同型別鎖的相容矩陣
| RECORD | GAP | NEXT-KEY | II GAP | |
|---|---|---|---|---|
| RECORD | 相容 | 相容 | ||
| GAP | 相容 | 相容 | 相容 | 相容 |
| NEXT-KEY | 相容 | 相容 | ||
| II GAP | 相容 | 相容 |
其中,第一行表示已有的鎖,第一列表示要加的鎖。插入意向鎖較為特殊,所以我們先對插入意向鎖做個總結,如下:
- 插入意向鎖不影響其他事務加其他任何鎖。也就是說,一個事務已經獲取了插入意向鎖,對其他事務是沒有任何影響的;
- 插入意向鎖與間隙鎖和 Next-key 鎖衝突。也就是說,一個事務想要獲取插入意向鎖,如果有其他事務已經加了間隙鎖或 Next-key 鎖,則會阻塞。
其他型別的鎖的規則較為簡單:
- 間隙鎖不和其他鎖(不包括插入意向鎖)衝突;
記錄鎖和記錄鎖衝突,Next-key 鎖和 Next-key 鎖衝突,記錄鎖和 Next-key 鎖衝突;
以上就是今日份的深入理解MySQL鎖型別和加鎖原理的詳細內容,更多請關注TW511.COM其它相關文章!