最新爬取全網代理IP【隱藏標籤混淆+埠加密】(一)
爬取全網代理IP【隱藏標籤混淆+埠加密】(一)
起因:這兩天,在學習Scrapy爬取某家租房資訊時,被頻繁封IP,去網上找免費的代理IP,時間長,還要測試有效性,去購買套餐,又不值得,畢竟只是學習。於是,就打算搭建一個代理池,在網上爬取公開免費的代理IP,並進行維護,做有效性檢測。
前言:在爬取前幾家(西拉代理、泥馬代理等)公開的免費代理IP時,都沒問題,很順利的就爬取下來了,但在爬取全網代理時,讓我的腳步,一度放慢,為什麼呢?
坐好坐好,開始表演啦~~🐱🏍
一、混淆在其中的隱藏標籤
1.分析對方
先放上其全網代理官網地址:http://www.goubanjia.com/
老練的,按F12,複製xpath,進行提取…等等,等等,我們看下圖,發現它多出一些p標籤來了【達到了混淆的目的】,這對我們可不是好事。
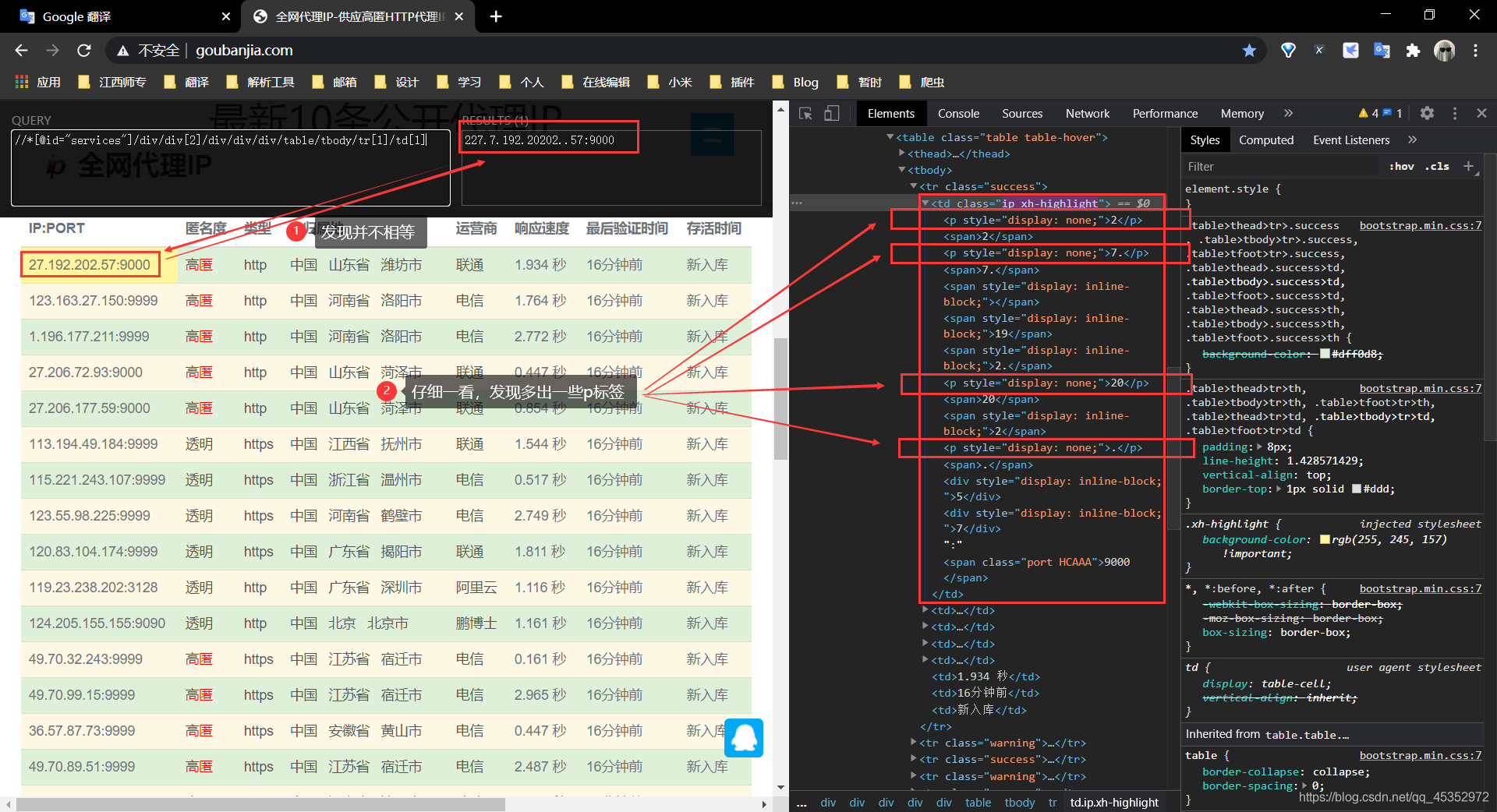
怎麼辦呢?我們仔細看看這些混淆在其中的p標籤,發現都有一個共同的一個特點,就是混淆值的下一個就是真實值;即該p標籤跟p標籤下一個標籤的值是相等的。【突破的關鍵】
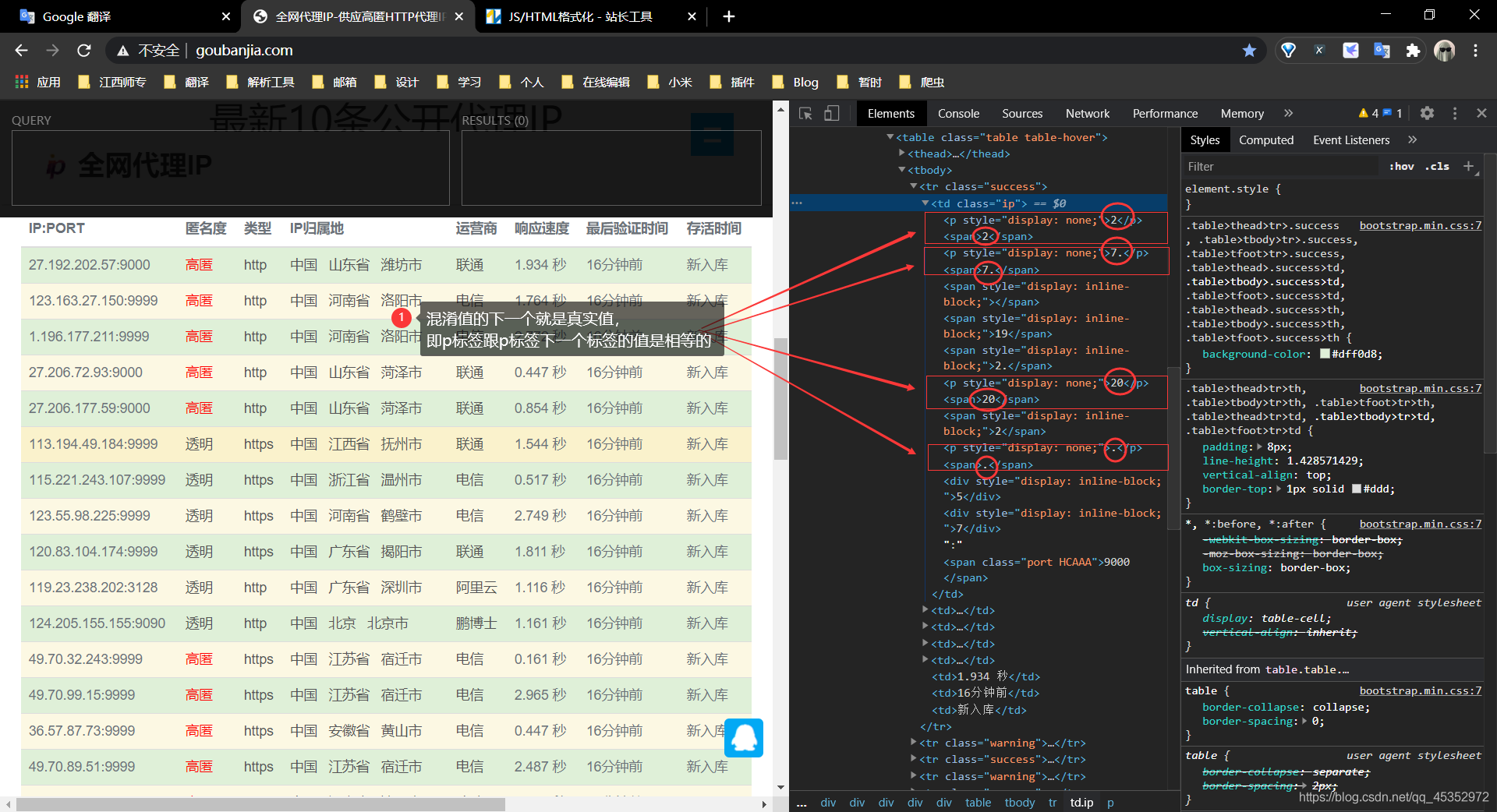
如下:
<td class="ip">
<p style='display: none;'>2</p> //<----
<span>2</span>
<p style='display: none;'>7.</p> //<----
<span>7.</span>
<span style='display: inline-block;'></span>
<span style='display: inline-block;'>19</span>
<span style='display: inline-block;'>2.</span>
<p style='display: none;'>20</p> //<----
<span>20</span>
<span style='display: inline-block;'>2</span>
<p style='display: none;'>.</p> //<----
<span>.</span>
<div style='display: inline-block;'>5</div>
<div style='display: inline-block;'>7</div>:
<span class="port HCAAA">8174</span>
</td>
2.首次出征
瞭解到這些就好辦了,解決方法:
我們直接將td標籤下的值都獲取下來,然後進行校驗,校驗思路,我們瞭解混淆的值跟下一個值是一樣的,那拿它作為我們的校驗條件,遍歷裡面的值,將遍歷的值跟後一個值進行匹配,如果相同,刪除當前遍歷的值,但我們看看下面這個td標籤
<td class="ip">
<span style='display:inline-block;'>2</span>
<span style='display:inline-block;'>2</span>
<p style='display: none;'>0.</p>
<span>0.</span>
<span style='display:inline-block;'>1</span>
<span style='display:inline-block;'>67</span>
<span style='display:inline-block;'>.4</span>
<div style='display:inline-block;'>2</div>
<div style='display:inline-block;'></div>
<p style='display: none;'></p>
<span></span>
<div style='display:inline-block;'>.1</div>
<p style='display: none;'>5</p>
<span>5</span>:
<span class="port GEZEE">8823</span>
</td>
我們使用剛才那個校驗規則,來校驗這個,第一個值(是2)跟第二個值(也是2)相同,刪除第一個,但實際,我們並不是要刪除這個,而是p標籤下的字元,所以繼續優化校驗規則。
3.二次再戰
我們知道xpath是可以通過文字獲取它的內容。如果輸入的文字沒有找到相應的值則會返回空,如//tr[1]/td[1]/p[text()="2"]/text(),其中text()="2"的2 就是第一個校驗規則匹配篩選出的相同值,將其放入到xpath語法中,通過文字查詢它的值,如果有值,說明在該td標籤中有該值的p標籤,反之該值就不是p標籤的值。
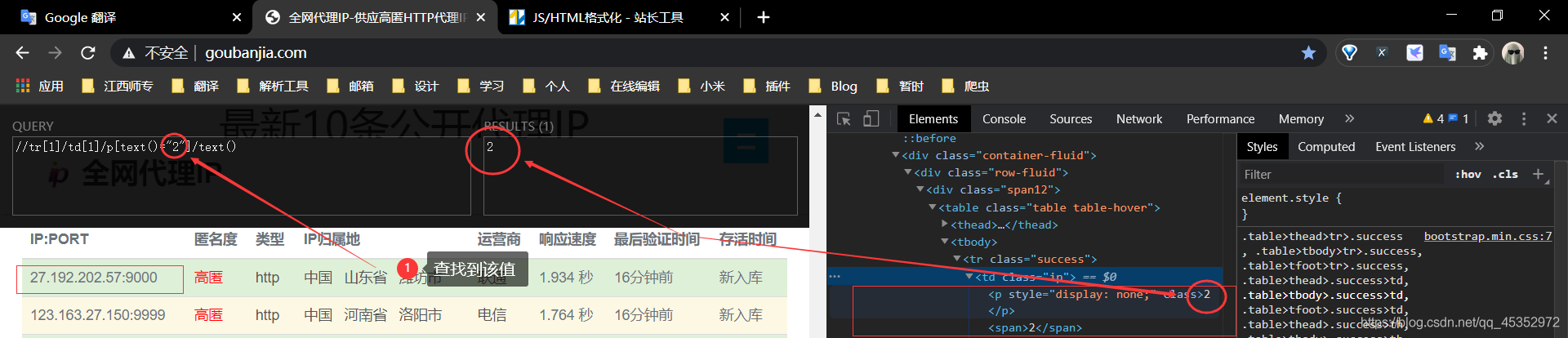
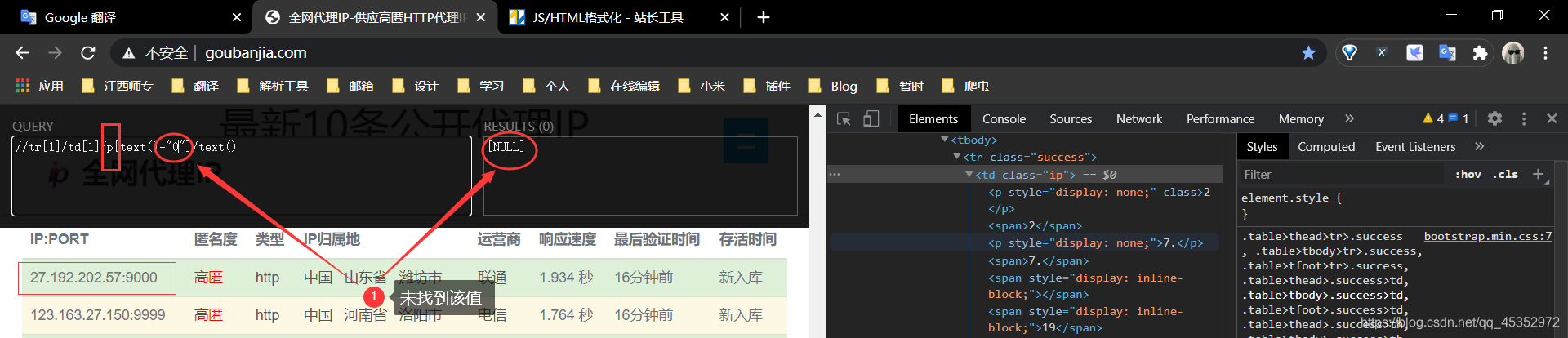
梳理下,校驗規則,先獲取
td下的所有值,並進行遍歷,第一次篩選,如果第一個值跟下一個值相同,進入第二次篩選,如果該值能通過p標籤的文字查詢到相同文字,說明td標籤下確實有該值的p標籤,並將其刪除,即刪除p標籤的值,留下真實(有效)值。
4.區域性出兵策略
**校驗規則**程式碼如下:
# 獲取所有的tr標籤
tr_list = html_str.xpath('//*[@id="services"]/div/div[2]/div/div/div/table/tbody/tr')
for tr in tr_list:
# TODO 1.解析ip值
tr_ip = tr.xpath('./td[1]//text()') # 獲取td[1]下的所有值
tr_ip_list = list(enumerate(tr_ip))
y = 0
while True:
if y + 1 < len(tr_ip_list):
# 第一個校驗條件,如果兩值相等 -->可疑物件
if tr_ip_list[y][1] == tr_ip_list[y + 1][1]:
# 第二個校驗條件,如果成立,即已確定是混淆值,進行刪除當前遍歷的值
if tr.xpath(f'./td[1]/p[text()="{tr_ip_list[y][1]}"]/text()'):
# print('在p標籤中,文字查詢返回值:', tr.xpath(f'./td[1]/p[text()="{tr_ip_list[y][1]}"]/text()')[0], '並等於下一個值:', tr_ip_list[y + 1][1], '-->刪除該p標籤值:',tr_ip_list[y])
del tr_ip_list[y] # 刪除當前值
else:
# print('在p標籤中,文字查詢返回值:', tr.xpath(f'./td[1]/p[text()="{tr_ip_list[y][1]}"]/text()'), '不等於下一個值', tr_ip_list[y + 1][1],'>>>>>>可疑物件關係解除<<<<<<')
pass
else:
break
y += 1
ip = "".join([i[1] for i in tr_ip_list])
print('IP:', ip, '\n', "=" * 100)
如果不是很懂的,可以取消列印註釋,看看控制檯效果。

【擴充套件】第二個校驗規則還可以這麼寫,我們再仔細看看其p標籤,發現都有共同的 display: none; 屬性。所以,第二個條件我們可以這麼判斷,通過文字去獲取它的屬性,如果屬性為display: none;,即說明該值是在p標籤中。(這個就不做程式碼演示了,跟上面的基本一樣。)
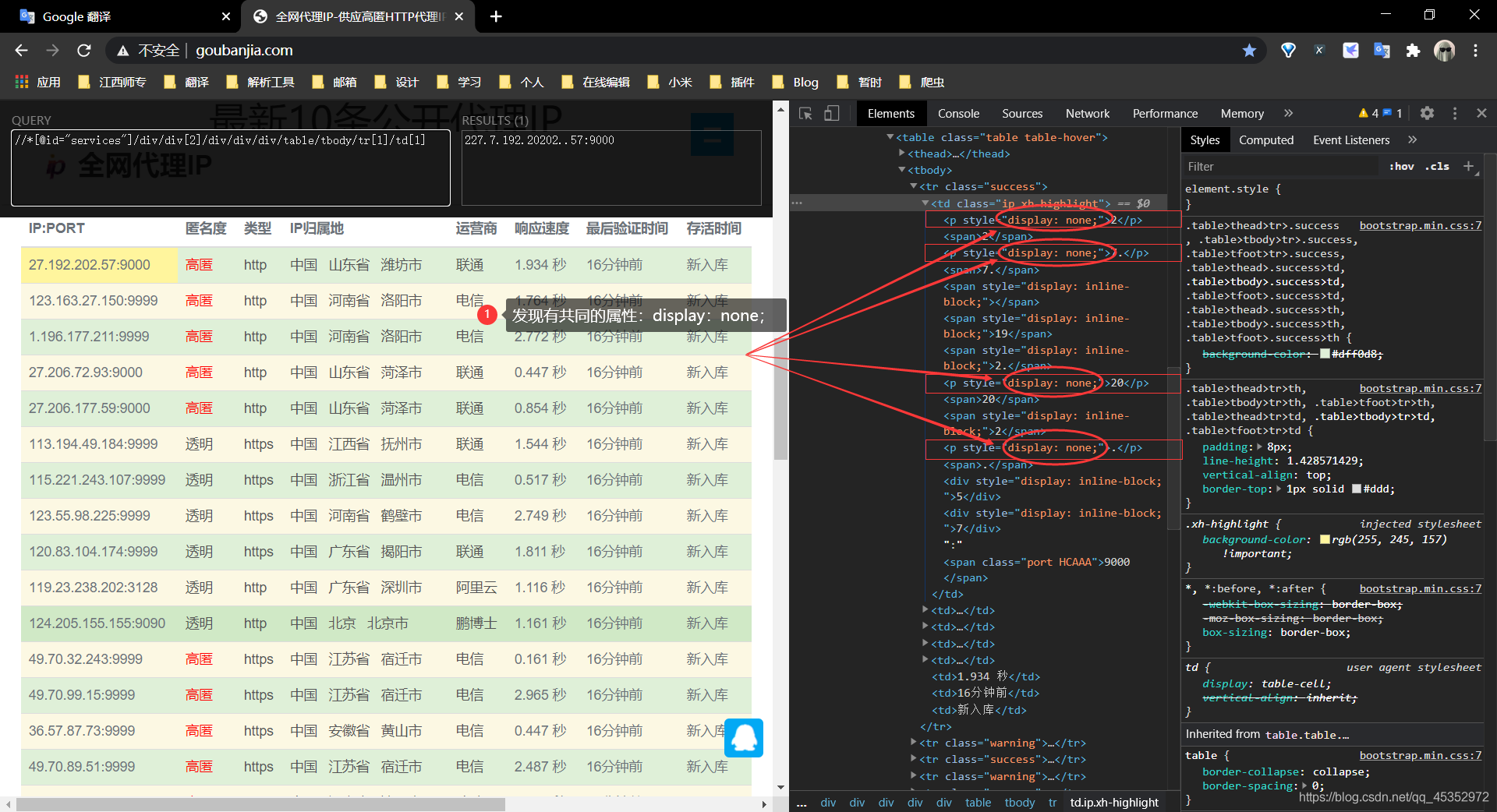
到這,我們就將這些混淆在其中的隱藏元素標籤給剔除了。
5.準備發起總攻
結束了?並沒呢,我們只是將其ip給解析了,埠還加密著呢,但是考慮到文章太長,閱讀效果不佳,於是就放在下一篇。
剛接觸這塊知識,程式碼寫的不好,還請諒解,如果有理解錯誤的,也請大佬在評論區指出來,非常感謝!
以上就是剔除混淆在其中的隱藏標籤的所有內容了,點贊收藏加評論是最大的支援哦!
📑編寫不易,轉載請註明出處,如有侵權,請聯絡我!