記一次排序規則utf8_genera_ci與utf8mb4_bin的區別引發的資料丟失問題
2020-10-05 13:00:33
前言
在做一個批次匯入關鍵詞的功能時,發現關鍵詞如果帶有像é這樣的字元時,存入資料庫時會識別為e,造成部分關鍵詞沒有被匯入,且與原來部分關鍵詞可能重複的情況,因此記錄下來避免以後再踩坑。
提示:以下是本篇文章正文內容,下面案例可供參考
一、準備工作
準備一份批次匯入關鍵詞excel,其中包含2個關鍵詞
1.pokemon
2.pokémon
注意:這2個關鍵詞中一個是普通的e,一個是帶音節的é
準備資料庫表sql指令碼
-- 匯入關鍵詞表
CREATE TABLE `keyword_lexicon` (
`id` int(10) NOT NULL AUTO_INCREMENT,
`keyword` varchar(128) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL DEFAULT '' COMMENT '搜尋關鍵詞',
PRIMARY KEY ("id"),
UNIQUE KEY "idx_keyword" ("keyword") USING BTREE COMMENT '關鍵詞'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='匯入關鍵詞表';
二、場景復現
簡單寫一個匯入介面,程式碼就不附上了,需要注意的是匯入sql用的是INSERT IGNORE INTO的方式,如果表中已經有該關鍵詞了則不會寫入表中。(keyword欄位設為唯一索引)
匯入sql例子如下
INSERT IGNORE INTO keyword_lexicon (`keyword`) VALUES ('pokemon'),('pokémon')
調介面完成匯入後,檢視資料庫表,發現只有一條pokemon的資料。
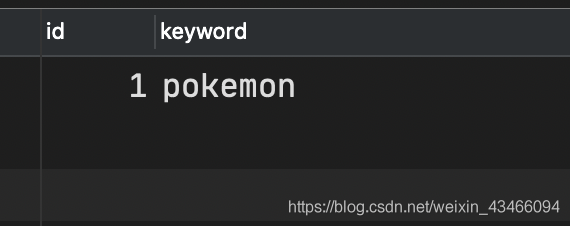
三、解決問題
檢視表結構發現,keyword欄位的排序規則為
utf8mb4_general_ci
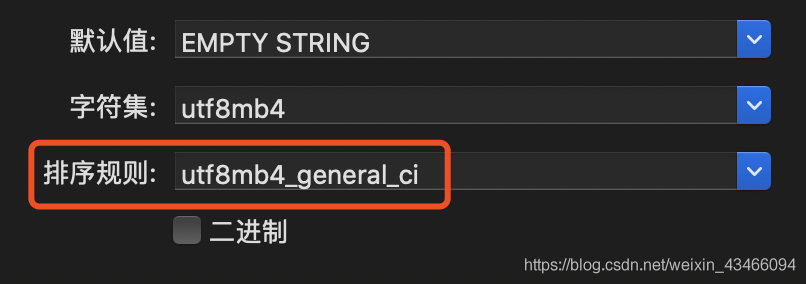
這種排序規則在識別é這種帶有音節的字元時,會識別為e,導致2個關鍵詞在通過INSERT IGNORE INTO匯入後只會有一條記錄,只要將排序規則改為
utf8mb4_bin
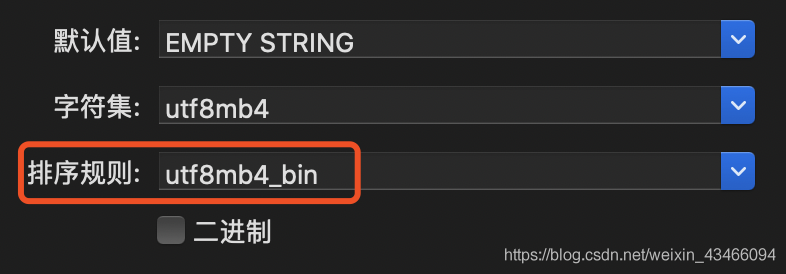
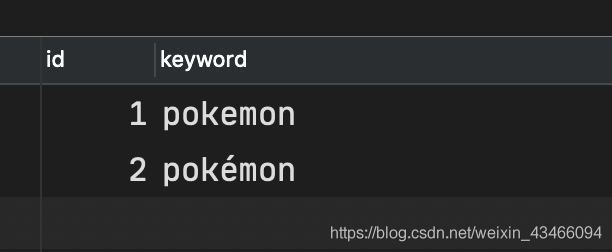
然後再重新匯入,檢視結果可發現2條資料都已經插入表中,問題解決。
總結
utf8mb4_bin是區分大小寫的,也區分e和é這類字元的
utf8_genera_ci是不區分大小寫的,也不區分e和é這類字元
注:utf8_general_cs是區分大小寫的,但不區分e和é這類字元
如果需要區分帶有音節的字元,又不想要區分大小寫,可在sql查詢對應欄位時用LOWER()函數