文章淺析-《Joint Deep Modeling of Users and Items Using Reviews for Recommendation》
文章淺析-《Joint Deep Modeling of Users and Items Using Reviews for Recommendation》
推薦系統論文閱讀筆記之《Joint Deep Modeling of Users and Items Using Reviews for Recommendation》
Introduction
推薦系統應用於眾多電商平臺,如不離手的抖音、百貨大樓淘寶、Amazon,甚至一些廣告、新聞推播等。簡言之,推薦即通過使用者的歷史互動資訊對使用者進行特徵建模,然後通過預測user對item的評分、點選概率、喜歡的可能排序等進行推薦。.
This paper
文章下載地址:https://arxiv.org/pdf/1701.04783.pdf
程式碼下載地址(非文章作者提供,碼友之作):https://github.com/zhaojinglong/DeepCoNN
Summary
現有的一些推薦演演算法主要考慮user-item的互動和評分情況,忽略了使用者的評論中包含了大量的資訊,它不僅可以提供附加資訊,還能潛在地緩解稀疏性問題,提高推薦的品質。在本文中,我們提出了一個基於CNN的深度學習的模型——DeepCoNN,通過user的所有評論資訊和item的所有被評論資訊來學習user和item的特徵表示,最後預測評分。
Contributions
1.提出DeepCoNN(名為:深度合作的神經網路),使用user reviews和item reviews對user和item屬性進行聯合建模(PS: 所謂聯合建模,就是使用提出的網路模型同時對user和item進行建模)。
2.使用pre-train好的模型對詞進行embedding,就是根據詞進行look-up操作,得到word-embedding矩陣。
3.在三個資料集上(Yelp、Amazon、Beer)實驗表明優於現有的演演算法。
Methods
DeepCoNN網路模型
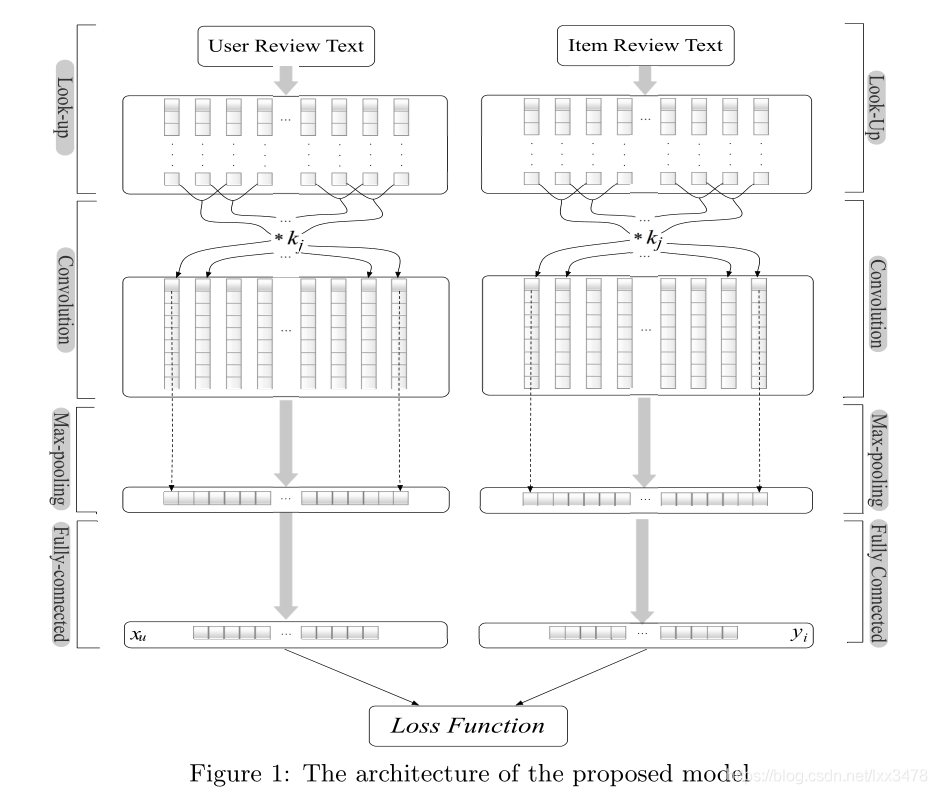
圖片來源:原文
由上圖可知,模型一共有三層(三層?明明是四層啊!~好,那就四層!說三層是因為把折積層和池化層合為折積網路,是一層。按圖,四層!)
下面,以學習user特徵為例,介紹模型各層……
第一層 look-up層
給不瞭解文書處理的小夥伴簡簡單單說一下蛤~
look-up翻譯過來就是查詢。
問: 去哪裡查什麼呢? 答: 去訓練好的詞嵌入矩陣查某個詞的詞向量。
再問: 為什麼要查呢?有詞不就好了嗎?再答: 不好!網路模型計算的是數位,不是詞,所以詞要轉化成數位!詞嵌入矩陣就是每個詞對應的數位形式,一般來講,一個詞對應一個向量,look-up之後的reviews就對應一個矩陣,因為一個review有很多詞鴨,呱呱呱~二、四、六、七、八……
反問: 懂了嗎?反答: 懂了!
好,Go on!
In the look-up layer, reviews are represented as a matrix of word embeddings to extract their semantic information. To achieve it, all the reviews written by user u, denoted as user reviews, are merged into a single document du1:n, consisting of n words in total. Then, a matrix of word vectors, denoted as V u1:n, is built for user u as follows:
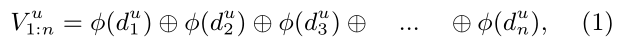
別看原文了,看中文吧:
把使用者的所有評論合成一條長評論,一共有n個單詞,對每個單詞進行look-up操作,再合起來就構成Vu1:n了。所謂的合起來就是把每個詞查得的vector按行排成矩陣,這個矩陣的行數就是這條評論詞的個數,列數就是每個詞向量的維度。
第二層 Convolution層
折積層,通過不同的折積核提取不同的特徵。
瞭解CNN的小夥伴就知道這個操作蛤~
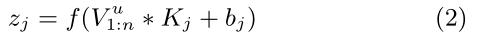
Vu1:n是使用者Uj的評論embedding,Kj是折積核,bj是偏置項。對於文字資料通常採用1d折積,Vu1:n折積之後對應圖中折積層的一個列向量,多個折積核輸出多個列向量。使用多個折積核的目的是提取多種特徵,一個折積核提取一種特徵,要問怎麼就提取特徵了?詳見CNN介紹蛤~
第三層 Max-pooling層
池化層,最大池化操作!

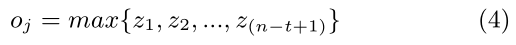
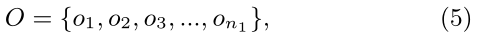
對每個折積核提取的特徵取最大值,即圖中從折積層的每一列取最大值組合起來得到池化層的一行。O是池化得到的向量,n1是折積核個數。
第四層 Fully-connected層
全連線層
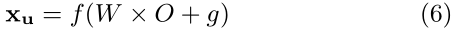
將得到的O輸進全連線層,xu即為學得的user特徵,f為啟用函數,W是權重矩陣,g是偏置項。
至此,模型介紹完畢!
???
別急,還有……
第四+1層 Factorization Machine層
為了將user特徵和item特徵對映到同一空間,引入因子分解機,一套行雲流水的常規操作,OK了!
Experiment
資料集:
1.Yelp: https://www.yelp.com/dataset-challenge
2.Amazon: https://snap.stanford.edu/data/web-Amazon.html
3.Beer
資料集情況分析:

詞embedding方式
使用訓練好的GoogleNews-vectors-negative300.bin進行look-up。
評價標準
Mean Square Error (MSE,均方誤差):
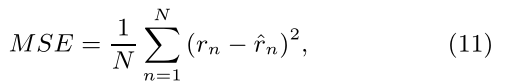
通常來講,預測評分的評價標準為MSE、RMSE,本文也不例外。
Baseline
讀者可以參見原文。
Result
讀者亦可以參見原文。
-----完結-----
???
文章讀完就完了嗎?!還要思考啊!
這篇文章發表於2017年ACM,時隔已久。可以看到,這篇文章的網路結構並不複雜,可以說是中規中矩,只不過是用到了評論資料作為附加資訊。近幾年,相關論文很多,用到的時間感知、內容感知、LSTM、注意力機制等都可以考慮到網路結構中。以上!
謝謝惠顧!哈哈哈哈哈~