【專案實戰】基於Yolov5 火災濃煙檢測與天池免費算力的教學篇
免費算力,白嫖黨頂級薅羊毛!
愁筆電差,又買不起桌上型電腦顯示卡的同學,請注意啦!今天cv調包俠分享一下自己這幾天開始使用的阿里天池的免費GPU伺服器,以及這篇文章介紹如何在天池的tesla p100 16gb視訊記憶體的伺服器上訓練自己的深度學習視覺模型~我們以火災濃煙檢測為例子。
首先,大家可以看我Yolov5 吸菸檢測文章與baseline,傳送門,今天主要與大家分享一下國慶好禮~
國慶這幾天呆在家裡,可不能白費了,花點時間鑽研一下新東西,我這幾天嘗試了百度AIstudio,Kaggle ,天池三個平臺的免費算力,百度的大家都比較熟悉了,可惜小菜雞不會paddle,又想跑自己的大模型,怎麼辦,怎麼辦,怎麼辦???
| 平臺\ 資訊 | 顯示卡 | 視訊記憶體 |
|---|---|---|
| 百度AIstudio | Nvidia Teslav100 | 16GB |
| 阿里 天池 | Nvidia Teslap100 | 16GB |
| Kaggle | Tesla K80 | 12GB |
算力來說,百度的較好~,但是對於我們想用pytorch 和tensorflow ,以及Paddle還沒入門的孩子來說,就建議來薅阿里天池的羊毛!因為Kaggle 速度很慢。
回到正題
一 阿里天池的使用篇
首先註冊並進入阿里雲實驗室。
2、如何安裝、解除安裝、更新包?如遇錯誤怎麼辦?
1)安裝包:pip install some_package --user
2)解除安裝包:部分包有依賴,無法解除安裝
3)更新包:pip install -U some_package –user
如果匯入過程出錯,建議嘗試重新啟動kernel或重新整理頁面
3、如何切換GPU和CPU?
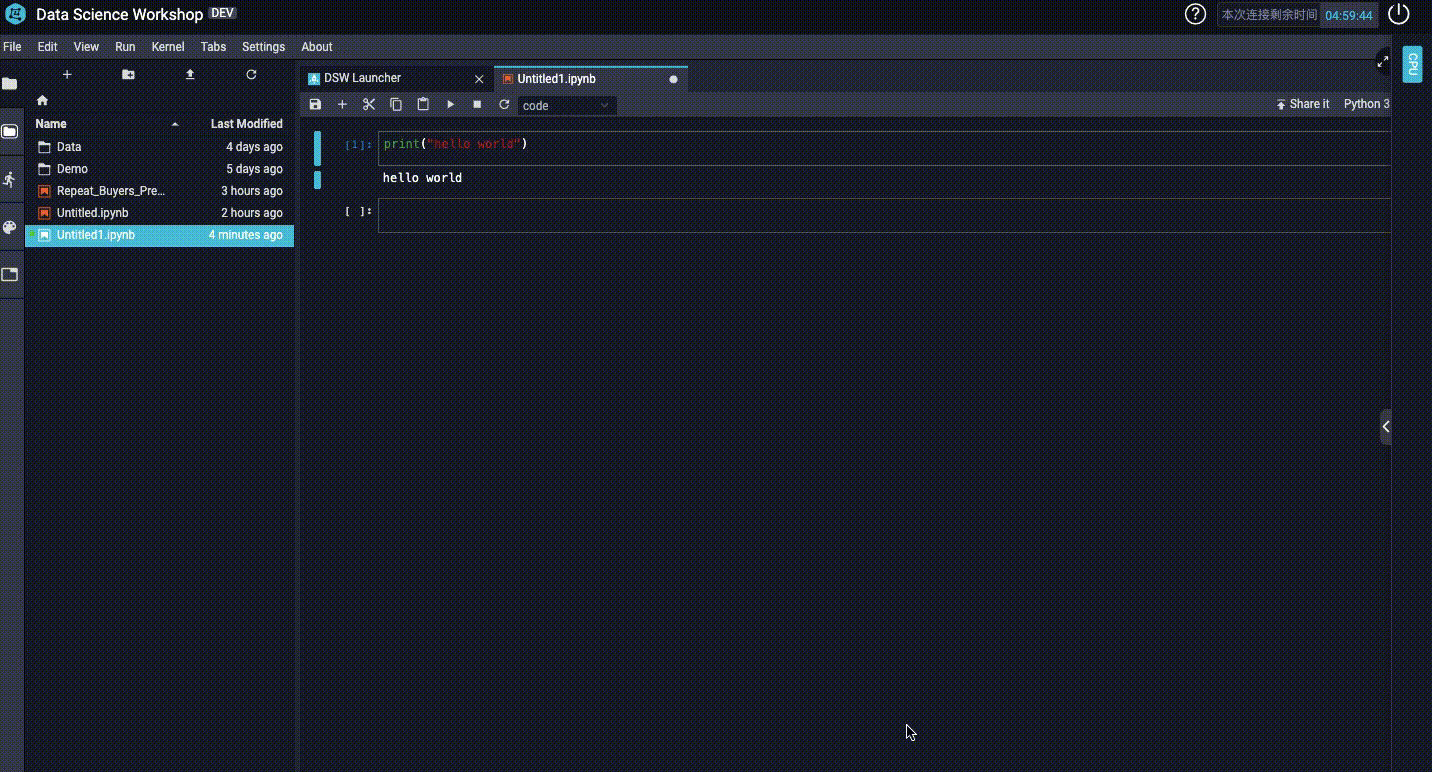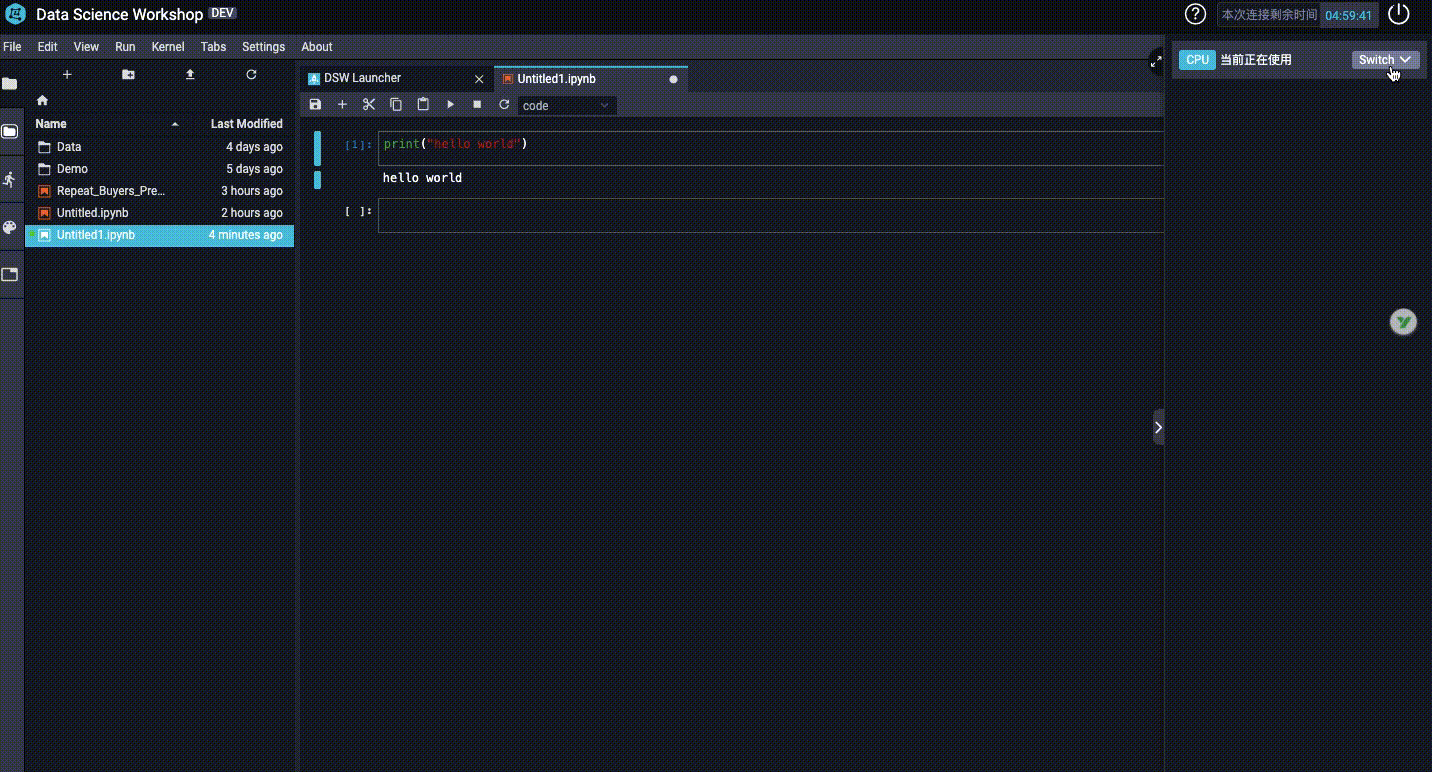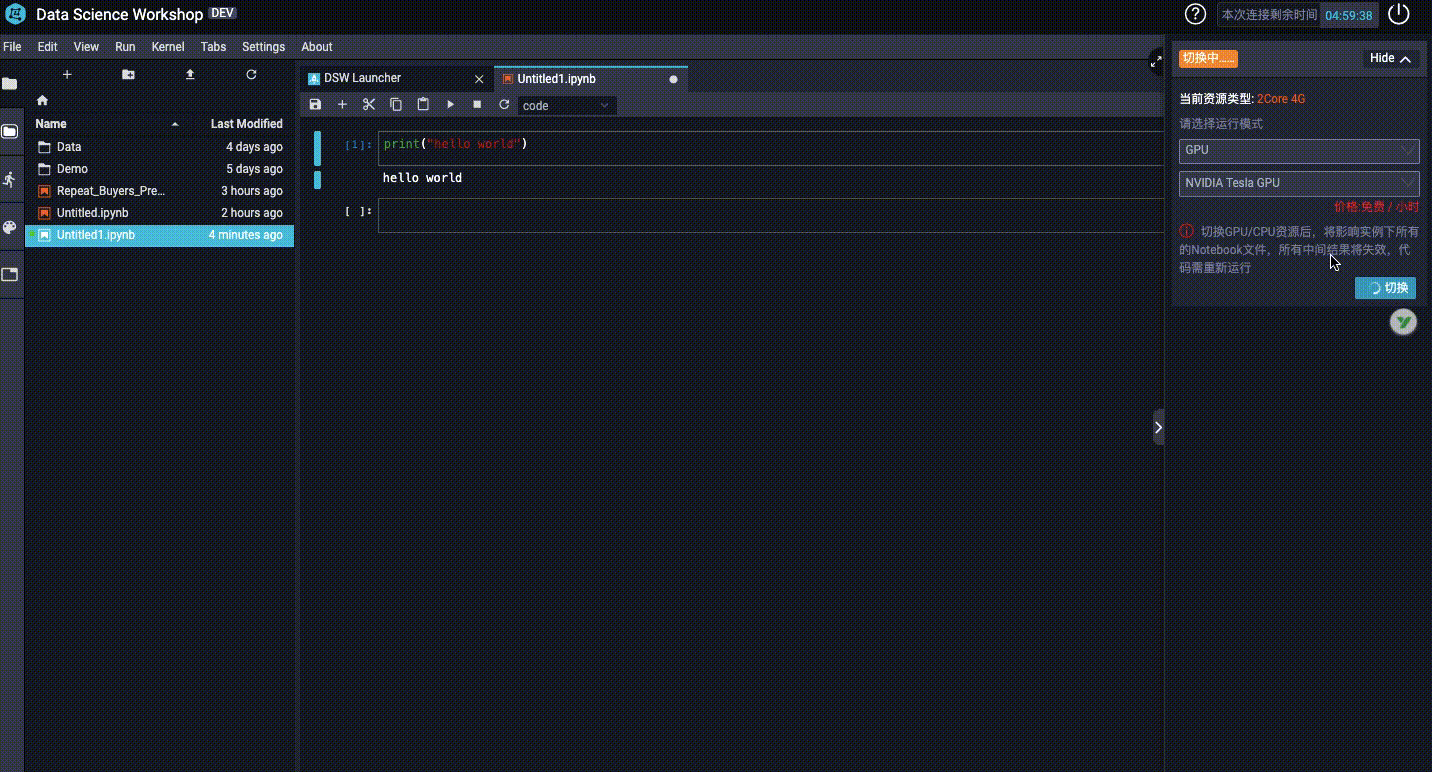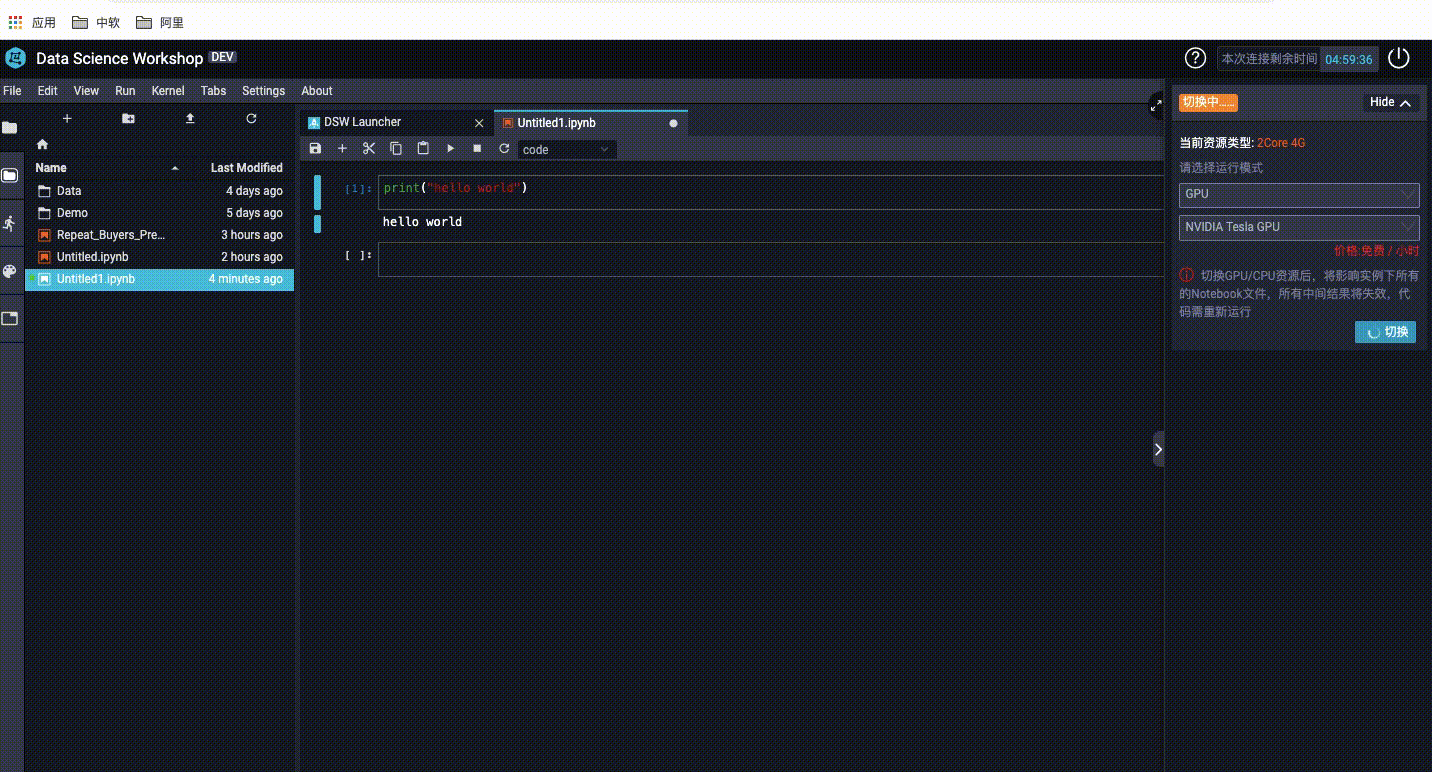
二 開啟我們在天池伺服器的第一個專案: 火災濃煙與吸菸檢測
2.1 演示
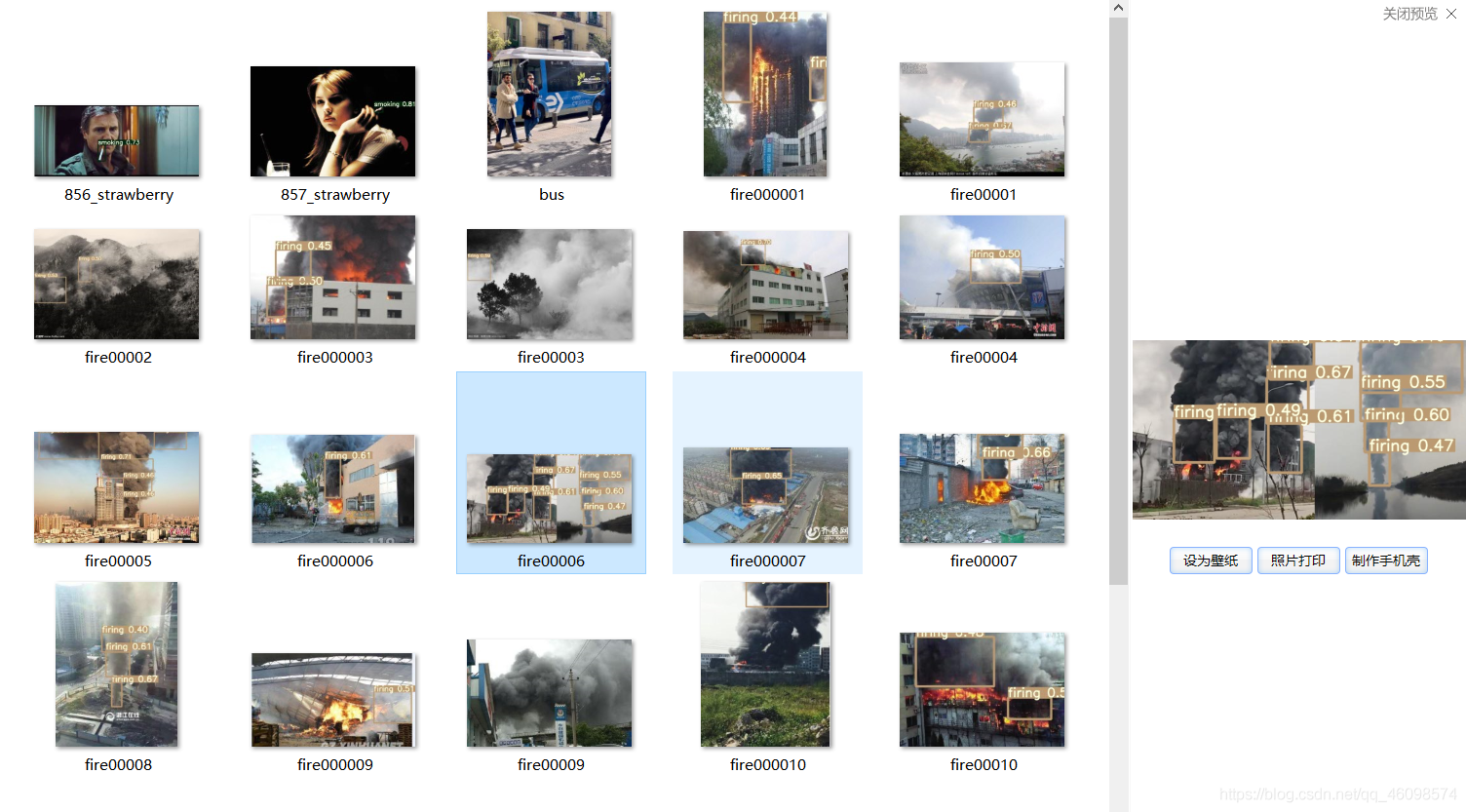





2.2 介紹
本專案為基礎baseline ,資料為5000的香菸圖片與3000的火災圖片,為兩類別檢測(因為後續需要做校園等場景異常行為監控,所以將以前的吸菸檢測也加入進來了);
圖片如下(已放至公眾號:Deep AI 視界 公眾號回覆:火災檢測):

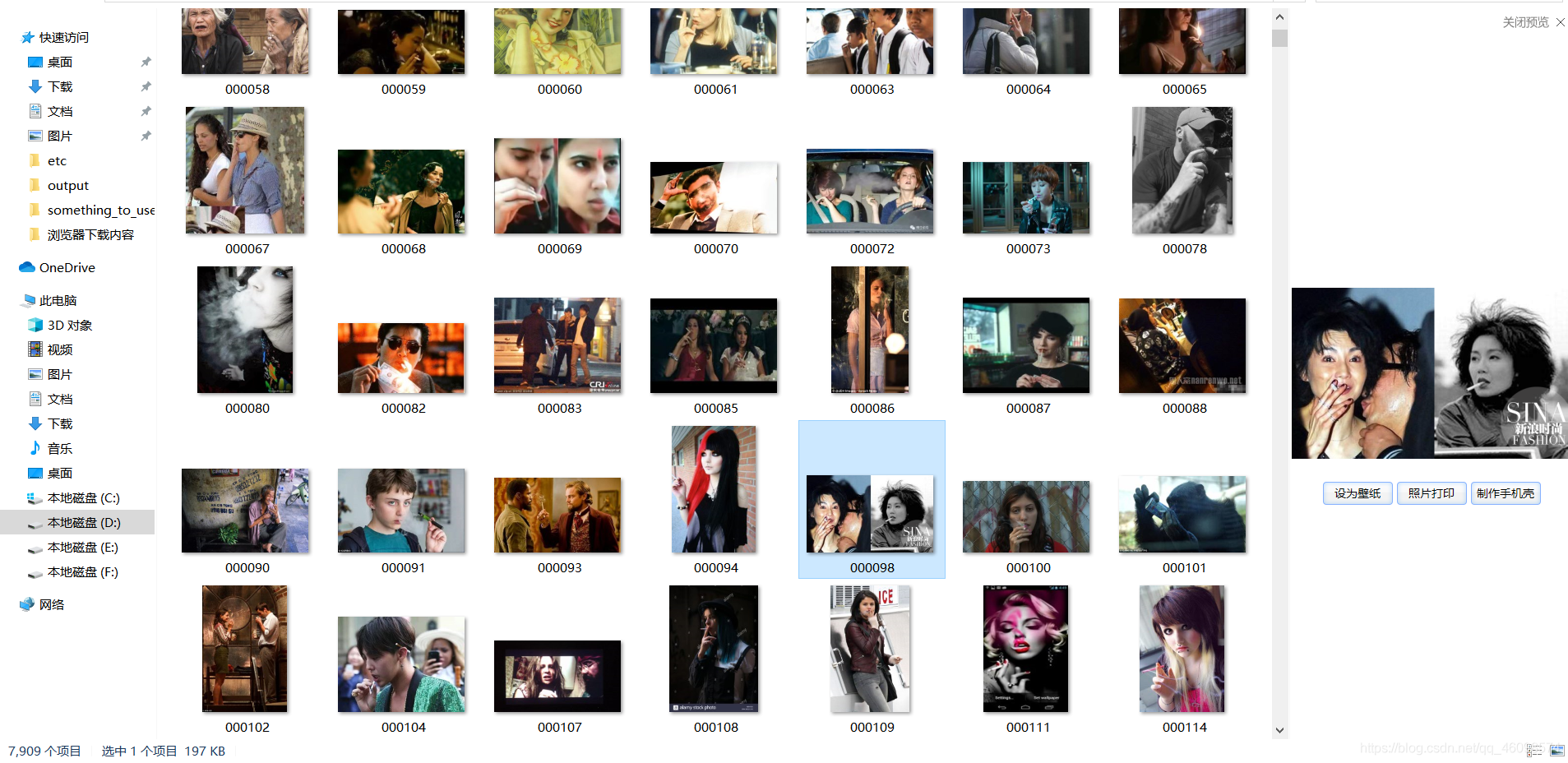
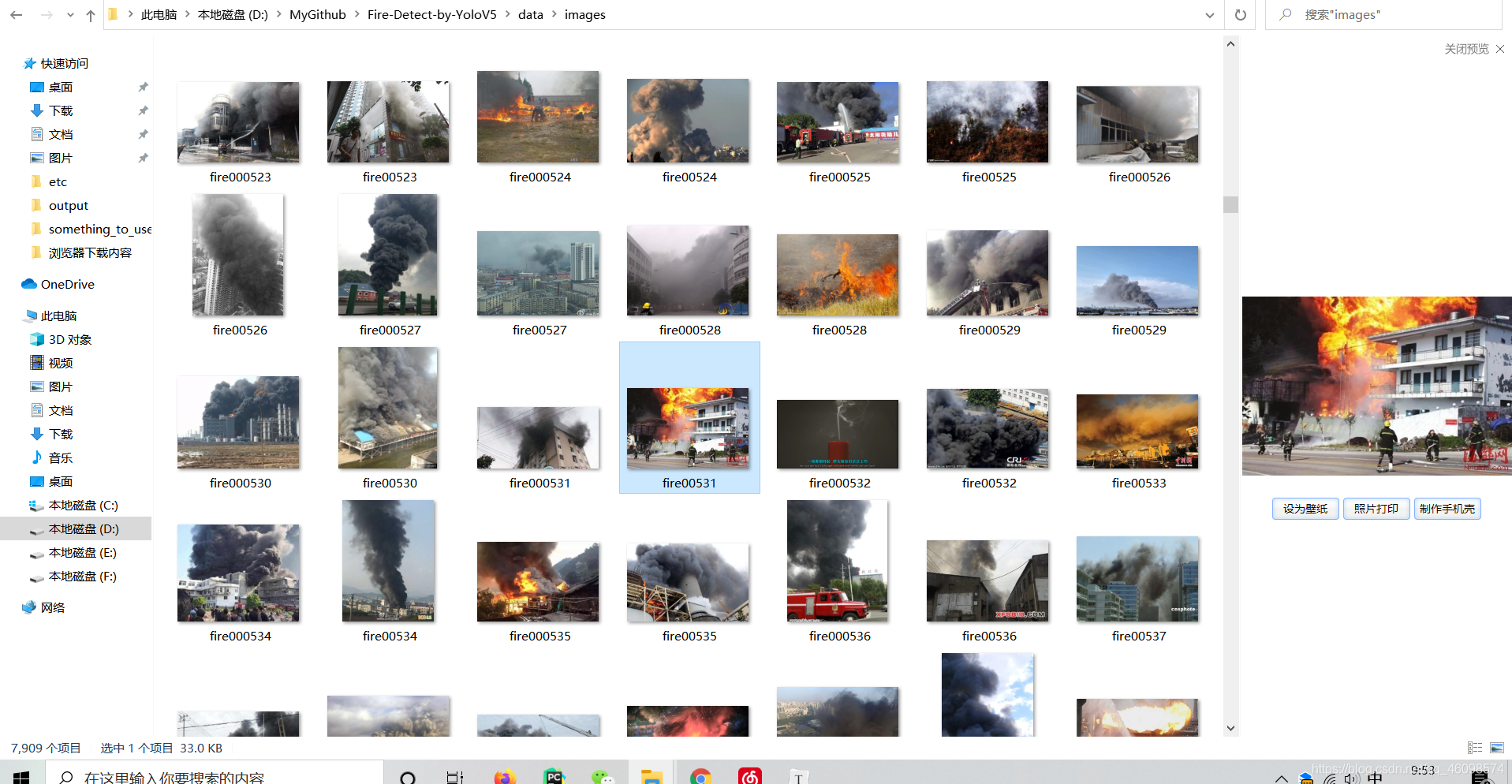
三 模型訓練
先clone 我的專案:https://github.com/CVUsers/Fire-Detect-by-YoloV5(歡迎star~)
或者 git clone https://github.com/CVUsers/Fire-Detect-by-YoloV5.git
到本地進行偵錯,跑通後再放到阿里雲伺服器加大模型直接跑~
然後公眾號 DeepAI 視界回覆:火災檢測
會拿到一份8000張左右的圖片images.7z
解壓到data下,data下的目錄應為:
![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片儲存下來直接上傳(img-VBfQt1tS-1601784638378)(D:\CSDN\pic\天池\1601776984096.png)]](https://s3.ap-northeast-1.wasabisys.com/img.tw511.com/202010/20201004121601728fq5wuyhicno.png)
其中,train.txt ,labels,test.txt我已經給您寫好,不用重新制作資料,若是需要重新制作資料,請參考我的另一篇文章:
令將yolov5預訓練模型放至weights/下(我的網路硬碟有)
需要注意的有幾點:
1:labels中名字要與images中的圖片名字對應(字尾不同),且要歸一化成:id, x,y,w,h;
2:修改data下的smoke.yaml 為如下(已為您修改)
![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片儲存下來直接上傳(img-8Ne93a96-1601784638379)(D:\CSDN\pic\天池\1601777255275.png)]](https://s3.ap-northeast-1.wasabisys.com/img.tw511.com/202010/20201004121632231rqupk143coz.png)
3:修改models/ yolov5x.yaml 中的類別為你的類別(已為您修改);
4:train的args修改batchsize等引數
四 天池端訓練
tips:您可以用小模型yolov5s進行測試,跑一個迭代沒問題後,就可以改成yolov5x ;
然後將整個專案壓縮成壓縮包,進入阿里實驗室,開啟notebook,點選上傳檔案:
![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片儲存下來直接上傳(img-R0YZYCCl-1601784638381)(D:\CSDN\pic\天池\1601778097520.png)]](https://s3.ap-northeast-1.wasabisys.com/img.tw511.com/202010/20201004121648173my1urzhahce.png)
然後在notebook右側改成使用gpu:
![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片儲存下來直接上傳(img-BIrVkCmS-1601784638385)(D:\CSDN\pic\天池\1601778143859.png)]](https://s3.ap-northeast-1.wasabisys.com/img.tw511.com/202010/20201004121705675ynt1iawbqvn.png)
檢測是否為gpu環境:notebook左側+號,新建一個terminal,輸入nvidia-smi即可,若顯示16gb就是gpu環境,如是cpu環境,會顯示command not found
tips:若是由於自己操作失誤,gpu被程式誤佔滿,停不下來,就在終端輸入 fuser -v .dev/nvidia* 看到佔用顯示卡的程序,然後kill 掉他的編號即可
現在開始解壓壓縮包,我是7z壓縮包(其他壓縮包命令請自查):
notebook中輸入:
!pip install py7zr
a = py7zr.SevenZipFile('./Fire-Detect-by-YoloV5','r')
a.extractall(path=r'./')
a.close()
print('over')
等待over(可能需要一些時間)後,雙擊解壓好的資料夾進入專案
![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片儲存下來直接上傳(img-ucfD6SpJ-1601784638388)(D:\CSDN\pic\天池\1601778826053.png)]](https://s3.ap-northeast-1.wasabisys.com/img.tw511.com/202010/20201004121738792eadfqesdlxw.png)
你可以左上角➕加號,新建python3的ipynb檔案,然後輸入:
%load train.py
Tips 此時,將main中的一行修改一下(因為是notebook版的引數解析方式):
opt = parser.parse_args()改成
opt = parser.parse_known_args()[0]
當前的pytorch版本是符合我們專案要求的,你需要安裝一個opencv-python
終端輸入:
pip install opencv-python==3.4.2.17
然後在我們的train.py 程式碼上按下shift+enter執行這個指令碼,即可:
![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片儲存下來直接上傳(img-kUIdBpOW-1601784638389)(D:\CSDN\pic\天池\1601779323817.png)]](https://s3.ap-northeast-1.wasabisys.com/img.tw511.com/202010/20201004121801797emd2xxzpq4l.png)
此圖中,可看到模型引數分佈與維度;一共是8.8*10^7次方引數
![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片儲存下來直接上傳(img-hkqpIIKG-1601784638396)(D:\CSDN\pic\天池\1601779473179.png)]](https://s3.ap-northeast-1.wasabisys.com/img.tw511.com/202010/20201004121817749nrcfczxaons.png)
等待訓練結束,同時會將模型儲存在weights/下
Tips:如果8小時的時長不夠用,8小時後停止了迭代,那就重新啟動範例,並修改train.py 的args中為:
–resume 這一行加一個default = True,將–weights的模型改成weights/last.pt ,然後執行
你就會發現,會繼續原有模型訓練~
然後訓練結束後,將模型中的best.pt 右鍵download到本地(在雲端測試也行,不過雲端不能開攝像頭,可以測試圖片和視訊),我以本地為例,將best.pt放到原生的weights/下,將detect.py 的引數:–source 改成0 執行即可。
if __name__ == '__main__':
check_git_status()
parser = argparse.ArgumentParser()
parser.add_argument('--cfg', type=str, default='models/yolov5s.yaml', help='model.yaml path')
parser.add_argument('--data', type=str, default='data/coco128.yaml', help='data.yaml path')
parser.add_argument('--hyp', type=str, default='', help='hyp.yaml path (optional)')
parser.add_argument('--epochs', type=int, default=300)
parser.add_argument('--batch-size', type=int, default=16)
parser.add_argument('--img-size', nargs='+', type=int, default=[640, 640], help='train,test sizes')
parser.add_argument('--rect', action='store_true', help='rectangular training')
parser.add_argument('--resume', nargs='?', const='get_last', default=False,
help='resume from given path/to/last.pt, or most recent run if blank.')
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
parser.add_argument('--notest', action='store_true', help='only test final epoch')
parser.add_argument('--noautoanchor', action='store_true', help='disable autoanchor check')
parser.add_argument('--evolve', action='store_true', help='evolve hyperparameters')
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
parser.add_argument('--cache-images', action='store_true', help='cache images for faster training')
parser.add_argument('--weights', type=str, default='', help='initial weights path')
parser.add_argument('--name', default='', help='renames results.txt to results_name.txt if supplied')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
parser.add_argument('--single-cls', action='store_true', help='train as single-class dataset')
opt = parser.parse_args()
cfg,data,weights:前面看過了是一定要傳的兩個參;
hyp:超引數,是指定一些超引數用的(學習率啥的);
epochs: 輪數,預設300,需要指定;
batch-size:一次喂多少資料,yolov5x 16gb視訊記憶體,資料量大隻能開到12,所以可以不傳按預設16;
img-size: 訓練和測試資料集的圖片尺寸(個人理解為解析度),預設640,640nargs='+' 表示引數可設定一個或多個;
rect: 只要加上’–rect’程式就會將rect設為true(應該是訓練時啟用矩形訓練);
resume: 斷開後繼續原有last.pt訓練;
notest:only test final epoch,僅在最後測試,節省時間與資源(這樣訓練中間變化趨勢應該就看不到了);
evolve:進化超引數(hyp),可以試試,但是加了這個,原始碼那邊就不建議每次迭代完都儲存模型了,可能是最後儲存;
cache-images:cache images for faster training,加快訓練的,可以試試;
name:renames results.txt to results_name.txt if supplied;
device:cuda device, i.e. 0 or 0,1,2,3 or cpu,我這預設已經用了tesla p100了,不用改;
single-cls:train as single-class dataset,暫時沒用;
解釋一下result.png裡都是啥:
![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片儲存下來直接上傳(img-6Z2adUS9-1601784638398)(D:\CSDN\pic\天池\1601781211748.png)]](https://s3.ap-northeast-1.wasabisys.com/img.tw511.com/202010/20201004121834360ql2zdsbv0xo.png)
- GIoU:推測為GIoU損失函數均值,越小方框越準;
- Objectness:推測為目標檢測loss均值,越小目標檢測越準;
- Classification:推測為分類loss均值,越小分類越準;
- Precision:準確率(找對的/找到的);
- Recall:召回率(找對的/該找對的);
- mAP@0.5 & mAP@0.5:0.95:這裡說的挺好,總之就是AP是用Precision和Recall作為兩軸作圖後圍成的面積,m表示平均,@後面的數表示判定iou為正負樣本的閾值,@0.5:0.95表示閾值取0.5:0.05:0.95後取均值。
![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片儲存下來直接上傳(img-vNKqqNRV-1601784638399)(D:\CSDN\pic\天池\1601784586318.png)]](https://s3.ap-northeast-1.wasabisys.com/img.tw511.com/202010/20201004121901304jzxghda5tiy.png)
五 總結與技巧
總的來說,這阿里天池的伺服器比較方便,網路速度也可以。
我已經準備長期入駐阿里雲天池實驗室,為以後去達摩院掃地做鋪墊–_--,叫:cv調包俠,歡迎來fork~
總結一下上文的所有tips:
敲黑板:
tips:您可以用小模型yolov5s進行測試,跑一個迭代沒問題後,就可以改成yolov5x放到伺服器訓練 ;
tips:若是由於自己操作失誤,gpu被程式誤佔滿,停不下來,就在終端輸入 fuser -v .dev/nvidia* 看到佔用顯示卡的程序,然後kill 掉他的編號即可
tips:引數解析要修改如下:
opt = parser.parse_args()改成
opt = parser.parse_known_args()[0]
Tips:如果8小時的時長不夠用,8小時後停止了迭代,那就重新啟動範例,並修改train.py 的args中為:
--resume 這一行加一個default = True,將--weights的模型改成weights/last.pt ,然後執行
你就會發現,會繼續原有模型訓練~
tips:可以開多個賬號,在其他瀏覽器的頁面上訓練其他模型。
六 總結
歡迎關注個人公眾號:DeepAI 視界 公眾號回覆火災檢測有好禮喲~
