如何基於HBase構建容納大規模資料、支撐高並行、毫秒響應、穩定高效的OLTP實時系統
前言
本文致力於從架構原理、叢集部署、效能優化與使用技巧等方面,闡述在如何基於HBase構建容納大規模資料、支撐高並行、毫秒響應、穩定高效的OLTP實時系統 。
一、架構原理
1.1 基本架構

從上層往下可以看到HBase架構中的角色分配為:
Client——>Zookeeper——>HMaster——>RegionServer——>HDFS
Client
Client是執行查詢、寫入等對HBase表資料進行增刪改查的使用方,可以是使用HBase Client API編寫的程式,也可以是其他開發好的HBase使用者端應用。
Zookeeper
Zookeeper同HDFS一樣,HBase使用Zookeeper作為叢集協調與管理系統。
在HBase中其主要的功能與職責為:
- 儲存整個叢集HMaster與RegionServer的執行狀態
- 實現HMaster的故障恢復與自動切換
- 為Client提供後設資料表的儲存資訊
- HMaster、RegionServer啟動之後,將會在Zookeeper上註冊並建立節點(/hbasae/master 與 /hbase/rs/*),同時 Zookeeper 通過Heartbeat的心跳機制來維護與監控節點狀態,一旦節點丟失心跳,則認為該節點宕機或者下線,將清除該節點在Zookeeper中的註冊資訊。
- 當Zookeeper中任一RegionServer節點狀態發生變化時,HMaster都會收到通知,並作出相應處理,例如RegionServer宕機,HMaster重新分配Regions至其他RegionServer,以保證叢集整體可用性。
- 當HMaster宕機時(Zookeeper監測到心跳超時),Zookeeper中的 /hbasae/master 節點將會消失,同時Zookeeper通知其他備用HMaster節點,重新建立 /hbasae/master 並轉化為active master。
協調過程示意圖如下:

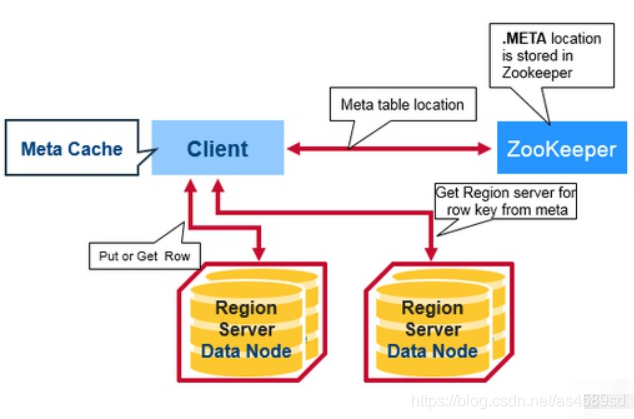
除了作為叢集中的協調者,Zookeeper還為Client提供了 hbase:meta 表的儲存資訊。
使用者端要存取HBase中的資料,只需要知道Zookeeper叢集的連線資訊,存取步驟如下:
- 使用者端將從Zookeeper(/hbase/meta-region-server)獲得 hbase:meta 表儲存在哪個RegionServer,快取該位置資訊
- 查詢該RegionServer上的 hbase:meta 表資料,查詢要操作的 rowkey所在的Region儲存在哪個RegionServer中,快取該位置資訊
- 在具體的RegionServer上,根據rowkey檢索該Region資料
可以看到,使用者端運算元據過程並不需要HMaster的參與,通過Zookeeper間接存取RegionServer來運算元據。
第一次請求將會產生3次RPC,之後使用相同的rowkey時,使用者端將直接使用快取下來的位置資訊,直接存取RegionServer,直至快取失效(Region失效、遷移等原因)。
通過Zookeeper的讀寫流程如下:
hbase:meta 表儲存了叢集中所有Region的位置資訊。
表結構如下:

| rowkey規則:${表名},${起始鍵},${region時間戳}.${encode編碼}. |
| 列簇:info |
| 列 |
| state:Region狀態,正常情況下為 OPEN |
| serverstartcode:RegionServer啟動的13位時間戳 |
| server:所在RegionServer 地址和埠,如cdh85-47:16020 |
| sn:server和serverstartcode組成,如cdh85-47:16020,1549491783878 |
| seqnumDuringOpen:Region線上時長的二進位制串 |
| regioninfo:region的詳細資訊,如:ENCODED、NAME、STARTKEY、ENDKEY等 |
| ENCODED:基於${表名},${起始鍵},${region時間戳}生成的32位元md5字串, region資料儲存在hdfs上時使用的唯一編號,可以從meta表中根據該值定位到hdfs中的具體路徑。 rowkey中最後的${encode編碼}就是 ENCODED 的值,其是rowkey組成的一部分。 |
| NAME:與ROWKEY值相同 |
| STARTKEY:該region的起始鍵 |
| ENDKEY:該region的結束鍵 |
簡單總結Zookeeper在HBase叢集中的作用如下:
- 對於伺服器端,是實現叢集協調與控制的重要依賴。
- 對於使用者端,是查詢與運算元據必不可少的一部分。
HMaster

- HBase整體架構中HMaster的功能與職責如下:
- 管理RegionServer,監聽其狀態,保證叢集負載均衡且高可用。
- 管理Region,如新Region的分配、RegionServer宕機時該節點Region的分配與遷移
- 接收使用者端的DDL操作,如建立與刪除表、列簇等資訊
- 許可權控制
如我們前面所說的,HMaster 通過 Zookeeper 實現對叢集中,各個 RegionServer 的監控與管理,在RegionServer 發生故障時,可以發現節點宕機,並轉移 Region 至其他節點,以保證服務的可用性。
但是HBase的故障轉移並不是無感知的,相反故障轉移過程中,可能會直接影響到線上請求的穩定性,造成段時間內的大量延遲。
在分散式系統的 CAP定理中(Consistency一致性、Availability可用性、Partition tolerance分割區容錯性),分散式資料庫基本特性都會實現P,但是不同的資料庫對於A和C各有取捨。
如HBase選擇了C,而通過Zookeeper這種方式來輔助實現A(雖然會有一定缺陷),而Cassandra選擇了A,通過其他輔助措施實現了C,各有優劣。
對於HBase叢集來說,HMaster是一個內部管理者,除了DDL操作並不對外(使用者端)開放,因而HMaster的負載是比較低的。
造成HMaster壓力大的情況,可能是叢集中存在多個(兩個或者三個以上)HMaster,備用的Master會定期與Active Master通訊,以獲取最新的狀態資訊,以保證故障切換時自身的資料狀態是最新的,因而Active Master可能會收到大量來自備用Master的資料請求。
RegionServer
RegionServer在HBase叢集中的功能與職責:
- 根據HMaster的region分配請求,存放和管理Region
- 接受使用者端的讀寫請求,檢索與寫入資料,產生大量IO
- 一個RegionServer中儲存並管理者多個Region,是HBase叢集中真正 儲存資料、接受讀寫請求 的地方,是HBase架構中最核心、同時也是最複雜的部分。
RegionServer內部結構圖如下:

BlockCache
BlockCache為RegionServer中的讀快取,一個RegionServer共用一個BlockCache。
RegionServer處理使用者端讀請求的過程:
- 在BlockCache中查詢是否命中快取。
- 快取未命中,則定位到儲存該資料的Region。
- 檢索Region Memstore中,是否有所需要的資料。
- Memstore中未查得,則檢索Hfiles。
- 任一過程查詢成功,則將資料返回給使用者端,並快取至BlockCache。
BlockCache有兩種實現方式,有不同的應用場景,各有優劣:
- On-Heap的LRUBlockCache
- 優點:直接從Java堆內記憶體獲取,響應速度快。
- 缺陷:容易受GC影響,響應延遲不穩定,特別是在堆記憶體巨大的情況下。
- 適用於:寫多讀少型、小記憶體等場景。
- Off-Heap的BucketCache
- 優點:無GC影響,延遲穩定
- 缺陷:從堆外記憶體獲取資料,效能略差於堆內記憶體
- 適用於:讀多寫少型、大記憶體等場景
我們將在「效能優化」一節中具體討論如何判斷應該使用哪種記憶體模式。
WAL
全稱 Write Ahead Log ,是 RegionServer 中的預寫紀錄檔。
所有寫入資料,預設情況下,都會先寫入WAL中,以保證RegionServer宕機重新啟動之後,可以通過WAL來恢復資料,一個RegionServer中共用一個WAL。
RegionServer的寫流程如下:
- 將資料寫入WAL中
- 根據TableName、Rowkey和ColumnFamily將資料寫入對應的Memstore中
- Memstore通過特定演演算法將記憶體中的資料刷寫成Storefile寫入磁碟,並標記WAL sequence值
- Storefile定期合小檔案
WAL會通過紀錄檔卷動的操作,定期對紀錄檔檔案進行清理(已寫入HFile中的資料可以清除),對應HDFS上的儲存路徑為 /hbase/WALs/${HRegionServer_Name} 。
Region
一個Table由一個或者多個Region組成,一個Region中可以看成是Table按行切分且有序的資料塊,每個Region都有自身的StartKey、EndKey。
一個Region由一個或者多個Store組成,每個Store儲存該Table對應Region中一個列簇的資料,相同列簇的列,儲存在同一個Store中。
同一個Table的Region,會分佈在叢集中不同的RegionServer上,以實現讀寫請求的負載均衡。故,一個RegionServer中,將會儲存來自不同Table的N多個Region。
Store、Region與Table的關係可以表述如下:多個Store(列簇)組成Region,多個Region(行資料塊)組成完整的Table。
其中,Store由Memstore(記憶體)、StoreFile(磁碟)兩部分組成。
在RegionServer中,Memstore可以看成指定Table、Region、Store的寫快取(正如BlockCache小節中所述,Memstore還承載了一些讀快取的功能),以RowKey、Column Family、Column、Timestamp進行排序。如下圖所示:
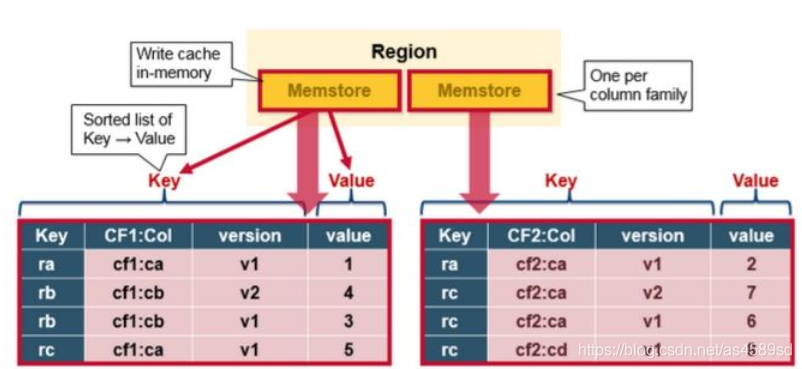
寫請求到RegionServer之後,並沒有立刻寫入磁碟中,而是先寫入記憶體中的Memstore(記憶體中資料丟失問題,可以通過回放WAL解決)以提升寫入效能。
Region中的Memstore,會根據特定演演算法,將記憶體中的資料,將會刷寫到磁碟,形成Storefile檔案,因為資料在Memstore中為已排序,順序寫入磁碟效能高、速度快。
在這種 Log-Structured Merge Tree架構模式下,隨機寫入HBase擁有相當高的效能。
Memstore刷磁碟形成的StoreFile,以HFile格式,儲存HBase的KV資料於HDFS之上。
HDFS
HDFS為HBase提供底層儲存系統,通過HDFS的高可用、高可靠等特性,保障了HBase的資料安全、容災與備份。
1.2寫資料 與 Memstore Flush
對於使用者端來說,將請求傳送到需要寫入的RegionServer中,等待RegionServer寫入WAL、Memstore之後,即返回寫入成功的ack訊號。
對於RegionServer來說,寫入的資料,還需要經過一系列的處理步驟。
首先我們知道Memstore是在記憶體中的,將資料放在記憶體中,可以得到優異的讀寫效能,但是同樣也會帶來麻煩:
- 記憶體中的資料如何防止斷電丟失
- 將資料儲存於記憶體中的代價是高昂的,空間總是有限的
對於第一個問題,雖然可以通過WAL機制在重新啟動的時候,進行資料回放,但是對於第二個問題,則必須將記憶體中的資料持久化到磁碟中。
在不同情況下,RegionServer通過不同級別的刷寫策略,對Memstore中的資料進行持久化,根據觸發刷寫動作的時機,以及影響範圍,可以分為不同的幾個級別:
- Memstore級別:Region中任意一個MemStore達到了 hbase.hregion.memstore.flush.size 控制的上限(預設128MB),會觸發Memstore的flush。
- Region級別:Region中Memstore大小之和達到了 hbase.hregion.memstore.block.multiplier *, hbase.hregion.memstore.flush.size 控制的上限(預設 2 * 128M = 256M),會觸發Memstore的flush。
- RegionServer級別:Region Server中所有Region的Memstore大小總和達到了 hbase.regionserver.global.memstore.upperLimit * hbase_heapsize 控制的上限(預設0.4,即RegionServer 40%的JVM記憶體),將會按Memstore由大到小進行flush,直至總體Memstore記憶體使用量低於 hbase.regionserver.global.memstore.lowerLimit * hbase_heapsize 控制的下限(預設0.38, 即RegionServer 38%的JVM記憶體)。
- RegionServer中HLog數量達到上限:將會選取最早的 HLog對應的一個或多個Region進行flush(通過引數hbase.regionserver.maxlogs設定)。
- HBase定期flush:確保Memstore不會長時間沒有持久化,預設週期為1小時。為避免所有的MemStore,在同一時間都進行flush導致的問題,定期的flush操作,有20000左右的隨機延時。
- 手動執行flush:使用者可以通過shell命令 flush ‘tablename’或者flush ‘region name’,分別對一個表或者一個Region進行flush。
Memstore刷寫時,會阻塞線上的請求響應,由此可以看到,不同級別的刷寫,對線上的請求,會造成不同程度影響的延遲:
- 對於Memstore與Region級別的刷寫,速度是比較快的,並不會對線上造成太大影響
- 對於RegionServer級別的刷寫,將會阻塞傳送到該RegionServer上的所有請求,直至Memstore刷寫完畢,會產生較大影響
所以在Memstore的刷寫方面,需要儘量避免出現RegionServer級別的刷寫動作。
資料在經過Memstore刷寫到磁碟時,對應的會寫入WAL sequence的相關資訊,已經持久化到磁碟的資料,就沒有必要通過WAL記錄的必要。
RegionServer會根據這個sequence值,對WAL紀錄檔進行卷動清理,防止WAL紀錄檔數量太多,RegionServer啟動時,載入太多資料資訊。
同樣,在Memstore的刷寫策略中,可以看到,為了防止WAL紀錄檔數量太多,達到指定閾值之後,將會選擇WAL記錄中,最早的一個或者多個Region進行刷寫。
1.3讀資料 與 Bloom Filter
經過前文的瞭解,我們現在可以知道HBase中一條資料完整的讀取操作流程中,Client會和Zookeeper、RegionServer等發生多次互動請求。
基於HBase的架構,一條資料可能存在RegionServer中的三個不同位置:
- 對於剛讀取過的資料,將會被快取到BlockCache中
- 對於剛寫入的資料,其存在Memstore中
- 對於之前已經從Memstore刷寫到磁碟的,其存在於HFiles中
RegionServer接收到的一條資料查詢請求,只需要從以上三個地方,檢索到資料即可。
在HBase中的檢索順序依次是:BlockCache -> Memstore -> HFiles。
其中,BlockCache、Memstore都是直接在記憶體中進行高效能的資料檢索。
而HFiles則是真正儲存在HDFS上的資料:
- 檢索HFiles時會產生真實磁碟的IO操作
- Memstore不停刷寫的過程中,將會產生大量的HFile
如何在大量的HFile中快速找到所需要的資料呢?
為了提高檢索HFiles的效能,HBase支援使用 Bloom Fliter 對HFiles進行快讀定位。
Bloom Filter(布隆過濾器)是一種資料結構,常用於大規模資料查詢場景,其能夠快速判斷一個元素一定不在集合中,或者可能在集合中。
Bloom Filter由 一個長度為m的位陣列 和 k個雜湊函數 組成。
其工作原理如下:
- 原始集合寫入一個元素時,Bloom Filter同時將該元素 經過k個雜湊函數對映成k個數位,並以這些數位為下標,將 位陣列 中對應下標的元素標記為1
- 當需要判斷一個元素是否存在於原始集合中,只需要將該元素經過同樣的 k個雜湊函數得到k個數位
- 取 位陣列 中對應下標的元素,如果都為1,則表示元素可能存在
- 如果存在其中一個元素為0,則該元素不可能存在於原始集合中
- 因為雜湊碰撞問題,不同的元素經過相同的雜湊函數之後可能得到相同的值
- 對於集合外的一個元素,如果經過 k個函數得到的k個數位,對應位陣列中的元素都為1,可能是該元素存在於集合中
- 也有可能是集合中的其他元素」碰巧「讓這些下標對應的元素都標記為1,所以只能說其可能存在
- 對於集合中的不同元素,如果 經過k個函數得到的k個數位中,任意一個重複
- 位陣列 中對應下標的元素會被覆蓋,此時該下標的元素不能被刪除(即歸零)
- 刪除可能會導致其他多個元素在Bloom Filter表示不「存在」
由此可見,Bloom Filter中:
- 位陣列的長度m越大,誤差率越小,而儲存代價越大
- 雜湊函數的個數k越多,誤差率越小,而效能越低

HBase中支援使用以下兩種Bloom Filter:
- ROW:基於 Rowkey 建立的Bloom Filter
- ROWCOL:基於 Rowkey+Column 建立的Bloom Filter
兩者的區別僅僅是:是否使用列資訊作為Bloom Filter的條件。
- 使用ROWCOL時,可以讓指定列的查詢更快,因為其通過Rowkey與列資訊來過濾不存在資料的HFile,但是相應的,產生的Bloom Filter資料會更加龐大。
- 而只通過Rowkey進行檢索的查詢,即使指定了ROWCOL也不會有其他效果,因為沒有攜帶列資訊。
- 通過Bloom Filter(如果有的話)快速定位到當前的Rowkey資料儲存於哪個HFile之後(或者不存在直接返回),通過HFile攜帶的 Data Block Index 等後設資料資訊,可快速定位到具體的資料塊起始位置,讀取並返回(載入到快取中)。
這就是Bloom Filter在HBase檢索資料的應用場景:
- 高效判斷key是否存在
- 高效定位key所在的HFile
當然,如果沒有指定建立Bloom Filter,RegionServer將會花費比較多的力氣,一個個檢索HFile,來判斷資料是否存在。
1.4 HFile儲存格式
通過Bloom Filter快速定位到需要檢索的資料,所在的HFile之後的操作,自然是從HFile中讀出資料,並返回。
據我們所知,HFile是HDFS上的檔案(或大或小都有可能),現在HBase面臨的一個問題,就是如何在HFile中 快速檢索獲得指定資料?
HBase隨機查詢的高效能,很大程度上取決於底層HFile的儲存格式,所以這個問題可以轉化為 HFile的儲存格式,該如何設計,才能滿足HBase 快速檢索 的需求。
生成一個HFile
Memstore記憶體中的資料,在刷寫到磁碟時,將會進行以下操作:
- 會先現在記憶體中建立 空的Data Block資料塊 包含 預留的Header空間。而後,將Memstore中的KVs一個個順序寫滿該Block(一般預設大小為64KB)。
- 如果指定了壓縮或者加密演演算法,Block資料寫滿之後,將會對整個資料區做相應的壓縮或者加密處理。
- 隨後在預留的Header區,寫入該Block的後設資料資訊,如 壓縮前後大小、上一個block的offset、checksum 等。
- 記憶體中的準備工作完成之後,通過HFile Writer輸出流將資料寫入到HDFS中,形成磁碟中的Data Block。
- 為輸出的Data Block生成一條索引資料,包括 {startkey、offset、size} 資訊,該索引資料會被暫時記錄在記憶體中的Block Index Chunk中。
至此,已經完成了第一個 Data Block 的寫入工作,Memstore中的 KVs 資料,將會按照這個過程,不斷進行 寫入記憶體 中的Data Block ——> 輸出到HDFS——> 生成索引資料儲存到記憶體中的Block Index Chunk 流程。
值得一提的是,如果啟用了Bloom Filter,那麼 Bloom Filter Data(點陣圖資料) 與 Bloom後設資料(雜湊函數與個數等) 將會和 KVs 資料一樣被處理:寫入記憶體中的Block ——> 輸出到HDFS Bloom Data Block ——>生成索引資料儲存到相對應的記憶體區域中。
由此我們可以知道,HFile寫入過程中,Data Block 和 Bloom Data Block 是交叉存在的。
隨著輸出的Data Block越來越多,記憶體中的索引資料Block Index Chunk也會越來越大。
達到一定大小之後(預設128KB)將會經過類似Data Block的輸出流程,寫入到HDFS中,形成 Leaf Index Block (和Data Block一樣,Leaf Index Block也有對應的Header區,保留該Block的後設資料資訊)。
同樣的,也會生成一條該 Leaf Index Block 對應的索引記錄,儲存在記憶體中的 Root Block Index Chunk。
Root Index ——> Leaf Data Block ——> Data Block 的索引關係,類似 B+樹 的結構。得益於多層索引,HBase可以在不讀取整個檔案的情況下查詢資料。
隨著記憶體中最後一個 Data Block、Leaf Index Block 寫入到HDFS,形成 HFile 的 Scanned Block Section。
Root Block Index Chunk 也會從記憶體中寫入HDFS,形成 HFile 的 Load-On-Open Section 的一部分。
至此,一個完整的HFile已經生成,如下圖所示:

檢索HFile
生成HFile之後該如何使用呢?
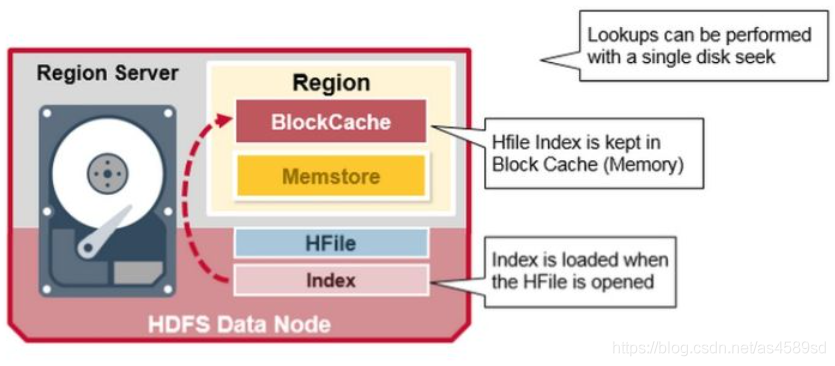
HFile的索引資料(包括 Bloom Filter索引和資料索引資訊)會在 Region Open 的時候被載入到讀快取中,之後資料檢索經過以下過程:
- 所有的讀請求,如果讀快取和Memstore中不存在,那麼將會檢索HFile索引
- 通過Bloom Filter索引(如果有設定Bloom Filter的話)檢索Bloom Data以 快速定位HFile是否存在 所需資料
- 定位到資料可能存在的HFile之後,讀取該HFile的 三層索引資料,檢索資料是否存在
- 存在,則根據索引中的 後設資料 ,找到具體的 Data Block 讀入記憶體,取出所需的KV資料
可以看到,在HFile的資料檢索過程中,一次讀請求,只有 真正確認資料存在, 且 需要讀取硬碟資料的時候,才會 執行硬碟查詢操作。
同時,得益於 分層索引 與 分塊儲存,在Region Open載入索引資料的時候,再也不必和老版本(0.9甚至更早,HFile只有一層資料索引並且統一儲存)一樣載入所有索引資料到記憶體中,導致啟動緩慢甚至卡機等問題。
1.5 HFile Compaction
Bloom Filter解決了如何在大量的HFile中快速定位資料,所在的HFile檔案,雖然有了Bloom Filter的幫助,大大提升了檢索效率,但是對於RegionServer來說,要檢索的HFile數量並沒有減少。
為了再次提高HFile的檢索效率,同時避免大量小檔案的產生,造成效能低下,RegionServer會通過Compaction機制,對HFile進行合併操作。
常見的Compaction觸發方式有:
- Memstore Flush檢測條件執行
- RegionServer定期檢查執行
- 使用者手動觸發執行
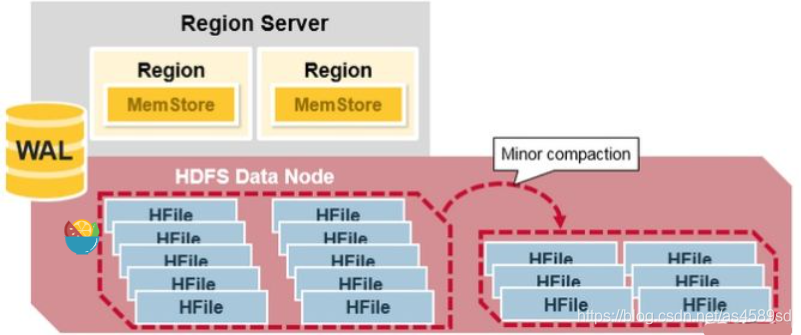
Minor Compaction
Minor Compaction 只執行簡單的檔案合併操作,選取較小的HFiles,將其中的資料順序寫入新的HFile後,替換老的HFiles。
但是如何在眾多HFiles中,選擇本次Minor Compaction,要合併的檔案卻有不少講究:
- 首先排除掉檔案大小, 大於 hbase.hstore.compaction.max.size 值的HFile
- 將HFiles按照檔案年齡排序(older to younger),並從older file開始選擇
- 如果該檔案大小 小於 hbase.hstore.compaction.min ,則加入Minor Compaction中
- 如果該檔案大小 小於 後續hbase.hstore.compaction.max 個HFile大小之和 * hbase.hstore.compaction.ratio,則將該檔案加入Minor Compaction中
- 掃描過程中,如果需要合併的HFile檔案數 達到 hbase.hstore.compaction.max(預設為10) 則開始合併過程
- 掃描結束後,如果需要合併的HFile的檔案數 大於 hbase.hstore.compaction.min(預設為3) 則開始合併過程
- 通過 hbase.offpeak.start.hour、hbase.offpeak.end.hour 設定高峰、非高峰時期,使 hbase.hstore.compaction.ratio的值在不同時期靈活變化(高峰值1.2、非高峰值5)
可以看到,Minor Compaction不會合並過大的HFile,合併的HFile數量也有嚴格的限制,以避免產生太大的IO操作,Minor Compaction經常在Memstore Flush後觸發,但不會對線上讀寫請求造成太大延遲影響。
Major Compaction
相對於Minor Compaction 只合並選擇的一部分HFile合併、合併時只簡單合併資料檔案的特點,Major Compaction則將會把Store中的所有HFile合併成一個大檔案,將會產生較大的IO操作。
同時將會清理三類無意義資料:被刪除的資料、TTL過期資料、版本號超過設定版本號的資料,Region Split過程中產生的Reference檔案也會在此時被清理。
Major Compaction定期執行的條件由以下兩個引數控制:
- hbase.hregion.majorcompaction:預設7天
- hbase.hregion.majorcompaction.jitter:預設為0.2
叢集中各個RegionServer將會在 hbase.hregion.majorcompaction +- hbase.hregion.majorcompaction * hbase.hregion.majorcompaction.jitter 的區間浮動進行Major Compaction,以避免過多RegionServer同時進行,造成較大影響。
Major Compaction 執行時機觸發之後,簡單來說,如果當前Store中HFile的最早更新時間,早於某個時間值,就會執行Major Compaction,該時間值為 hbase.hregion.majorcompaction * hbase.hregion.majorcompaction.jitter 。
手動觸發的情況下將會直接執行Compaction。

Compaction的優缺點
HBase通過Compaction機制,使底層HFile檔案數,保持在一個穩定的範圍,減少一次讀請求產生的IO次數、檔案Seek次數,確保HFiles檔案檢索效率,從而實現高效處理線上請求。
如果沒有Compaction機制,隨著Memstore刷寫的資料越來越多,HFile檔案數量將會持續上漲,一次讀請求生產的IO操作、Seek檔案的次數將會越來越多,反饋到線上,就是讀請求延遲越來越大。
然而,在Compaction執行過程中,不可避免的仍然會對線上造成影響。
- 對於Major Compaction來說,合併過程將會佔用大量頻寬、IO資源,此時線上的讀延遲將會增大。
- 對於Minor Compaction來說,如果Memstore寫入的資料量太多,刷寫越來越頻繁超出了HFile合併的速度。
- 即使不停地在合併,但是HFile檔案仍然越來越多,讀延遲也會越來越大
- HBase通過 hbase.hstore.blockingStoreFiles(預設7) 來控制Store中的HFile數量
- 超過設定值時,將會堵塞Memstore Flush阻塞flush操作 ,阻塞超時時間為 hbase.hstore.blockingWaitTime
- 阻塞Memstore Flush操作將會使Memstore的記憶體佔用率越來越高,可能導致完全無法寫入
簡而言之,Compaction機制保證了HBase的讀請求一直保持低延遲狀態,但付出的代價是Compaction執行期間大量的讀延遲毛刺和一定的寫阻塞(寫入量巨大的情況下)。
1.6 Region Split
HBase通過 LSM-Tree架構提供了高效能的隨機寫,通過快取、Bloom Filter、HFile與Compaction等機制提供了高效能的隨機讀。
至此,HBase已經具備了作為一個高效能讀寫資料庫的基本條件。如果HBase僅僅到此為止的話,那麼其也只是個在架構上和傳統資料庫有所區別的資料庫而已,作為一個高效能讀寫的分散式資料庫來說,其擁有近乎可以無限擴充套件的特性。
支援HBase進行自動擴充套件、負載均衡的是Region Split機制。
Split策略與觸發條件
在HBase中,提供了多種Split策略,不同的策略觸發條件各不相同。
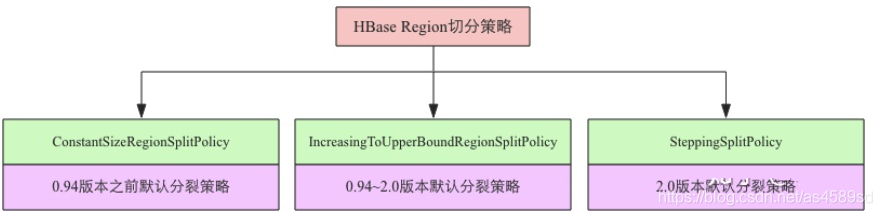
如上圖所示,不同版本中使用的預設策略在變化。
| ConstantSizeRegionSplitPolicy |
| 固定值策略:閾值預設大小 hbase.hregion.max.filesize |
| 優點:簡單實現 |
| 缺陷:考慮片面,小表不切分、大表切分成很多Region,線上使用弊端多 |
| IncreasingToUpperBoundRegionSplitPolicy |
| 非固定閾值:計算公式 min(R^2 * memstore.flush.size, region.split.size) R為Region所在的Table,在當前RegionServer上Region的個數 最大大小 hbase.hregion.max.filesize |
| 優點:自動適應大小表,對於Region個數多的閾值大,Region個數少的閾值小 |
| 缺陷:對於小表來說會產生很多小region |
| SteppingSplitPolicy: |
| 非固定閾值:如果Region個數為1,則閾值為 memstore.flush.size * 2 否則為 region.split.size |
| 優點:對大小表更加友好,小表不會一直產生小Region |
| 缺點:控制力度比較粗 |
可以看到,不同的切分策略其實只是在尋找切分Region時的閾值,不同的策略對閾值有不同的定義。
切分點
切分閾值確認完之後,首先要做的是尋找待切分Region的切分點。
HBase對Region的切分點定義如下:
- Region中最大的Store中,最大的HFile中心的block中,首個Rowkey。
- 如果最大的HFile只有一個block,那麼不切分(沒有middle key)。
得到切分點之後,核心的切分流程分為 prepare - execute - rollback 三個階段。
- prepare階段
在記憶體中,初始化兩個子Region(HRegionInfo物件),準備進行切分操作。
- execute階段
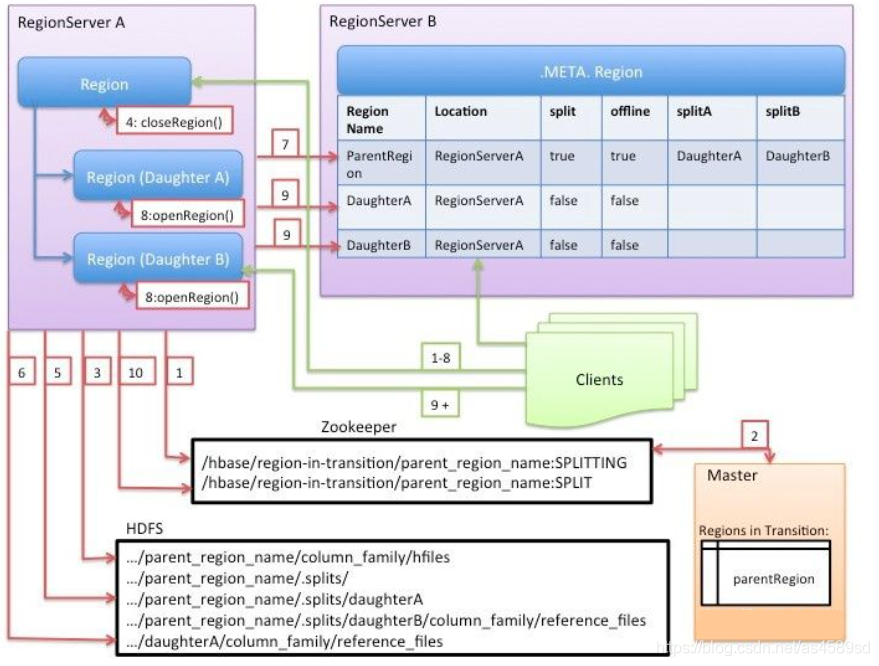
execute階段執行流程較為複雜,具體實施步驟為:
| 1 | RegionServer在Zookeeper上的 /hbase/region-in-transition 節點中,標記該Region狀態為SPLITTING。 |
| 2 | HMaster監聽到Zookeeper節點發生變化,在記憶體中,修改此Region狀態為RIT。 |
| 3 | 在該Region的儲存路徑下建立臨時資料夾 .split |
| 4 | 父Region close,flush所有資料到磁碟中,停止所有寫入請求。 |
| 5 | 在父Region的 .split資料夾中,生成兩個子Region資料夾,並寫入reference檔案 1.reference是一個特殊的檔案,體現在其檔名與檔案內容上 2.檔名組成:{父Region} 3.檔案內容:[splitkey]切分點rowkey,[top?]true/false,true為top上半部分,false為bottom下半部分 4.根據reference檔名,可以快速找到對應的父Region、其中的HFile檔案、HFile切分點,從而確認該子Region的資料範圍 5.資料範圍確認完畢之後,進行正常的資料檢索流程(此時仍然檢索父Region的資料) |
| 6 | 將子Region的目錄拷貝到HBase根目錄下,形成新的Region |
| 7 | 父Regin通知修改 hbase:meta 表後下線,不再提供服務 1.此時並沒有刪除父Region資料,僅在表中標記split列、offline列為true,並記錄兩個子region |
| 8 | 兩個子Region上線服務 |
| 9 | 通知 hbase:meta 表標記兩個子Region正式提供服務 |
- rollback階段
如果execute階段出現異常,則執行rollback操作,保證Region切分整個過程,是具備事務性、原子性的,要麼切分成功、要麼回到未切分的狀態。
region切分是一個複雜的過程,涉及到父region切分、子region生成、region下線與上線、zk狀態修改、後設資料狀態修改、master記憶體狀態修改 等多個子步驟,回滾程式,會根據當前進展到哪個子階段,清理對應的垃圾資料。
為了實現事務性,HBase設計了使用狀態機(SplitTransaction類),來儲存切分過程中的每個子步驟狀態。這樣一來,一旦出現異常,系統可以根據當前所處的狀態,決定是否回滾,以及如何回滾。
但是目前實現中,中間狀態是儲存在記憶體中,因此一旦在切分過程中,RegionServer宕機或者關閉,重新啟動之後,將無法恢復到切分前的狀態。即Region切分處於中間狀態的情況,也就是RIT。
由於Region切分的子階段很多,不同階段,解決RIT的處理方式也不一樣,需要通過hbck工具進行,具體檢視,並分析解決方案。
好訊息是,HBase2.0之後提出了,新的分散式事務框架Procedure V2,將會使用HLog儲存事務中間狀態,從而保證事務處理中,宕機重新啟動後,可以進行回滾或者繼續處理,從而減少RIT問題產生。
- 父Region清理
從以上過程中我們可以看到,Region的切分過程,並不會父Region的資料到子Region中,只是在子Region中建立了reference檔案,故Region切分過程是很快的。
只有進行Major Compaction時,才會真正(順便)將資料切分到子Region中,將HFile中的kv順序讀出、寫入新的HFile檔案。
RegionServer將會定期檢查 hbase:meta 表中的split和offline為true的Region,對應的子Region,是否存在reference檔案,如果不存在則刪除父Region資料。
- 負載均衡
Region切分完畢之後,RegionServer上將會存在更多的Region塊,為了避免RegionServer熱點,使請求負載均衡到叢集各個節點上,HMaster將會把一個或者多個子Region移動到其他RegionServer上。
移動過程中,如果當前RegionServer繁忙,HMaster將只會修改Region的後設資料資訊,至其他節點,而Region資料,仍然保留在當前節點中,直至下一次Major Compaction時進行資料移動。

至此,我們已經揭開了HBase架構與原理的大部分神祕面紗,在後續做叢集規劃、效能優化與實際應用中,為什麼這麼調整,以及為什麼這麼操作,都將一一對映到HBase的實現原理上。
如果你希望瞭解HBase的更多細節,可以參考《HBase權威指南》。
二、叢集部署
經過冗長的理論初步瞭解過HBase架構與工作原理之後,搭建HBase叢集是使用HBase的第一個步驟。
需要注意的是,HBase叢集一旦部署使用,再想對其作出調整需要付出慘痛代價(線上環境中),所以如何部署HBase叢集是使用的第一個關鍵步驟。
2.1 叢集物理架構
硬體混合型+軟體混合型叢集:
- 硬體混合型 :指的是該叢集機器設定參差不齊,混搭結構。
- 軟體混合型 :指的是該叢集部署了一套類似CDH全家桶套餐。
如以下的軟體混合型叢集狀況:
- 叢集規模:30
- 部署服務:HBase、Spark、Hive、Impala、Kafka、Zookeeper、Flume、HDFS、Yarn等
- 硬體情況:記憶體、CPU、磁碟等參差不齊,有高配有低配,混搭結構
這個叢集不管是規模、還是服務部署方式相信都是很多都有公司的「標準」設定。
那麼這樣的叢集有什麼問題呢?
如果僅僅HBase是一個非「線上」的系統,或者充當一個歷史冷資料儲存的巨量資料庫,這樣的叢集其實一點問題也沒有,因為對其沒有任何苛刻的效能要求。
但是如果希望HBase作為一個線上能夠承載海量並行、實時響應的系統,這個叢集隨著使用時間的增加很快就會崩潰。
從 硬體混合型 來說,一直以來Hadoop都是以宣稱能夠用低廉、老舊的機器撐起一片天。
這確實是Hadoop的一個大優勢,然而前提是作為離線系統使用。
離線系統的定義,即跑批的系統,如:Spark、Hive、MapReduce等,沒有很強的時間要求,顯著的吞吐量大,延遲高。
因為沒有實時性要求,幾臺拖拉機跑著也沒有問題,只要最後能出結果並且結果正確就OK。
那麼在我們現在的場景中,對HBase的定義已經不是一個離線系統,而是一個實時系統。
對於一個硬性要求很高的實時系統來說,如果其中幾臺老機器拖了後腿也會引起線上響應的延遲。
統一高配硬體+軟體混合型叢集
既然硬體拖後腿,那麼硬體升級自然是水到渠成。
現在我們有全新的高配硬體可以使用,參考如下:
- 叢集規模:30
- 部署服務:HBase、Spark、Hive、Impala、Kafka、Zookeeper、Flume、HDFS、Yarn等
- 硬體情況:記憶體、CPU、磁碟統一高設定
這樣的叢集可能還會存在什麼問題呢?
從 軟體混合型 來說,離線任務最大的特點就是吞吐量特別高,瞬間讀寫的資料量,可以把IO直接撐到10G/s,最主要的影響因素,就是大型離線任務,帶動高IO,將會影響HBase的響應效能。
如果僅止步於此,那麼線上的表現僅僅為短暫延遲,真正令人窒息的操作是,如果離線任務再把CPU撐爆,RegionServer節點可能會直接宕機,造成嚴重的生產影響。
存在的另外一種情況是,離線任務大量讀寫磁碟、讀寫HDFS,導致HBase IO連線異常,也會造成RegionServer異常(HBase紀錄檔反應HDFS connection timeout,HDFS紀錄檔反應IO Exception),造成線上故障。
根據觀測,叢集磁碟IO到4G以上、叢集網路IO 8G以上、HDFS IO 5G以上任意符合一個條件,線上將會有延遲反應。
因為離線任務執行太過強勢,導致RegionServer宕機,無法解決,那麼能採取的策略,只能是重新調整離線任務的執行,使用資源、執行順序等,限制離線計算能力來滿足線上的需求。同時還要限制叢集的CPU的使用率,可能出現,某臺機器CPU打滿後,整個機器假死,致服務異常,造成線上故障。
軟、硬體獨立的HBase叢集
簡而言之,無論是硬體混合型還是軟體混合型叢集,其可能因為各種原因帶來的延遲影響,對於一個高效能要求的HBase來說,都是無法忍受的。
所以在叢集規劃初始就應該考慮到種種情況,最好使用獨立的叢集部署HBase。
參考如下一組叢集規模設定:
- 叢集規模:15+5(RS+ZK)
- 部署服務:HBase、HDFS(另5臺虛擬Zookeeper)
- 硬體情況:除虛擬機器器外,物理機統一高設定
雖然從可用節點上來看,比之前的參考設定少了一半,但是從叢集部署模式上看,最大程度保證HBase的穩定性,從根本上,分離了軟硬體對HBase所帶來的影響,將會擁有比之前兩組叢集設定 更穩定的響應和更高的效能。
其他硬體推薦
- 網路卡:網路卡是容易產生瓶頸的地方,有條件建議使用雙萬兆網路卡
- 磁碟:沒有特殊要求,空間越大越好,轉速越高越好
- 記憶體:不需要大容量記憶體,建議32-128G(詳見下文)
- CPU:CPU核數越多越好,HBase本身壓縮資料、合併HFile等都需要CPU資源。
- 電源:建議雙電源冗餘
另外值得注意的是,Zookeeper節點建議設定5個節點,5個節點能保證Leader快速選舉,並且最多可以允許2個節點宕機的情況下正常使用。
硬體上可以選擇使用虛擬機器器,因為zk節點本身消耗資源並不大,不需要高配機器。但是5個虛擬節點不能在一個物理機上,防止物理機宕機影響所有zk節點。
2.2 安裝與部署
以CDH叢集為例安裝HBase。
使用ansible自動化指令碼工具進行安裝操作:
# 獲取安裝指令碼,上傳相關安裝軟體包至伺服器(JDK、MySQL、CM、CDH等)
yum install -y git
git clone https://github.com/chubbyjiang/cdh-deploy-robot.git
cd cdh-deploy-robot
# 編輯節點主機名
vi hosts
# 修改安裝設定項
vi deploy-robot.cnf
# 執行
sh deploy-robot.sh install_all安裝指令碼,將會執行 設定SSH免密登入、安裝軟體、作業系統優化、Java等開發環境初始化、MySQL安裝、CM服務安裝、作業系統效能測試等過程。
指令碼操作說明見:CDH叢集自動化部署工具 。
等待cloudera-scm-server程序起來後,在瀏覽器輸入 ip:7180 進入CM管理介面部署HDFS、HBase元件即可。
三、效能優化
HBase叢集部署完畢執行起來之後,看起來一切順利,但是所有東西都處於「初始狀態」中。
我們需要根據軟硬體環境,針對性地對HBase進行 調優設定,以確保其能夠以最完美的狀態執行,在當前叢集環境中,儘可能發揮硬體的優勢。
為了方便後續設定項計算說明,假設我們可用的叢集硬體狀況如下:
- 總記憶體:256G
- 總硬碟:1.8T * 12 = 21.6T
- 可分配記憶體:256 * 0.75 = 192G
- HBase可用記憶體空間:192 * 0.8 = 153G(20%留給HDFS等其他程序)
- 可用硬碟空間:21.6T * 0.85 = 18.36T
3.1 Region規劃
對於Region的大小,HBase官方檔案推薦單個在10G-30G之間,單臺RegionServer的數量,控制在20-300之間(當然,這僅僅是參考值)。
Region過大過小都會有不良影響:
| 過大的Region |
| 優點:遷移速度快、減少總RPC請求 |
| 缺點:compaction的時候資源消耗非常大、可能會有資料分散不均衡的問題 |
| 過小的Region |
| 優點:叢集負載平衡、HFile比較少,compaction影響小 |
| 缺點:遷移或者balance效率低、頻繁flush導致頻繁的compaction、維護開銷大 |
規劃Region的大小與數量時可以參考以下演演算法:
| 0. 計算HBase可用磁碟空間(單臺RegionServer) |
| 1. 設定region最大與最小閾值,region的大小在此區間選擇,如10-30G |
| 2. 設定最佳region數(這是一個經驗值),如單臺RegionServer 200個 |
| 3. 從region最小值開始,計算 HBase可用磁碟空間 / (region_size * hdfs副本數) = region個數 |
| 4. 得到的region個數如果 > 200,則增大region_size(step可設定為5G), 繼續計算直至找到region個數最接近200的region_size大小 |
| 5. region大小建議不小於10G |
例如:
當前可用磁碟空間為18T,選擇的region大小範圍為10-30G,最佳region個數為300。
那麼最接近 最佳Region個數300的 region_size 值為30G。
得到以下設定項:
- hbase.hregion.max.filesize=30G
- 單節點最多可儲存的Region個數約為300
3.2 記憶體規劃
我們知道RegionServer中的BlockCache有兩種實現方式:
- LRUBlockCache:On-Heap
- BucketCache:Off-Heap
這兩種模式的詳細說明可以參考 CDH官方檔案。
為HBase選擇合適的 記憶體模式 以及根據 記憶體模式 計算相關設定項是調優中的重要步驟。
首先我們可以根據可用記憶體大小來判斷使用哪種記憶體模式。
先看 超小記憶體(假設8G以下) 和 超大記憶體(假設128G以上) 兩種極端情況:
- 對於超小記憶體來說,即使可以使用BucketCache來利用堆外記憶體,但是使用堆外記憶體的主要目的,是避免GC時不穩定的影響,堆外記憶體的效率是要比堆內記憶體低的。由於記憶體總體較小,即使讀寫快取都在堆內記憶體中,GC時也不會造成太大影響,所以可以直接選擇LRUBlockCache。
- 對於超大記憶體來說,在超大記憶體上使用LRUBlockCache,將會出現我們所擔憂的情況:GC時,對線上造成很不穩定的延遲影響。這種場景下,應該儘量利用堆外記憶體作為讀快取,減小堆內記憶體的壓力,所以可以直接選擇BucketCache。
在兩邊的極端情況下,我們可以根據記憶體大小,選擇合適的記憶體模式,那麼如果記憶體大小,在合理、正常的範圍內該如何選擇呢?
此時我們應該主要關注業務應用的型別:
- 當業務主要為寫多讀少型應用時,寫快取利用率高,應該使用LRUBlockCache儘量提高堆內寫快取的使用率。
- 當業務主要為寫少讀多型應用時,讀快取利用率高(通常也意味著需要穩定的低延遲響應),應該使用BucketCache儘量提高堆外讀快取的使用率。
- 對於不明確或者多種型別混合的業務應用,建議使用BucketCache,保證讀請求的穩定性同時,堆內寫快取效率並不會很低。
- 當前HBase可使用的記憶體高達153G,故將選擇BucketCache的記憶體模型,來設定HBase,該模式下能夠最大化利用記憶體,減少GC影響,對線上的實時服務較為有利。
得到設定項:
hbase.bucketcache.ioengine=offheap: 使用堆外快取
確認使用的記憶體模式之後,接下來將通過計算確認 JavaHeap、對外讀快取、堆內寫快取、LRU後設資料 等記憶體空間具體的大小。
記憶體與磁碟比
討論具體設定之前,我們從 HBase叢集規劃 引入一個Disk / JavaHeap Ratio的概念,來幫助我們設定記憶體相關的引數。
理論上我們假設 最優 情況下 硬碟維度下的Region個數 和 JavaHeap維度下的Region個數 相等。
相應的計算公式為:
- 硬碟容量維度下Region個數: DiskSize / (RegionSize * ReplicationFactor)
- JavaHeap維度下Region個數: JavaHeap * HeapFractionForMemstore / (MemstoreSize / 2 )
其中:
- RegionSize:Region大小,設定項:hbase.hregion.max.filesize
- ReplicationFactor:HDFS的副本數,設定項:dfs.replication
- HeapFractionForMemstore:JavaHeap寫快取大小,即RegionServer記憶體中Memstore的總大小,設定項:hbase.regionserver.global.memstore.lowerLimit
- MemstoreSize:Memstore刷寫大小,設定項:hbase.hregion.memstore.flush.size
現在我們已知條件 硬碟維度和JavaHeap維度相等,求 1 bytes的JavaHeap大小需要搭配多大的硬碟大小 ?
已知:
DiskSize / (RegionSize * ReplicationFactor) = JavaHeap * HeapFractionForMemstore / (MemstoreSize / 2 )
求:DiskSize / JavaHeap
進行簡單的交換運算可得:
DiskSize / JavaHeap = (RegionSize / MemstoreSize) * ReplicationFactor * HeapFractionForMemstore * 2
以HBase的預設設定為例:
RegionSize: 10G
MemstoreSize: 128M
ReplicationFactor: 3
HeapFractionForMemstore: 0.4
計算:
(10G / 128M) * 3 * 0.4 * 2 = 192
即理想狀態下 ,RegionServer上 1 bytes的Java記憶體大小,需要搭配192bytes的硬碟大小最合適。
套用到當前叢集中,HBase可用記憶體為152G,在LRUBlockCache模式下,對應的硬碟空間需要為153G * 192 = 29T,這顯然是比較不合理的。
在BucketCache模式下,當前 JavaHeap、HeapFractionForMemstore 等值還未確定,我們會根據這個 計算關係,和已知條件,對可用記憶體進行規劃和調整,以滿足合理的記憶體/磁碟比。
已知條件:
記憶體模式:BucketCache
可用記憶體大小:153G
可用硬碟大小:18T
Region大小:30G
ReplicationFactor:3
未知變數:
JavaHeap
MemstoreSize
HeapFractionForMemstore
記憶體佈局
在計算位置變數的具體值之前,我們有必要了解一下當前使用的記憶體模式中對應的記憶體佈局。
BucketCache模式下,RegionServer的記憶體劃分如下圖:

簡化版:

寫快取
從架構原理中我們知道,Memstore有4種級別的Flush,需要我們關注的是 Memstore、Region和RegionServer級別的刷寫。
其中Memstore和Region級別的刷寫,並不會對線上造成太大影響,但是需要控制其閾值和刷寫頻次來進一步提高效能。
而RegionServer級別的刷寫,將會阻塞請求,直至刷寫完成,對線上影響巨大,需要儘量避免。
得到以下設定項:
- hbase.hregion.memstore.flush.size=256M: 控制的Memstore大小預設值為128M,太過頻繁的刷寫,會導致IO繁忙,重新整理佇列阻塞等。 設定太高也有壞處,可能會較為頻繁的觸發RegionServer級別的Flush,這裡設定為256M。
- hbase.hregion.memstore.block.multiplier=3: 控制的Region flush上限預設值為2,意味著一個Region中,最大同時儲存的Memstore大小為2 * MemstoreSize ,如果一個表的列族過多,將頻繁觸發,該值視情況調整。
現在我們設定兩個 經驗值變數:
- RegionServer總記憶體中,JavaHeap的佔比=0.35
- JavaHeap最大大小=56G:超出此值表示GC有風險
計算得JavaHeap的大小為 153 * 0.35 = 53.55 ,沒有超出預期的最大JavaHeap。如果超過最大期望值,則使用最大期望值代替,得JavaHeap大小為53G。
現在JavaHeap、MemstoreSize已知,可以得到唯一的位置變數 HeapFractionForMemstore 的值為 0.48 。
得到以下設定項:
- RegionServer JavaHeap堆疊大小: 53G
- hbase.regionserver.global.memstore.upperLimit=0.58: 整個RS中Memstore最大比例,比lower大5-15%
- hbase.regionserver.global.memstore.lowerLimit=0.48: 整個RS中Memstore最小比例
- 寫快取大小為 53 * 0.48 = 25.44G
讀快取設定
當前記憶體資訊如下:
| A 總可用記憶體:153G |
| J JavaHeap大小:53G W 寫快取大小:25.44G R1 LRU快取大小:? |
| R2 BucketCache堆外快取大小:153 - 53 = 100G |
因為讀快取由 堆內的LRU後設資料 與 堆外的資料快取 組成,兩部分佔比一般為 1:9(經驗值) 。
而對於總體的堆內記憶體,存在以下限制,如果超出此限制,則應該調低比例:
LRUBlockCache + MemStore < 80% * JVM_HEAP即 LRUBlockCache + 25.44 < 53 * 0.8
可得R1的最大值為16.96G
總讀快取:R = R1 + R2
R1:R2 = 1:9
R1 = 11G < 16G
R = 111G
設定堆外快取涉及到的相關引數如下:
- hbase.bucketcache.size=111 * 1024M: 堆外快取大小,單位為M
- hbase.bucketcache.percentage.in.combinedcache=0.9: 堆外讀快取所佔比例,剩餘為堆內後設資料快取大小
- hfile.block.cache.size=0.15: 校驗項,+upperLimit需要小於0.8
現在,我們再來計算 Disk / JavaHeap Ratio 的值,檢查JavaHeap記憶體與磁碟的大小是否合理:
RegionSize / MemstoreSize * ReplicationFactor * HeapFractionForMemstore * 2
30 * 1024 / 256 * 3 * 0.48 * 2 = 345.6
53G * 345.6 = 18T <= 18T
至此,已得到HBase中記憶體相關的重要引數:
RegionServer JavaHeap堆疊大小: 53G
hbase.hregion.max.filesize=30G
hbase.bucketcache.ioengine=offheap
hbase.hregion.memstore.flush.size=256M
hbase.hregion.memstore.block.multiplier=3
hbase.regionserver.global.memstore.upperLimit=0.58
hbase.regionserver.global.memstore.lowerLimit=0.48
hbase.bucketcache.size=111 * 1024M
hbase.bucketcache.percentage.in.combinedcache=0.9
hfile.block.cache.size=0.153.3 合併與切分
HFile合併
Compaction過程中,比較常見的優化措施是:
| Major Compaction 停止自動執行 增大其處理執行緒數 |
| Minor Compaction 增加Memstore Flush大小 增加Region中最大同時儲存的Memstore數量 |
設定項如下:
# 關閉major compaction,定時在業務低谷執行,每週一次
hbase.hregion.majorcompaction=0
# 提高compaction的處理閾值
hbase.hstore.compactionThreshold=6
# 提高major compaction處理執行緒數
hbase.regionserver.thread.compaction.large=5
# 提高阻塞memstore flush的hfile檔案數閾值
hbase.hstore.blockingStoreFiles=100
hbase.hregion.memstore.flush.size=256M
hbase.hregion.memstore.block.multiplier=3Major Compaction 指令碼
關閉自動compaction之後手動執行指令碼的程式碼範例:
#!/bin/bash
if [ $# -lt 1 ]
then
echo "Usage: <table key>"
exit 1
fi
TMP_FILE=tmp_tables
TABLES_FILE=tables.txt
key=$1
echo "list" | hbase shell > $TMP_FILE
sleep 2
sed '1,6d' $TMP_FILE | tac | sed '1,2d' | tac | grep $key > $TABLES_FILE
sleep 2
for table in $(cat $TABLES_FILE); do
date=`date "+%Y%m%d %H:%M:%S"`
echo "major_compact '$table'" | hbase shell
echo "'$date' major_compact '$table'" >> /tmp/hbase-major-compact.log
sleep 5
done
rm -rf $TMP_FILE
rm -rf $TABLES_FILE
echo "" >> /tmp/hbase-major-compact.logRegion切分
在架構原理中我們知道,Region多有種切分策略,在Region切分時,將會有短暫時間內的Region下線無服務,Region切分完成之後的Major Compaction中,將會移動父Region的資料到子Region中,HMaster為了叢集整體的負載均衡,可能會將子Region分配到其他RegionServer節點。
從以上描述中可以看到,Region的切分行為,其實是會對線上的服務請求,帶來一定影響的。
Region切分設定中,使用預設設定,一般不會有太大問題,但是有沒有 保證資料表負載均衡的情況下,Region不進行切分行為?
有一種解決方案是使用 預分割區 + 固定值切分策略,可以一定程度上,通過預估資料表數量,以及Region個數,從而在一段時間內,抑制Region不產生切分。
假設我們可以合理的預判到一個表的當前總資料量為150G,每日增量為1G,當前Region大小為30G。
那麼我們建表的時候,至少要設定 (150 + 1 * 360) / 30 = 17 個分割區,如此一來,一年內(360天)該表的資料增長,都會落到17個Region中,而不再切分。
當然對於一個不斷增長的表,除非時間段設定的非常長,否則總有發生切分的一天。如果無限制的延長時間段,則會在一開始,就產生大量的空Region,這對HBase是極其不友好的,所以時間段是一個需要合理控制的閾值。
在hbase-site.xml中設定Region切分策略為ConstantSizeRegionSplitPolicy:
hbase.regionserver.region.split.policy=org.apache.hadoop.hbase.regionserver.ConstantSizeRegionSplitPolicy
3.4 響應優化
HBase伺服器端
高並行情況下,如果HBase伺服器端處理執行緒數不夠,應用層將會收到HBase伺服器端,丟擲的無法建立新執行緒的異常,從而導致應用層執行緒阻塞。
可以釋放調整HBase伺服器端設定以提升處理效能:
# Master處理使用者端請求最大執行緒數
hbase.master.handler.count=256
# RS處理使用者端請求最大執行緒數,如果該值設定過大,則會佔用過多的記憶體,導致頻繁的GC,或者出現OutOfMemory
hbase.regionserver.handler.count=256
# 使用者端快取大小,預設為2M
hbase.client.write.buffer=8M
# scan快取一次獲取資料的條數,太大也會產生OOM
hbase.client.scanner.caching=100另外,以下兩項中,預設設定下超時太久、重試次數太多,一旦應用層連線不上HBse伺服器端將會進行近乎無限的重試,長連線無法釋放,新請求不斷進來,從而導致執行緒堆積應用假死等,影響比較嚴重,可以適當減少:
hbase.client.retries.number=3
hbase.rpc.timeout=10000
HDFS
適當增加處理執行緒等設定:
dfs.datanode.handler.count=64
dfs.datanode.max.transfer.threads=12288
dfs.namenode.handler.count=256
dfs.namenode.service.handler.count=256同時,對於HDFS的儲存設定也可以做以下優化:
# 可以設定多個,擁有多個後設資料備份
dfs.name.dir
# 設定多個磁碟與路徑,提高並行讀寫能力
dfs.data.dir
# dn同時處理檔案的上限,預設為256,可以提高到8192
dfs.datanode.max.xcievers應用層(使用者端)
之前我們說到,HBase為了保證CP,在A的實現上做了一定的妥協,導致HBase出現故障,並轉移的過程中,會有較大的影響。
對於應用服務層來說,保證服務的 穩定性 是最重要的,為了避免HBase可能產生的問題,應用層應該採用 讀寫分離 的模式,來最大程度保證自身穩定性。
應用層讀寫分離
可靠的應用層應使用 讀寫分離 的模式提高響應效率與可用性:
- 讀寫應用應該分別屬於 不同的服務範例 ,避免牽一髮而動全身
- 對於寫入服務,資料非同步寫入redis或者kafka佇列,由下游消費者同步至HBase,響應效能十分優異
- 需要處理資料,寫入失敗的事務處理與重寫機制
- 對於讀取服務,如果一個RS掛了,一次讀請求,經過若干重試和超時,可能會持續幾十秒甚至更久,由於和寫入服務分離,可以做到互不影響
- 最好使用快取層,來緩解RS宕機問題,對於至關重要的資料,先查快取,再查HBase(見下文)
在應用層的 程式碼 中,同樣有需要注意的小TIPS:
- 如果在Spring中,將HBaseAdmin設定為Bean載入,則需設定為懶載入,避免在啟動時,連結HMaster失敗,導致啟動失敗,從而無法進行一些降級操作。
- scanner使用後及時關閉,避免浪費使用者端和伺服器的記憶體
- 查詢時指定列簇或者指定要查詢的列限定掃描範圍
- Put請求可以關閉WAL,但是優化不大
- 最後,可以適當調整一下 連線池 設定:
# 組態檔載入為全域性共用,可提升tps
setInt(「hbase.hconnection.threads.max」, 512);
setInt(「hbase.hconnection.threads.core」, 64); 3.5 使用快取層
即使我們經過大量的準備、調優與設定,在真實使用場景中,隨著HBase中承載的資料量越來越大、請求越來越多、並行越來越大,HBase不可避免的會有一些「毛刺」問題。
如果你現在已經通過HBase,解決了大部分的線上資料儲存與存取問題,但是有一小部分的資料,需要提供最快速的響應、最低的延遲,由於HBase承載的東西太多,總是有延遲比較高的響應,此時需要怎麼解決?
其實,對所有資料庫軟體來說,都會存在這樣的場景。於是,類似關係型資料庫中的資料庫拆分等策略,也是可以應用到HBase上的。
或者是將最關鍵、最熱點的資料,使用 獨立的HBase叢集 來處理,或者是使用諸如 Redis等更高效能的快取軟體,其核心思想就是,將最關鍵的業務資料獨立儲存,以提供最優質的服務,這個服務統稱為快取層。
3.6 其他設定
hbase-env.sh 的 HBase 使用者端環境高階設定程式碼段
設定了G1垃圾回收器和其他相關屬性:
-XX:+UseG1GC
-XX:InitiatingHeapOccupancyPercent=65
-XX:-ResizePLAB
-XX:MaxGCPauseMillis=90
-XX:+UnlockDiagnosticVMOptions
-XX:+G1SummarizeConcMark
-XX:+ParallelRefProcEnabled
-XX:G1HeapRegionSize=32m
-XX:G1HeapWastePercent=20
-XX:ConcGCThreads=4
-XX:ParallelGCThreads=16
-XX:MaxTenuringThreshold=1
-XX:G1MixedGCCountTarget=64
-XX:+UnlockExperimentalVMOptions
-XX:G1NewSizePercent=2
-XX:G1OldCSetRegionThresholdPercent=5hbase-site.xml 的 RegionServer 高階設定程式碼段(安全閥)
手動split region設定
<property>
<name>hbase.regionserver.wal.codec</name>
<value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec</value>
</property>
<property>
<name>hbase.region.server.rpc.scheduler.factory.class</name>
<value>org.apache.hadoop.hbase.ipc.PhoenixRpcSchedulerFactory</value>
<description>Factory to create the Phoenix RPC Scheduler that uses separate queues for index and metadata updates</description>
</property>
<property>
<name>hbase.rpc.controllerfactory.class</name>
<value>org.apache.hadoop.hbase.ipc.controller.ServerRpcControllerFactory</value>
<description>Factory to create the Phoenix RPC Scheduler that uses separate queues for index and metadata updates</description>
</property>
<property>
<name>hbase.regionserver.thread.compaction.large</name>
<value>5</value>
</property>
<property>
<name>hbase.regionserver.region.split.policy</name>
<value>org.apache.hadoop.hbase.regionserver.ConstantSizeRegionSplitPolicy</value>
</property>四、使用技巧
4.1 建表規約
Rowkey規範
| 如無特殊情況,長度應控制在64位元組內。 |
| 充分分析業務需求後,確認需要查詢的維度欄位。 |
| get請求,則rowkey雜湊處理。 |
| scan請求,rowkey字首維度雜湊後,後續維度依照查詢順序或者權重拼接(視具體情況決定是否雜湊處理)。 各個欄位都保持相同長度以支援左對齊的部分鍵掃描。 scan形式的資料表中,需要提前統計,單個scan可掃描出的最大數量。 |
列簇規範
如無特殊情況,一個表中只有一個列簇,統一使用info命名。
如果需要1以上的列簇,則原則上,一次請求的資料,不可跨列簇儲存,多不超過3個列簇。
範例:NAME =>'info'
壓縮
統一使用SNAPPY壓縮。
範例:COMPRESSION => 'SNAPPY'
版本
預設版本數為3,前期儲存空間緊張的情況下,設定為1。
範例:VERSIONS => 1
布隆過濾器
視情情況使用,主要針對get查詢提高效能。
kv範例:BLOOMFILTER => 'ROW',根據rowkey中的資訊,生成布隆過濾器資料。
kv+col範例:BLOOMFILTER => 'ROWCOL',根據rowkey+列資訊生成布隆過濾器,針對get+指定列名的查詢,產生的過濾器檔案會比ROW大。
預分割區
預分割區需要通過評估整體表資料量來確認,當前hbase叢集region塊大小為30G。
- 歷史大增量小的資料:給定的預分割區數,足夠支撐該表,永遠(或者相當長的時間內)不split,即更新的所有資料,將進入已存在的region中,以減少split與compaction造成的影響。
- 歷史小增量大的資料:預分割區個數,需滿足歷史資料等分儲存,並支撐未來一段時間內(一個月以上)的增量資料。
預分割區區間計算:屬性相同的表中,隨機取出部分樣本資料(rowkey維度欄位)。將樣本轉換成rowkey之後排序,並以樣本個數/預分割區個數為步長,取預分割區個數個rowkey組成預分割區區間。
預分割區程式碼範例:
/**
* hbase region預分割區工具
*
* @param filePath 樣本檔案路徑
* @param numOfSPlits 預分割區個數
**/
def rowkeySplitedArr(filePath: String, numOfSPlits: Int) = {
val file = Source.fromFile(filePath).getLines()
val res = file.map {
line =>
val arr = line.split("_")
val card = arr(0)
val name = arr(1)
MathUtil.MD5Encrypt32(card) + MathUtil.MD5Encrypt32(card)
}.toList.sorted
val count = res.length / numOfSPlits
var str = ""
for (i <- 0 until numOfSPlits) {
str += s"\'${res(i * count)}\',"
}
println(str.substring(0, str.length - 1))
}4.2 使用者端使用
伺服器端設定完成之後,如何更好的使用HBase叢集,也需要花點心思測試與調整。
以Spark作為HBase讀寫使用者端為例。
批次查詢
Spark有對應的API,可以批次讀取HBase資料,但是使用過程比較繁瑣,這裡安利一個小元件Spark DB Connector,批次讀取HBase的程式碼可以這麼簡單:
val rdd = sc.fromHBase[(String, String, String)]("mytable")
.select("col1", "col2")
.inColumnFamily("columnFamily")
.withStartRow("startRow")
.withEndRow("endRow")
done!實時查詢
以流式計算為例,Spark Streaming中,我們要實時查詢HBase只能通過HBase Client API(沒有隊友提供服務的情況下)。
那麼HBase Connection每條資料建立一次,肯定是不允許的,效率太低,對服務壓力比較大,並且ZK的連線數,會暴增影響服務。
比較可行的方案是每個批次建立一個連結(類似for each Partiton中,每個分割區建立一個連結,分割區中資料共用連結)。但是這種方案也會造成部分連線浪費、效率低下等。
如果可以做到一個Streaming中,所有批次、所有資料,始終複用一個連線池是最理想的狀態。
Spark中提供了Broadcast,這個重要工具可以幫我們實現這個想法,只要將建立的HBase Connection廣播出去,所有節點就都能複用,但是真實執行程式碼時,你會發現HBase Connection是不可序列化的物件,無法廣播。。。
其實利用scala的lazy關鍵字可以繞個彎子來實現:
//範例化該物件,並廣播使用
class HBaseSink(zhHost: String, confFile: String) extends Serializable {
//延遲載入特性
lazy val connection = {
val hbaseConf = HBaseConfiguration.create()
hbaseConf.set(HConstants.ZOOKEEPER_QUORUM, zhHost)
hbaseConf.addResource(confFile)
val conn = ConnectionFactory.createConnection(hbaseConf)
sys.addShutdownHook {
conn.close()
}
conn
}
}在Driver程式中,範例化該物件並廣播,在各個節點中取廣播變數的value進行使用。
廣播變數只在具體呼叫value的時候,才會去建立物件,並copy到各個節點,而這個時候被序列化的物件,其實是外層的HBaseSink,當在各個節點上,具體呼叫connection,進行操作的時候,Connection才會被真正建立(在當前節點上),從而繞過了HBase Connection無法序列化的情況(同理也可以推導RedisSink、MySQLSink等)。
這樣一來,一個Streaming Job,將會使用同一個資料庫連線池,在Structured Streaming中的for each Write也可以直接應用。
批次寫入
同理安利元件
rdd.toHBase("mytable")
.insert("col1", "col2")
.inColumnFamily("columnFamily")
.save()這裡邊其實對HBase Client的Put介面包裝了一層,但是當線上有大量實時請求,同時線下又有大量資料需要更新時,直接這麼寫會對線上的服務造成衝擊,具體表現可能為持續一段時間的短暫延遲,嚴重的甚至可能會把RS節點整掛。
大量寫入的資料帶來具體大GC開銷,整個RS的活動都被阻塞了,當ZK來監測心跳時,發現無響應,就將該節點列入宕機名單,而GC完成後,RS發現自己「被死亡」了,那麼就乾脆自殺,這就是HBase的「朱麗葉死亡」。
這種場景下,使用bulkload是最安全、快速的,唯一的缺點是帶來的IO比較高。
大批次寫入更新的操作,建議使用bulkload工具來實現。
實時寫入
理同,實時查詢,可以使用建立的Connection做任何操作。
結束語
我們從HBase的架構原理出發,接觸了HBase大部分的核心知識點。
理論基礎決定上層建築,有了對HBase的總體認知,在後續的叢集部署、效能優化,以及實際應用中都能夠比較遊刃有餘。
知其然而之所以然,保持對技術原理的探索,不僅能學習到,其中許多令人驚歎的設計與操作,最重要的是,能夠真正在業務應用中充分發揮其應有的效能。